A Neural Network in 11 lines of Python
A Neural Network in 11 lines of Python
A bare bones neural network implementation to describe the inner workings of backpropagation.
Posted by iamtrask on July 12, 2015
Summary: I learn best with toy code that I can play with. This tutorial teaches backpropagation via a very simple toy example, a short python implementation.
Edit: Some folks have asked about a followup article, and I'm planning to write one. I'll tweet it out when it's complete at @iamtrask. Feel free to follow if you'd be interested in reading it and thanks for all the feedback!
Just Give Me The Code:
X = np.array([ [0,0,1],[0,1,1],[1,0,1],[1,1,1] ])
y = np.array([[0,1,1,0]]).T
syn0 = 2*np.random.random((3,4)) - 1
syn1 = 2*np.random.random((4,1)) - 1
for j in xrange(60000):
l1 = 1/(1+np.exp(-(np.dot(X,syn0))))
l2 = 1/(1+np.exp(-(np.dot(l1,syn1))))
l2_delta = (y - l2)*(l2*(1-l2))
l1_delta = l2_delta.dot(syn1.T) * (l1 * (1-l1))
syn1 += l1.T.dot(l2_delta)
syn0 += X.T.dot(l1_delta)
However, this is a bit terse…. let’s break it apart into a few simple parts.
Part 1: A Tiny Toy Network
A neural network trained with backpropagation is attempting to use input to predict output.
| Inputs | Output | ||
|---|---|---|---|
| 0 | 0 | 1 | 0 |
| 1 | 1 | 1 | 1 |
| 1 | 0 | 1 | 1 |
| 0 | 1 | 1 | 0 |
Consider trying to predict the output column given the three input columns. We could solve this problem by simply measuring statistics between the input values and the output values. If we did so, we would see that the leftmost input column is perfectly correlated with the output. Backpropagation, in its simplest form, measures statistics like this to make a model. Let's jump right in and use it to do this.
2 Layer Neural Network:
import numpy as np # sigmoid function
def nonlin(x,deriv=False):
if(deriv==True):
return x*(1-x)
return 1/(1+np.exp(-x)) # input dataset
X = np.array([ [0,0,1],
[0,1,1],
[1,0,1],
[1,1,1] ]) # output dataset
y = np.array([[0,0,1,1]]).T # seed random numbers to make calculation
# deterministic (just a good practice)
np.random.seed(1) # initialize weights randomly with mean 0
syn0 = 2*np.random.random((3,1)) - 1 for iter in xrange(10000): # forward propagation
l0 = X
l1 = nonlin(np.dot(l0,syn0)) # how much did we miss?
l1_error = y - l1 # multiply how much we missed by the
# slope of the sigmoid at the values in l1
l1_delta = l1_error * nonlin(l1,True) # update weights
syn0 += np.dot(l0.T,l1_delta) print "Output After Training:"
print l1
Output After Training:
[[ 0.00966449]
[ 0.00786506]
[ 0.99358898]
[ 0.99211957]]
| Variable | Definition |
|---|---|
| X | Input dataset matrix where each row is a training example |
| y | Output dataset matrix where each row is a training example |
| l0 | First Layer of the Network, specified by the input data |
| l1 | Second Layer of the Network, otherwise known as the hidden layer |
| syn0 | First layer of weights, Synapse 0, connecting l0 to l1. |
| * | Elementwise multiplication, so two vectors of equal size are multiplying corresponding values 1-to-1 to generate a final vector of identical size. |
| - | Elementwise subtraction, so two vectors of equal size are subtracting corresponding values 1-to-1 to generate a final vector of identical size. |
| x.dot(y) | If x and y are vectors, this is a dot product. If both are matrices, it's a matrix-matrix multiplication. If only one is a matrix, then it's vector matrix multiplication. |
As you can see in the "Output After Training", it works!!! Before I describe processes, I recommend playing around with the code to get an intuitive feel for how it works. You should be able to run it "as is" in an ipython notebook (or a script if you must, but I HIGHLY recommend the notebook). Here are some good places to look in the code:
• Check out the "nonlin" function. This is what gives us a probability as output.
