从Learning to Segment Every Thing说起
原文地址:https://arxiv.org/pdf/1711.10370.pdf
这是何恺明老师发表于CVPR2018的一篇优秀paper。
先简单回顾一下语义分割领域之前的工作
那么什么是语义分割?
语义分割其实就是对图片的每个像素都做分类。其中,较为重要的语义分割数据集有:VOC2012 以及 MSCOCO 。
比较流行经典的几种方法
传统机器学习方法:如像素级的决策树分类,参考TextonForest以及Random Forest based classifiers。再有就是深度学习方法。
深度学习最初流行的分割方法是,打补丁式的分类方法 (patch classification) 。逐像素地抽取周围像素对中心像素进行分类。由于当时的卷积网络末端都使用全连接层 (full connected layers) ,所以只能使用这种逐像素的分割方法。
但是到了2014年,来自伯克利的Fully Convolutional Networks(FCN)卷积网络,去掉了末端的全连接层。随后的语义分割模型基本上都采用了这种结构。除了全连接层,语义分割另一个重要的问题是池化层。池化层能进一步提取抽象特征增加感受域,但是丢弃了像素的位置信息。然而语义分割需要类别标签和原图像对齐,因此需要重新引入像素的位置信息。有两种不同的架构可以解决此像素定位问题。
▪ 第一种是编码-译码架构。编码过程通过池化层逐渐减少位置信息、抽取抽象特征;译码过程逐渐恢复位置信息。一般译码与编码间有直接的连接。该类架构中U-net 是最流行的。
▪ 第二种是膨胀卷积 (dilated convolutions) 【这个核心技术值得去阅读学习】,抛弃了池化层。使用的卷积核如下图所示:

既然都说到这里,那继续来简单说一些相关的文献。按时间顺序总结,大概总结9篇paper,看语义分割的结构是如何演变的。分别有FCN 、SegNet 、U-Net、Dilated Convolutions 、DeepLab (v1 & v2) 、RefineNet 、PSPNet 、Large Kernel Matters 、DeepLab v3 。
1)FCN 2014年
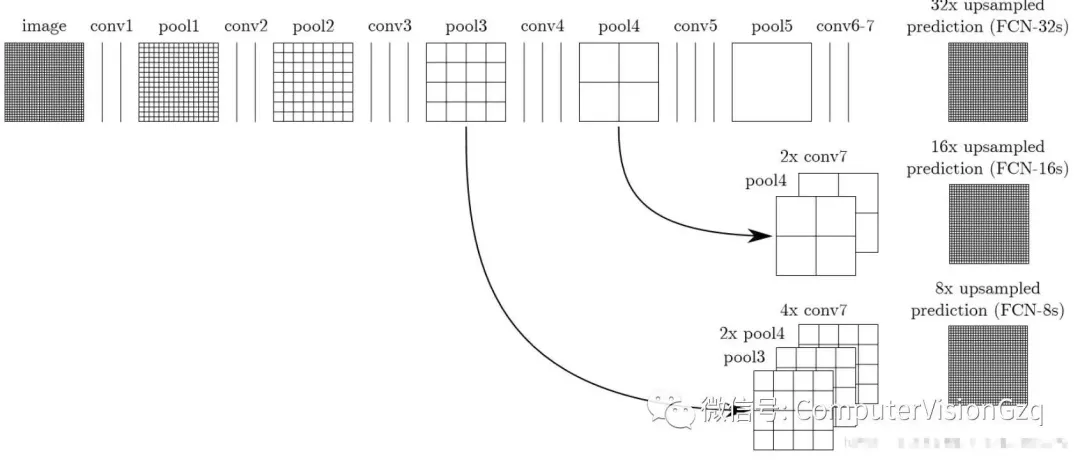
主要的贡献:
▪ 为语义分割引入了 端到端 的全卷积网络,并流行开来
▪ 重新利用 ImageNet 的预训练网络用于语义分割
▪ 使用 反卷积层 进行上采样
▪ 引入跳跃连接来改善上采样粗糙的像素定位
比较重要的发现是,分类网络中的全连接层可以看作对输入的全域卷积操作,这种转换能使计算更为高效,并且能重新利用ImageNet的预训练网络。经过多层卷积及池化操作后,需要进行上采样,FCN使用反卷积(可学习)取代简单的线性插值算法进行上采样。
那么什么是反卷积呢?
