YARN简述
YARN(Yet Another Resource Negotiator)是Hadoop的集群资源管理系统。YARN提供请求和使用集群资源的API,但这些API很少直接用于用户代码。相反,用户代码中用的是分布式计算框架提供的更高层API,这些API建立在YARN之上且向用户隐藏了资源管理细节。
一、YARN应用运行机制
1、运行机制
YARN通过两类长期运行的守护进程提供自己的核心服务:管理集群上资源使用的资源管理器(resource manager)、运行在集群中所有节点上且能够启动和监控容器(container)的节点管理器(node manager)。容器用于执行特定应用程序的进程,每个容器都有资源限制(内存、CPU等)。一个容器可以是一个Unix进程,也可以是一个Linux cgroup,取决于YARN的配置。
YARN应用运行机制示意图如下:
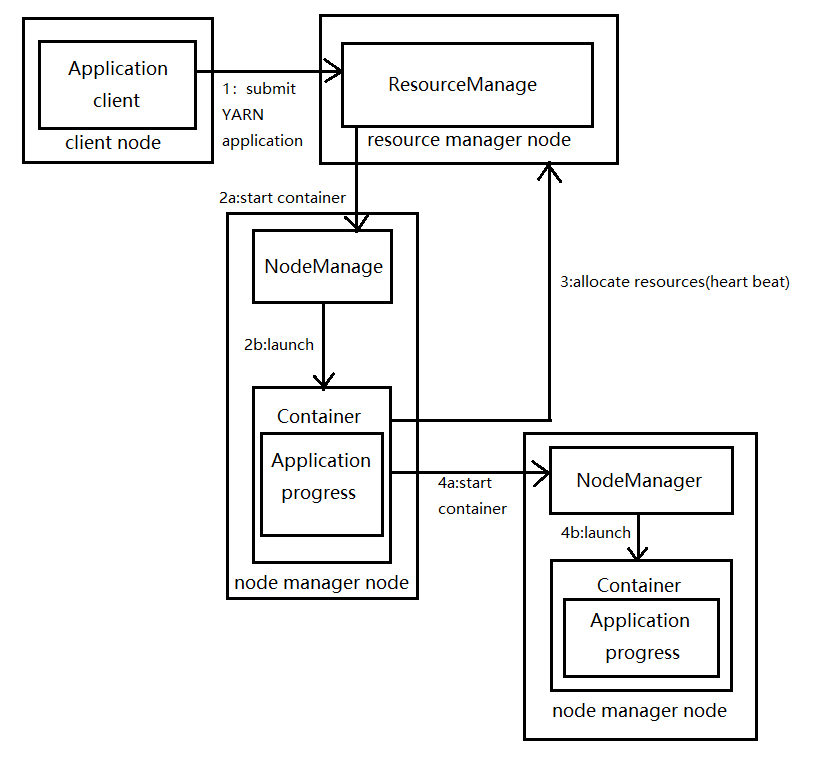
首先,客户端联系资源管理器,要求它运行一个application master进程(1)。然后,资源管理器找到一个能够在容器中启动application master的节点管理器(2a & 2b)。application master运行起来后做什么依赖于应用本身。可能是在所处的容器中简单地运行一个计算,并将结果返回给客户端;或是向资源管理器请求更多的容器(3),以用于运行一个分布式计算(4a & 4b)。
YARN本身不会为应用的各部分(客户端、master和进程)彼此间通信提供任何手段。大多数重要的YARN应用使用某种形式的远程通信机制来向客户端传递状态更新和返回结果,但是这些通信机制都是专属于各应用的。
2、资源请求
YARN有一个灵活的资源请求模型。当请求多个容器时,可以指定每个容器需要的计算机资源数量(内存和CPU),还可以指定对容器的本地限制要求。YARN允许一个应用为所申请的容器指定本地限制。本地限制可用于申请位于指定节点或机架,或集群中任何位置的容器。
有时本地限制无法被满足,这种情况下要么不分配资源,或者可选择放松限制。例如,一个节点由于已运行了别的容器而无法再启动新的容器,这时如果有应用请求该节点,则YARN将尝试在同一机架中的其他节点上启动一个容器,如果还不行,则会尝试集群中的任意一个节点。
YARN应用可以在运行中的任意时刻提出资源申请。例如,可以在最开始提出所有的请求,或者为了满足不断变化的应用需要,采取更为动态的方式在需要更多资源时提出请求。Spark采用第一种方式,在集群上启动固定数量的执行器;MapReduce则分两步走,在最开始的时候申请map任务容器,reduce人去容器的启用则放在后期。
3、YARN三种模型
YARN应用生命周期差异性很大,所以按照应用到用户运行的作业之间的映射关系对应用分类更有意义。
① 一个用户作业对应一个应用(MapReduce);
② 作业的每个工作流或每个用户对话对应一个应用(Spark);
③ 多个用户共享一个长期运行的应用,作为一种协调者的角色运行(Apache Slider、Impala)。
二、YARN与MapReduce 1相比
1、组成
MapReduce 1中,有两类守护进程控制着作业执行过程:一个jobtracker及一个或多个tasktracker。jobtracker通过调度tasktracker上运行的任务来协调所有运行在系统上的作业。tasktracker在运行任务的同时将运行进度报告发送给jobtracker,jobtracker由此记录每项作业任务的整体进度情况。如果其中一个任务失败,jobtracker可以在任何一个tasktracker节点上重新调度该任务。
