A Statistical View of Deep Learning (I): Recursive GLMs
A Statistical View of Deep Learning (I): Recursive GLMs
Deep learningand the use of deep neural networks [1] are now established as a key tool for practical machine learning. Neural networks have an equivalence with many existing statistical and machine learning approaches and I would like to explore one of these views in this post. In particular, I'll look at the view of deep neural networks as recursive generalised linear models (RGLMs). Generalised linear models form one of the cornerstones of probabilistic modelling and are used in almost every field of experimental science, so this connection is an extremely useful one to have in mind. I'll focus here on what are called feedforward neural networks and leave a discussion of the statistical connections to recurrent networks to another post.
Generalised Linear Models
The basic linear regressionmodel is a linear mapping from P-dimensional input features (or covariates) x, to a set of targets (or responses) y, using a set of weights (or regression coefficients) β and a bias (offset) β0 . The outputs can also by multivariate, but I'll assume they are scalar here. The full probabilistic model assumes that the outputs are corrupted by Gaussian noise of unknown variance σ².
In this formulation, η is the systematic component of the model and ε is the random component. Generalised linear models (GLMs)[2] allow us to extend this formulation to problems where the distribution on the targets is not Gaussian but some other distribution (typically a distribution in the exponential family). In this case, we can write the generalised regression problem, combining the coefficients and bias for more compact notation, as:
where g(·) is the link function that allows us to move from natural parameters η to mean parameters μ. If the inverse link function used in the definition of μ above were the logistic sigmoid, then the mean parameters correspond to the probabilities of y being a 1 or 0 under the Bernoulli distribution.
There are many link functions that allow us to make other distributional assumptions for the target (response) y. In deep learning, the link function is referred to as the activation function and I list in the table below the names for these functions used in the two fields. From this table we can see that many of the popular approaches for specifying neural networks that have counterparts in statistics and related literatures under (sometimes) very different names, such multinomial regression in statistics and softmax classification in deep learning, or rectifier in deep learning and tobit models is statistics.
| Target Type | Regression | Link | Inv link | Activation |
|---|---|---|---|---|
| Real | Linear | Identity | Identity | |
| Binary | Logistic | Logit
logμ1−μ
|
Sigmoid σ
11+exp(−η)
|
Sigmoid |
| Binary | Probit | Inv Gauss CDF
Φ−1(μ)
|
Gauss CDF
Φ(η)
|
Probit |
| Binary | Gumbel | Compl. log-log
log(−log(μ))
|
Gumbel CDF
e−e−x
|
|
| Binary | Logistic | Hyperbolic Tangent
tanh(η)
|
Tanh | |
| Categorical | Multinomial | Multin. Logit
ηi∑jηj
|
Softmax | |
| Counts | Poisson |
log(μ)
|
exp(ν)
|
|
| Counts | Poisson |
(√μ)
|
ν2
|
|
| Non-neg. | Gamma | Reciprocal
1μ
|
1ν
|
|
| Sparse | Tobit | max
max(0;ν)
|
ReLU | |
| Ordered | Ordinal | Cum. Logit
σ(ϕk−η)
|
Recursive Generalised Linear Models
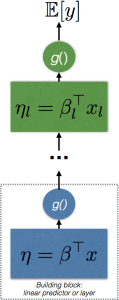
Constructing a recursive GLM or deep deep feedforward neural network using the linear predictor as the basic building block.
GLMS have a simple form: they use a linear combination of the input using weights β, and pass this result through a simple non-linear function. In deep learning, this basic building block is called a layer. It is easy to see that such a building block can be easily repeated to form more complex, hierarchical and non-linear regression functions. This recursive application of the basic regression building block is why models in deep learning are described as having multiple layers and are described as deep.
If an arbitrary regression function h, for layer l, with linear predictorη, and inverse link or activation function f, is specified as:
then we can easily specify a recursive GLM by iteratively applying or composing this basic building block:
This composition is exactly the specification of an L-layer deep neural network model. There is no mystery in such a construction (and hence in feedforward neural networks) and the utility of such a model is easy to see, since it allows us to extend the power of our regressors far beyond what is possible using only linear predictors.
This form also shows that recursive GLMs and neural networks are one way of performing basis function regression. What such a formulation adds is a specific mechanism by which to specify the basis functions: by application of recursive linear predictors.
Learning and Estimation
Given the specification of these models, what remains is an approach for training them, i.e. estimation of the regression parameters β for every layer. This is where deep learning has provided a great deal of insight and has shown how such models can be scaled to very high-dimensional inputs and on very large data sets.
A natural approach is to use the negative log-probability as the loss function and maximum likelihood estimation [3]:
where if using the Gaussian distribution as the likelihood function we obtain the squared loss, or if using the Bernoulli distribution we obtain the cross entropy loss. Estimation or learning in deep neural networks corresponds directly to maximum likelihood estimation in recursive GLMs. We can now solve for the regression parameters by computing gradients w.r.t. the parameters and updating using gradient descent. Deep learning methods now always train such models using stochastic approximation (usingstochastic gradient descent), using automated tools for computing the chain rule for derivatives throughout the model (i.e. back-propagation), and perform the computation on powerful distributed systems and GPUs. This allows such a model to be scaled to millions of data points and to very large models with potentially millions of parameters [4].