https://blog.csdn.net/itleaks/article/details/80336825 这篇博客及其附带链接会详细告诉你。
2)SegNet 2015年
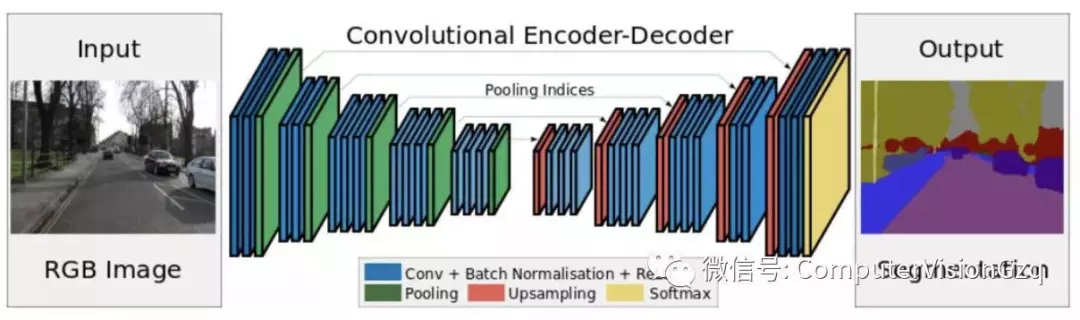
编码-译码架构
主要贡献:将池化层结果应用到译码过程。引入了更多的编码信息。使用的是pooling indices而不是直接复制特征,只是将编码过程中 pool 的位置记下来,在 uppooling 阶段使用该信息进行 pooling 。
3)U-Net 2015
U-Net有更规整的网络结构,通过将编码器的每层结果拼接到译码器中得到更好的结果。

4)Dilated Convolutions 2015年
通过膨胀卷积操作聚合多尺度信息。

主要贡献:
▪ 使用膨胀卷积
▪ 提出 ’context module‘ ,用来聚合多尺度信息
池化在分类网络中能够扩大感知域,同样降低了分辨率,所以提出了膨胀卷积层。
5)DeepLab (v1 & v2) 2014 & 2016
谷歌——DeepLab v1:
Semantic image segmentation with deep convolutional nets and fully connected CRFs
DeepLab是结合了深度卷积神经网络(DCNNs)和概率图模型(DenseCRFs)的方法。在实验中发现DCNNs做语义分割时精准度不够的问题,根本原因是DCNNs的高级特征的平移不变性(即高层次特征映射)。DeepLab解决这一问题的方法是通过将DCNNs层的响应和完全连接的条件随机场(CRF)结合。同时模型创新性的将Hole(即空洞卷积)算法应用到DCNNs模型上,在现代GPU上运行速度达到了8FPS。
相比于传统的视觉算法(SIFT或HOG),DCNN以其end-to-end(端到端)方式获得了很好的效果。这样的成功部分可以归功于DCNN对图像转换的平移不变性,这根本是源于重复的池化和下采样组合层。平移不变性增强了对数据分层抽象的能力,但同时可能会阻碍低级视觉任务,例如姿态估计、语义分割等,在这些任务中我们倾向于精确的定位而不是抽象的空间关系。
DCNN在图像标记任务中存在两个技术障碍:
信号下采样;
空间不敏感。
第一个问题涉及到:在DCNN中重复最大池化和下采样带来的分辨率下降问题,分辨率的下降会丢失细节。DeepLab是采用的atrous(带孔)算法扩展感受野,获取更多的上下文信息。
第二个问题涉及到:分类器获取以对象中心的决策是需要空间变换的不变性,这天然的限制了DCNN的定位精度,DeepLab采用完全连接的条件随机场(DenseCRF)提高模型捕获细节的能力。
主要贡献:
速度:带atrous算法的DCNN可以保持8FPS的速度,全连接CRF平均推断需要0.5s;
准确:在PASCAL语义分割挑战中获得了第二的成绩;