MapReduce 1和YARN组成比较如下:
|
MapReduce 1 |
YARN |
|
Jobtracker |
资源管理器、application master、时间轴服务器 |
|
TaskTracker |
节点管理器 |
|
Slot |
容器 |
2、可扩展性
YARN可以在更大规模的集群上运行。由于jobtracker必须同时管理作业任务和任务,当节点数达到4000、任务数达到40000时,MapReduce 1会遇到可扩展性瓶颈。YARN利用资源管理器和application master分离的架构优点克服了这个局限性,可以扩展到面向将近10000个节点和100000个任务。
3、利用率
MapReduce 1中,每个tasktracker都配置有若干固定长度的slot,这些slot时静态分配的,在配置的时候就被划分为map slot和reduce slot。一个map slot仅能用于运行一个map任务,同样,一个reduce slot仅能用于运行一个reduce任务。
YARN上,一个节点管理器管理一个资源池,而不是指定的固定数目的slot。YARN上运行的MapReduce不会出现由于集群中仅有map slot可用导致reduce任务必须等待的情况。YARN中的资源时精细化管理的,这样一个应用能够按需请求资源,而不是请求一个不可分割的、对于特定的任务而言可能会太大或太小的slot。
4、多租户
YARN向MapReduce以外的其他类型的分布式应用开放了Hadoop。用户甚至可以在同一个YARN集群上运行不同版本的MapReduce。
三、YARN中的调度
1、调度选项
YARN调度器的工作是根据既定策略为应用分配资源。YARN中有三种调度器可用:FIFO调度器、容量调度器、公平调度器。
FIFO调度器将应用放置在一个队列中,然后按照提交的顺序运行应用,优点是简单易懂不需要任何配置,但是不适合共享集群。
使用容量调度器时,一个独立的专门队列保证小作业一提交就可以启动,由于队列容量是为那个队列中的作业所保留的,因此这种策略是以整个集群的利用率为代价的。
使用公平调度器时,不需要预留一定量的资源,因为调度器会在所有运行的作业之间动态平衡资源,既得到了较高的集群利用率,又能保证小作业能及时完成。
2、延迟调度
在一个繁忙的集群上,如果一个应用请求某个节点,那么极有可能此时有其他容器正在该节点上运行。此时如果等待一小段时间,能够增加在所请求的节点上分配到一个容器的机会,从而可以提高集群的效率。这个特性称为延迟调度。容量调度器和公平调度器都支持延迟调度。
当使用延迟调度时,调度器不会简单的使用它收到的第一个调度机会,而是等待、设定的最大数目的调度机会发生,然后才放松本地性限制并接收下一个调度机会。
3、主导资源公平性
YARN中调度器解决公平性的思路是,观察每个用户的主导资源,并将其作为对集群资源使用的一个度量(称为主导资源公平性 DRF),默认情况下不用DRF。
YARN简述的更多相关文章
- Hadoop YARN学习之组件功能简述(3)
Hadoop YARN学习之组件功能简述(3) 1. YARN的三大组件功能简述: ResourceManager(RM)是集群的资源的仲裁者, 它有两部分:一个可插拔的调度器和一个Applicati ...
- Hadoop YARN学习之Hadoop框架演进历史简述
Hadoop YARN学习之Hadoop框架演进历史简述(1) 1. Hadoop在其发展的过程中经历了多个阶段: 阶段0:Ad Hoc集群时代 标志着Hadoop的起源,集群以Ad Hoc.单用户方 ...
