Scrapy详解
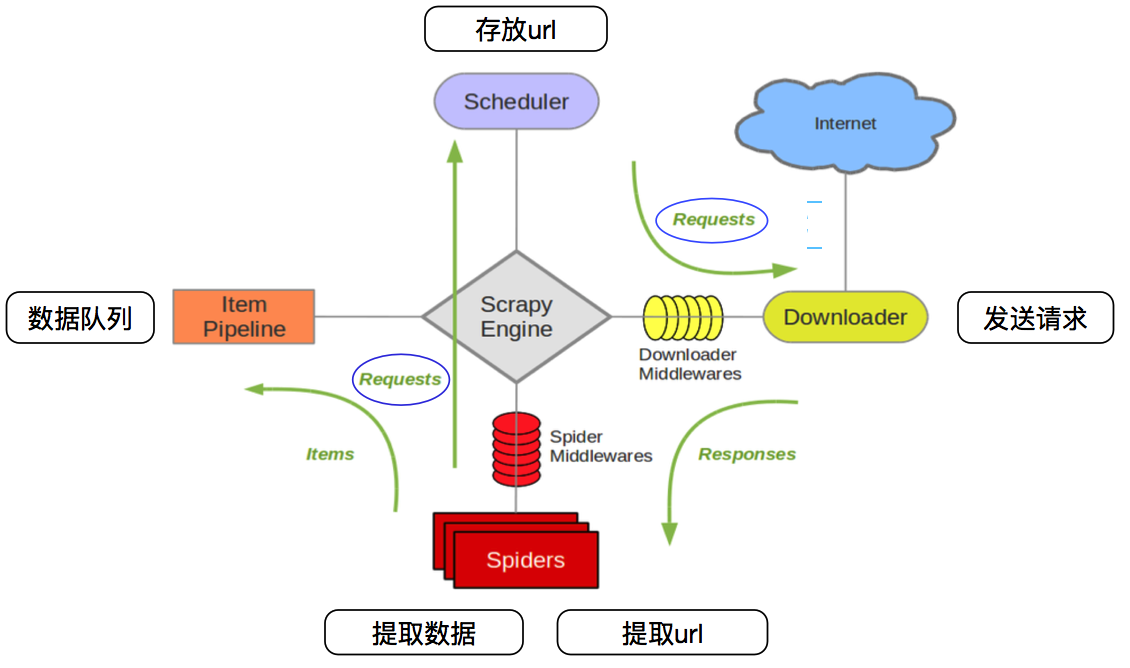
一、爬虫生态框架
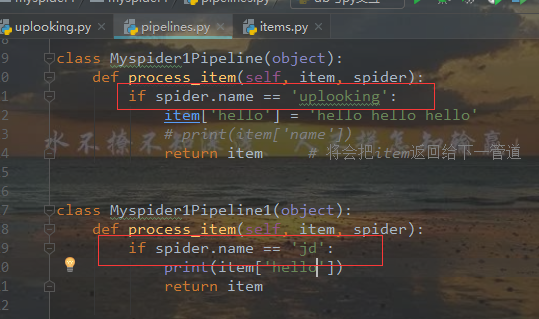
在管道传数据只能传字典和items类型。
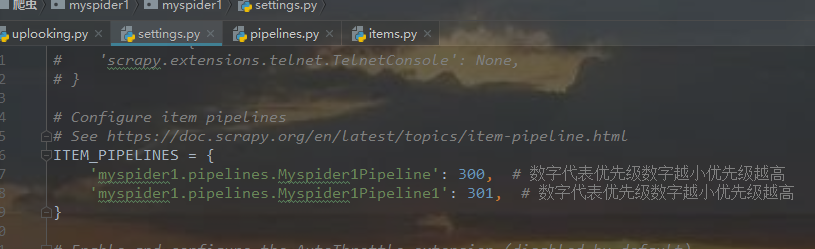

