Elastic Stack初篇-Logstash
一、Logstash简介
Logstash是一个开源数据收集引擎,具有实时管道功能。Logstash可以动态地将来自不同数据源的数据统一起来,并将数据标准化到你所选择的目的地。
二、Logstash处理流程
Logstash处理流程大致可分为3个阶段,Input---->Filter---->Output,用中文描述一下分别是,数据采集----->数据分析/解析---->数据输出;具体的处理流程可以查看下图,下面的一些函数和一些概念等后面我们在具体讲讲:
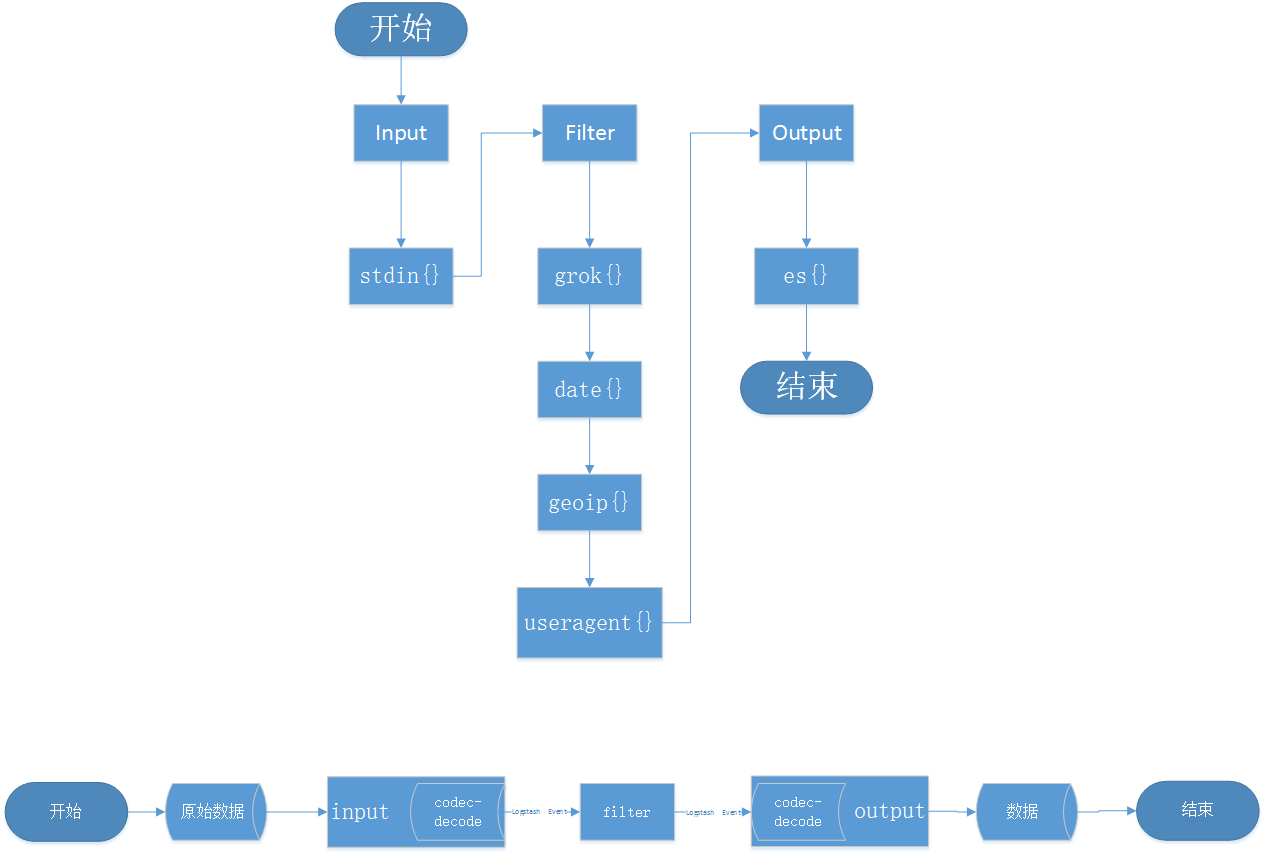
这里我们解释一下codec的概念,Codec 是 logstash 从 1.3.0 版开始新引入的概念(Codec 来自 Coder/decoder 两个单词的首字母缩写)。在此之前,logstash 只支持纯文本形式输入,然后以过滤器处理它。但现在,我们可以在输入 期处理不同类型的数据,这全是因为有了 codec 设置。所以,这里需要纠正之前的一个概念。Logstash 不只是一个input | filter | output 的数据流,而是一个 input | decode | filter | encode | output 的数据流!codec 就是用来 decode、encode 事件的。
Logstash Event也需要介绍,类似Java的Object的对象,在这个过程我们可以对其进行一些赋值等操作;
三、Logstash架构介绍
上面介绍一下Logstash的数据流向,接下来我们介绍下Logstash的架构,当然我介绍的是6.X的架构,看下图
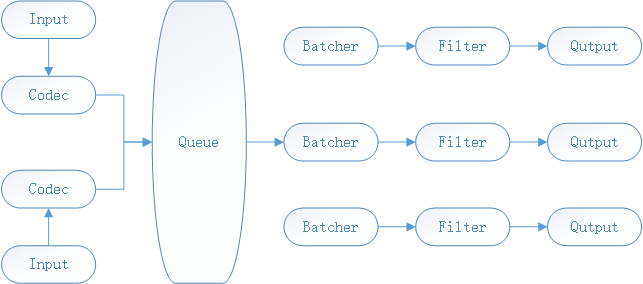
由上图得知,我们可以有多个输入的文本,另外由Queue分发到不同的Pipline中,这里的Pipline中文的意思就是管道,在程序中我们可以理解为线程,可以有多个Pipline,并且每个Pipline之间是互不打扰的,另外每个Batcher,Filter和Output组成,Batcher是批量从Queue获取数据的,这个值可以通过配置进行设置;
Pipline配置如下:
pipeline.workers : 8 Pipeline线程数,及filter_output的处理线程数,默认是CPU的核数,命令行参数为-w
pipeline.batch.size : 125 Batcher一次批量获取的待处理文档数,默认125(建议向es输出的时候10-20Mb之间,可以计算一下文档数),可以根据输出进行调整,越大会占用越多的heap空间,可以通过jvm.options调整。命令行参数-b
pipeline.batch.delay :5 :Batcher的等待时长,单位为ms。命令行参数-u
接下来我们在了解下Queue设计思路,使用Queue以后我们首先要关注的是怎么确保数据是正常被消费掉了,这里到达QutPut以后会有发送一个ACK给Queue来告诉Queue这些Logstash Event已经处理完了,这样就能确保一个数据正常被消费掉,这也是在消息队列中我们常用的一种手段,接下来我们再聊聊Queue分类:
1.In Memory(在内存)
