python爬取某站磁力链
不同磁力链网站网页内容都不同,需要定制
1,并发爬取
并发爬取后,好像一会就被封了
import requests
from lxml import etree
import re
from concurrent.futures import ThreadPoolExecutor def get_mlink(url, headers):
"""输入某影片磁力链所在的网页,返回该网页中的磁力链"""
r = requests.get(url, headers=headers)
select = etree.HTML(r.text)
try:
magnetlink = select.xpath('//textarea[@id="magnetLink"]//text()')
return magnetlink[0]
except AttributeError:
return None def get_page_mlinks(url, headers):
"""输入某一页搜索结果,返回该网页中所有的元组(url, 影片大小,时间,磁力链)"""
r = requests.get(url, headers=headers)
select = etree.HTML(r.text)
div_rows = select.xpath('//div[@class="row"]') def get_each(se):
size = se.xpath('.//div[@class="col-sm-2 col-lg-1 hidden-xs text-right size"]//text()')
date = se.xpath('.//div[@class="col-sm-2 col-lg-2 hidden-xs text-right date"]//text()')
href = se.xpath('.//a/@href')
try:
return href[0], size[0], date[0], get_mlink(href[0], headers)
except IndexError:
pass with ThreadPoolExecutor() as executor: # 并发执行爬取单个网页中所有的磁力链
res = executor.map(get_each, div_rows) return res def get_urls(baseurl, headers, suffix=None):
"""输入搜索网页,递归获取所有页的搜索结果"""
if suffix:
url = baseurl + suffix
else:
url = baseurl r = requests.get(url, headers=headers)
select = etree.HTML(r.text)
page_suffixes = select.xpath('//ul[@class="pagination pagination-lg"]'
'//li//a[@name="numbar"]/@href') # 有时该站会返回/search/.../search/...search/.../page,需要处理下
p = r'/search/[^/]+/page/\d+(?=\D|$)'
page_suffixes = [re.search(p, i).group() for i in page_suffixes] # 如果还有下一页,需要进一步递归查询获取
r = requests.get(url + page_suffixes[-1], headers=headers)
select = etree.HTML(r.text)
next_page = select.xpath('//ul[@class="pagination pagination-lg"]'
'//li//a[@name="nextpage"]/@href')
if next_page:
page_suffixes = page_suffixes + get_urls(baseurl, headers, next_page[0]) return page_suffixes if __name__ == '__main__':
keyword = "金刚狼3"
baseurl = 'https://btsow.club/search/{}'.format(keyword) # 该站是采用get方式提交搜索关键词
headers = {"Accept-Language": "en-US,en;q=0.8,zh-TW;q=0.6,zh;q=0.4"} urls = get_urls(baseurl, headers)
new_urls = list(set(urls))
new_urls.sort(key=urls.index)
new_urls = [baseurl + i for i in new_urls] with ThreadPoolExecutor() as executor:
res = executor.map(get_page_mlinks, new_urls, [headers for i in range(7)]) for r in res:
for i in r:
print(i)
2,逐页爬取
手工输入关键词和页数
超过网站已有页数时,返回None
爬取单个搜索页中所有磁力链时,仍然用的是并发
import requests
from lxml import etree
from concurrent.futures import ThreadPoolExecutor def get_mlink(url, headers):
"""输入某影片磁力链所在的网页,返回该网页中的磁力链"""
r = requests.get(url, headers=headers)
select = etree.HTML(r.text)
try:
magnetlink = select.xpath('//textarea[@id="magnetLink"]//text()')
return magnetlink[0]
except AttributeError:
return None def get_page_mlinks(url, headers):
"""输入某一页搜索结果,返回该网页中所有的元组(url, 影片大小,时间,磁力链)"""
r = requests.get(url, headers=headers)
select = etree.HTML(r.text)
div_rows = select.xpath('//div[@class="row"]') def get_each(se):
size = se.xpath('.//div[@class="col-sm-2 col-lg-1 hidden-xs text-right size"]//text()')
date = se.xpath('.//div[@class="col-sm-2 col-lg-2 hidden-xs text-right date"]//text()')
href = se.xpath('.//a/@href')
try:
return href[0], size[0], date[0], get_mlink(href[0], headers)
except IndexError:
pass with ThreadPoolExecutor() as executor: # 并发执行爬取单个网页中所有的磁力链
res = executor.map(get_each, div_rows) return res if __name__ == '__main__':
keyword = input('请输入查找关键词>> ')
page = input('请输入查找页>> ') url = 'https://btsow.club/search/{}/page/{}'.format(keyword, page)
headers = {"Accept-Language": "en-US,en;q=0.8,zh-TW;q=0.6,zh;q=0.4"} r = get_page_mlinks(url, headers)
for i in r:
print(i)
3,先输入影片,在选择下载哪个磁力链
import requests
from lxml import etree def get_mlink(url, headers):
"""输入某影片磁力链所在的网页,返回该网页中的磁力链"""
r = requests.get(url, headers=headers)
select = etree.HTML(r.text)
try:
magnetlink = select.xpath('//textarea[@id="magnetLink"]//text()')
return magnetlink[0]
except AttributeError:
return None def get_row(row):
size = row.xpath('.//div[@class="col-sm-2 col-lg-1 hidden-xs text-right size"]//text()')
date = row.xpath('.//div[@class="col-sm-2 col-lg-2 hidden-xs text-right date"]//text()')
href = row.xpath('.//a/@href')
title = row.xpath('.//a/@title')
try:
return href[0], size[0], date[0], title[0]
except IndexError:
pass if __name__ == '__main__':
headers = {"Accept-Language": "en-US,en;q=0.8,zh-TW;q=0.6,zh;q=0.4"} while True:
keyword = input('请输入查找关键词>> ')
if keyword == 'quit':
break
url = 'https://btsow.club/search/{}'.format(keyword)
r = requests.get(url, headers=headers)
print(r.status_code) select = etree.HTML(r.text)
div_rows = select.xpath('//div[@class="row"]')
div_rows = [get_row(row) for row in div_rows if get_row(row)]
if not div_rows:
continue
for index, row in enumerate(div_rows):
print(index, row[2], row[1], row[3]) # 选择和下载哪部片子
choice = input('请选择下载项>> ')
try: # 如果不是数字,退回到输入关键词
choice = int(choice)
except ValueError:
continue
download_url = div_rows[choice][0]
mlink = get_mlink(download_url, headers)
print(r.status_code)
print(mlink)
print('\n\n')
执行效果:
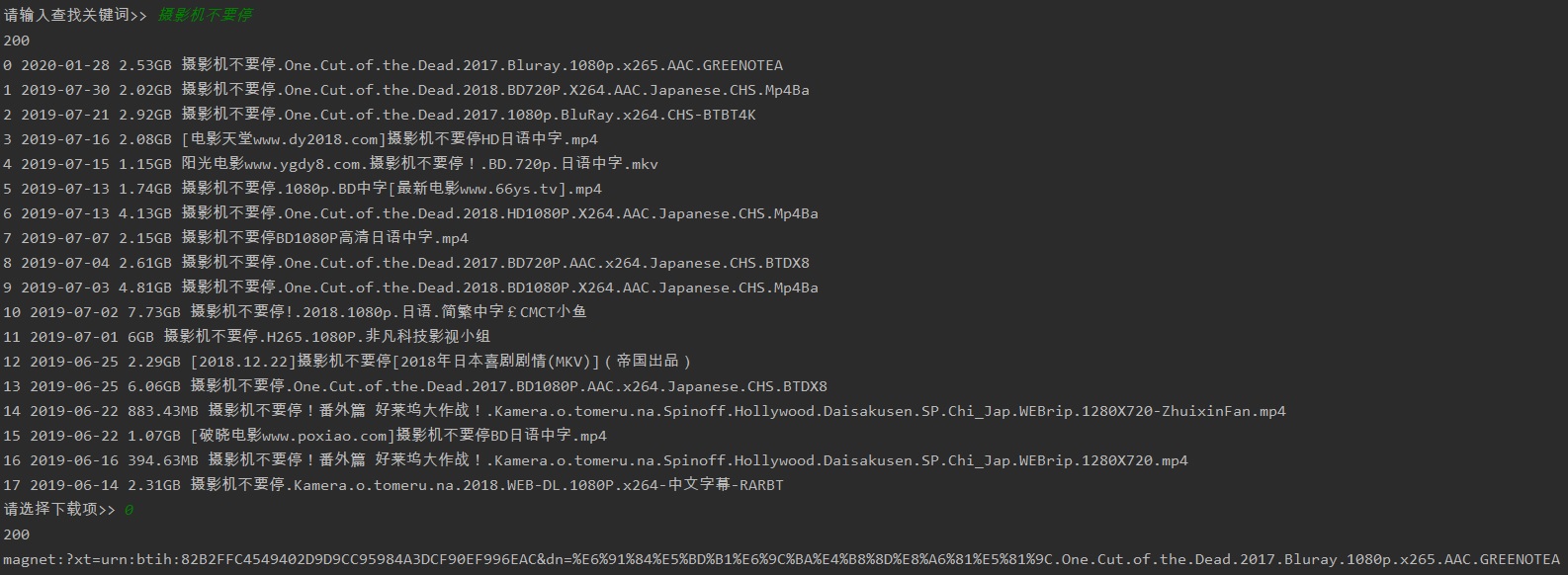
4,补充下lxml的使用
<div class="item" data-houseid="*****">
*************************************************************
</div> <div class="item" data-houseid="107102426781">
