Python初次实现MapReduce——WordCount
前言
Hadoop 本身是用 Java 开发的,所以之前的MapReduce代码小练都是由Java代码编写,但是通过Hadoop Streaming,我们可以使用任意语言来编写程序,让Hadoop 运行。
本文用Python语言实现了词频统计功能,最后通过Hadoop Streaming使其运行在Hadoop上。
Python写MapReduce代码
使用Python写MapReduce的“诀窍”是利用Hadoop流的API,通过STDIN(标准输入)、STDOUT(标准输出)在Map函数和Reduce函数之间传递数据。
我们唯一需要做的是利用Python的sys.stdin读取输入数据,并把我们的输出传送给sys.stdout。Hadoop流将会帮助我们处理别的任何事情。
Map阶段:mapper.py
#!/usr/bin/env python3
import sys
for line in sys.stdin:
line = line.strip()
words = line.split()
for word in words:
print("%s\t%s" % (word, 1))
Reducer阶段:reducer.py
#!/usr/bin/env python3
from operator import itemgetter
import sys current_word = None
current_count = 0
word = None for line in sys.stdin:
line = line.strip()
word, count = line.split('\t', 1)
try:
count = int(count)
except ValueError: #count如果不是数字的话,直接忽略掉
continue
if current_word == word:
current_count += count
else:
if current_word:
print("%s\t%s" % (current_word, current_count))
current_count = count
current_word = word if word == current_word: #最后一个单词
print("%s\t%s" % (current_word, current_count))
python代码放在本地即可,不需上传到HDFS。由于后面需要执行这两段代码,所以为它们增加可执行权限,即:
chmod +x mapper.py
chmod +x reducer.py
本地测试
用Hadoop Streaming的好处之一就是因为代码没有库的依赖,调试方便,可以脱离Hadoop先在本地用管道模拟调试,所以我们先在本地进行测试。
mapper.py

reducer.py

Hadoop运行
数据准备
测试文件in.txt文件内容为:
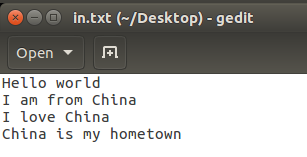
需要将其上传至HDFS,上传命令为:
bin/hadoop -copyFromLocal in.txt in.txt
Hadoop Streaming简介
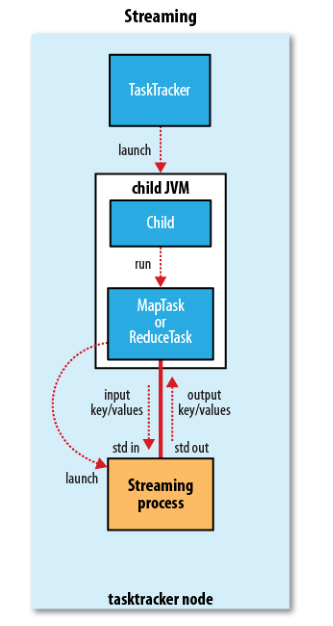
Hadoop Streaming框架,最大的好处是,让任何语言编写的map, reduce程序能够在hadoop集群上运行,map/reduce程序只要遵循从标准输入stdin读,写出到标准输出stdout即可。
它通过将其他语言编写的 mapper 和 reducer 通过参数传给一个事先写好的 Java 程序(Hadoop 自带的 *-streaming.jar),这个 Java 程序会负责创建 MR 作业,另开一个进程来运行 mapper,将得到的输入通过 stdin 传给它,再将 mapper 处理后输出到 stdout 的数据交给 Hadoop,经过 partition 和 sort 之后,再另开进程运行 reducer,同样通过 stdin/stdout 得到最终结果。因此,我们只需要在其他语言编写的程序中,通过 stdin 接收数据,再将处理过的数据输出到 stdout,Hadoop Streaming 就能通过这个 Java 的 wrapper 帮我们解决中间繁琐的步骤,运行分布式程序。
优点:
1. 可以使用自己喜欢的语言来编写 MapReduce 程序(不必非得使用 Java)
2. 不需要像写 Java 的 MR 程序那样 import 一大堆库,在代码里做很多配置,很多东西都抽象到了 stdio 上,代码量显著减少。
3. 因为没有库的依赖,调试方便,并且可以脱离 Hadoop 先在本地用管道模拟调试。
缺点:
1. 只能通过命令行参数来控制 MapReduce 框架,不像 Java 的程序那样可以在代码里使用 API,控制力比较弱。
2. 因为中间隔着一层处理,效率会比较慢。
3. 所以 Hadoop Streaming 比较适合做一些简单的任务,比如用 Python 写只有一两百行的脚本。如果项目比较复杂,或者需要进行比较细致的优化,使用 Streaming 就容易出现一些束手束脚的地方。
Hadoop Streaming运行
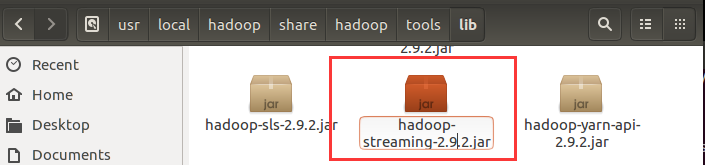
首先需要找到hadoop-streaming的位置,我的hadoop是2.x版本的,该包的位置在:
在执行的过程中遇到了权限不够的问题:

解决办法是扩大权限:

为了方便起见,接下来我就把hadoop-streaming-2.9.2.jar放在了/usr/local/hadoop目录下,所以在下面的命令中大家注意一下。
最后输入如下命令:
bin/hadoop jar /usr/local/hadoop/hadoop-streaming-2.9.2.jar\
-mapper /usr/local/hadoop/mapper.py\
-file /usr/local/hadoop/mapper.py\
-reducer /usr/local/hadoop/reducer.py\
-file /usr/local/hadoop/reducer.py\
-input in.txt\
-output out
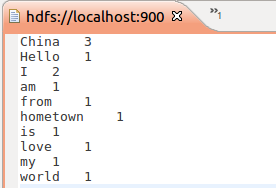
第一行是告诉Hadoop运行Streaming的Jav 程序,后面的mapper.py 和 reducer.py 是 mapper 所对应 Python 程序的路径。为了让Hadoop 将程序分发给其他机器,需要再加一个 -file 参数用于指明要分发的程序放在哪里。

Python代码优化
使用 Python 编写 Hadoop Streaming 时,在能使用 iterator 的情况下,尽量使用 iterator,避免将 stdin 的输入大量储存在内存里,否则会严重降低性能。
参考:
[1] 用python写MapReduce函数——以WordCount为例
[2] 使用Python实现Hadoop MapReduce程序
[5] 使用hadoop-streaming初体验mapreduce
[6] 使用python+hadoop-streaming编写hadoop处理程序
Python初次实现MapReduce——WordCount的更多相关文章
- Python实现MapReduce,wordcount实例,MapReduce实现两表的Join
Python实现MapReduce 下面使用mapreduce模式实现了一个简单的统计日志中单词出现次数的程序: from functools import reduce from multiproc ...
- 使用Python实现Hadoop MapReduce程序
转自:使用Python实现Hadoop MapReduce程序 英文原文:Writing an Hadoop MapReduce Program in Python 根据上面两篇文章,下面是我在自己的 ...
- [python]使用python实现Hadoop MapReduce程序:计算一组数据的均值和方差
这是参照<机器学习实战>中第15章“大数据与MapReduce”的内容,因为作者写作时hadoop版本和现在的版本相差很大,所以在Hadoop上运行python写的MapReduce程序时 ...
- MapReduce WordCount Combiner程序
MapReduce WordCount Combiner程序 注意使用Combiner之后的累加情况是不同的: pom.xml <project xmlns="http://maven ...
- [b0004] Hadoop 版hello word mapreduce wordcount 运行
目的: 初步感受一下hadoop mapreduce 环境: hadoop 2.6.4 1 准备输入文件 paper.txt 内容一般为英文文章,随便弄点什么进去 hadoop@ssmaster:~$ ...
- [b0013] Hadoop 版hello word mapreduce wordcount 运行(三)
目的: 不用任何IDE,直接在linux 下输入代码.调试执行 环境: Linux Ubuntu Hadoop 2.6.4 相关: [b0012] Hadoop 版hello word mapred ...
- [b0012] Hadoop 版hello word mapreduce wordcount 运行(二)
目的: 学习Hadoop mapreduce 开发环境eclipse windows下的搭建 环境: Winows 7 64 eclipse 直接连接hadoop运行的环境已经搭建好,结果输出到ecl ...
- Hadoop2.2.0 第一步完成MapReduce wordcount计算文本数量
1.完成Hadoop2.2.0单机版环境搭建之后需要利用一个例子程序来检验hadoop2 的mapreduce的功能 //启动hdfs和yarn sbin/start-dfs.sh sbin/star ...
- hadoop之MapReduce WordCount分析
MapReduce的设计思想 主要的思想是分而治之(divide and conquer),分治算法. 将一个大的问题切分成很多小的问题,然后在集群中的各个节点上执行,这既是Map过程.在Map过程结 ...
随机推荐
- Oracle数据泵远程导入数据
查看现存镜像目录 select * from dba_directories; 创建镜像目录 create or replace directory my_dir as 'local_dir' ; 把 ...
- python 数组中数字求和是否为零
需求是: 给定一个不少于4个元素的list(4个元素不重复): 请确认是否存在这样的4个元素,使得四数之和为0?如果有打印出符合条件的四个元素,如果没有打印False #!/usr/bin/pytho ...
- 【LeetCode每天一题】Add Binary(二进制加法)
Given two binary strings, return their sum (also a binary string).The input strings are both non-emp ...
- 时区切换导致quartz定时任务没有触发问题
时区切换对Quartz的cron表达式有影响,切换的1小时内停止触发定时任务,导致sla没有定时清空内存计数,误发限流. 美国夏令时PST切换到冬令时PDT,会有时间跳变.不带时区跳变的,会出现时间重 ...
- ubuntu 16.04 国内仓库地址
deb http://mirrors.aliyun.com/ubuntu xenial maindeb http://mirrors.aliyun.com/ubuntu xenial universe ...
- G面经Prepare: Print Zigzag Matrix
For instance, give row = 4, col = 5, print matrix in zigzag order like: [1, 8, 9, 16, 17] [2, 7, 10, ...
- PHP----------php封装的一些简单实用的方法汇总
1.xml转换成array,格式不对的xml则返回false function xml_parser($str){ $xml_parser = xml_parser_create(); i ...
- Linux系统——MHA-Atlas-MySQL高可用集群
Linux系统——MHA-Atlas-MySQL高可用集群 MHA MHA介绍MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,是一套优秀的 ...
- Cpython解释器GIL-多线程执行流程
- XML文件的读取
<?xml version="1.0" encoding="gbk"?> <!--设置编码格式为gbk--> <!DOCTYPE ...