在内存中,固定大小,无法处理进程crash、机器宕机等情况,会导致数据丢失。
2.Persistent Queue In Disk (持久化到磁盘)
可处理进程crash情况,保证数据不丢失。保证数据至少消费一次;充当缓冲区,可代替kafka等消息队列作用。
接下来我们来了解下持久队列是怎么保证的?这里我们从数据到队列以后的处理开始说起,首先队列将数据备份到disk(磁盘),队列返回响应给Input,最后数据经过OutPut以后返回ACK给队列,当队列接收到消息以后开始删除disk中备份的数据,这样就能保证数据持久性;
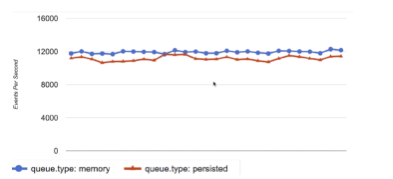
性能方面对比如下图,基本性能是无差别的:
队列主要配置如下:
queue.type: persisted 默认是memory
queue.max_bytes: 4gb 默认是1gb
四、Logstash配置介绍
我们会使用的配置文件在config目录录下面,logstash.yml和官方,接下来我们主要介绍下参数的配置logstash.yml配置:jvm.options,另外6.0以上的版本会有pipelines.yml,这个文件是为了在同一个进程中运行多个管道,具体可以参考下
node.name:节点名,默认是主机名;
path.data:持续化存储数据的文件夹,默认是在Logstash home目录下的data
path.config:设定Pipeline配置文件的目录
path.log:设置Pipeline日志目录
第三小节介绍的Queue和Pipeline都可以在该文件下设置,这里不做过多的介绍,另外更细节的一些参数配置大家可以参考官方;
jvm.options这个里面的配置大家可以自己根据自己机器的情况进行下JVM参数调优;
另外还有Pipeline配置文件,定义数据处理流程的文件,以.conf结尾
五、Pipeline配置
布尔类型 Boolean:isFailed => true
数值类型 Number:age => 33
字符串类型 String: name => “Hello”
数组类型:users => [{age=>11, name=>wtz}, {age => 22, name => myt}] 或者 path => [“/var/log/error,log”,”/var/log/warn.log”]
哈希类型:match => {“field” => “value1” “field”=>”value2”}
备注:#
在配置中可以引用Logstash Event的属性(字段),主要由下面两种方式:
1.直接引用字段值 – 直接使用[],如果是多层直接嵌套

2.在字符串中以 sprintf 方式引用 – 使用%{}来实现

配置文件支持条件判断语法:

表达式操作如下:
1.比较:== != < > <= >=
2.正则是否匹配:=~ =
3.包含(字符串或者数组):in, not in
4.布尔操作符:and or nand xor !
5.分组操作符(条件非常复杂的时候,其实就相当于括号):()
六、插件详解
第二部分的时候我们介绍了Logstash的数据处理流程,涉及到一些插件流程,接下来我们介绍下插件的配置,也是分成3部分介绍:
input插件介绍:
1.stdin
最简单的输入,从标准输入读取数据
2.file
从文件读取数据,参数介绍如下:
3.kafka
这个是我们使用的配置,供大家参考下,另外大家可以参考官方文档
input {
kafka {
bootstrap_servers => "服务地址"
group_id => "消费组id"
topics => ["订阅的主题列表","订阅的主题列表"]
codec => "json"
auto_offset_reset => "Kafka偏移量,超出设置为最早偏移量"
consumer_threads => "线程数"
}
}
另外大家还可以看下官方文档选择自己合适的使用;
Filter插件介绍
1.grok
解析和构造任意文本,Grok是目前Logstash中解析非结构化日志数据到结构化和可查询数据的最佳方式,使用内置的120种模式;
另外可以阅读下这篇文章你真的理解grok吗
2.mutate
对事件字段执行一般的转换,你可以重命名、删除、替换和修改事件中的字段。
3.drop
完全删除事件,例如调试事件。
4.clone
复制事件,可能添加或删除字段。
5.geoip
添加关于IP地址地理位置的信息
更多的大家可以阅读官方文档
OutPut插件介绍
最常用的就是输出到es,配置如下
elasticsearch {
hosts => "地址"
index => "索引"
document_type => "文档类型"
template_overwrite => 是否重写
}
Codec插件介绍
1.plain 读取原始内容
2.rubydebug将Logstash Event按照ruby格式输出,方便调试
3.line处理带有换行符的内容
4.json处理json格式的内容
5.multiline处理多行数据的内容
七、最后说点什么
参考与学习的来源为慕课网和官方文档,欢迎大家加入我QQ群:438836709
欢迎大家关注我公众号:

另外Oath2.0的文章和demo正在努力写!!没事大家动动小手点个赞!!谢谢!!
Elastic Stack初篇-Logstash的更多相关文章
- 使用 Spring Cloud Sleuth、Elastic Stack 和 Zipkin 做微服务监控
关于迁移微服务架构,最常被提及的挑战莫过于监控.每个微服务应独立于其他服务的运行环境,所以他们之间不会共享如数据源.日志文件等资源. 然而,较容易的查看服务的调用历史,并且能够查看多个微服务的请求传播 ...
- Elastic Stack之Logstash进阶
Elastic Stack之Logstash进阶 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.使用GeoLite2和logstash 过滤插件的geoip案例 1>. ...
- Elastic Stack核心产品介绍-Elasticsearch、Logstash和Kibana
Elastic Stack 是一系列开源产品的合集,包括 Elasticsearch.Kibana.Logstash 以及 Beats 等等,能够安全可靠地获取任何来源.任何格式的数据,并且能够实时地 ...
