爬虫入门(三)——动态网页爬取:爬取pexel上的图片
Pexel上有大量精美的图片,没事总想看看有什么好看的自己保存到电脑里可能会很有用
但是一个一个保存当然太麻烦了
所以不如我们写个爬虫吧(๑•̀ㅂ•́)و✧
一开始学习爬虫的时候希望爬取pexel上的壁纸,然而自己当时不会
上周好不容易搞出来了,周末现在认真地总结一下上周所学的内容
也希望自己写的东西可以帮到爬虫入门滴朋友!
Before
同样的,我们在写一个爬虫前要明确自己想要爬取的东西是什么,明确下载目标数据在浏览器的操作如何
对于动态网页的爬取,在网页地址不变的情况下,我们首先要明确如何获取AJAX请求
首先我们看看这个网站pexel
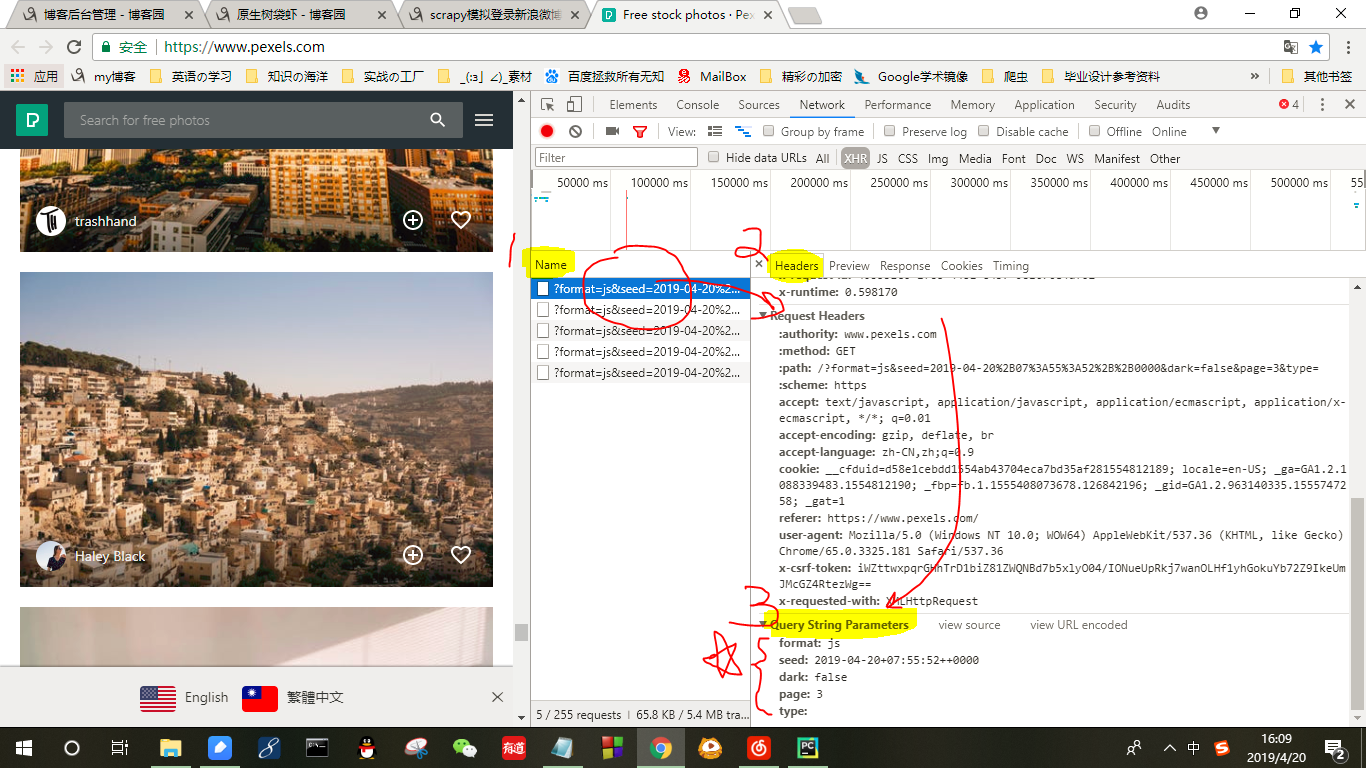
打开页面后再Chrome浏览器中选择“更多工具”→“开发者工具”→“Network”→XHR
1、看到Name那一栏中,找到每一次鼠标下滑浏览器发出的请求,任意点开一个请求;
2、在右侧的Headers下拉
3、找到Query String Parameter这一栏,记住这里的数据
等下用于构造请求
接下来,在脑海里明确一下下载图片的步骤
我们首先点开一张图(要获得这个图的地址)→选择下载图片→获得一个.jpeg结尾或者.png结尾的网页,最后保存图片
查看网页源代码可以发现在每一次动态生成的页面中我们就可以直接获取图的下载地址
找到它,发现前缀是"https://images.pexels.com/photos/"+jpeg或者png
这时候我们可以考虑到,首先我们先获得页面的代码
然后通过正则表达式去搜索符合条件的图片
但是后面可能会有重复的地方,在获取的list中最后再用set筛选一下即可。
明确上述思路后,接下来我们开始构建爬虫
①初始化Headers☆
这一步非常重要,不构造headers会被禁止访问= =
headers初始化代码如下,用于将爬虫伪装成浏览器请求,而请求用于出发特定的AJAX内容
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
}
url="https://www.pexels.com/"
②构造动态AJAX请求
根据上述截图中保存的Query String Parameter参数,我们构造request请求的时候捎上Params内容
把获取的下载图片的link保存到一个list中
def get_next_page ():
# ulist = []
pic_data_list = []
for i in range(1,100): # 构造动态访问请求,注意那个seed最好就是和当下时间相近的时间,可以直接打开网页copy一个来
try:
r=requests.get(url,params={'format': 'js','seed':'2019-04-20+07:55:52++0000','dark': 'true','page': i,'type':''},headers=headers,timeout = 0.5) print('the %s page is analyzing' % i) pattern = re.compile(r'.*?https://images.pexels.com/photos/(.*?).jpeg.*?')
pic_list = re.findall(pattern,r.text)
