webRTC中音频相关的netEQ(三):存取包和延时计算
上篇(webRTC中音频相关的netEQ(二):数据结构)讲了netEQ里主要的数据结构,为理解netEQ的机制打好了基础。本篇主要讲MCU中从网络上收到的RTP包是怎么放进packet buffer和从packet buffer里取出来,以及网络延时值(optBufLevel)和抖动缓冲延时值(buffLevelFilt)的计算。先看RTP语音包是怎么放进packet buffer的。
前面说过把从网络收到的RTP包放进packet buffer时有个slot概念,每个slot里放一个包的属性(比如timestamp、sequence number等)和payload。Packet buffer初始化时把numPacketsInBuffer(已有的包个数)和insertPosition(下一个包放的位置)置成0,也把属性和payload置成合理的值(比如把payloadLengthBytes(payload长度)置成0,把payloadType(负载类型)置成-1)。当一个RTP包要放进packet buffer时,先要看packetbuffer是否为空(即numPacketsInBuffer是否为零)。如为空,直接把包放在slot 0的位置(把包的属性以及payload放到slot 0的位置上)。如不为空,insertPosition加1,先看这个slot上是否有包(标志是payloadLengthBytes是否为零,为零表示没包。当这个slot上的包被取走时payloadLengthBytes会被置为零)。如有包说明packet buffer 满了,需要reset(代码中叫flush)packet buffer,然后把当前包放在slot 0的位置(Packet buffer中能放的包个数是一个很大的值,通常不会放满)。如未满,则直接放在下一个slot上。下面举例说明。假设packet buffer最多可以放240个包,则slot范围是0—239,如下图。从网络上收到的第一个包会放在slot 0 的位置,第二个包放在slot1的位置,以此类推,第240个包会放在slot239的位置。当一个包从packet buffer取出时,相应slot就又被初始化了。当第241个包来时就又放到slot0 的位置。当包放进相应slot时要check这个slot里是否有包(标准是payloadLengthBytes是否为零),有包则说明packet buffer已满需要reset/flush,然后这个包放在slot0的位置。
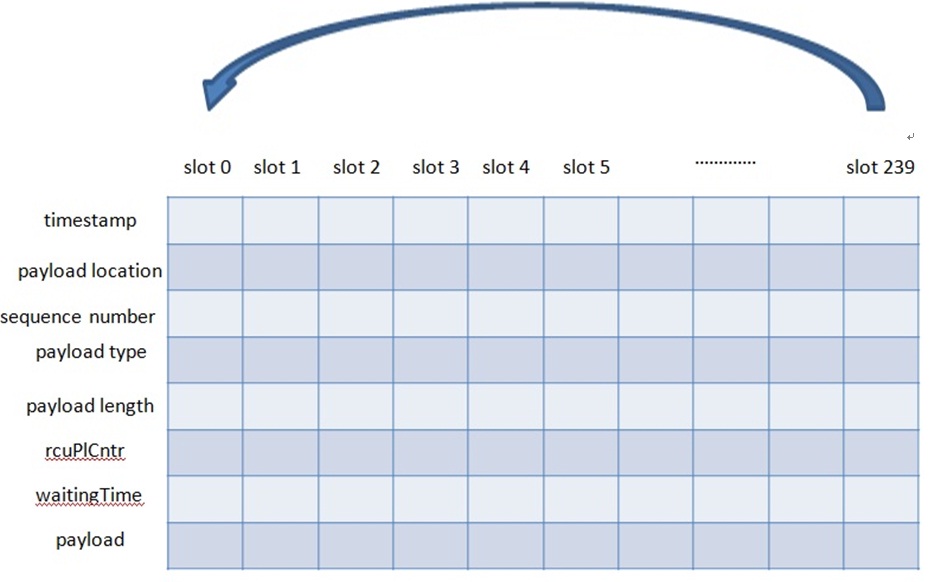
接下来看怎么从pakcet buffer里取一个语音包,这要依赖于从DSP模块带来的timestamp值(记为timestamp_from_dsp)。遍历packet buffer里每个slot,如果这个slot上语音包的timestamp小于timestamp_from_dsp,并且slot上有payload,就可以认为这个包来的太迟应该主动discard掉,包括reset这个slot和packet buffer里包个数减一等。遍历完packet buffer后把离timestamp_from_dsp最近的语音包的timestamp(即语音包的timestamp减去timestamp_from_dsp的值最小)对应的slot作为将要取出来的slot,把语音包从这个slot取出来后同样要reset这个slot以及packet buffer里包个数减一等。
从上面的描述可以看出这种放包的方式是比较简单的,是按照语音包到netEQ的先后顺序依次放在buffer里,而且可能是乱序的(收到包时就有可能是乱序的)。这就要求在取包时要遍历buffer把离DSP模块带过来的timestamp最近的timestamp的包取出来,遍历要用for循环,这就增加了计算量。这跟我以前做的jitter buffer的设计是有很大区别的。那种思想是把乱序的包排好序后再放在buffer里,取包时就不需要遍历buffer,而是从头上依次向后取。具体怎么实现的可以看我前面的文章(音频传输之Jitter Buffer设计与实现)。