- Elastic Stack简介和Elasticsearch--先搞清楚概念第二篇
ELK 是三款软件的简称:分别是Elasticsearch. Logstash.Kibana组成 .在发展的过程中,又有新成员Beats等的加入,所以就形成了Elastic Stack.ELK 是旧的 ...
- Elastic Stack(ElasticSearch 、 Kibana 和 Logstash) 实现日志的自动采集、搜索和分析
Elastic Stack 包括 Elasticsearch.Kibana.Beats 和 Logstash(也称为 ELK Stack).能够安全可靠地获取任何来源.任何格式的数据,然后实时地对数据 ...
- 浅尝 Elastic Stack (二) Logstash
一.安装与启动 Logstash 依赖 Java 8 或者 Java 11,需要先安装 JDK 1.1 下载 curl -L -O https://artifacts.elastic.co/downl ...
- Elastic Stack
Elastic Stack 开发人员不能登陆线上服务器查看详细日志 各个系统都有日志,日志数据分散难以查找 日志数据量大,查询速度慢,或者数据不够实时 官网地址:https://www.elastic ...
- Elastic 技术栈之 Logstash 基础
title: Elastic 技术栈之 Logstash 基础 date: 2017-12-26 categories: javatool tags: java javatool log elasti ...
- Elastic Stack之kibana使用
Elastic Stack之kibana使用 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客数据流走向:FileBeat ===>Redis ===>log ...
随机推荐
- Linux vi常用命令
vi常用命令[Ctrl] + [f] 屏幕『向前』移动一页(常用)[Ctrl] + [b] 屏幕『向后』移动一页(常用)0 这是数字『 0 』:移动到这一行的最前面字符处(常用)$ 移动到这一行的最后 ...
- 痞子衡嵌入式:一表全搜罗常见短距离无线通信协议(Wi-Fi/Bluetooth/ZigBee/Thread...)
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是常见短距离无线通信协议. 短距离无线通信是物联网的基础,随着物联网IoT的火热发展,各种短距离无线通信协议也是层出不穷,这些协议标准各有 ...
- MySql如何查询JSON字段值的指定key的数据
实例:SELECT param->'$.pay' as pay_type FROM game.roominfo; 其中:param是roominfo表的一个字段,当中存的是JSON字符串,pay ...
- python-操作文件和目录
操作文件和目录 为文件和目的操作经常用到os模块和shutil模块. 常用方法: 获取当前脚本工作的目录路径:os.getcwd(),返回的是str类型. 返回指定目录下的所有文件和目录名:os.li ...
- Java开发笔记(二十八)布尔包装类型
前面介绍了数值包装类型,因为不管是整数还是小数,它们的运算操作都是类似的,所以只要学会了Integer的用法,其它数值包装类型即可一并掌握.但是对于布尔类型boolean来说,该类型定义的是“true ...
- fork/join概述
Fork/Join是java 7 解决并发问题的解决方案. 是 java内部并行框架.核心思想分别为拆分任务和结果合并,在核心思想外,为了提高cpu多核的利用率,设计了工作窃取算法,并将工作队列设计为 ...
- 程序员奇谈之我写的程序不可能有bug篇
程序员在普通人的印象里是一份严(ku)谨(bi)的职业,也是一个被搞怪吐槽乐此不疲的职业,程序员们面对复杂的代码敲打电脑时连眉头都不会皱一下,但是有一个词却是他们痛苦的根源,它就是Bug. 有不少的新 ...
- create-react-app 修改项目端口号及ip,设置代理
项目相关配置,需要在package.json中配置
- vue 路由的使用
ue-router是Vue.js官方的路由插件,它和vue.js是深度集成的,适合用于构建单页面应用.vue的单页面应用是基于路由和组件的,路由用于设定访问路径,并将路径和组件映射起来.传统的页面应用 ...
- 十分钟(小时)学习pandas
十分钟学习pandas 一.导语 这篇文章从pandas官网翻译:链接,而且也有很多网友翻译过,而我为什么没去看他们的,而是去官网自己艰难翻译呢? 毕竟这是一个学习的过程,别人写的不如自己写的记忆深刻 ...