- Hadoop YARN 的工作流程简述
1.Client 向 YARN 提交应用程序,其中包括 ApplicationMaster 程序及启动 ApplicationMaster 命令2.ResourceManager 为该 Applica ...
- Spark on Yarn
Spark on Yarn 1. Spark on Yarn模式优点 与其他计算框架共享集群资源(eg.Spark框架与MapReduce框架同时运行,如果不用Yarn进行资源分配,MapReduce ...
- Spark简述及基本架构
Spark简述 Spark发源于美国加州大学伯克利分校AMPLab的集群计算平台.它立足 于内存计算.从多迭代批量处理出发,兼收并蓄数据仓库.流处理和图计算等多种计算范式. 特点: 1.轻 Spark ...
- Using YARN with Cgroups testing in sparkml cluster
部署服务器: sparkml 集群 ########### sparkml ########## sparkml-node1 # yarn resource manager sparkml-node2 ...
- HDFS 架构简述
HDFS 架构简述 Hadoop分布式文件系统(HDFS)是一个分布式的文件系统,运行在廉价的硬件上.它与现有的分布式文件系统有很多相似之处.然而与其他的分布式文件系统的差异也是显着的.HDFS是高容 ...
- flink hadoop yarn
新一代大数据处理引擎 Apache Flink https://www.ibm.com/developerworks/cn/opensource/os-cn-apache-flink/ 新一代大数据处 ...
- react基础课程一简述JSX及目录关系
简述JSX及目录关系 简述:它被称为JSX,它是JavaScript的语法扩展,JSX是一种模板语言,但它具有JavaScript的全部功能.所以学习jsx还是需要学习基础的javaScript的. ...
随机推荐
- 微信小程序scroll-view滚动一次多次触发的问题解决方案
最近使用微信小程序开发的时候,需要用scroll-view的bindscrolltolower事件,控制加载下一页的内容.但是发现在ios里,下拉滚动一次,事件触发两次,导致重复加载数据. 经过百度和 ...
- shell 统计字符串 字符个数
统计“abbc”中“b”的个数 1:awknum=`echo abbc | awk -F"b" '{print NF-1}'` 2:trnum=`echo abbc | tr -c ...
- 2019微软Power BI 每月功能更新系列——Power BI 4月版本功能完整解读
Power BI4月份的更新对整个产品进行了重大更新.此版本增加了基于DAX表达式定义视觉效果标题和按钮URL的功能.本月Power BI也新增了许多新的连接器,现在可以使用几种预览连接器,包括Pow ...
- Python 列表(List)
Python 列表(List) 序列是Python中最基本的数据结构.序列中的每个元素都分配一个数字 - 它的位置,或索引,第一个索引是0,第二个索引是1,依此类推. Python有6个序列的内置类型 ...
- echarts 滚动条 缩放
// 初始化是否需要展示滚动条,与初始显示的数据数(总数据数的百分比) var isShowScroll = false;// 是否显示滚动条,默认false不显示 var dataZoom_end; ...
- ES6模板字符串之标签模板
首先,模板字符串和标签模板是两个东西. 标签模板不是模板,而是函数调用的一种特殊形式.“标签”指的就是函数,紧跟在后面的模板字符串就是它的参数. 但是,如果模板字符串中有变量,就不再是简单的调用了,而 ...
- LeetCode第一次刷题
感觉自身编程水平还是差很多,所以刷刷题 LeetCode貌似是一个用的人比较多的题库,下面是第一题 给数组和目标和求需要元素的下标 public class Solution { public int ...
- Error: “app_name” is not translated in af
in values/strings.xml "app_name" is not translated in af, am, ar, be, bg, ca, cs, da, de ...
- 软件测试2019:第四次作业—— 性能测试(含JMeter实验)
题目:性能测试练习 一.回答下述问题: 性能测试有几种类型,它们之间什么关系? 性能测试根据不同测试目的可以分为以下类: (1)性能验证测试 (2)性能基准测试 (3)性能规划测试 (4)容量测试 渗 ...
- 搭建Jmeter + Grafana + InfluxDB性能测试监控环境
背景 Jmeter原生的实时监控每半分钟收集一次数据,只能在Linux控制台查看日志输出,界面看起来不直观,图表报告只能等压测结束后才能生成.如下图为jmeter在Linux下运行的实时日志: 那么如 ...