学习笔记:Spark Streaming的核心
Spark Streaming的核心
1.核心概念
StreamingContext:要初始化Spark Streaming程序,必须创建一个StreamingContext对象,它是所有Spark StreamingContext功能的主要入口点。
一个StreamingContext对象可以由SparkConf对象来创建,需要指定Seconds。
import org.apache.spark._
import org.apache.spark.streaming._ val conf = new SparkConf().setAppName(appName).setMaster(master)
val ssc = new StreamingContext(conf, Seconds()) 注意点:batch interval可根据你的应用程序需求的延迟要去以及集群可用的资源情况来设置
一个StreamingContext对象也可以由已存在SparkContext对象来创建,需要指定Seconds。
import org.apache.spark.streaming._ val sc = ... // existing SparkContext
val ssc = new StreamingContext(sc, Seconds())
为什么可以通过SparkConf或是SparkContext对象创建StreamingContext对象呢?
#通过阅读源码中StreamingContext.scala去了解
class StreamingContext private[streaming] (
sc_ : SparkContext,
cp_ : Checkpoint,
batchDur_ : Duration #多久执行一次
) extends Logging{ #this是附属构造器
def this(sparkContext: SparkContext, batchDuration: Duration)={
this(sparkContext, null, batchDuration)
}
#传进一个SparkConf,调用StreamingContext.createNewSparkContext返回的是一个sparkContext,最后调用了上面this这个附属构造器
def this(conf: SparkConf, batchDuration: Duration)={
this( StreamingContext.createNewSparkContext(conf),null,batchDuration)
}
一旦StreamingContext定义好之后,可用做以下事情:
- 通过input DStreams来定义输入源;如果要处理hdfs上文件,通过StreamingContext拿到一个输入的DStreams
- 通过对DStreams应用transformation和output操作来定义流计算
- 开始接收数据并使用streamingContext.start()处理它
- 等待使用streamingContext.awaitTermination()停止处理(手动或由于任何错误)
- 可以使用streamingContext.stop()手动停止处理
注意事项:
- 一旦streamingContext启动,就不能设置或是添加新的流计算
- 一旦streamingContext停止了,就不能重启它;
- 只能有一个streamingContext存活在JVM中
- StreamingContext上的stop()也会停止SparkContext。 要仅停止StreamingContext,请将stop()的可选参数stopSparkContext设置为false。
- 只要在创建下一个StreamingContext之前停止前一个StreamingContext(不停止SparkContext),就可以重复使用SparkContext创建多个StreamingContexts
DStreams(Discretized Streams):是Spark Streaming提供的基本抽象,它表示持续化的数据流,可从输入数据流接收过来,也可以是输入流通过transform操作转成另一个Dstream;本质上,一个DStream代表这一系列连续的RDDs,DStream中每个RDD都包含来自特定时间间隔(batch interval)的数据。

对DStream操作算子,比如map/flatMap,其实底层会被翻译为对DStream中每个RDD都做相同的操作,因为一个DStream是由不同批次的RDD所构成的。

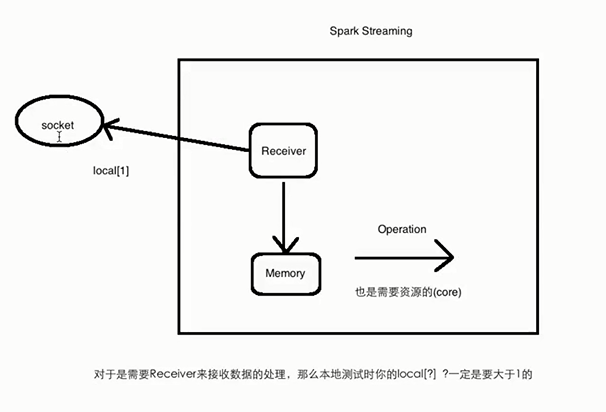
InputDStream:是一个DStream,表示输入数据的流是从源头接收过来的;每个input DStream都需要关联一个receivers对象,receivers对象从源头接收数据并将该数据存储在Spark的内存中以供后期进行处理,但是InputDStream如果是文件系统,就不需要关联receivers对象,因为数据已经存储在文件系统上了不需要receivers对象去接收数据,直接通过文件系统的api访问返回的就是一个DStream。
Spark Streaming中提供了两种内置的流源:
基本来源:StreamingContext API中直接提供的源。 示例:文件系统和套接字连接。
高级资源:Kafka,Flume,Kinesis等资源可通过额外的实用程序类获得。 这些需要链接到额外的依赖项,如链接部分所述。
2.Transformations Operations: 与RDD类似,转换允许修改来自输入DStream的数据。 DStreams支持普通Spark RDD上可用的许多转换。
一些常见的Transformations Operations有:map,flatMap,filter,union,count等等
3.Output Operations:该操作允许将DStream的数据推送到外部系统,如数据库或文件系统。 由于输出操作实际上允许外部系统使用转换后的数据,因此它们会触发所有DStream转换的实际执行(类似于RDD的操作)。 目前,定义了以下output operations:print,saveAsTextFile, foreachRDD等等
4.案例实战
案例一:Spark Streaming处理socket数据
/**
*Spark Streaming 处理Socket数据
* 测试,使用nc -lk 9999
*/ object NetworkWordCount{ def main(args:Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster('local[2]').setAppName('NetworkWordCount')
#创建StreamingContext需要SparkConf和batch interval
val ssc = new StreamingContext(sparkConf,Seconds())
val lines = ssc.socketTextStream('localhost',)
val result = lines.flarMap(_.split(" ")).map((_,)).reduceByKey(_+_)
result.print()
ssc.start()
ssc.awaitTermination()
}
}
对于需要Receiver接收的数据的处理,本地测试时local[?]为什么要大于1?