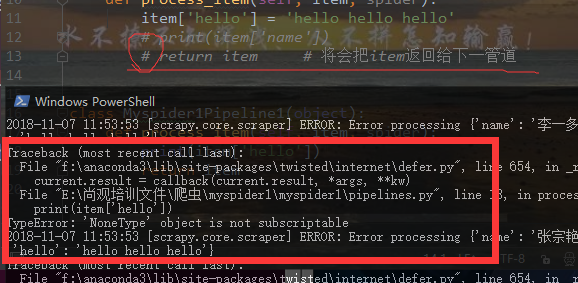
将 上一return语句注释则会报错 如:

如上图,爬虫文件中有一个name属性,如果多个爬虫可以通过这个属性在管道控制分析的是哪个爬虫的数据
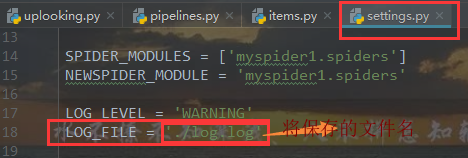
日志文件

添加红框里面的一条代码,让打印结果只显示warning级别及以上的警告
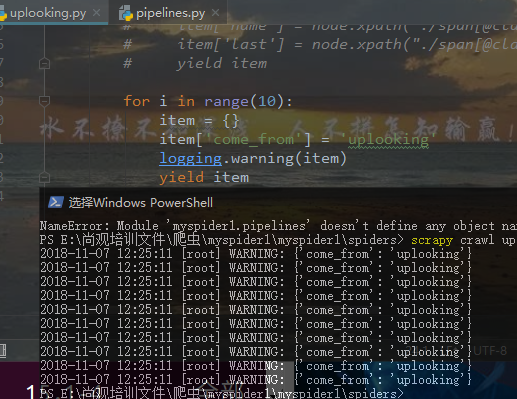
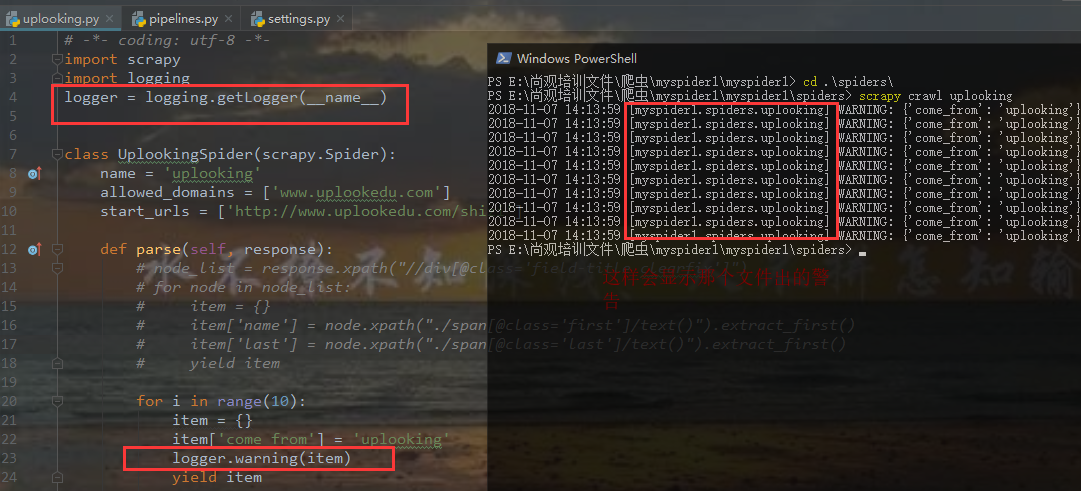
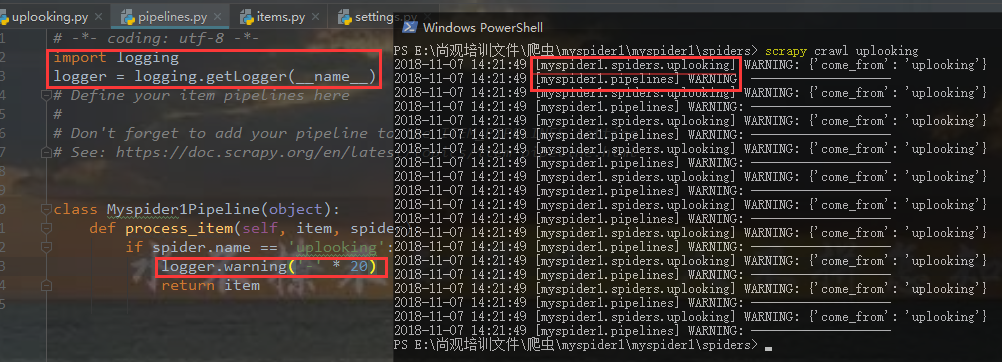
如何保存日志信息
发现运行后没有任何输出

