Scrapy-下载中间件
下载中间件
下载器中间件是介于Scrapy的request/response处理的钩子框架。 是用于全局修改Scrapy request和response的一个轻量、底层的系统
编写您自己的下载器中间件
每个中间件组件是一个定义了以下一个或多个方法的Python类
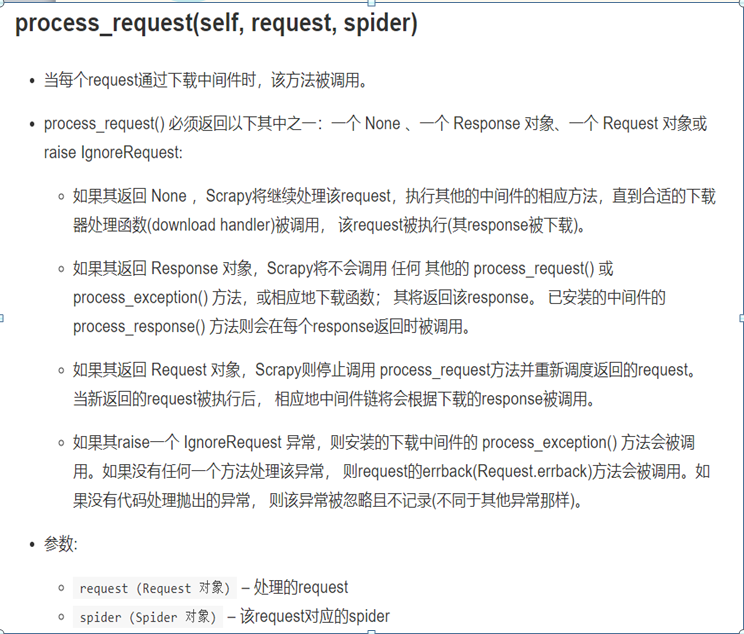

使用中间件随机选择头部信息
1. 创建项目
scrapy startproject chinaarea
2. 创建爬虫文件
scrapy genspider airs "www.aqistudy.cn"
class AirsSpider(scrapy.Spider):
name = 'airs'
allowed_domains = ['aqistudy.cn']
baseUrl = 'https://www.aqistudy.cn/historydata/'
start_urls = [baseUrl] def parse(self, response):
yield scrapy.Request(url='https://www.baidu.com',callback=self.parse)
3.创建下载中间件
from chinaarea.settings import USER_AGENTS as ua_list
import random
class UserAgentMiddleware(object):
"""
给每个请求随机选取user_Agent
"""
def process_request(self,request, spider):
user_agent = random.choice(ua_list)
request.headers['USER_AGENTS'] = user_agent
# request.meta['proxy'] 设置代理
print('request: ', request.headers['USER_AGENTS'] )
print('*'*30)
4.设置setting
USER_AGENTS = [
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3192.0 Safari/537.36Name"
] DOWNLOADER_MIDDLEWARES = {
'chinaarea.middlewares.UserAgentMiddleware': 543,
}
爬取天气网
编写item
import scrapy class ChinaareaItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass # 城市
city = scrapy.Field()
# 日期
date = scrapy.Field()
# 空气质量指数
aqi = scrapy.Field()
# 空气质量等级
level = scrapy.Field()
# pm2.5
pm2_5 = scrapy.Field()
# pm10
pm10 = scrapy.Field()
# 二氧化硫
so2 = scrapy.Field()
# 一氧化碳
co = scrapy.Field()
# 二氧化氮
no2 = scrapy.Field()
# 臭氧
o3 = scrapy.Field()
# 数据源
source = scrapy.Field()
# utctime
utc_time = scrapy.Field()
编写spider
from chinaarea.items import ChinaareaItem
class AirSpider(scrapy.Spider):
name = 'airs'
allowed_domains = ['aqistudy.cn']
base_url = "https://www.aqistudy.cn/historydata/"
start_urls = [base_url] def parse(self, response):
print("正在爬取城市信息...")