简单:DeepLab是由两个非常成熟的模块(DCNN和CRFs)级联而成。
相关工作:
DeepLab系统应用在语义分割任务上,目的是做逐像素分类的,这与使用两阶段的DCNN方法形成鲜明对比(指R-CNN等系列的目标检测工作),R-CNN系列的做法是原先图片上获取候选区域,再送到DCNN中获取分割建议,重新排列取结果。虽然这种方法明确地尝试处理前段分割算法的本质,但在仍没有明确的利用DCNN的预测图。
我们的系统与其他先进模型的主要区别在于DenseCRFs和DCNN的结合。是将每个像素视为CRF节点,利用远程依赖关系,并使用CRF推理直接优化DCNN的损失函数。Koltun(2011)的工作表明完全连接的CRF在语义分割下非常有效。
也有其他组采取非常相似的方向,将DCNN和密集的CRF结合起来,我们已经更新提出了DeepLab系统(指的是DeepLabV2)。
密集分类下的卷积神经网络
这里先描述一下DCNN如何设计,调整VGG16模型,转为一个可以有效提取特征的语义分割系统。具体来说,先将VGG16的FC层转为卷积层,模型变为全卷积的方式,在图像的原始分辨率上产生非常稀疏的计算检测分数(步幅32,步幅=输入尺寸/输出特征尺寸步幅),为了以更密集(步幅8)的计算得分,我们在最后的两个最大池化层不下采样(padding到原大小),再通过2或4的采样率的空洞卷积对特征图做采样扩大感受野,缩小步幅。
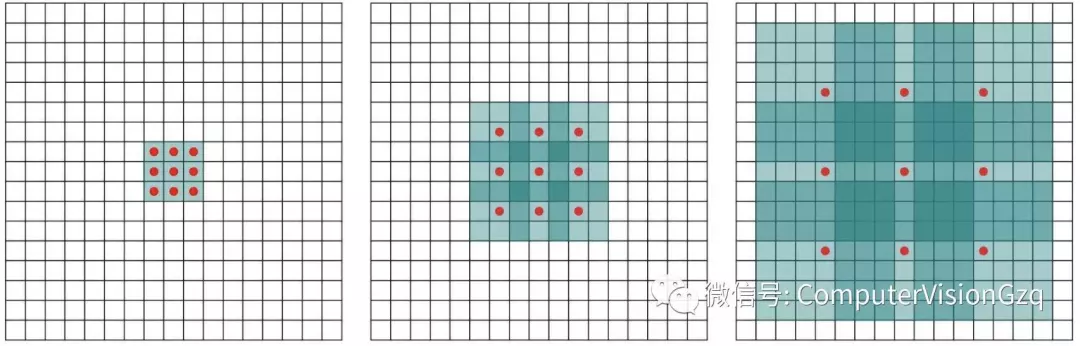
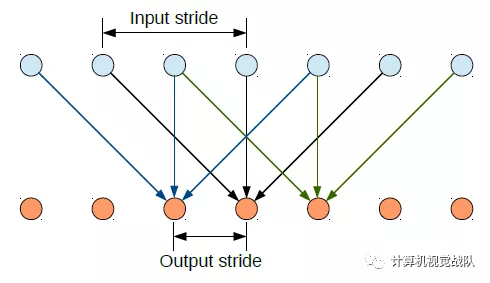
空洞卷积的使用
简单介绍下空洞卷积在卷积神经网络的使用(在DeepLabv3中有更详细的讨论)。在1-D的情况下,我们扩大输入核元素之间的步长,如下图Inputstride:
如果不是很直观,看下面的在二维图像上应用空洞卷积:

蓝色部分是输入:7×77×7的图像;
青色部分是输出:3×33×3的图像;
空洞卷积核:3×33×3 采样率(扩展率)为2 无padding。
这种带孔的采样又称atrous算法,可以稀疏的采样底层特征映射,该方法具有通常性,并且可以使用任何采样率计算密集的特征映射。在VGG16中使用不同采样率的空洞卷积,可以让模型再密集的计算时,明确控制网络的感受野。保证DCNN的预测图可靠的预测图像中物体的位置。
训练时将预训练的VGG16的权重做fine-tune,损失函数取是输出的特征图与ground truth下采样8倍做交叉熵和;测试时取输出图双线性上采样8倍得到结果。但DCNN的预测物体的位置是粗略的,没有确切的轮廓。在卷积网络中,因为有多个最大池化层和下采样的重复组合层使得模型的具有平移不变性,我们在其输出的high-level的基础上做定位是比较难的。这需要做分类精度和定位精度之间是有一个自然的折中。
解决这个问题的工作,主要分为两个方向:
第一种是利用卷积网络中多个层次的信息;