From the maximum likelihood theory, we know that such estimators can be prone to overfitting and this can be reduced by incorporating model regularisation, either using approaches such as penalised regression and shrinkage, or through Bayesian regression. The importance of regularisation has also been recognised in deep learning and further exchange here could be beneficial.
Summary
Deep feedforward neural networks have a direct correspondence to recursive generalised linear models and basis function regression in statistics -- which is an insight that is useful in demystifying deep networks and an interpretation that does not rely on analogies to sequential processing in the brain. The training procedure is an application of (regularised) maximum likelihood estimation, for which we now have a large set of tools that allow us to apply these models to very large-scale, real-world systems. A statistical perspective on deep learning points to a broad set of knowledge that can be exchanged between the two fields, with the potential for further advances in efficiency and understanding of these regression problems. It is thus one I believe we all benefit from by keeping in mind. There are other viewpoints such as the connection to graphical models, or for recurrent networks,to dynamical systems, which I hope to think through in the future.
Some References
| [1] | Christopher M Bishop, Neural networks for pattern recognition, , 1995 |
| [2] | Peter McCullagh, John A Nelder, Generalized linear models., , 1989 |
| [3] | Peter J Bickel, Kjell A Doksum, Mathematical Statistics, volume I, , 2001 |
| [4] | Leon Bottou, Stochastic Gradient Descent Tricks, Neural Networks: Tricks of the Trade, 2012 |
A Statistical View of Deep Learning (I): Recursive GLMs的更多相关文章
- A Statistical View of Deep Learning (IV): Recurrent Nets and Dynamical Systems
A Statistical View of Deep Learning (IV): Recurrent Nets and Dynamical Systems Recurrent neural netw ...
- A Statistical View of Deep Learning (II): Auto-encoders and Free Energy
A Statistical View of Deep Learning (II): Auto-encoders and Free Energy With the success of discrimi ...
- A Statistical View of Deep Learning (V): Generalisation and Regularisation
A Statistical View of Deep Learning (V): Generalisation and Regularisation We now routinely build co ...
- A Statistical View of Deep Learning (III): Memory and Kernels
A Statistical View of Deep Learning (III): Memory and Kernels Memory, the ways in which we remember ...
- 【深度学习Deep Learning】资料大全
最近在学深度学习相关的东西,在网上搜集到了一些不错的资料,现在汇总一下: Free Online Books by Yoshua Bengio, Ian Goodfellow and Aaron C ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料【转】
转自:机器学习(Machine Learning)&深度学习(Deep Learning)资料 <Brief History of Machine Learning> 介绍:这是一 ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 2)
##机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 2)---#####注:机器学习资料[篇目一](https://github.co ...
- translation of 《deep learning》 Chapter 1 Introduction
原文: http://www.deeplearningbook.org/contents/intro.html Inventors have long dreamed of creating mach ...
- 深度学习基础 Probabilistic Graphical Models | Statistical and Algorithmic Foundations of Deep Learning
目录 Probabilistic Graphical Models Statistical and Algorithmic Foundations of Deep Learning 01 An ove ...
随机推荐
- 深入N皇后问题的两个最高效算法的详解 分类: C/C++ 2014-11-08 17:22 117人阅读 评论(0) 收藏
N皇后问题是一个经典的问题,在一个N*N的棋盘上放置N个皇后,每行一个并使其不能互相攻击(同一行.同一列.同一斜线上的皇后都会自动攻击). 一. 求解N皇后问题是算法中回溯法应用的一个经典案例 回溯算 ...
- HDU-4041-Eliminate Witches! (11年北京网络赛!!)
Eliminate Witches! Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Other ...
- 洛谷比赛 堕落的Joe
/*暴力50*/ #include<iostream> #include<cstdio> #include<cstring> #define maxn 100010 ...
- html input 文本框的一些操作(限制输入...)
1.取消按钮按下时的虚线框 在input里添加属性值 hideFocus 或者 HideFocus=true 2.只读文本框内容 在input里添加属性值 readonly 3.防止退后清空的TEXT ...
- WPF FindName()查找命名注册的元素
一.查找xaml中命名注册的元素 <Button x:Name="btn1" Content="显示内容" HorizontalAlignment=&qu ...
- C#快速排序法
最近面试的时候,被问到了快速排序法.一时之间,无法想起算法来. 重新看了书本,算法如下: 1)设置两个变量I.J,排序开始的时候:I=0,J=N-1: 2)以第一个数组元素作为关键数据,赋值给key, ...
- Android开发app如何设定应用图标下的应用名称为汉字以及自定义图标
一.应用名称为汉字 二.自定义图标
- ubuntu桌面变空白,或者只有壁纸,任务栏消失的解决办法
原因:因为打开了桌面特效的原因,但设置不合导致的. 解决方法:方法一:1.按住Ctrl+Alt+F1切换到字符终端下,输入用户名和密码登录2.输入以下命令删除出错的Compiz配置文件相关目录:rm ...
- Asp.Net MVC安全更新MS14-059导致项目编译失败
微软最近一次安全更新MS14-059(链接:https://technet.microsoft.com/en-us/library/security/ms14-059)由于直接应用到了machine. ...
- Android布局管理器(贞布局)
贞布局有FrameLayout所代表,它直接继承了ViewGroup组建 贞布局为每个加入其中的组件创建一个空白区域(一帧),所以每个子组件占用一帧,这些贞都会根据gravity属性执行自动对齐 贞布 ...