url_list = response.xpath('//div[@class="all"]/div[@class="bottom"]//a/@href').extract()[10:11]
city_list = response.xpath('//div[@class="all"]/div[@class="bottom"]//a/text()').extract()[10:11]
for city, url in zip(city_list, url_list):
link = self.base_url + url
yield scrapy.Request(url=link, callback=self.parse_month, meta={"city":city}) def parse_month(self, response):
print("正在爬取城市月份...")
url_list = response.xpath("//tr/td/a/@href").extract()[0:2]
for url in url_list:
url = self.base_url + url
yield scrapy.Request(url=url, meta={"city":response.meta['city']}, callback=self.parse_day) def parse_day(self, response):
print("爬取最终数据...")
node_list = response.xpath('//tr')
node_list.pop(0) for node in node_list:
item = ChinaareaItem()
item['city'] = response.meta['city']
item['date'] = node.xpath('./td[1]/text()').extract_first()
item['aqi'] = node.xpath('./td[2]/text()').extract_first()
item['level'] = node.xpath('./td[3]//text()').extract_first()
item['pm2_5'] = node.xpath('./td[4]/text()').extract_first()
item['pm10'] = node.xpath('./td[5]/text()').extract_first()
item['so2'] = node.xpath('./td[6]/text()').extract_first()
item['co'] = node.xpath('./td[7]/text()').extract_first()
item['no2'] = node.xpath('./td[8]/text()').extract_first()
item['o3'] = node.xpath('./td[9 ]/text()').extract_first()
yield item
编写Middleware
from selenium import webdriver
import time
import scrapy class SeleniumMiddleware(object):
def process_request(self, request, spider):
self.driver = webdriver.Chrome()
if request.url != "https://www.aqistudy.cn/historydata/":
self.driver.get(request.url)
time.sleep(2)
html = self.driver.page_source
self.driver.quit()
return scrapy.http.HtmlResponse(url=request.url, body=html, encoding="utf-8", request=request)
编写pipeline
import json
from datetime import datetime class ChinaareaPipeline(object): def process_item(self, item, spider):
item['source'] = spider.name
item['utc_time'] = str(datetime.utcnow()) return item class AreaJsonPipeline(object):
def open_spider(self, spider):
self.file = open("area.json", "w") def process_item(self, item, spider):
content = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(content)
return item def close_spider(self, spider):
self.file.close()
.设置setting
'chinaarea.middlewares.SeleiumMiddleware': 200,
ITEM_PIPELINES = {
'chinaarea.pipelines.ChinaareaPipeline':200,
'chinaarea.pipelines.AreaJsonPipeline': 300,
}

Scrapy-下载中间件的更多相关文章
- Scrapy下载中间件的优先级(神踏马值越小优先级越高)
自从之前看的一篇讲Scrapy下载中间件的文章后,一直认为设置里下载中间件的优先级数值越小,越优先,最近要抓的网站反爬增强了,所以需要使用代理ip,但是由于使用的是免费代理以至于经常失效,需要对失效的 ...
- scrapy下载中间件,UA池和代理池
一.下载中间件 框架图: 下载中间件(Downloader Middlewares) 位于scrapy引擎和下载器之间的一层组件. - 作用: (1)引擎将请求传递给下载器过程中, 下载中间件可以对请 ...
- scrapy下载中间件结合selenium抓取全国空气质量检测数据
1.所需知识补充 1.下载中间件常用函数 process_request(self, request, spider): 当每个request通过下载中间件是,该方法被调用 process_reque ...
- 爬虫(十四):scrapy下载中间件
下载器中间件是介于Scrapy的request/response处理的钩子框架,是用于全局修改Scrapy request和response的一个轻量.底层的系统. 激活Downloader Midd ...
- 爬虫系列---scrapy post请求、框架组件和下载中间件+boss直聘爬取
一 Post 请求 在爬虫文件中重写父类的start_requests(self)方法 父类方法源码(Request): def start_requests(self): for url in se ...