• Check out how l1_error changes as you iterate.
• Take apart line 36. Most of the secret sauce is here.
• Check out line 39. Everything in the network prepares for this operation.
Let's walk through the code line by line.
Recommendation: open this blog in two screens so you can see the code while you read it. That's kinda what I did while I wrote it. :)
Line 01: This imports numpy, which is a linear algebra library. This is our only dependency.
Line 04: This is our "nonlinearity". While it can be several kinds of functions, this nonlinearity maps a function called a "sigmoid". A sigmoid function maps any value to a value between 0 and 1. We use it to convert numbers to probabilities. It also has several other desirable properties for training neural networks.
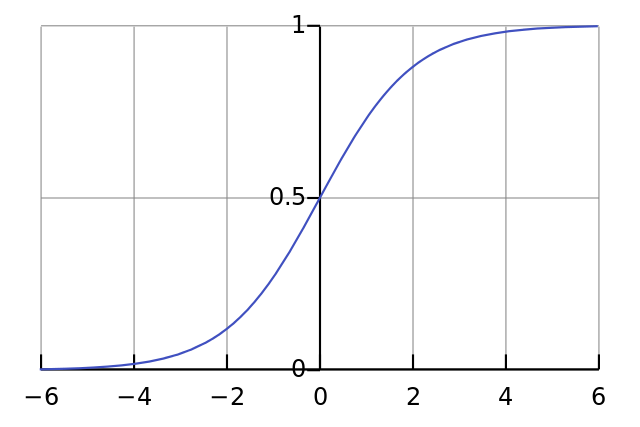
Line 05: Notice that this function can also generate the derivative of a sigmoid (when deriv=True). One of the desirable properties of a sigmoid function is that its output can be used to create its derivative. If the sigmoid's output is a variable "out", then the derivative is simply out * (1-out). This is very efficient.
If you're unfamililar with derivatives, just think about it as the slope of the sigmoid function at a given point (as you can see above, different points have different slopes). For more on derivatives, check out this derivatives tutorialfrom Khan Academy.
Line 10: This initializes our input dataset as a numpy matrix. Each row is a single "training example". Each column corresponds to one of our input nodes. Thus, we have 3 input nodes to the network and 4 training examples.
Line 16: This initializes our output dataset. In this case, I generated the dataset horizontally (with a single row and 4 columns) for space. ".T" is the transpose function. After the transpose, this y matrix has 4 rows with one column. Just like our input, each row is a training example, and each column (only one) is an output node. So, our network has 3 inputs and 1 output.
Line 20: It's good practice to seed your random numbers. Your numbers will still be randomly distributed, but they'll be randomly distributed in exactly the same way each time you train. This makes it easier to see how your changes affect the network.
Line 23: This is our weight matrix for this neural network. It's called "syn0" to imply "synapse zero". Since we only have 2 layers (input and output), we only need one matrix of weights to connect them. It's dimentionality is (3,1) because we have 3 inputs and 1 output. Another way of looking at it is that l0 is of size 3 and l1 is of size 1. Thus, we want to connect every node in l0 to every node in l1, which requires a matrix of dimensionality (3,1). :)
Also notice that it is initialized randomly with a mean of zero. There is quite a bit of theory that goes into weight initialization. For now, just take it as a best practice that it's a good idea to have a mean of zero in weight initialization.
Another note is that the "neural network" is really just this matrix. We have "layers" l0 and l1 but they are transient values based on the dataset. We don't save them. All of the learning is stored in the syn0 matrix.
Line 25: This begins our actual network training code. This for loop "iterates" multiple times over the training code to optimize our network to the dataset.