pic_data_list.extend(pic_list) except:
pass return pic_data_list
③元素的筛选
一开始调试程序的时候发现获取的link中还有以png形式结尾的link,这里需要再对list进行二次筛选,保留可以下载图片的link
最后还别忘了使用set把list中重复的元素删去哦
list_content=get_next_page()
list_content=list(set(list_content))
pattern = re.compile(r'.*?/pexels-photo-(.*?).png.*?') for i in range(len(list_content)):
if(re.search(pattern,list_content[i])):
list_content[i]=re.search(pattern,list_content[i]).group()
else:
list_content[i]=list_content[i]+'.jpeg' list_content=list(set(list_content))
④最后对于保存了每一张图片的下载地址的list使用urllib.request.urlretrieve把图片保存到指定路径就可以啦
*pexel一开始还对每个图片的下载地址整了反爬虫机制,所以下载也要再构造一次headers模拟浏览器^_^
这一步可以单独写成一个函数,不过我贪方便就没这么写
x=1
for i in list_content: try:
url1 = "https://images.pexels.com/photos/"+i
opener = urllib.request.build_opener()
opener.addheaders = [('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36')]
urllib.request.install_opener(opener)
request.urlretrieve(url1,"E://walkingbug/PAGE2/%r.jpg" % x)
print("the %s is downloaded." % url1)
x+=1
except error.HTTPError as e:
print(e.reason)
except error.URLError as e:
print(e.reason)
except:
pass
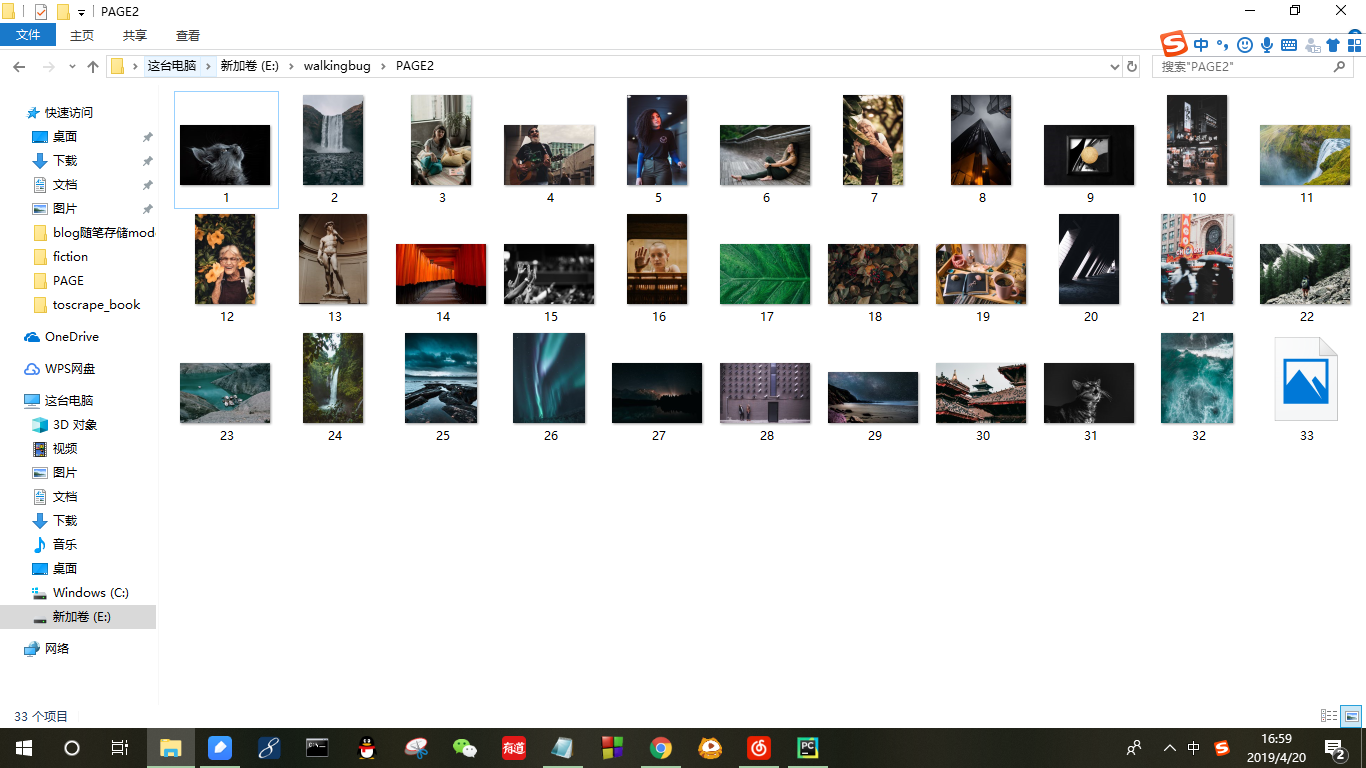
最后贴两张运行结果图
控制台的输出:

下载到本地的壁纸
完整代码如下:
①为了调试程序中间加了一些输出语句
②如果要粘去直接用,记得通过打开页面查看query string parameter修改23行代码的seed内容!不然可能会爬不到东西
import lxml.html
import requests
from urllib import request,error
import urllib
import re import time #用于爬取计时,后面不用也可以 headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36' }
url="https://www.pexels.com/" searched_url=[]