项目中多了log.log日志文件
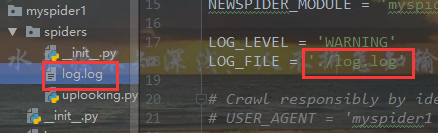
打开log.log日志文件即日志信息

items类型对象
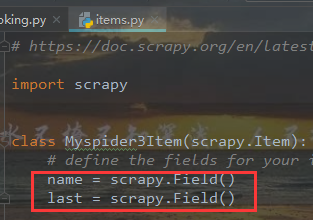
在items文件中声明了name、last的键在爬虫文件中声明即可用

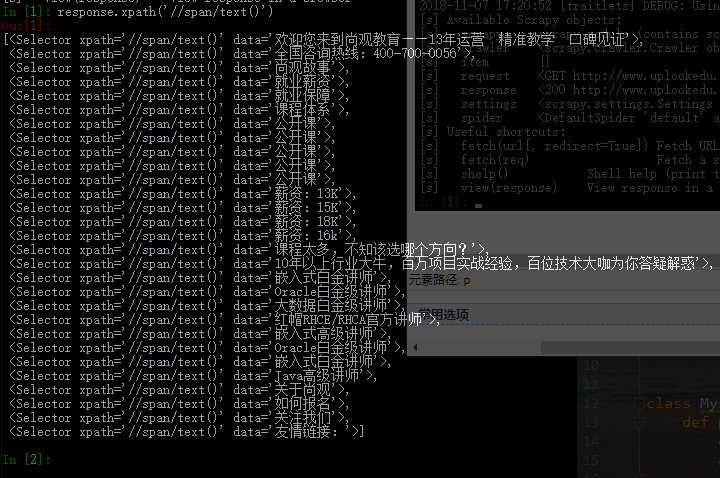
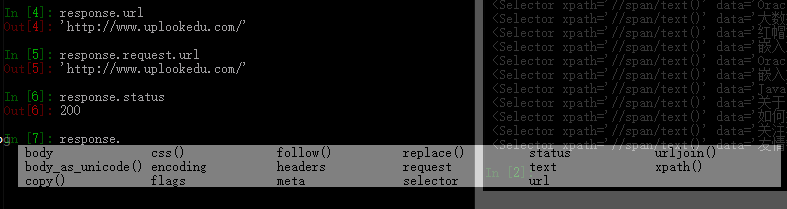
scrapy shell 用法
scrapy shell + 网址 会进入一个ipython可以测试response 如:

模仿浏览器
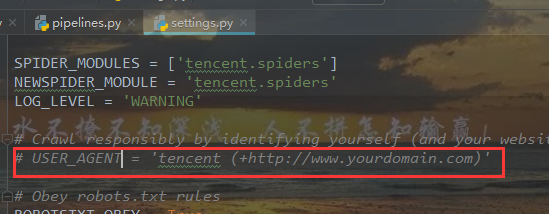
改为自己浏览器的user_agent信息

更改遵守robots规则
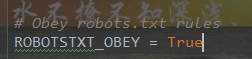
将True改为False
提取下一页url: scrapy.Request(url, callback)用来获取网页里的地址
callback:指定由那个函数去处理
分布式爬虫:
1.多台机器爬到的数据不能重复
2.多台机器爬到的数据不能丢失
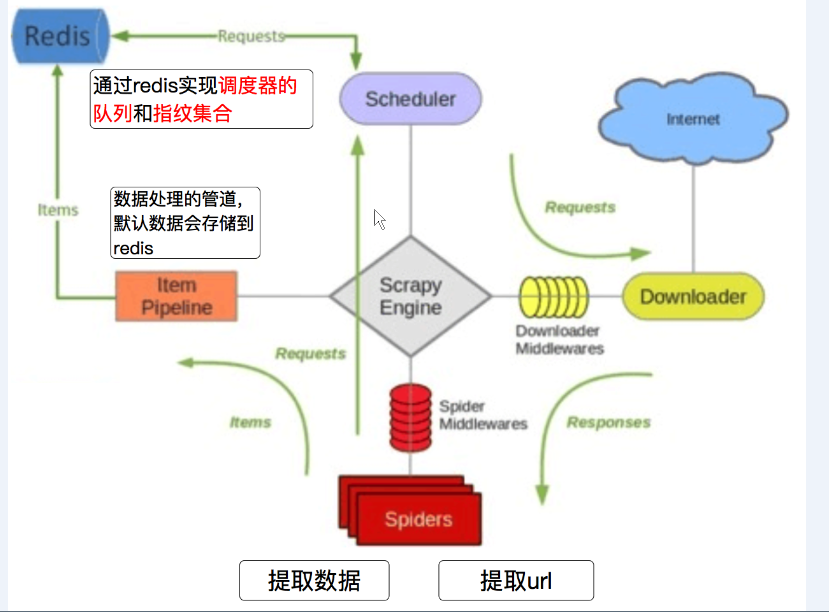
1.redis是什么?
Redis是一个开源的、内存数据库,他可以用作数据库、缓存、消息中间件。它支持多种数据类型的数据结构,如字符串、哈希、列表、集合、有序集合(可能存在数据丢失)
redis安装 Ubuntu: sudo apt-get install redis-server Centos:sudo yum install redis-server
检测redis状态
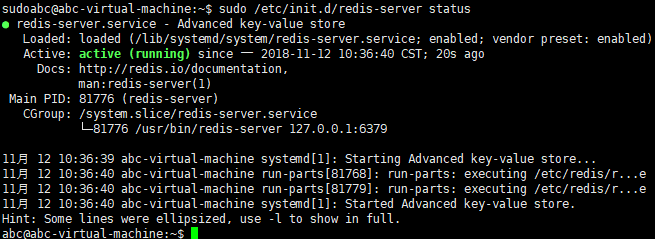
redis服务的开启:sudo /etc/init.d/redis-server start
重启:sudo /etc/init.d/redis-server restart
关闭:sudo /etc/init.d/redis-server stop
redis连接客户端:redis-cli
redis远程连接客户端:redis-cli -h<hostname> -p <port>(默认6379)
redis常用命令:
选择数据库:select 1 (第一个数据库为0 ,默认16个数据库,可修改配置文件修改数据库个数且个数没有上限)

查看数据库里的内容:keys *
向数据库加列表:lpush mylist a b c d (数据可重复)
查看列表数据:lrange mylist 0 -1

查看列表元素个数:llen mylist
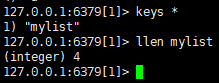
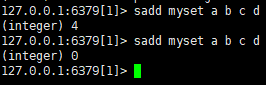
向set中加数据:sadd myset a b c d(不能重复,无序)
查看set中的数据:smembers myset

查看set中的元素个数:scard myset

向有序zset中添加数据:zadd myzset 1 a 2 b 3 c 4 d

查看zset编号和数据:zrange myzset 0 -1 withscores
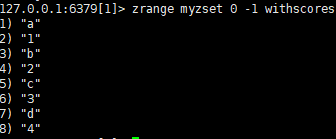
查看zset数据
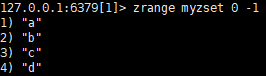
改变编号 如改变a的编号:

统计zset元素的个数zcard myzset

删除当前数据库:flushdb
清楚所有数据库:flushall
安装scrapy-redis
sudo pip install scrapy_redis
下载scrapy-redis例子:git clone https://github.com/rolando/scrapy-redis.git
setting.py中:
# 去重
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 调度器内容持久化
SCHEDULER_PERSIST = True
ITEM_PIPELINES = {
'example.pipelines.ExamplePipeline': 300,
# 负责把数据存储到redis数据库里
'scrapy_redis.pipelines.RedisPipeline': 400,
}
最后需把redis加上

序列化:把一个类的对象变成字符串最后保存到文件
反序列化:保存到文件的对象是字符串格式 --> 读取字符串 --> 对象
注:后台打印的数据较杂乱,我只想要自己爬到的东西怎么办?
第一步:
setting.py中加 LOG_LEVEL = 'WARNING'
这句代码会将不必要的数据屏蔽,屏蔽的数据如下:
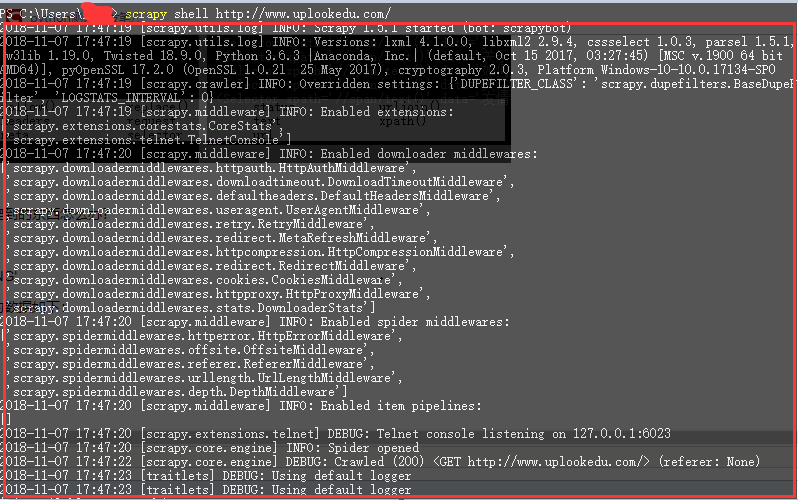
第二步:
然而现在还不是最简洁的,还有杂项。这样做,将response.xpath('*********')变成response.xpath('*********').extract()
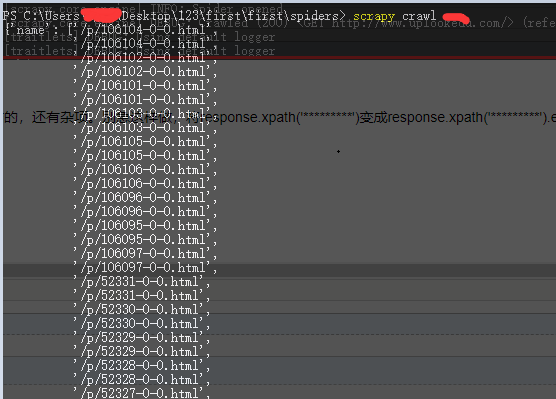
怎么样是不是你想要的。
Scrapy详解的更多相关文章
- 爬虫之Scrapy详解
性能相关 在编写爬虫时,性能的消耗主要在IO请求中,当单进程单线程模式下请求URL时必然会引起等待,从而使得请求整体变慢. import requests def fetch_async(url): ...
- 【图文详解】scrapy爬虫与动态页面——爬取拉勾网职位信息(2)
上次挖了一个坑,今天终于填上了,还记得之前我们做的拉勾爬虫吗?那时我们实现了一页的爬取,今天让我们再接再厉,实现多页爬取,顺便实现职位和公司的关键词搜索功能. 之前的内容就不再介绍了,不熟悉的请一定要 ...
- 【图文详解】scrapy安装与真的快速上手——爬取豆瓣9分榜单
写在开头 现在scrapy的安装教程都明显过时了,随便一搜都是要你安装一大堆的依赖,什么装python(如果别人连python都没装,为什么要学scrapy….)wisted, zope interf ...
- 全网最全的Windows下Anaconda2 / Anaconda3里正确下载安装爬虫框架Scrapy(离线方式和在线方式)(图文详解)
不多说,直接上干货! 参考博客 全网最全的Windows下Anaconda2 / Anaconda3里正确下载安装OpenCV(离线方式和在线方式)(图文详解) 第一步:首先,提示升级下pip 第二步 ...
- scrapy (三)各部分意义及框架示意图详解
一.框架示意图 Scrapy由 Python 编写,是一个快速.高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy用途广泛,可以用于数据挖掘.监测和自动化测试 ...
- 第三百五十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy信号详解
第三百五十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy信号详解 信号一般使用信号分发器dispatcher.connect(),来设置信号,和信号触发函数,当捕获到信号时执行 ...