Line 28: Since our first layer, l0, is simply our data. We explicitly describe it as such at this point. Remember that X contains 4 training examples (rows). We're going to process all of them at the same time in this implementation. This is known as "full batch" training. Thus, we have 4 different l0 rows, but you can think of it as a single training example if you want. It makes no difference at this point. (We could load in 1000 or 10,000 if we wanted to without changing any of the code).
Line 29: This is our prediction step. Basically, we first let the network "try" to predict the output given the input. We will then study how it performs so that we can adjust it to do a bit better for each iteration.
This line contains 2 steps. The first matrix multiplies l0 by syn0. Consider the dimensions of each:
(4 x 3) dot (3 x 1) = (4 x 1)
Matrix multiplication is ordered, such the dimensions in the middle of the equation must be the same. The final matrix generated is thus the number of rows of the first matrix and the number of columns of the second matrix.
Since we loaded in 4 training examples, we ended up with 4 guesses for the correct answer, a (4 x 1) matrix. Each output corresponds with the network's guess for a given input. Perhaps it becomes intuitive why we could have "loaded in" an arbitrary number of training examples. The matrix multiplication would still work out. :)
Line 32: So, given that l1 had a "guess" for each input. We can now compare how well it did by subtracting the true answer (y) from the guess (l1). l1_error is just a vector of positive and negative numbers reflecting how much the network missed.
Line 36: Now we're getting to the good stuff! This is the secret sauce! There's a lot going on in this line, so let's further break it into two parts.
First Part: The Derivative
nonlin(l1,True)
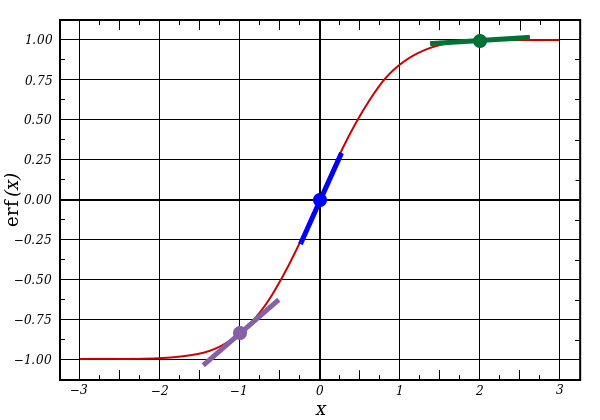
If l1 represents these three dots, the code above generates the slopes of the lines below. Notice that very high values such as x=2.0 (green dot) and very low values such as x=-1.0 (purple dot) have rather shallow slopes. The highest slope you can have is at x=0 (blue dot). This plays an important role. Also notice that all derivatives are between 0 and 1.
Entire Statement: The Error Weighted Derivative
l1_delta = l1_error * nonlin(l1,True)
There are more "mathematically precise" ways than "The Error Weighted Derivative" but I think that this captures the intuition. l1_error is a (4,1) matrix. nonlin(l1,True) returns a (4,1) matrix. What we're doing is multiplying them"elementwise". This returns a (4,1) matrix l1_delta with the multiplied values.
When we multiply the "slopes" by the error, we are reducing the error of high confidence predictions. Look at the sigmoid picture again! If the slope was really shallow (close to 0), then the network either had a very high value, or a very low value. This means that the network was quite confident one way or the other. However, if the network guessed something close to (x=0, y=0.5) then it isn't very confident. We update these "wishy-washy" predictions most heavily, and we tend to leave the confident ones alone by multiplying them by a number close to 0.
