synchronized 与 volatile 原理 —— 内存屏障的重要实践
单例模式的双重校验锁的实现:
第一种:
private static Singleton _instance;
public static synchronized Singleton getInstance() {
if (_instance == null) {
_instance = new Singleton();
}
return _instance;
}
在 static 方法上加 synchronized,等同于将整个类锁住。每当通过此静态方法得到该对象时,就需要同步。
如果是实例方法(不是 static),那个 synchronized 锁只会对同一个对象多次调用该方法才会同步,不同的对象(实例)调用则不保证同步性。
if (_instance == null) {
_instance = new Singleton();
}
第二种:
public class Singleton {
//volatile 防止延迟初始化
private volatile static Singleton instance;
public static Singleton getInstance() {
if (instance == null) { //判断是否已有单例生成
synchronized (Singleton.class) { //获取单例的方法是static方法,所以锁的是 .class对象
if (instance == null) //判断 是否在第一重判断与 synchronized 语句之间的状态,已经被另一个 synchronized 块 赋值
instance = new Singleton();//instance为volatile,现在没问题了
}
}
return instance;
}
}
判断是否有单例生成并不需要同步锁,只有在第一次单例类实例创建时需要同步锁。并且在同步锁中赋值时,还需再检验一次。
这里使用 volatile 的目的是:避免重排序。直接原因也就是 instance = new Singleton(); 初始化(初始化本身是原子操作)一个对象并使另一个引用指向他 这个过程可分为多个步骤:
- 1. 分配内存空间,
- 2. 初始化默认值(区别于构造器方法的初始化),
- 3. 初始化对象,
- 4. 将引用与对应的变量绑定。
如果最后 2步替换顺序,1243 执行。则导致了可能会出现(怎样出现?)引用指向了对象并未初始化好的那块堆内存。
注意:这里的 synchronized 不像第一种是直接在整个方法上添加的,而是在内部的代码块上添加的,也就是说该方法的第一重判断是不包括在 synchronized 里面的,并且返回语句也不在 synchronized 中。当线程一按照1243 的执行顺序,首次访问到 步骤 4时。线程二异步执行到第一重判断时,它判断不为空,获取到了一个未初始化好的内存。线程一继续往下执行,它获取到了一个真实的初始化的对象。
拓展:
线程安全:多条线程同时工作的情况下,通过运用线程锁,原子操作等方法避免多条线程因为同时访问同一快内存造成的数据错误或冲突。
原子性:解决的是某一操作不会被线程调度机制打断,中间不会有任何context switch (切 换到另一个线程)。即保证当前为原子操作。
有序性:解决的是 cpu 进行指令重排序
可见性:解决的是工作内存/寄存器 对主存的不可见
内存屏障:为了解决写缓冲器和无效化队列带来的有序性和可见性问题,我们引入了内存屏障。内存屏障是被插入两个CPU指令之间的一种指令,用来禁止处理器指令发生重排序(像屏障一样),从而保障有序性的。另外,为了达到屏障的效果,它也会使处理器写入、读取值之前,将写缓冲器的值写入高速缓存,清空无效队列,从而“附带”的保障了可见性。
八 种原子操作:
lock(锁定):作用于主内存中的变量,它把一个变量标识为一个线程独占的状态;
unlock(解锁):作用于主内存中的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定
read(读取):作用于主内存的变量,它把一个变量的值从主内存传输到线程的工作内存中,以便后面的load动作使用;
load(载入):作用于工作内存中的变量,它把read操作从主内存中得到的变量值放入工作内存中的变量副本
use(使用):作用于工作内存中的变量,它把工作内存中一个变量的值传递给执行引擎,每当虚拟机遇到一个需要使用到变量的值的字节码指令时将会执行这个操作;
assign(赋值):作用于工作内存中的变量,它把一个从执行引擎接收到的值赋给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作;
store(存储):作用于工作内存的变量,它把工作内存中一个变量的值传送给主内存中以便随后的write操作使用;
write(操作):作用于主内存的变量,它把store操作从工作内存中得到的变量的值放入主内存的变量中。
LoadLoad屏障:
对于这样的语句 Load1; LoadLoad; Load2,在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