下面看怎么计算网络延时统计值(optBufLevel),这是难点之一。假设每包20Ms,理想情况下每隔20Ms从网咯上收到一个语音包。实际情况是网络有延时丢包抖动,导致并不是每隔20Ms收到一个包,而是有时几十甚至100多毫秒收不到一个包,有时20Ms内收到几个包。我们要算出网络延时的统计值,作为产生向DSP发出控制命令的依据之一。怎么算呢?netEQ用包到的时间间隔来算,它的意思是当前收到的包相对上一个收到的包的时间间隔,以包个数为单位。当每收到一个包时就把packetIatCountSamp(已采样点数为单位)清零,以后每取一帧数据播放就把packetIatCountSamp加上一帧的采样点数(以AMR-WB每帧20Ms为例,每帧有320个采样点。每取一帧,packetIatCountSamp就增加320),当下一个包到时,拿packetIatCountSamp除以320就可以 算出两个包之间的间隔了。
下面给出计算网络延时的算法:
1, 计算当前包绝对到达间隔iat(以数据据包个数为单位),计算公式如下:
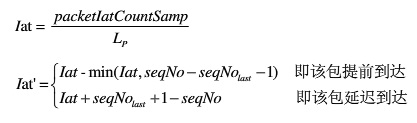
根据公式,提前到达的数据包的iat均为0,正常到达的iat为1,延迟一个包时间到达的Iat为2。Iat的最大值为64,即有65种(0—64)种可能。
2, 更新iat在每个值(0—64)上的概率分布。初始化时每个值(0—64)上的概率均为0,随着包的到来,每个值上的概率都在动态的改变着。概率更新分以下几小步:
1) 用遗忘因子f对当前概率进行遗忘,计算公式如下:
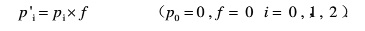
这里有个遗忘因子(forgetting factor)的概念。每个值上的概率均要算一下,得到新的概率。
2) 增大本次计算到的iat的概率,计算公式如下:
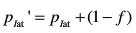
3) 更新遗忘因子f,使f为递增趋势,即通话时间越长,包间隔iat的概率分布越稳定。计算公式如下:

4) 调整本次计算到的iat的概率,使整个iat的概率分布之和近似为1。假设当前概率分布之和为tempSum,则计算公式如下:

3, 统计满足95%概率的iat值,记为B。根据下式可以算出B的值。
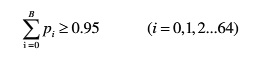
4, 统计iat的峰值
netEQ中采用两个长度为8的数组来统计iat的峰值,一个用来存峰值幅度,另一个用来存峰值间隔。峰值间隔是结构体automode中另一个参数peakIatCountSamp,用于统计当前探测到的峰值距离上次探测到的峰值的间隔,以样本个数为单位。当iat的值大于2B时就认为峰值出现了,把当前的iat和peakIatCountSamp值存在数组里。如果数组未满,就放在上一个峰值位置后的空的位置上;如果满了,就淘汰掉数组里最早的那个峰值,其他峰值左移,并把新的峰值放在数组里index为7的位置上。这里需要说明的是当两个数组的值不足8个时,峰值数组是不起作用的。
5, 计算optBufLevel
当峰值数组起作用并且当前peakIatCountSamp小于等于峰值间隔数组中最大的间隔两倍时,optBufLevel 取峰值数组中的最大值。否则optBufLevel 就为B。