Line 36: We are now ready to update our network! Let's take a look at a single training example.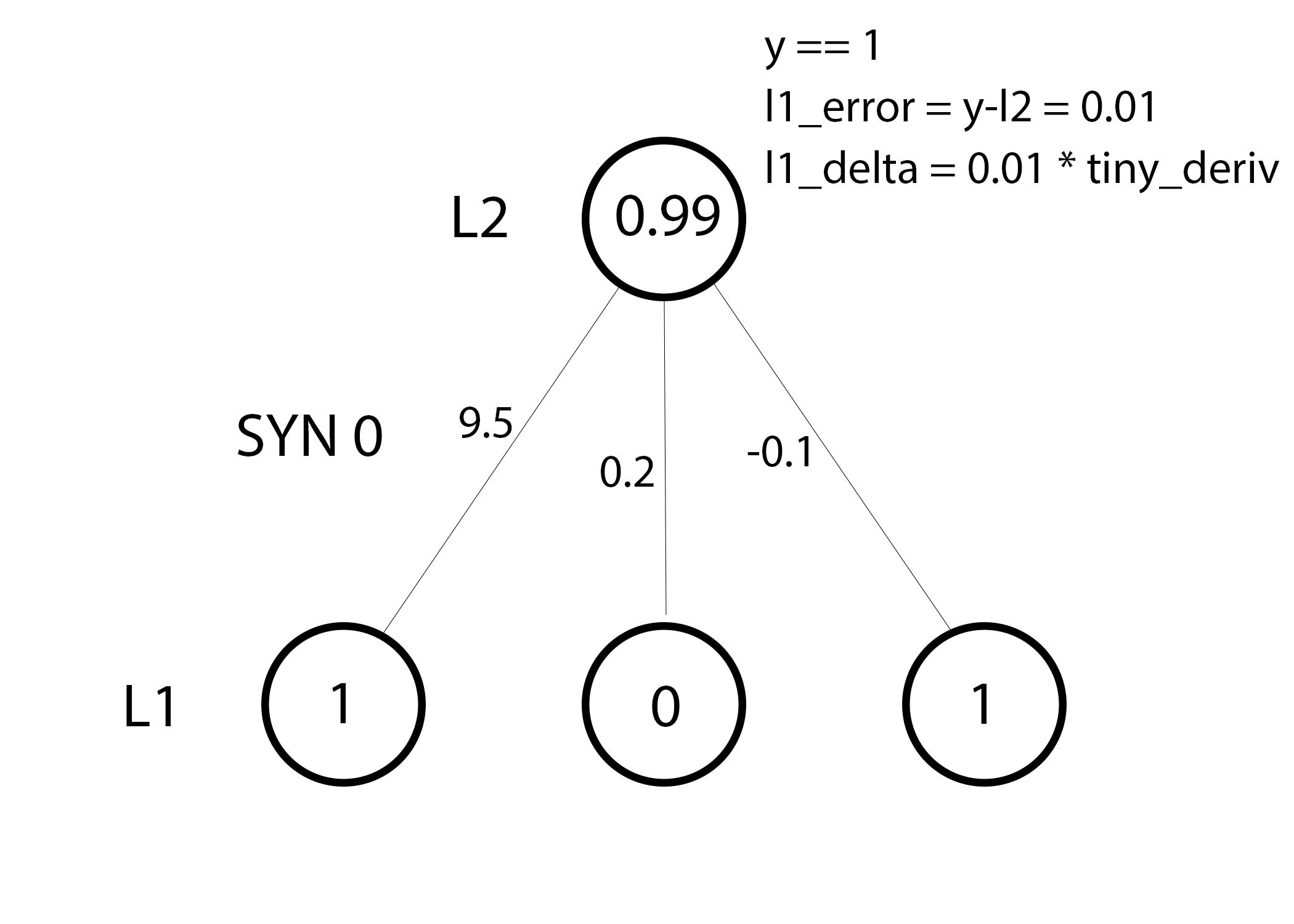 In this training example, we're all setup to update our weights. Let's update the far left weight (9.5).
In this training example, we're all setup to update our weights. Let's update the far left weight (9.5).
weight_update = input_value * l1_delta
For the far left weight, this would multiply 1.0 * the l1_delta. Presumably, this would increment 9.5 ever so slightly. Why only a small ammount? Well, the prediction was already very confident, and the prediction was largely correct. A small error and a small slope means a VERY small update. Consider all the weights. It would ever so slightly increase all three.