<a class="img" href="https://sh.lianjia.com/ershoufang/107102426781.html" target="_blank" data-bl="list" data-log_index="5" data-housecode="107102426781" data-is_focus="" data-el="ershoufang">
<img class="lj-lazy" src="https://s1.ljcdn.com/feroot/pc/asset/img/blank.gif?_v=20200428212347" data-original="https://image1.ljcdn.com/110000-inspection/pc1_JZKtMEOU3_1.jpg.296x216.jpg.437x300.jpg">
<div class="btn-follow follow" data-hid="107102426781"><span class="star"></span><span class="follow-text">关注</span></div>
<div class="leftArrow"><span></span></div>
<div class="rightArrow"><span></span></div><div class="price"><span>375</span>万</div>
</a>
<a class="title" href="https://sh.lianjia.com/ershoufang/107102426781.html" target="_blank" data-bl="list" data-log_index="5" data-housecode="107102426781" data-is_focus="" data-el="ershoufang">临河位置,全明户型带边窗,满五年唯一,拎包入住</a>
<div class="info">
御桥
<span>/</span>
2室1厅
<span>/</span>
50.11平米
<span>/</span>
南
<span>/</span>
精装
</div>
<div class="tag"><span class="subway">近地铁</span><span class="vr">VR房源</span></div>
</div> <div class="tag"><span class="subway">近地铁</span><span class="vr">VR房源</span></div> </div> <div class="item" data-houseid="*****">
*************************************************************
</div>
要获取所有房源tilte,价格,朝向,装修情况等,可以:
elements = select.xpath('//div[@class="item"]') # 所有房源组成的items列表,即所有class='item'的div标签
for element in elements:
title = element.xpath('a[@class="title"]/text()')[0] # class='item'的div标签下,所有class='title'的a标签
price = element.xpath('a[@class="img"]/div[@class="price"]/span/text()')[0]
_, scale, size, orient, deco = element.xpath('div[@class="info"]/text()')
print(title, price, scale, size, orient, deco)
输入某小区的结果:
中间楼层+精装保养好+满两年+双轨交汇+诚意出售 385 2室1厅 62.7平米 南 精装
南北通风,户型方正,楼层佳位置佳,11/18号线双轨 368 2室1厅 52.49平米 南 精装
一手动迁 业主置换 急售 双南采光佳 看房方便 370 2室1厅 62.7平米 南 简装
临河位置,全明户型带边窗,满五年唯一,拎包入住 375 2室1厅 50.11平米 南 精装
一手动迁,税费少,楼层采光好,精装修。 388 2室1厅 62.7平米 南 精装
南北通两房 近地铁 拎包入住 业主诚意出售 508 2室2厅 90.88平米 南 其他
python爬取某站磁力链的更多相关文章
- 萌新学习Python爬取B站弹幕+R语言分词demo说明
代码地址如下:http://www.demodashi.com/demo/11578.html 一.写在前面 之前在简书首页看到了Python爬虫的介绍,于是就想着爬取B站弹幕并绘制词云,因此有了这样 ...
- 用Python爬取B站、腾讯视频、爱奇艺和芒果TV视频弹幕!
众所周知,弹幕,即在网络上观看视频时弹出的评论性字幕.不知道大家看视频的时候会不会点开弹幕,于我而言,弹幕是视频内容的良好补充,是一个组织良好的评论序列.通过分析弹幕,我们可以快速洞察广大观众对于视频 ...
- python爬取某站新闻,并分析最近新闻关键词
在爬取某站时并做简单分析时,遇到如下问题和大家分享,避免犯错: 一丶网站的path为 /info/1013/13930.htm ,其中13930为不同新闻的 ID 值,但是这个数虽然为升序,但是没有任 ...
- 用python爬取B站在线用户人数
最近在自学Python爬虫,所以想练一下手,用python来爬取B站在线人数,应该可以拿来小小分析一下 设计思路 首先查看网页源代码,找到相应的html,然后利用各种工具(BeautifulSoup或 ...