以上是我照本宣科的把怎么算网络延时的算法表述出来。我基本理解了算法的思想,但是不清楚算法中的一些系数是怎么得到的。用google搜了一下,没找到相关的文档说明,这也是好多开源软件的通病,没有文档。我猜测是相关开发人员用数学建模的方法得到的系数值吧。如果有哪位朋友知道,麻烦给讲讲,先谢谢了。讲讲我对这个算法的理解吧。算网络延时是基于概率来算的,共有65个样本(0延时,一个包延时,2个包延时,…….,64个延时)。初始化时各个样本的概率(占的百分比)均为0。通话后某个延时值出现了它的概率值就要变大,相应的其他延时值的概率就要变小(已经为零的没办法再变小,依旧为零)。算法里先用遗忘因子去减小各个延时值的概率,然后再去变大本次延时值的概率,为了保证概率和为1要做一些微调(也会去更新遗忘因子)。然后从零延时开始把各个延时值的概率加起来,达到95%的值就可初步认为是延时值了。比如0延时概率为0.1, 1个包延时概率为0.7, 2个包延时概率为0.09,3个包延时概率为0.07,这时概率和为0.96,已达到0.95的线,取网络延时最大的值3,就可初步认为网络延时为3个包的延时。还要看当前网络状况,如果一段时间内频繁出现延时的峰值,说明当前网络环境比较糟糕,为了提高语音质量需要加大网络延时的值,就把峰值数组里的最大值,作为最终的网络延时值。
算网络延时是在语音包放进packet buffer后。算抖动缓冲延时是在收到DSP模块给MCU模块发反馈信息后(要用到反馈信息)以及从packet buffer取语音包前。下面给出计算步骤:
1, 根据packet buffer里已有的语音包的个数算出已有的样本数,记为samples_in_packetbuffer,这依赖于采样率和包时长,以AMR-WB为例,采样率为16kHZ,包时长为20ms,可算出每包有320个样本。假设packet buffer里有5个语音包,则packet buffer里已有的样本数为1600 (1600 = 320*5)。
2, 在speech buffer里未播放的(即sampleLeft)样本也要算在抖动缓冲延时内。它与packet buffer内的样本数相加就是实时的抖动缓冲延时(samples_jitter_delay,以样本个数为单位),即samples_jitter_delay = samples_in_packet_buffer + samplesLeft,再除以每包样本数samples_per_packet,就可以得到实时抖动缓冲延时值(以包个数为单位)。
3, 计算bufferLevelFilt,公式如下:
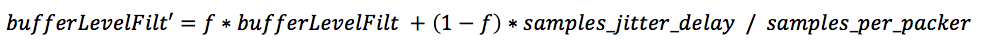
这里计算的是抖动缓冲延时的自适应平均值,f是计算均值的遗忘因子,根据网络状况自适应的变化,具体取值见下式:

其中B为前面算网络延时时的B值(以包个数为单位)。
4, 如果经过加速或者减速播放,则需要去修正bufferLevelFilt,公式如下:
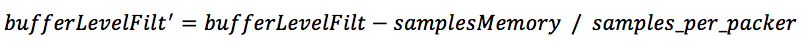
其中samplesMemory表示加速或减速播放后数据长度的伸缩变化,已样本个数为单位。若为加速,sampleMemory为正值,bufferLevelFilt减小;若为减速,sampleMemory为负值,bufferLevelFilt变大。
上面讲了MCU中网络延时和抖动缓冲延时的计算,MCU也收到了DSP模块发过来的反馈报告。后面MCU就要根据这些来决定给DSP模块发什么样的控制命令(加速/减速等),这是下一篇的主要内容。
webRTC中音频相关的netEQ(三):存取包和延时计算的更多相关文章
- webRTC中音频相关的netEQ(四):控制命令决策
上篇(webRTC中音频相关的netEQ(三):存取包和延时计算)讲了语音包的存取以及网络延时和抖动缓冲延时的计算,MCU也收到了DSP模块发来的反馈报告.本文讲MCU模块如何根据网络延时.抖动缓冲延 ...
- webRTC中音频相关的netEQ(二):数据结构
上篇(webRTC中音频相关的netEQ(一):概述)是netEQ的概述,知道了它主要是用于解决网络延时抖动丢包等问题提高语音质量的,也知道了它有两大单元MCU和DSP组成.MCU 主要是把从网络收到 ...