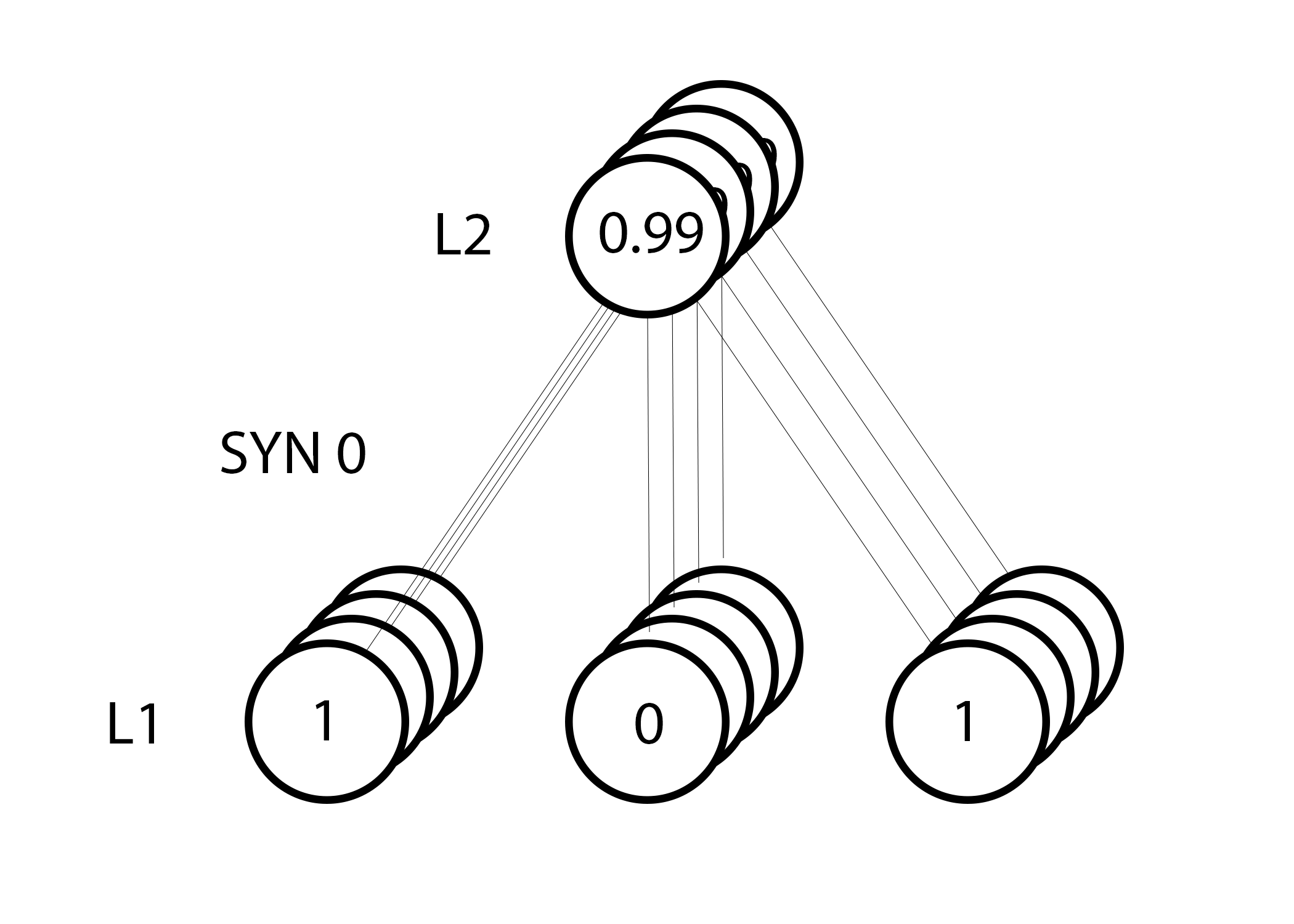
However, because we're using a "full batch" configuration, we're doing the above step on all four training examples. So, it looks a lot more like the image above. So, what does line 36 do? It computes the weight updates for each weight for each training example, sums them, and updates the weights, all in a simple line. Play around with the matrix multiplication and you'll see it do this!