- python 全栈开发,Day138(scrapy框架的下载中间件,settings配置)
昨日内容拾遗 打开昨天写的DianShang项目,查看items.py class AmazonItem(scrapy.Item): name = scrapy.Field() # 商品名 price ...
- Python爬虫框架Scrapy实例(四)下载中间件设置
还是豆瓣top250爬虫的例子,添加下载中间件,主要是设置动态Uesr-Agent和代理IP Scrapy代理IP.Uesr-Agent的切换都是通过DOWNLOADER_MIDDLEWARES进行控 ...
- Scrapy——5 下载中间件常用函数、scrapy怎么对接selenium、常用的Setting内置设置有哪些
Scrapy——5 下载中间件常用的函数 Scrapy怎样对接selenium 常用的setting内置设置 对接selenium实战 (Downloader Middleware)下载中间件常用函数 ...
- scrapy基础知识之下载中间件使用案例:
1. 创建middlewares.py文件. Scrapy代理IP.Uesr-Agent的切换都是通过DOWNLOADER_MIDDLEWARES进行控制,我们在settings.py同级目录下创建m ...
- Scrapy的下载中间件
下载中间件 简介 下载器,无法执行js代码,本身不支持代理 下载中间件用来hooks进Scrapy的request/response处理过程的框架,一个轻量级的底层系统,用来全局修改scrapy的re ...
随机推荐
- ERROR 1045 (28000): Access denied for user 'ODBC'@'localhost' (using password: N O) MYSQL
ERROR 1045 (28000): Access denied for user ODBC@localhost 刚使用mysql, 碰到这个问题.. C:\Program Files\MySQL\ ...
- AR.Drone 2.0四轴飞机体验:最好的玩具航拍器
http://digi.tech.qq.com/a/20140513/007458.htm?pgv_ref=aio2012&ptlang=2052 AR.Drone 2.0四轴飞机体验:最好的 ...
- HDU 1548 A strange lift(BFS)
Problem Description There is a strange lift.The lift can stop can at every floor as you want, and th ...
- jmeter随笔(31)--RandomString和Random函数使用
在使用jmeter中,用到了一些自带的函数,后面我逐步把自己用到的分享出来,当然这些是比较简单的,也可自己看看英文文档,小怪这里只是结合自己分享. 视频介绍: https://v.qq.com/x/p ...
- 对线性模型进行最小二乘法学习的实例(使用三角多项式基函数 Python实现)
该文为个人学习时的学习笔记.最小二乘法在统计学中需要验证数据的多重共性性等问题,需要做相关的假设检验,这里我们假设一切为理想状态. 最小二乘法 一个简单的应用就是进行线性模型的拟合,一般情况下我们 ...
- RESTful API 学习
/********************************************************************************* * RESTful API 学习 ...
- liunx用户管理的基本命令
1.passwd 修改用户密码 2.useradd 用户组名 增加用户组 3.su 用户名 切换用户名 4.usermod 用户更改 5.userdel 用户删除
- OLED的相关信息
有2种方式与OLED模块相连接,一种是8080的并口方式,另一种是4线SPI方式. ALIENTEK OLED 模块的 8080 接口方式需要如下一些信号线:CS: OLED 片选信号.WR:向 OL ...
- BZOJ3473: 字符串【后缀数组+思维】
Description 给定n个字符串,询问每个字符串有多少子串(不包括空串)是所有n个字符串中至少k个字符串的子串? Input 第一行两个整数n,k. 接下来n行每行一个字符串. Output 一 ...
- HDU 5372 Segment Game (树状数组)
题意是指第i此插入操作,插入一条长度为i的线段,左端点在b[i],删除某一条线段,问每次插入操作时,被当前线段完全覆盖的线段的条数. 题解:对于新插入的线段,查询有多少个线段左端点大于等于该线段的左端 ...