第二种是采样超像素表示,实质上是将定位任务交给低级的分割方法。
DeepLab是结合了DCNNs的识别能力和全连接的CRF的细粒度定位精度,寻求一个结合的方法,结果证明能够产生准确的语义分割结果。

CRF在语义分割上的应用
传统上,CRF已被用于平滑噪声分割图。通常,这些模型包含耦合相邻节点的能量项,有利于相同标签分配空间近端像素。定性的说,这些短程的CRF主要功能是清除在手工特征基础上建立的弱分类器的虚假预测。
与这些弱分类器相比,现代的DCNN体系产生质量不同的预测图,通常是比较平滑且均匀的分类结果(即以前是弱分类器预测的结果,不是很靠谱,现在DCNN的预测结果靠谱多了)。在这种情况下,使用短程的CRF可能是不利的,因为我们的目标是恢复详细的局部结构,而不是进一步平滑。而有工作证明可用全连接的CRF来提升分割精度。
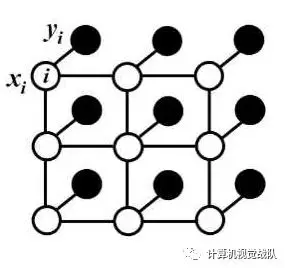
对于每个像素位置ii具有隐变量xi(这里隐变量就是像素的真实类别标签,如果预测结果有21类,则(i∈1,2,..,21),还有对应的观测值yi(即像素点对应的颜色值)。以像素为节点,像素与像素间的关系作为边,构成了一个条件随机场(CRF)。通过观测变量yi来推测像素位置i对应的类别标签xi。条件随机场示意图如下:
多尺度预测
论文还探讨了使用多尺度预测提高边界定位效果。具体的,在输入图像和前四个最大池化层的输出上附加了两层的MLP(第一层是128个3×33×3卷积,第二层是128个1×11×1卷积),最终输出的特征映射送到模型的最后一层辅助预测,合起来模型最后的softmax层输入特征多了5×128=6405×128=640个通道,实验表示多尺度有助于提升预测结果,但是效果不如CRF明显。
Experiment
测试细节:
|
项目 |
设置 |
|
数据集 |
PASCAL VOC 2012 segmentation benchmark |
|
DCNN模型 |
权重采用预训练的VGG16 |
|
DCNN损失函数 |
交叉熵 |
|
训练器 |
SGD,batch=20 |
|
学习率 |
初始为0.001,最后的分类层是0.01。每2000次迭代乘0.1 |
|
权重 |
0.9的动量, 0.0005的衰减 |
DeepLab由DCNN和CRF组成,训练策略是分段训练,即DCNN的输出是CRF的一元势函数,在训练CRF时是固定的。在对DCNN做了fine-tune后,对CRF做交叉验证。具体参数请参考论文。
CRF和多尺度的表现
在验证集上的表现:

可以看到带CRF和多尺度的(MSc)的DeepLab模型效果明显上升了。
多尺度的视觉表现:
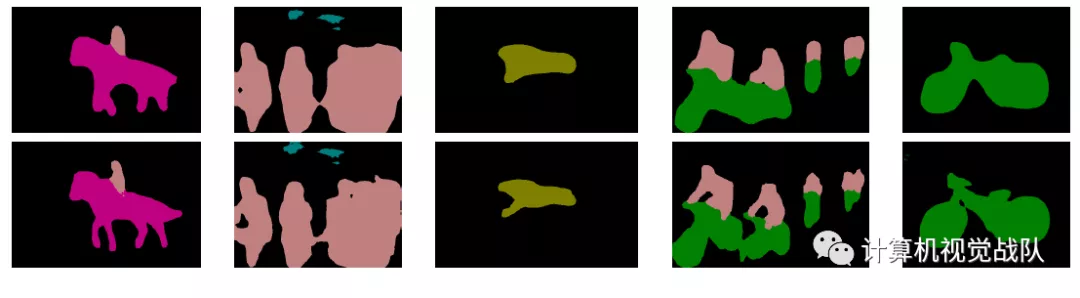
第一行是普通输出,第二行是带多尺度的输出,可以看出多尺度输出细节部分要好点
离散卷积的表现
在使用离散卷积的过程中,可控制离散卷积的采样率来扩展特征感受野的范围,不同配置的参数如下:

同样的实验结果:
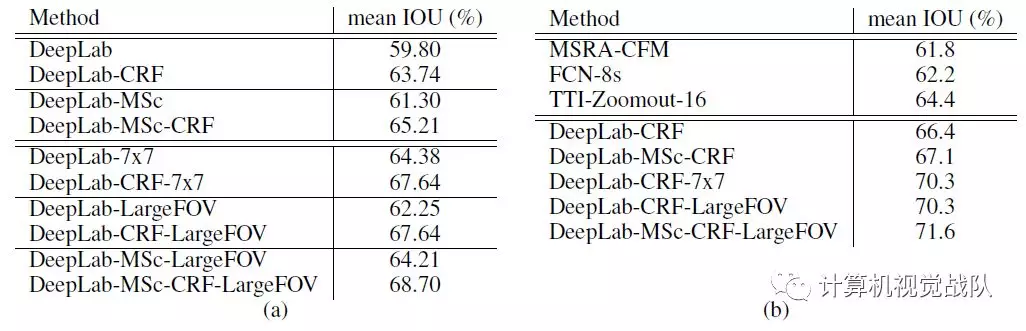
带FOV的即不同离散卷积的配置.可以看到大的离散卷积效果会好一点。
与其他模型相比

与其他先进模型相比,DeepLab捕获到了更细节的边界。
DeepLab创造性的结合了DCNN和CRF产生一种新的语义分割模型,模型有准确的预测结果同时计算效率高。在PASCAL VOC 2012上展现了先进的水平。DeepLab是卷积神经网络和概率图模型的交集,后续可考虑将CNN和CRF结合到一起做end-to-end训练。
附:Deeplab v2 安装及调试全过程
感谢“计算机视觉战队”分享总结,很好的一个微信公众号,推荐关注。
6)RefineNet 2016年
RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation

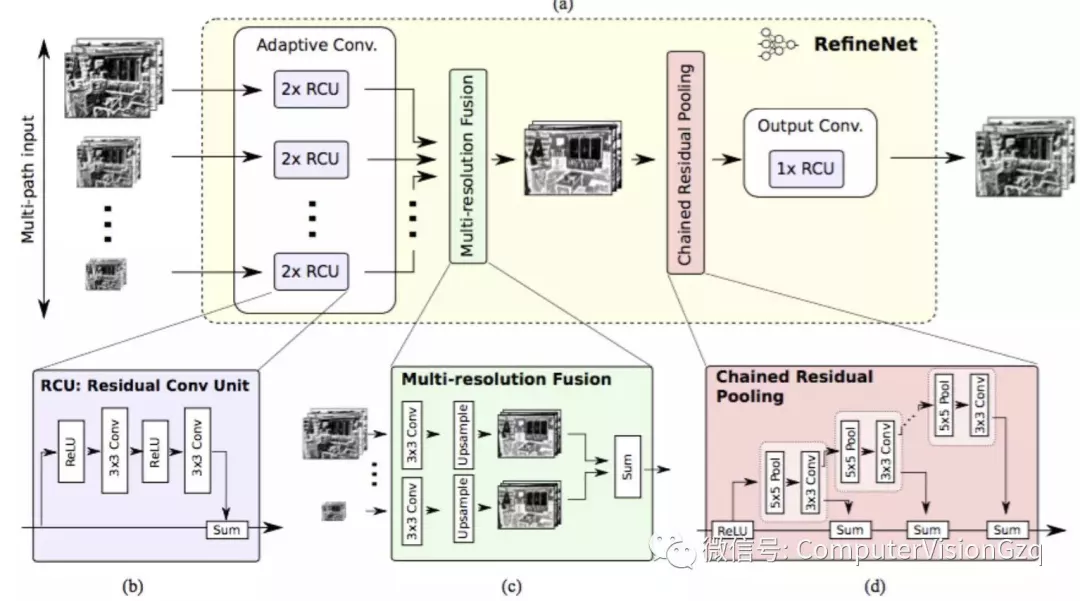
主要贡献:
▪ 精心设计的译码模块
▪ 所有模块遵循残余连接设计
膨胀卷积有几个缺点,如计算量大、需要大量内存。这篇文章采用编码-译码架构。编码部分是ResNet-101模块。译码采用RefineNet模块,该模块融合了编码模块的高分辨率特征和前一个RefineNet模块的抽象特征。每个RefineNet模块接收多个不同分辨率特征,并融合。
7)PSPNet 2016年
Pyramid Scene Parsing Network 金字塔场景解析网络
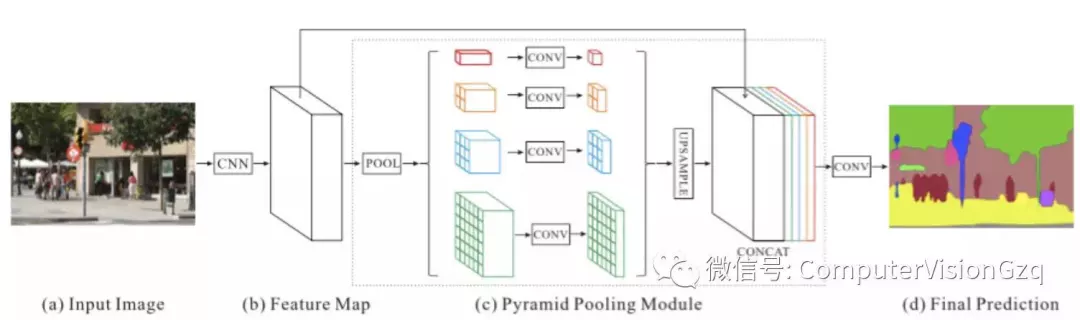
主要贡献:
▪ 提出了金字塔池化模块来聚合图片信息
▪ 使用附加的损失函数
金字塔池化模块通过应用大核心池化层来提高感知域。使用膨胀卷积来修改ResNet网,并增加了金字塔池化模块。金字塔池化模块对ResNet输出的特征进行不同规模的池化操作,并作上采样后,拼接起来,最后得到结果。
本文提出的网络结构简单来说就是将DeepLab(不完全一样)aspp之前的feature map pooling了四种尺度之后将5种feature map concat到一起经过卷积最后进行prediction的过程。
8)Large Kernel Matters 2017
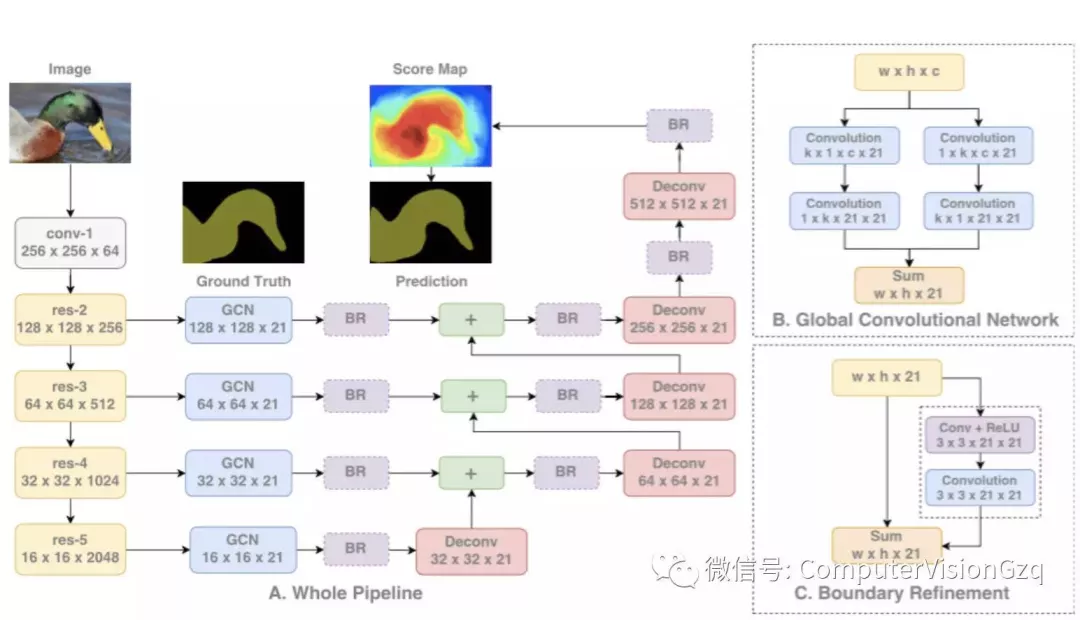
主要贡献:
▪ 提出了使用大卷积核的编码-译码架构
理论上更深的ResNet能有很大的感知域,但研究表明实际上提取的信息来自很小的范围,因此使用大核来扩大感知域。但是核越大,计算量越大,因此将k x k的卷积近似转换为1 x k + k x 1和k x 1 + 1 x k卷积的和,称为GCN。
本文的架构是:使用ResNet作为编译器,而GCN和反卷积作为译码器。还使用了名为Boundary Refinement的残余模块。