Takeaways:
So, now that we've looked at how the network updates, let's look back at our training data and reflect. When both an input and a output are 1, we increase the weight between them. When an input is 1 and an output is 0, we decrease the weight between them.
| Inputs | Output | ||
|---|---|---|---|
| 0 | 0 | 1 | 0 |
| 1 | 1 | 1 | 1 |
| 1 | 0 | 1 | 1 |
| 0 | 1 | 1 | 0 |
Thus, in our four training examples below, the weight from the first input to the output would consistently increment or remain unchanged, whereas the other two weights would find themselves both increasing and decreasing across training examples (cancelling out progress). This phenomenon is what causes our network to learn based on correlations between the input and output.
Part 2: A Slightly Harder Problem
| Inputs | Output | ||
|---|---|---|---|
| 0 | 0 | 1 | 0 |
| 0 | 1 | 1 | 1 |
| 1 | 0 | 1 | 1 |
| 1 | 1 | 1 | 0 |
Consider trying to predict the output column given the two input columns. A key takeway should be that neither columns have any correlation to the output. Each column has a 50% chance of predicting a 1 and a 50% chance of predicting a 0.
So, what's the pattern? It appears to be completely unrelated to column three, which is always 1. However, columns 1 and 2 give more clarity. If either column 1 or 2 are a 1 (but not both!) then the output is a 1. This is our pattern.
This is considered a "nonlinear" pattern because there isn't a direct one-to-one relationship between the input and output. Instead, there is a one-to-one relationship between a combination of inputs, namely columns 1 and 2.

Believe it or not, image recognition is a similar problem. If one had 100 identically sized images of pipes and bicycles, no individual pixel position would directly correlate with the presence of a bicycle or pipe. The pixels might as well be random from a purely statistical point of view. However, certaincombinations of pixels are not random, namely the combination that forms the image of a bicycle or a person.
Our Strategy
In order to first combine pixels into something that can then have a one-to-one relationship with the output, we need to add another layer. Our first layer will combine the inputs, and our second layer will then map them to the output using the output of the first layer as input. Before we jump into an implementation though, take a look at this table.
| Inputs (l0) | Hidden Weights (l1) | Output (l2) | |||||
|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 0.1 | 0.2 | 0.5 | 0.2 | 0 |
| 0 | 1 | 1 | 0.2 | 0.6 | 0.7 | 0.1 | 1 |
| 1 | 0 | 1 | 0.3 | 0.2 | 0.3 | 0.9 | 1 |
| 1 | 1 | 1 | 0.2 | 0.1 | 0.3 | 0.8 | 0 |
If we randomly initialize our weights, we will get hidden state values for layer 1. Notice anything? The second column (second hidden node), has a slight correlation with the output already! It's not perfect, but it's there. Believe it or not, this is a huge part of how neural networks train. (Arguably, it's the only way that neural networks train.) What the training below is going to do is amplify that correlation. It's both going to update syn1 to map it to the output, and update syn0 to be better at producing it from the input!
Note: The field of adding more layers to model more combinations of relationships such as this is known as "deep learning" because of the increasingly deep layers being modeled.
3 Layer Neural Network:
import numpy as np def nonlin(x,deriv=False):
if(deriv==True):
return x*(1-x) return 1/(1+np.exp(-x)) X = np.array([[0,0,1],
[0,1,1],
[1,0,1],
[1,1,1]]) y = np.array([[0],
[1],
[1],
[0]]) np.random.seed(1) # randomly initialize our weights with mean 0
syn0 = 2*np.random.random((3,4)) - 1
syn1 = 2*np.random.random((4,1)) - 1 for j in xrange(60000): # Feed forward through layers 0, 1, and 2
l0 = X
l1 = nonlin(np.dot(l0,syn0))
l2 = nonlin(np.dot(l1,syn1)) # how much did we miss the target value?
l2_error = y - l2 if (j% 10000) == 0:
print "Error:" + str(np.mean(np.abs(l2_error))) # in what direction is the target value?