- webRTC中音频相关的netEQ(五):DSP处理
上篇(webRTC中音频相关的netEQ(四):控制命令决策)讲了MCU模块是怎么根据网络延时.抖动缓冲延时和反馈报告等来决定给DSP模块发什么控制命令的.DSP模块根据收到的命令进行相关处理,处理简 ...
- webRTC中音频相关的netEQ(一):概述
上篇文章(语音通信中终端上的时延(latency)及减小方法)说从本篇开始会切入webRTC中的netEQ主题,netEQ是webRTC中音频技术方面的两大核心技术之一(另一核心技术是音频的前后处理, ...
- WebRTC 源码分析(三):安卓视频硬编码
数据怎么送进编码器? 怎么从编码器取数据? 如何做流控? 在开始之前,我们先了解一下 MediaCodec 的基本知识. MediaCodec 基础 Developer 官网 上的描述已经很清楚了,下 ...
- 【Oracle 集群】ORACLE DATABASE 11G RAC 知识图文详细教程之RAC 工作原理和相关组件(三)
RAC 工作原理和相关组件(三) 概述:写下本文档的初衷和动力,来源于上篇的<oracle基本操作手册>.oracle基本操作手册是作者研一假期对oracle基础知识学习的汇总.然后形成体 ...
- 通过WebRTC实现实时视频通信(三)
通过WebRTC实现实时视频通信(一) 通过WebRTC实现实时视频通信(二) 通过WebRTC实现实时视频通信(三) 在这篇文章中我们继续了解WebRTC的相关API,RTCPeerConnecti ...
- 【转】【Oracle 集群】ORACLE DATABASE 11G RAC 知识图文详细教程之RAC 工作原理和相关组件(三)
原文地址:http://www.cnblogs.com/baiboy/p/orc3.html 阅读目录 目录 RAC 工作原理和相关组件 ClusterWare 架构 RAC 软件结构 集群注册(OC ...
- Spring3.2AOP实现需要添加的三个包
Spring3.2AOP实现需要添加的三个包 http://down.51cto.com/data/1001395 http://down.51cto.com/data/519542
随机推荐
- jstl,el表达式
在上一篇中,我们写了将数据传到jsp页面,在jsp页面进行展示数组,但是我们发现,在jsp页面写代码是一件很烦的事,一个循环要拆成两部分,例如for循环,在例如if语句: <%int a=22; ...
- C#获取当前日期时间
我们可以通过使用DataTime这个类来获取当前的时间.通过调用类中的各种方法我们可以获取不同的时间:如:日期(2008-09-04).时间(12:12:12).日期+时间(2008-09-04 12 ...
- css设置文字多余部分显示省略号
如果只显示一行,则可以使用以下方法: overflow: hidden; text-overflow:ellipsis; white-space: nowrap; 如果需要显示多行,在需要设置的元素s ...
- WEB学习笔记5-标准的HTML页面结构
完整的文档包含一下 <html> <head> </head> <body> </body> </html> 在HTML5规范中 ...
- 给PostgreSQL添加MySQL的unix_timestamp与from_unixtime函数
MySQL的2个常用函数unix_timestamp()与from_unixtime PostgreSQL并不提供,但通过PostgreSQL强大的扩展性可以轻松的解决问题. 话说远在天边,尽在眼前, ...
- crunch--字典生成工具
Crunch是一种创建密码字典工具,按照指定的规则生成密码字典,可以灵活的制定自己的字典文件.使用Crunch工具生成的密码可以输出到屏幕,保存到文件.或另一个程序.crunch程序在2004年及以前 ...
- PHP错误日志和内存查看(转)
本篇文章给大家带来的内容是关于PHP错误日志和内存查看的方法介绍(代码),有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助. 1.通过命令查看服务器上一共开了多少的 php-cgi 进程: ...
- PHP编译安装报错:configure: error: mcrypt.h not found. Please reinstall libmcrypt
我是在CentOS6.5安装php5.5.28这个版本,PHP编译代码如下: ./configure --prefix=/usr/local/php --with-config-file-path=/ ...
- Stackoverflow热门问题
1. JavaScript如何重定向到其他网页 如何使用JavaScript将用户从一个网页重定向到另一个网页? 2. JavaScript闭包是如何工作的 只知道JavaScript闭包的概念,但是 ...
- O/R关系的深入理解(转载)
本文转载自aa8945163: http://aa8945163.iteye.com/blog/859713 什么是O/R Mapping? 广义上,ORM指的是面向对象的对象模型和关系型数据库的数据 ...