9)DeepLab v3 2017
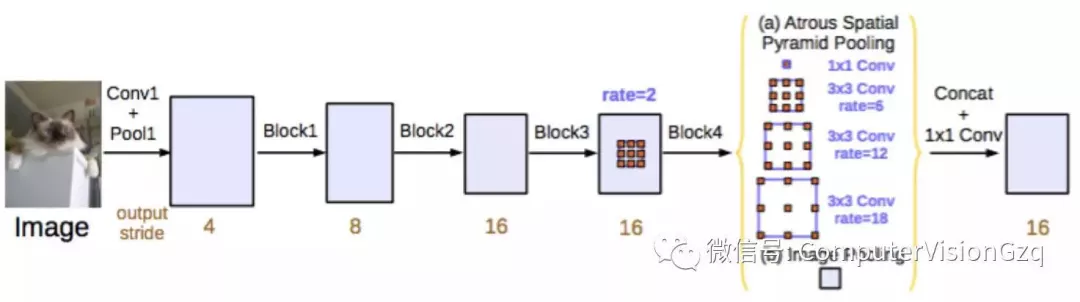
主要贡献:
▪ 改进 ASPP
▪ 串行部署 ASPP 的模块
和DeepLab v2一样,将膨胀卷积应用于ResNet中。改进的ASPP(https://blog.csdn.net/u011974639/article/details/80844304)指的是将不同膨胀率的膨胀卷积结果拼接起来,并使用了BN 。与Dilated convolutions (2015) 不一样的是,v3直接对中间的特征图进行膨胀卷积,而不是在最后做。
小总结:

现在把之前较为典型的简单介绍了一遍,现在,next,终于要说今天这个分割技术了。
1、概述
大多数目标实例分割的方法都要求所有的训练样本带有segmentation masks。这种要求就使得注释新类别的开销很大,并且将实例分段模型限制为∼100注释良好的类。
本次技术目的是提出一种新的部分监督的训练模式,该模式具有一种新的权重传递函数,结合一种新的权重传递函数,可以在一大组类别上进行训练实例分割模型,所有这些类别都有框注释,但只有一小部分有mask注释。这些设计允许我们训练MASK R-CNN,使用VisualGenome数据集的框注释和COCO数据集中80个类的mask注释来检测和分割3000种视觉概念。
最终,在COCO数据集的对照研究中评估了提出的方法。这项工作是迈向对视觉世界有广泛理解的实例分割模型的第一步。
2、学习分割everything
让C是一组目标类别,希望为其训练一个instance segmentation模型。大多数现有方法假设C中的所有训练样本都带有instance mask。
于是,本次放宽了这一要求,而是假设C=A∪B,其中来自A中类别的样本有mask,而B中的只有边界框。由于B类的样本是弱标记的w.r.t.目标任务(instance segmentation),将强标签和弱标签组合的训练作为一个部分监督的学习问题。注意到可以很容易地将instance mask转换为边界框,假设边界框注释也适用于A中的类。
给出了一个包含边界框检测组件和mask预测组件的MASK R-CNN instance segmentation模型,提出了MaskX R-CNN方法,该方法将特定类别的信息从模型的边界框检测器转移到其instance mask预测器。
▪ 权重传递来Mask预测
本方法是建立在Mask R-CNN,因为它是一个简单的instance segmentation模型,也取得了最先进的结果。简单地说,MASK R-CNN可以被看作是一个更快的R-CNN边界框检测模型,它有一个附加的mask分支,即一个小的全卷积网络(FCN)。
