Mapreduce求气温值项目
Mapreduce前提工作
简单的来说map是大数据,reduce是计算<运行时如果数据量不大,但是却要分工做这就比较花时间了>
首先想要使用mapreduce,需要在linux中进行一些配置:
1.在notepad++里修改yarn-site.xml文件,新添加
<property> <name>yarn.resourcemanager.hostname</name> <value>192.168.64.141</value> </property> <property> <name>yarn.nodemanager.aux-service</name> <value>mapreduce_shuffle</value> </property> 在notepad++里修改mapred-site.xml文件,新添加 <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
2.在xshell里将soft/soft/hadoop/etc/hadoop下的mapred-site.xml.template去掉后缀名

3.保证在start-dfs.sh、start-yarn.sh服务打开情况下

检测服务是否打开。输入Jps,显示namenod 和 datanod
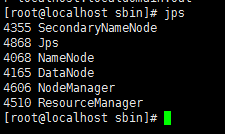
4.到hadoop目录下新建一个有数据的txt

 (保存退出是 Esc 后输入:wq!)
(保存退出是 Esc 后输入:wq!)
5.确保文件存在之后,将其放在hadoop文件下(如果用可视化界面如XFTP比较难找目录,但是使用eclipse上的小蓝象还是挺方便的)

6.在我们的ip下查看,已经将hadoop.txt放进了hadoop下


7.到hadoop下的mapreduce文件下
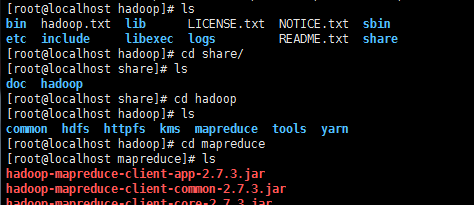
8.在hadoop下运行(这里hadoop-mapreduce-examples-2.7.3.jar是以及放在上面的架包工具)

可以看见数据在map和reduce之间传



9.也可以刷新eclipse里面的hadoop文件下的abc.txt查看结果
接下来我们自己来写一个mapreduce吧!
在mapreduce中,map和reduce是有个字不同的所以要单独写成两个类。
1.引入架包
2.创建webapp下的WEB-INF文件下的web.xml
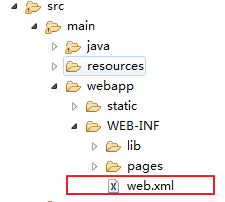
2.建类
Worldcount项目
Mapper代码:
package com.nenu.mprd.test; import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; public class MyMap extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
String line=value.toString();
String[] words=line.split(" ");
for (String word : words) {
context.write(new Text(word.trim()), new IntWritable(1));
}
}
}
Reduce代码:
package com.nenu.mprd.test; import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class MyReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
// TODO Auto-generated method stub
int sum=0;
for (IntWritable intWritable : values) {
sum+=intWritable.get();
}
context.write(key, new IntWritable(sum));
}
}
Job代码:
package com.nenu.mprd.test; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; public class MyJob extends Configured implements Tool{ public static void main(String[] args) throws Exception {
MyJob myJob=new MyJob();
ToolRunner.run(myJob, null);
}
@Override
public int run(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration conf=new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.64.141:9000");
Job job=Job.getInstance(conf);
job.setJarByClass(MyJob.class);
job.setMapperClass(MyMap.class);
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path("/hadoop/hadoop.txt"));
FileOutputFormat.setOutputPath(job, new Path("/hadoop/out"));
job.waitForCompletion(true);
return 0;
} }
Weather平均气温项目:
Mapper代码:
package com.nenu.weathermyreduce.test; import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.lib.input.FileSplit; //传入文件 输出拆分后的每个单词
public class MyMap extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
//获取文件目录下的每个文件的部分文件名
FileSplit filesplit = (FileSplit)context.getInputSplit();
String fileName = filesplit.getPath().getName().substring(5,10).trim();
//获取气温值
//每次只处理一行 字符偏移量下一行第一个字符为上一行最后一个字符位+1
//按行提取字符串
String line=value.toString();
//获取对应位置上的气温
Integer val =Integer.parseInt(line.substring(13, 19).trim());//去掉空格
//文件名作为输出key 获取的气温值作为value
//相同的key会交给同一个reduce进行计算
context.write(new Text(fileName), new IntWritable(val));
}
}
Reduce代码:
package com.nenu.weathermyreduce.test; import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; //输入单词 输出混洗、统计结果和
public class MyReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
// TODO Auto-generated method stub //求平均数 //计数 一共有多少个数据
int sum=0;//和
int count=0;//计算
for (IntWritable val : values) {
count++;
sum+=val.get();//转换为int类型
}
int average = sum/count;
context.write(key, new IntWritable(average)); }
}
Myjob代码:
package com.nenu.weathermyreduce.test; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; public class MyJob extends Configured implements Tool{ public static void main(String[] args) throws Exception {
MyJob myJob=new MyJob();
ToolRunner.run(myJob, null);
}
@Override
public int run(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration conf=new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.64.141:9000");
Job job=Job.getInstance(conf);
job.setJarByClass(MyJob.class);
job.setMapperClass(MyMap.class);
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path("/hadoop/weather"));
FileOutputFormat.setOutputPath(job, new Path("/hadoop/weather/out"));
job.waitForCompletion(true);
return 0;
} }
3.开启服务,dfs+yarn。(所有mapreduce项目都需要开启yarn,yarn下管理资源和节点)
4.运行job类
Job的任务:
是mapreduce程序运行的主类。指定使用的是哪个mapper哪个reduce
指定mapper、reduce输入输出的key-value类型
以及输入、输出的数据位置
要说明的一点是,在我的程序中Job提交---一般是用waitforCompletion(true)可以看见运行过程(不用submit)