start_time = time.time() def get_next_page ():
# ulist = []
pic_data_list = []
for i in range(1,100): # 构造动态访问请求,注意那个seed最好就是和当下时间相近的时间,可以直接打开网页copy一个来
try:
r=requests.get(url,params={'format': 'js','seed':'2019-04-20+07:55:52++0000','dark': 'true','page': i,'type':''},headers=headers,timeout = 0.5) print('the %s page is analyzing' % i) pattern = re.compile(r'.*?https://images.pexels.com/photos/(.*?).jpeg.*?')
pic_list = re.findall(pattern,r.text)
pic_data_list.extend(pic_list) except:
pass return pic_data_list list_content=get_next_page()
list_content=list(set(list_content))
pattern = re.compile(r'.*?/pexels-photo-(.*?).png.*?') for i in range(len(list_content)):
if(re.search(pattern,list_content[i])):
list_content[i]=re.search(pattern,list_content[i]).group()
else:
list_content[i]=list_content[i]+'.jpeg' list_content=list(set(list_content))
for i in list_content:
print(i)
print(len(list_content)) x=1
for i in list_content: try:
url1 = "https://images.pexels.com/photos/"+i
opener = urllib.request.build_opener()
opener.addheaders = [('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36')]
urllib.request.install_opener(opener)
request.urlretrieve(url1,"E://walkingbug/PAGE2/%r.jpg" % x)
print("the %s is downloaded." % url1)
x+=1
except error.HTTPError as e:
print(e.reason)
except error.URLError as e:
print(e.reason)
except:
pass
爬虫入门(三)——动态网页爬取:爬取pexel上的图片的更多相关文章
- 爬虫入门三 scrapy
title: 爬虫入门三 scrapy date: 2020-03-14 14:49:00 categories: python tags: crawler scrapy框架入门 1 scrapy简介 ...