在推理时,将mask分支应用于每个检测到的对象,以预测instance-level的前景分割mask。在训练过程中,mask分支与Faster R-CNN中的标准边界框head并行训练。在Mask R-CNN中,边界框分支中的最后一层和mask分支中的最后一层都包含特定类别的参数,这些参数分别用于对每个类别执行边界框分类和instance mask预测。与独立学习类别特定的包围框参数和mask参数不同,我们建议使用一个通用的、与类别无关的权重传递函数来预测一个类别的mask参数,该函数可以作为整个模型的一部分进行联合训练。
具体如下如所示:
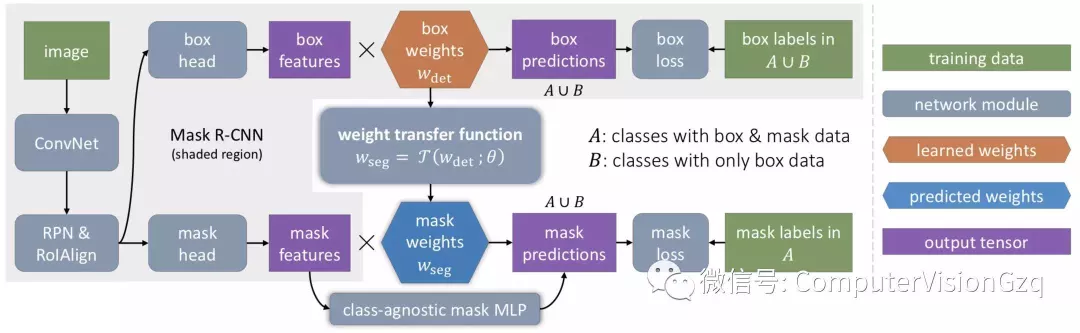
▪ Training
在训练期间,假设对于A和B两组类,instance mask注释仅适用于A中的类,而不适用于B中的类,而A和B中的所有类都有可用的边界框注释。如上图所示,我们使用A∪B中所有类的标准框检测损失来训练边界框head,但只训练mask head和权重传递函数T(·),在A类中使用mask loss,考虑到这些损失,我们探索了两种不同的训练过程:分阶段训练和端到端训练。
分阶段训练
由于Mask R-CNN可以被看作是用mask head增强Faster R-CNN,一种可能的训练策略是将训练过程分为检测训练(第一阶段)和分割训练(第二阶段)。
在第一阶段,只使用A∪B中类的边界框注释来训练一个Faster R-cnn,然后在第二阶段训练附加的mask head,同时保持卷积特征和边界框head的固定。这样,每个c类的类特定检测权重wc可以被看作是在训练第二阶段时不需要更新的固定类emdet层叠向量。
该方法具有很好的实用价值,使我们可以对边界框检测模型进行一次训练,然后对权重传递函数的设计方案进行快速评估。它也有缺点,这是我们接下来要讨论的。
端到端联合训练
结果表明,对于MASK R-CNN来说,多任务训练比单独训练更能提高训练效果。上述分阶段训练机制将检测训练和分割训练分开,可能导致性能低下。
因此,我们也希望以一种端到端的方式,联合训练边界框head和mask head。原则上,可以直接使用A∪B中类的box损失和A中类的mask loss来进行反向传播训练,但是,这可能导致A组和B组之间的类特定检测权重Wc的差异,因为只有c∈A的Wc会通过权重传递函数T(·)从mask loss得到梯度。
我们希望Wc在A和B之间是均匀的,这样在A上训练的预测Wc=T(Wc;θ)可以更好地推广到B。
效果图

Mask predictions from the class-agnostic baseline (top row) vs. our MaskX R-CNN approach (bottom row).Green boxes are classes in set A while the red boxes are classes in set B. The left 2 columns are A = {voc} and the right 2 columns are A = {non-voc}.