因为receiver需要一个线程来接收数据,后面的operation也需要线程来处理。
案例二:Spark Streaming处理HDFS文件数据
/**
*Spark Streaming 处理文件系统(local,hdfs)数据
*/ object FileWordCount{ def main(args:Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster('local').setAppName('FileWordCount')
#创建StreamingContext需要SparkConf和batch interval
val ssc = new StreamingContext(sparkConf,Seconds())
val lines = ssc.textFileStream("file://Users/rocky/data/imooc/ss/") #监控指定文件夹下数据
val result = lines.flarMap(_.split(" ")).map((_,)).reduceByKey(_+_)
result.print()
ssc.start()
ssc.awaitTermination()
}
}
#注意事项:监控文件夹下的添加的文件需要相同的格式;对于递归的子目录情况是不支持的;不能在已有文件中添加内容,添加了也不会被处理,因为处理过的文件将不会再被处理文件必须以原始性方式创建
学习笔记:Spark Streaming的核心的更多相关文章
- Spark学习笔记——Spark Streaming
许多应用需要即时处理收到的数据,例如用来实时追踪页面访问统计的应用.训练机器学习模型的应用, 还有自动检测异常的应用.Spark Streaming 是 Spark 为这些应用而设计的模型.它允许用户 ...
- Spark学习之Spark Streaming(9)
Spark学习之Spark Streaming(9) 1. Spark Streaming允许用户使用一套和批处理非常接近的API来编写流式计算应用,这就可以大量重用批处理应用的技术甚至代码. 2. ...
- Spark 学习笔记之 Streaming和Kafka Direct
Streaming和Kafka Direct: Spark version: 2.2.0 Scala version: 2.11 Kafka version: 0.11.0.0 Note: 最新版本感 ...
- Spark 学习笔记之 Streaming Window
Streaming Window: 上图意思:每隔2秒统计前3秒的数据 slideDuration: 2 windowDuration: 3 例子: import org.apache.kafka.c ...
- Spark学习之Spark Streaming
一.简介 许多应用需要即时处理收到的数据,例如用来实时追踪页面访问统计的应用.训练机器学习模型的应用,还有自动检测异常的应用.Spark Streaming 是 Spark 为这些应用而设计的模型.它 ...
- 大数据学习笔记——Spark工作机制以及API详解
Spark工作机制以及API详解 本篇文章将会承接上篇关于如何部署Spark分布式集群的博客,会先对RDD编程中常见的API进行一个整理,接着再结合源代码以及注释详细地解读spark的作业提交流程,调 ...
- Spark学习(4) Spark Streaming
什么是Spark Streaming Spark Streaming类似于Apache Storm,用于流式数据的处理 Spark Streaming有高吞吐量和容错能力强等特点.Spark Stre ...
- bootstrap学习笔记<八>(bootstrap核心布局风格——栅格系统)
栅格系统(bootstrap的核心之一,也是bootstrap的主要布局风格) 栅格系统是对原有div布局的升级版.打破了传统div模式只能纵向垂直排列的弊端,大大提高了页面布局的速度和效果,也很好的 ...
- Java基础学习笔记二十三 Java核心语法之反射
类加载器 类的加载 当程序要使用某个类时,如果该类还未被加载到内存中,则系统会通过加载,链接,初始化三步来实现对这个类进行初始化. 加载就是指将class文件读入内存,并为之创建一个Class对象.任 ...
随机推荐
- vue-cli脚手架build目录中的webpack.prod.conf.js配置文件
// 下面是引入nodejs的路径模块 var path = require('path') // 下面是utils工具配置文件,主要用来处理css类文件的loader var utils = req ...
- Struts 2中如何解决中文乱码问题?
在配置文件中定义如下常量值配置: <constant name=”struts.i18n.encoding” value=”UTF-8”/> 注意:只能解决post请求的乱码问题,针对ge ...
- angular 组件学习-组件内属性绑定
#组件内的属性(元素的属性)绑定(property binding) 应用场景:通过改变DOM元素的属性,动态显示/隐藏一个元素 知识点:HTML 属性与DOM属性的区别 改变HTMl属性,浏览器需要 ...
- BZOJ2662 [BeiJing wc2012]冻结
网上的题解都是分层图+spfa或者dijkstra 我觉得dijk太难写了,懒得写,看了一下数据范围$N=50$,这显然是出题人勾引人犯罪 我决定使用floyd的做法,令$f[i][j][t](k)$ ...
- freemarker导出word档
1.word另存为xml:2.xml文件后缀名改成ftl:3.编写完整json字符串备用:4.修改ftl中动态字段为json中对应字段名:5.编写java代码自动生成word文件:(注意:换行用< ...
- Android向通讯录添加联系人的一般方法
Android向通讯录添加联系人的一般方法 以一个简单的例子加以说明,记得需要相应的权限: 测试代码,关键的内容就在add函数里面. package zhangphil.demo; import an ...
- Java final类&所有构造方法均为private的类(类型说明符&访问控制符)
1. final是类型说明符,表示关闭继承,即final类不能有子类: 但final类可能可以在类外创建对象(即final类的构造方法可以不是private型): 在同一包中时,可以在任何另外一个类中 ...
- python 多进程多线程的对比
link:http://www.cnblogs.com/whatisfantasy/p/6440585.html mark一下,挺详细
- d3js可视化策略
d3js是数据驱动图形的思路.基本可以这么理解,有什么样的图形,后面基本就有类似结构的数据.大概思路步骤如下: 一.适配数据格式 这一步主要是为第二部服务,第一步的结果作为第二部的入参. 比如,画层级 ...
- js缓存问题的解决