- Python 爬虫修养-处理动态网页
Python 爬虫修养-处理动态网页 本文转自:i春秋社区 0x01 前言 在进行爬虫开发的过程中,我们会遇到很多的棘手的问题,当然对于普通的问题比如 UA 等修改的问题,我们并不在讨论范围,既然要将 ...
- 3.Python爬虫入门三之Urllib和Urllib2库的基本使用
1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解释才呈现出来的,实质它是一段HTML代码,加 JS.CSS ...
- 转 Python爬虫入门三之Urllib库的基本使用
静觅 » Python爬虫入门三之Urllib库的基本使用 1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器 ...
- Python爬虫入门教程 2-100 妹子图网站爬取
妹子图网站爬取---前言 从今天开始就要撸起袖子,直接写Python爬虫了,学习语言最好的办法就是有目的的进行,所以,接下来我将用10+篇的博客,写爬图片这一件事情.希望可以做好. 为了写好爬虫,我们 ...
- Python爬虫入门教程:豆瓣Top电影爬取
基本开发环境 Python 3.6 Pycharm 相关模块的使用 requests parsel csv 安装Python并添加到环境变量,pip安装需要的相关模块即可. 爬虫基本思路 一. ...
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- Java Web开发技术教程入门-初识动态网页
这段时间学校搞了一个"阅战阅勇"的阅读活动,奖品还是挺丰富的~于是,奔着这些奖品,我去图书馆借了这本<Java Web开发技术教程>.一是为了那些丰富的奖品,二是为了回 ...
- Python开发爬虫之BeautifulSoup解析网页篇:爬取安居客网站上北京二手房数据
目标:爬取安居客网站上前10页北京二手房的数据,包括二手房源的名称.价格.几室几厅.大小.建造年份.联系人.地址.标签等. 网址为:https://beijing.anjuke.com/sale/ B ...
随机推荐
- 对Jpa中Entity关系映射中mappedBy的理解
mappedBy 单向关系不需要设置该属性,双向关系必须设置,避免双方都建立外键字段数据库中1对多的关系,关联关系总是被多方维护的即外键建在多方,我们在单方对象的@OneToMany(mappedby ...
- sql server 查询当前月份日期列表数据
SELECT ), ,) AS every_time, --日期 ,getdate())) ) AS Weekd --星期几 FROM master..spt_values n WHERE n.typ ...
- React组件和生命周期简介
React 简介----React 是 Facebook 出品的一套颠覆式的前端开发类库.为什么说它是颠覆式的呢? 内存维护虚拟 DOM 对于传统的 DOM 维护,我们的步骤可能是:1.初始化 ...
- 解决Android Studio 将String类型保存为.txt文件,按下button跳转到文件管理器(解决了保存txt文件到文件管理后,手机打开是乱码的问题)
不知道为什么保存文件后之前打开一直都OK,就突然打开看到变成乱码了,最后解决了 关键:outStream.write(finalContent.getBytes("gbk")); ...
- 基于 TensorFlow 在手机端实现文档检测
作者:冯牮 前言 本文不是神经网络或机器学习的入门教学,而是通过一个真实的产品案例,展示了在手机客户端上运行一个神经网络的关键技术点 在卷积神经网络适用的领域里,已经出现了一些很经典的图像分类网络,比 ...
- 解决 spring-cloud-starter-zipkin 启动错误
应用场景:Spring Boot 服务添加 Zipkin 依赖,进行服务调用的数据采集,然后进行 Zipkin-Server 服务调用追踪显示. 示例pom.xml配置: <parent> ...
- zepto与jquery冲突的解决
一般是不会把zepto和jquery一起来用的.但有时候要引入一些插件,可能就会遇到这样的问题. jquery noConflict() jquery有一个方法叫noConflict() ,可以把jq ...
- Javascript高级编程学习笔记(86)—— Canvas(3)绘制矩形
绘制矩形 矩形是唯一一种可以直接在2D上下文中绘制的形状. 与矩形有关的方法包括: fillRect() strokeRect() clearRect() 上述方法都接收四个参数: 绘制矩形的 X 坐 ...
- [Swift]LeetCode305. 岛屿的个数 II $ Number of Islands II
A 2d grid map of m rows and n columns is initially filled with water. We may perform an addLand oper ...
- [Swift]LeetCode466. 统计重复个数 | Count The Repetitions
Define S = [s,n] as the string S which consists of n connected strings s. For example, ["abc&qu ...