StoreStore屏障:
对于这样的语句 Store1; StoreStore; Store2,在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。
LoadStore屏障:
对于这样的语句Load1; LoadStore; Store2,在Store2及后续写入操作被执行前,保证Load1要读取的数据被读取完毕。
StoreLoad屏障:
对于这样的语句Store1; StoreLoad; Load2,在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。它的开销是四种屏障中最大的(冲刷写缓冲器,清空无效化队列)。在大多数处理器的实现中,这个屏障是个万能屏障,兼具其它三种内存屏障的功能。
内存屏障分类
按照可见性保障来划分
内存屏障可分为:加载屏障(Load Barrier)和存储屏障(Store Barrier)。
加载屏障:StoreLoad屏障可充当加载屏障,作用是使用load 原子操作,刷新处理器缓存,即清空无效化队列,使处理器在读取共享变量时,先从主内存或其他处理器的高速缓存中读取相应变量,更新到自己的缓存中
存储屏障:StoreLoad屏障可充当存储屏障,作用是使用 store 原子操作,冲刷处理器缓存,即将写缓冲器内容写入高速缓存中,使处理器对共享变量的更新写入高速缓存或者主内存中
这两个屏障一起保证了数据在多处理器之间是可见的。按照有序性保障来划分
内存屏障分为:获取屏障(Acquire Barrier)和释放屏障(Release Barrier)。
获取屏障:相当于LoadLoad屏障与LoadStore屏障的组合。在读操作后插入,禁止该读操作与其后的任何读写操作发生重排序;
释放屏障:相当于LoadStore屏障与StoreStore屏障的组合。在一个写操作之前插入,禁止该写操作与其前面的任何读写操作发生重排序。
这两个屏障一起保证了临界区中的任何读写操作不可能被重排序到临界区之外。
1. Synchronized 底层原理(保证有序性,可见性,原子性与线程安全)
synchronized编译成字节码后,是通过monitorenter(lock原子操作抽象而来)和 monitorexit(unlock原子操作抽象而来)两个指令实现的,具体过程如下:
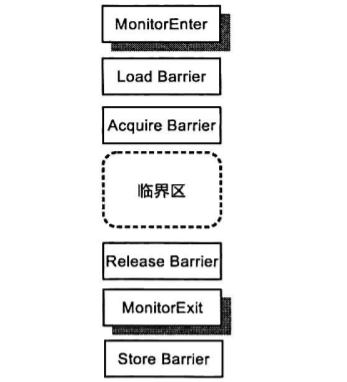
可以发现,synchronized底层通过获取屏障和释放屏障的配对使用保证有序性,加载屏障和存储屏障的配对使用保正可见性。最后又通过锁的排他性保障了原子性与线程安全。
2. Volatile 底层原理(保证有序性,可见性)
与 synchronized 类似,volatile 也是通过内存屏障来保证有序性与可见性,过程如下:
读操作:
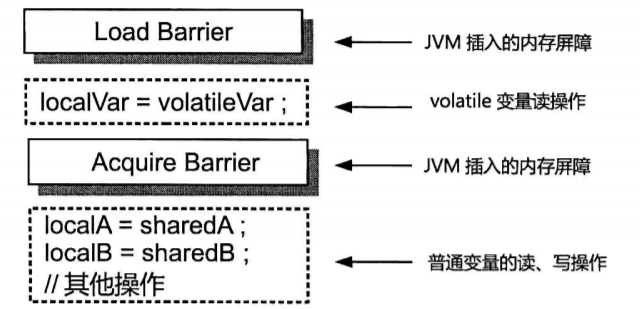
写操作:

二、数组与对象实例中的 volatile
针对的是引用,其含义是对象获数组的地址具有可见性,但是数组或对象内部的成员改变不具备可见性。这一点跟变量中 final 数组/对象 的用法是类似的,限定是引用地址。
关于 synchronized 的知识点
下列说法不正确的是()
A.当两个并发线程访问同一个对象object中的这个synchronized(this)同步代码块时,一个时间内只能有一个线程得到执行。
B.当一个线程访问object的一个synchronized(this)同步代码块时,另一个线程仍然可以访问该object中的非synchronized(this)同步代码块。
C.当一个线程访问object的一个synchronized(this)同步代码块时,其他线程对object中所有其它synchronized(this)同步代码块的访问不会被阻塞。
D.当一个线程访问object的一个synchronized(this)同步代码块时,它就获得了这个object的对象锁。结果,其它线程对该object对象所有同步代码部分的访问都被暂时阻塞。
答案:C,当一个线程访问object的一个synchronized(this)同步代码块时,其他线程对object中所有其它synchronized(this)同步代码块的访问将会被阻塞。
参考资料
https://blog.csdn.net/guyuealian/article/details/52525724
https://www.jianshu.com/p/43af2cc32f90
synchronized 与 volatile 原理 —— 内存屏障的重要实践的更多相关文章
- volatile 和 内存屏障
接下来看看volatile是如何解决上面两个问题的: 被volatile修饰的变量在编译成字节码文件时会多个lock指令,该指令在执行过程中会生成相应的内存屏障,以此来解决可见性跟重排序的问题. 内存 ...
- 【C#】通过一个案例 彻底了解 Volatile和 内存屏障
案例如下的.我个人理解是不会出现出现0,0的结果,但是很明显出现了. 说明对我对 Volatile\内存屏障\乱序排序的理解是不对. 今天就通过这个案例,理清这些概念. using System; u ...