- Python爬取B站视频信息
该文内容已失效,现已实现scrapy+scrapy-splash来爬取该网站视频及用户信息,由于B站的反爬封IP,以及网上的免费代理IP绝大部分失效,无法实现一个可靠的IP代理池,免费代理网站又是各种 ...
- python爬取b站排行榜
爬取b站排行榜并存到mysql中 目的 b站是我平时看得最多的一个网站,最近接到了一个爬虫的课设.首先要选择一个网站,并对其进行爬取,最后将该网站的数据存储并使其可视化. 网站的结构 目标网站:bil ...
- Python爬取b站任意up主所有视频弹幕
爬取b站弹幕并不困难.要得到up主所有视频弹幕,我们首先进入up主视频页面,即https://space.bilibili.com/id号/video这个页面.按F12打开开发者菜单,刷新一下,在ne ...
- Python爬取B站耗子尾汁、不讲武德出处的视频弹幕
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. 前言 耗子喂汁是什么意思什么梗呢?可能很多人不知道,这个梗是出自马保国,经常上网的人可能听说过这个 ...
- 使用python爬取P站图片
刚开学时有一段时间周末没事,于是经常在P站的特辑里收图,但是P站加载图片的速度比较感人,觉得自己身为计算机专业,怎么可以做一张张图慢慢下这么low的事,而且这样效率的确也太低了,于是就想写个程序来帮我 ...
随机推荐
- fork()相关的源码解析
fork()的真正执行采用的是do_fork()函数,所以下文将从do_fork()函数对fork()进行源码解析.下图是do_fork()的源码函数设计: 从上图我们可以看到do_fork()涉及到 ...
- python数据类型值数字类型
1.bin()函数是将十进制数转换成二进制数 2.oct()函数将十进制数转换成八进制数 3.hex()函数将十进制数转换成十六进制 数 十六进制表示:0-9 a b c d e f 4.数字 ...
- PYTHON装饰器用法及演变
'''开放封闭原则: 软件一旦上线之后就应该满足开放封闭原则 具体就是指对修改是封闭的,对扩展是开放的装饰器:什么是装饰器:装饰就是修饰,器指的是工具装饰器本省可以是任意可调用的对象被装饰的对象也可以 ...
- PHP 程序员危机(转载)
感谢有这样的机会,能和大家一起来聊聊开发者的那些事儿. 其实程序员危机是一个真实存在的问题.也有人说是互联网行业的下滑或者互联网行业已过了风口等等.我在这儿主要谈的是 PHP 程序员的危机,而这种危机 ...
- 畅捷通T+12.2升级时发生的错误及处理方法图解
前言:最近处理一个客户单位的财务数据,需要从2004年的U820版本的数据升级到畅捷通T+12.2版本.经查,该升级先要将原数据升级到T6,再从T6升级到畅捷通T+12.2版本.U820升级到T6很简 ...
- Spring boot 源码分析(前言)
开坑达人 & 断更达人的我又回来了 翻译的坑还没填完,这次再开个新坑= = 嗯,spring boot的源码分析 本坑不打算教你怎么用spring boot = = 也不打算跟你讲这玩意多方便 ...
- 三极管(如NPN)集电极正偏 发射极反偏会怎么样呢? 电流会倒流吗? 其他三种都知道,就是不知道这种情况
三极管除了你知道的放大,饱和和截止三种工作状态之外,还有一种用得极少的“倒置”工作状态,就是集电结正偏发射结反偏,这时跟对比放大状态的发射结正偏集电结反偏来理解,“倒置状态”的集电结,发射结分别充当了 ...
- 孙子兵法的计是最早的SWOT分析,《孙子兵法》首先不是战法,而是不战之法。首先不是战胜之法,而是不败之法
孙子兵法的计是最早的SWOT分析,<孙子兵法>首先不是战法,而是不战之法.首先不是战胜之法,而是不败之法 在打仗之前,你要详细地去算. 计算的目的是什么呢?孙子说,是为了知胜,就是为了知道 ...
- SQL大数据查询优化
常写的SQL可能主要以实现查询出结果为主,但如果数据量一大,就会突出SQL查询语句优化的性能独特之处.一般的数据库设计都会建索引查询,这样较全盘扫描查询的确快了不少.下面总结下SQL查询语句的几个优化 ...
- springboot使用@data注解,减少不必要代码
一.idea安装lombok插件 二.重启idea 三.添加maven依赖 <dependency> <groupId>org.projectlombok</groupI ...