- 网络爬虫之scrapy框架详解
twisted介绍 Twisted是用Python实现的基于事件驱动的网络引擎框架,scrapy正是依赖于twisted, 它是基于事件循环的异步非阻塞网络框架,可以实现爬虫的并发. twisted是 ...
- 转 Scrapy笔记(5)- Item详解
Item是保存结构数据的地方,Scrapy可以将解析结果以字典形式返回,但是Python中字典缺少结构,在大型爬虫系统中很不方便. Item提供了类字典的API,并且可以很方便的声明字段,很多Scra ...
- Scrapy框架的命令行详解【转】
Scrapy框架的命令行详解 请给作者点赞 --> 原文链接 这篇文章主要是对的scrapy命令行使用的一个介绍 创建爬虫项目 scrapy startproject 项目名例子如下: loca ...
随机推荐
- python 试题
1.现有两元祖 (('a'),('b'),('c'),('d') ) ,请使用Python中的匿名函数生成列表 [ {'a':'c'},{'c':'d'}] 答案:v = list(map(lambd ...
- js小笔记
1.let ,const,var 区别 let:块级作用域,if,for,用完就不存在了. const:用来定义常量. var: 声明的变量在它所声明的整个函数都是可见的. 2.==和===的区别 1 ...
- VB封装的WebSocket模块,拿来即用
一共就下面的两个模块,调用只使用到mWSProtocol模块,所有调用函数功能简单介绍一下: 建立连接后就开始握手,服务端用Handshake()验证,如果是客户端自己发送握手封包接收数据,先用Ana ...
- python学习:条件语句if、else
条件语句: 1.if...else...; 2.if...elif...esle 举例: 1.if...else... “age_of_princal = 56 guess_age = int(i ...
- HTML5_canvas_线性渐变
canvas 线性渐变 var linearG = pen.createLinearGradient(startX, startY, endX, endY); 两点的连线,决定了渐变的方向,和区间 v ...
- 用ImageJ快速分析和处理图像
ImageJ是一款由美国国立卫生研究院(NIH)开发的软件,原名NIH Image,适用于McIntosh.Windows和Linux等系统.ImageJ旨在对图像进行更好的分析和处理,可以下载或在线 ...
- MyCP-实现文件的复制以及进制转换
MyCP 一.设计思路 确定MyCP的要求 根据需求可知MyCP需要实现类似Linux下cp XXX1 XXX2的功能,且需要支持两个参数: java MyCP -tx XXX1.txt XXX2.b ...
- StarUML[3.1.0]官方安装破解版[app.asar]
StarUml 3.1.0 自注册破解版 安装完毕在注册界面随便输入一个 License 即可. 安装包方式可以选择从官方下,如果下载过慢,也可以选择分享包中的原版安装文件: 不放心的可以去校验MD5 ...
- oo第二单元作业总结
oo第二单元博客总结 在第一单元求导结束后,迎来了第二单元的多线程电梯的问题,在本单元前两次作业中个人主要应用两个线程,采用“生产者-消费者”模式和共享数据变量的方式解决问题.在第三次作业中加入多个电 ...
- HMAC-SHA256 签名方法各个语音的实现方式之前端JavaScriptes6
sha256和16进制输出,网上很多种后端的验证方法,几乎没有前端的,所以自己写了个,希望给类似需求的人一个帮助,适用场景 腾讯云接口鉴权 v3签名 npm install sha256npm ins ...