# were we really sure? if so, don't change too much.
l2_delta = l2_error*nonlin(l2,deriv=True) # how much did each l1 value contribute to the l2 error (according to the weights)?
l1_error = l2_delta.dot(syn1.T) # in what direction is the target l1?
# were we really sure? if so, don't change too much.
l1_delta = l1_error * nonlin(l1,deriv=True) syn1 += l1.T.dot(l2_delta)
syn0 += l0.T.dot(l1_delta)
Error:0.496410031903
Error:0.00858452565325
Error:0.00578945986251
Error:0.00462917677677
Error:0.00395876528027
Error:0.00351012256786
| Variable | Definition |
|---|---|
| X | Input dataset matrix where each row is a training example |
| y | Output dataset matrix where each row is a training example |
| l0 | First Layer of the Network, specified by the input data |
| l1 | Second Layer of the Network, otherwise known as the hidden layer |
| l2 | Final Layer of the Network, which is our hypothesys, and should approximate the correct answer as we train. |
| syn0 | First layer of weights, Synapse 0, connecting l0 to l1. |
| syn1 | Second layer of weights, Synapse 1 connecting l1 to l2. |
| l2_error | This is the amount that the neural network "missed". |
| l2_delta | This is the error of the network scaled by the confidence. It's almost identical to the error except that very confident errors are muted. |
| l1_error | Weighting l2_delta by the weights in syn1, we can calculate the error in the middle/hidden layer. |
| l1_delta | This is the l1 error of the network scaled by the confidence. Again, it's almost identical to the l1_error except that confident errors are muted. |
Recommendation: open this blog in two screens so you can see the code while you read it. That's kinda what I did while I wrote it. :)
Everything should look very familiar! It's really just 2 of the previous implementation stacked on top of each other. The output of the first layer (l1) is the input to the second layer. The only new thing happening here is on line 43.
Line 43: uses the "confidence weighted error" from l2 to establish an error for l1. To do this, it simply sends the error across the weights from l2 to l1. This gives what you could call a "contribution weighted error" because we learn how much each node value in l1 "contributed" to the error in l2. This step is called "backpropagating" and is the namesake of the algorithm. We then update syn0 using the same steps we did in the 2 layer implementation.
Part 3: Conclusion and Future Work
My Recommendation:
If you're serious about neural networks, I have one recommendation. Try to rebuild this network from memory. I know that might sound a bit crazy, but it seriously helps. If you want to be able to create arbitrary architectures based on new academic papers or read and understand sample code for these different architectures, I think that it's a killer exercise. I think it's useful even if you're using frameworks like Torch, Caffe, or Theano. I worked with neural networks for a couple years before performing this exercise, and it was the best investment of time I've made in the field (and it didn't take long).
Future Work
This toy example still needs quite a few bells and whistles to really approach the state-of-the-art architectures. Here's a few things you can look into if you want to further improve your network. (Perhaps I will in a followup post.)
• Alpha
• Bias Units
• Mini-Batches
• Delta Trimming
• Parameterized Layer Sizes
• Regularization
• Dropout
• Momentum
• Batch Normalization
• GPU Compatability
• Other Awesomeness You Implement
A Neural Network in 11 lines of Python的更多相关文章
- 课程一(Neural Networks and Deep Learning),第二周(Basics of Neural Network programming)—— 3、Python Basics with numpy (optional)
Python Basics with numpy (optional)Welcome to your first (Optional) programming exercise of the deep ...
- Tensorflow - Implement for a Convolutional Neural Network on MNIST.
Coding according to TensorFlow 官方文档中文版 中文注释源于:tf.truncated_normal与tf.random_normal TF-卷积函数 tf.nn.con ...