- C和C++中的volatile、内存屏障和CPU缓存一致性协议MESI
目录 1. 前言2 2. 结论2 3. volatile应用场景3 4. 内存屏障(Memory Barrier)4 5. setjmp和longjmp4 1) 结果1(非优化编译:g++ -g -o ...
- volatile的内存屏障的坑
请看下面的代码并尝试猜测输出: 可能一看下面的代码你可能会放弃继续看了,但如果你想要彻底弄明白volatile,你需要耐心,下面的代码很简单! 在下面的代码中,我们定义了4个字段x,y,a和b,它们被 ...
- JUC源码学习笔记4——原子类,CAS,Volatile内存屏障,缓存伪共享与UnSafe相关方法
JUC源码学习笔记4--原子类,CAS,Volatile内存屏障,缓存伪共享与UnSafe相关方法 volatile的原理和内存屏障参考<Java并发编程的艺术> 原子类源码基于JDK8 ...
- volatile关键字?MESI协议?指令重排?内存屏障?这都是啥玩意
一.摘要 三级缓存,MESI缓存一致性协议,指令重排,内存屏障,JMM,volatile.单拿一个出来,想必大家对这些概念应该有一定了解.但是这些东西有什么必然的联系,或者他们之间究竟有什么前世今生想 ...
- java内存屏障
为什么会有内存屏障 每个CPU都会有自己的缓存(有的甚至L1,L2,L3),缓存的目的就是为了提高性能,避免每次都要向内存取.但是这样的弊端也很明显:不能实时的和内存发生信息交换,分在不同CPU执行的 ...
- 内存屏障在CPU、JVM、JDK中的实现
前言 内存屏障(英语:Memory barrier),也称内存栅栏,内存栅障,屏障指令等,是一类同步屏障指令,它使得 CPU 或编译器在对内存进行操作的时候, 严格按照一定的顺序来执行, 也就是说在内 ...
- java多线程系列(五)---synchronized ReentrantLock volatile Atomic 原理分析
java多线程系列(五)---synchronized ReentrantLock volatile Atomic 原理分析 前言:如有不正确的地方,还望指正. 目录 认识cpu.核心与线程 java ...
随机推荐
- P5300 [GXOI/GZOI2019]与或和
题目地址:P5300 [GXOI/GZOI2019]与或和 考虑按位计算贡献 对于 AND 运算,只有全 \(1\) 子矩阵才会有贡献 对于 OR 运算,所以非全 \(0\) 子矩阵均有贡献 如果求一 ...
- [转] golang中struct、json、map互相转化
一.Json和struct互换 (1)Json转struct例子: type People struct { Name string `json:"name_title"` Age ...
- jupyter4.4.0自定义目录
百度是有技巧的,现在百度的基本上都是2年前的帖子,对于最新的版本都不适用 对于jupyter自定义目录都是修改配置文件,这个对于jupyter4.4.0不适用: 1.在桌面创建jupyter-note ...
- hololens Vuforia新时期的开发注意事项
首先是导入的时候unity版本 HolotoolKit的版本 是否搭配.按照推荐的版本号去下载安装: 其次是在原本的相机的设置. View of field 大小设置为60,不然会造成页面的放大,然后 ...
- 【Git】Git提交代码的正确姿势
按此步骤基本没问题,中间有conflict,需要手动解决. 1.git stash 2.git pull 3.git stash pop 4.git add --xxx 5.git commit -m ...
- 手把手设计MyBatis
最近趁热打铁,研究了一下Mybatis.MyBatis框架的核心功能其实不难,无非就是动态代理和jdbc的操作,难的是写出来可扩展,高内聚,低耦合的规范的代码. 本文完成的Mybatis功能比较简单, ...
- CSV文件导入导mysql数据库
1.导入 基本语法: load data [low_priority] [local] infile 'file_name txt' [replace | ignore] into table tbl ...
- mycat+mysql集群:实现读写分离,分库分表
1.mycat文档:https://github.com/MyCATApache/Mycat-doc 官方网站:http://www.mycat.org.cn/ 2.mycat的优点: 配 ...
- C++智能指针剖析(上)std::auto_ptr与boost::scoped_ptr
1. 引入 C++语言中的动态内存分配没有自动回收机制,动态开辟的空间需要用户自己来维护,在出函数作用域或者程序正常退出前必须释放掉. 即程序员每次 new 出来的内存都要手动 delete,否则会造 ...
- 浅析布隆过滤器及实现demo
布隆过滤器 布隆过滤器(Bloom Filter)是一种概率空间高效的数据结构.它与hashmap非常相似,用于检索一个元素是否在一个集合中.它在检索元素是否存在时,能很好地取舍空间使用率与误报比例. ...