Mapreduce求气温值项目的更多相关文章
- Hadoop阅读笔记(二)——利用MapReduce求平均数和去重
前言:圣诞节来了,我怎么能虚度光阴呢?!依稀记得,那一年,大家互赠贺卡,短短几行字,字字融化在心里:那一年,大家在水果市场,寻找那些最能代表自己心意的苹果香蕉梨,摸着冰冷的水果外皮,内心早已滚烫.这一 ...
- ACM3 求最值
/*2*2014.11.18*求最值*描述:给定N个整数(1<=N<=100),求出这N个数中的最大值,最小值.*输入:多组数据,第一行为一个整数N,第二行为N个不超过100的正整数,用空 ...
- [NOI2005]维修数列 Splay tree 区间反转,修改,求和,求最值
题目链接:http://www.lydsy.com/JudgeOnline/problem.php?id=1500 Description Input 输入文件的第1行包含两个数N和M,N表示初始时数 ...
- hdu4521-小明系列问题——小明序列(线段树区间求最值)
题意:求最长上升序列的长度(LIS),但是要求相邻的两个数距离至少为d,数据范围较大,普通dp肯定TLE.线段树搞之就可以了,或者优化后的nlogn的dp. 代码为 线段树解法. #include ...
- javascript之求最值
求最值: var selections = $("#deliveryGridSalesOrGoods").datagrid('getRows'); var costPrice = ...
- poj3264(线段树区间求最值)
题目连接:http://poj.org/problem?id=3264 题意:给定Q(1<=Q<=200000)个数A1,A2,```,AQ,多次求任一区间Ai-Aj中最大数和最小数的差. ...
- Sql示例说明如何分组后求中间值--【叶子】
原文:Sql示例说明如何分组后求中间值--[叶子] 这里所谓的分组后求中间值是个什么概念呢? 我举个例子来说明一下: 假设我们现在有下面这样一个表: type name price -- ...
- hdu 1754 I Hate It(树状数组区间求最值)2007省赛集训队练习赛(6)_linle专场
题意: 输入一行数字,查询第i个数到第j个数之间的最大值.可以修改其中的某个数的值. 输入: 包含多组输入数据. 每组输入首行两个整数n,m.表示共有n个数,m次操作. 接下来一行包含n个整数. 接下 ...
- C语言 · 求arccos值
算法提高 7-2求arccos值 时间限制:10.0s 内存限制:256.0MB 问题描述 利用标准库中的cos(x)和fabs(x)函数实现arccos(x)函数,x取值范围是[- ...
随机推荐
- 机器学习中模型泛化能力和过拟合现象(overfitting)的矛盾、以及其主要缓解方法正则化技术原理初探
1. 偏差与方差 - 机器学习算法泛化性能分析 在一个项目中,我们通过设计和训练得到了一个model,该model的泛化可能很好,也可能不尽如人意,其背后的决定因素是什么呢?或者说我们可以从哪些方面去 ...
- 010 socket定义服务器
using System; using System.Collections.Generic; using System.Linq; using System.Net; using System.Ne ...
- python之路(9)反射、包装类、动态模块导入
目录 反射 利用继承二次包装标准类 利用授权二次包装标准类 动态模块导入 反射 python提供自省的四个方法: hasattr(object,name) 判断object中有没有有个name字符串 ...
- python入门篇
第一篇:python入门 第二篇:数据类型.字符编码.文件处理 第三篇:函数 第四篇:模块与包 第五篇:常用模块 第六篇:面向对象 第七篇:面向对象高级 第八篇:异常处理 第九篇:网络编程 第十篇:并 ...
- 关于FastDBF库读写ArcGis dbf文件的小bug
该库托管于GitHub,地址:https://github.com/SocialExplorer/FastDBF 贡献者应该都是老外,所以…… 1.解析文件头,字段名部分如果有中文命名字段会出错 在D ...
- windows 下启动运行 jar 包程序
windows 下 运行 jar 包 java -jar XXX.jar java -server -Xms1024m -Xmx20480m -jar $JAR_NAME.jar windows 后台 ...
- 文件的暂存(git add)
如果我们更改了之前已经被跟踪的main.c,然后执行git status $ git status On branch master Changes not staged for commit: (u ...
- Centos7.2正常启动关闭CDH5.16.1
1.正常的启动.关闭流程 关闭流程 cluster1 stop Cloudera Management Service stop 4台agent:systemctl stop cloudera ...
- vue.js学习系列-第一篇(代码)
<html> <head> <script src="https://cdn.jsdelivr.net/npm/vue/dist/vue.js"> ...
- Android logcat lines missing原因分析
当出现类似如下错误日志时: 2019-04-14 17:51:14.506 10189-10189/com.ss.android.ex.parent D/GGK: no WonderfulVideo ...