- Recurrent Neural Network系列2--利用Python,Theano实现RNN
作者:zhbzz2007 出处:http://www.cnblogs.com/zhbzz2007 欢迎转载,也请保留这段声明.谢谢! 本文翻译自 RECURRENT NEURAL NETWORKS T ...
- [Python Debug]Kernel Crash While Running Neural Network with Keras|Jupyter Notebook运行Keras服务器宕机原因及解决方法
最近做Machine Learning作业,要在Jupyter Notebook上用Keras搭建Neural Network.结果连最简单的一层神经网络都运行不了,更奇怪的是我先用iris数据集跑了 ...
- Python -- machine learning, neural network -- PyBrain 机器学习 神经网络
I am using pybrain on my Linuxmint 13 x86_64 PC. As what it is described: PyBrain is a modular Machi ...
- Recurrent Neural Network系列4--利用Python,Theano实现GRU或LSTM
yi作者:zhbzz2007 出处:http://www.cnblogs.com/zhbzz2007 欢迎转载,也请保留这段声明.谢谢! 本文翻译自 RECURRENT NEURAL NETWORK ...
- 机器学习: Python with Recurrent Neural Network
之前我们介绍了Recurrent neural network (RNN) 的原理: http://blog.csdn.net/matrix_space/article/details/5337404 ...
- 从0开始用python实现神经网络 IMPLEMENTING A NEURAL NETWORK FROM SCRATCH IN PYTHON – AN INTRODUCTION
code地址:https://github.com/dennybritz/nn-from-scratch 文章地址:http://www.wildml.com/2015/09/implementing ...
- 课程五(Sequence Models),第一 周(Recurrent Neural Networks) —— 1.Programming assignments:Building a recurrent neural network - step by step
Building your Recurrent Neural Network - Step by Step Welcome to Course 5's first assignment! In thi ...
随机推荐
- Linux服务器命令行模式安装Matlab2014a
Linux服务器命令行模式安装Matlab2014a,有需要的朋友可以参考下. 0.下载安装包 下载Matlab2014a for Linux安装包的ISO镜像文件(感谢万能的度娘)以及破解包(下载地 ...
- Linux 查看文件修改
在以前知道在Linux下查看Tomcat日志文件, tail -f catalina.out 同样的命令"tail -f filename",我就可以看其它日志文件啦: tail ...
- 用Cookie记住上次登录用户名
一个登录页面设置查看Cookie中的数据(Cookie不为null);然后将页面提交到另一个页面去,在这个页面中的到是否选择记住用户名,如果选择了, 就创建Cookie对象,将用户名存储起来,下次登录 ...
- scala学习笔记:变量声明中的模式
先看个正常的写法: scala> val x = 1 x: Int = 1 体会一下元组的写法: scala> val (x,y,z)=(1,2,3) x: Int = 1 y: Int ...
- android NDK 笔记
*************************************************华丽的分割线********************************************* ...
- Java_JVM学习笔记(深入理解Java虚拟机)___重点
http://chenzhou123520.iteye.com/category/196061 转载 JVM学习笔记(一):运行时数据区 JVM学习笔记(二):JVM中对象访问的两种方式 JVM学习笔 ...
- C# IO操作(三)文件编码
在.net环境下新建一个文本文件(所谓文本文件就是直接可以用记事本打开的文件,直接保存字符串)和在系统中新建一个文本文件的编码是不一样的,.net默认采用UTF-8,而中文操作系统采用的是ANSI.如 ...
- lua package path 设置方法
lua package path 设置方法: 添加环境变量LUA_PATH="/add_path/?.lua;;" 1.add_path为新添加的目录: 2.一定要添加双引号: 3 ...
- QT/C++ 智能指针
什么是智能指针? 为什么用智能指针? 还有哪些关于内存管理方面的知识点,需要注意的?
- Build Error 6041: Internal build error
Note: Following content is reprinted from the Original article Flexera : Build Error 6041. Only for ...