Example mask predictions from our MaskX R-CNN on 3000 classes in Visual Genome. The green boxes are the 80 classes that overlap with COCO (set A with mask training data) while the red boxes are the remaining 2920 classes not in COCO (set B without mask training data). It can be seen that our model generates reasonable mask predictions on many classes in set B. See §5 for details.
很有趣吧O(∩_∩)O~,当然,这并不是针对弱监督的。。。
从Learning to Segment Every Thing说起的更多相关文章
- 论文阅读笔记二十三:Learning to Segment Instances in Videos with Spatial Propagation Network(CVPR2017)
论文源址:https://arxiv.org/abs/1709.04609 摘要 该文提出了基于深度学习的实例分割框架,主要分为三步,(1)训练一个基于ResNet-101的通用模型,用于分割图像中的 ...
- (zhuan) Where can I start with Deep Learning?
Where can I start with Deep Learning? By Rotek Song, Deep Reinforcement Learning/Robotics/Computer V ...
- Analyzing The Papers Behind Facebook's Computer Vision Approach
Analyzing The Papers Behind Facebook's Computer Vision Approach Introduction You know that company c ...
- 笔记:基于DCNN的图像语义分割综述
写在前面:一篇魏云超博士的综述论文,完整题目为<基于DCNN的图像语义分割综述>,在这里选择性摘抄和理解,以加深自己印象,同时达到对近年来图像语义分割历史学习和了解的目的,博古才能通今!感 ...
- FAIR开源Detectron:整合全部顶尖目标检测算法
昨天,Facebook AI 研究院(FAIR)开源了 Detectron,业内最佳水平的目标检测平台. 昨天,Facebook AI 研究院(FAIR)开源了 Detectron,业内最佳水平的目标 ...
- Awesome Torch
Awesome Torch This blog from: A curated list of awesome Torch tutorials, projects and communities. T ...
- (zhuan) 126 篇殿堂级深度学习论文分类整理 从入门到应用
126 篇殿堂级深度学习论文分类整理 从入门到应用 | 干货 雷锋网 作者: 三川 2017-03-02 18:40:00 查看源网址 阅读数:66 如果你有非常大的决心从事深度学习,又不想在这一行打 ...
- (zhuan) awesome-object-proposals
awesome-object-proposals A curated list of object proposals resources for object detection. This ...
- cvpr2015总结
cvpr所有文章 http://cs.stanford.edu/people/karpathy/cvpr2015papers/ CNN Hypercolumns for Object Segmenta ...
随机推荐
- Python实现FTP文件的上传和下载
# coding: utf-8 import os from ftplib import FTP def ftp_connect(host, username, password): ftp = FT ...
- MySQL学习基础知识1
什么是数据库? 数据库就是存储数据的仓库. 存储方式: 变量 无法永久存储 文件处理,可以永久存储,弊端:文件只能在自己的计算机读写,无法被分享(局域网除外) 数据库分类: 1.关系型数据库 提供某种 ...
- did not finish being created even after we waited 189 seconds or 61 attempts. And its status is downloading
did not finish being created even after we waited 189 seconds or 61 attempts. And its status is down ...
- BZOJ 3000: Big Number (数学)
题目: https://www.lydsy.com/JudgeOnline/problem.php?id=3000 题解: 首先n很大,O(n)跑不过,那么就要用一些高端 而且没听过 的东西——sti ...
- 关于docker的基础教程
对于docker来说,详细参考如下博客 http://www.ruanyifeng.com/blog/2018/02/docker-tutorial.html
- 使用zabbix监控nginx的活动连接数
使用zabbix监控nginx的活动连接数 1.方法简述 zabbix可以自定义很多监控,只要是能通过命令获取到相关的值,就可以在zabbix的监控中增加该对象进行监控,在zabbix中,该对象称之为 ...
- STL初始化initializer_list
#include <iostream> #include <stdio.h> #include <stdlib.h> #include <string.h&g ...
- Jira与Confluence集成、授权信息查看和问题汇总
上一篇文章详细阐述了jira和confluence的安装部署和相关配置的操作记录,也介绍了两者之间其中一种集成方式:下面介绍另外的集成方式. 安装部署jira和confluence的顺序是,先安装ji ...
- C++回顾day03---<string字符串操作>
一:string优点 相比于char*的字符串,C++标准程序库中的string类不必担心内存是否足够.字符串长度等等 而且作为一个类出现,他集成的操作函数足以完成我们大多数情况下的需要. 二:str ...
- python之路(3)函数和匿名函数
函数 函数与过程 过程 def test(): "注释" print('1 am chen') test() : 过程调用 def : 定义函数的关键字 test : 函数名 pr ...