第5章 pandas入门
pandas是专门为处理表格和混杂数据设计的,NumPy更适合处理统一的数值数组数据。
pandas的数据结构:
Series:Series是一种类似于一维数组的对象,它由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成。
如果只传入一个字典,则结果Series中的索引就是原字典的键(有序排列)。
pandas的isnull和notnull函数可用于检测缺失数据。
DataFrame:DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。
DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)。
DataFrame中的数据是以一个或多个二维块存放的(而不是列表、字典或别的一维数据结构)。
创建DataFrame的办法有很多,最常用的一种是直接传入一个由等长列表或NumPy数组组成的字典。
DataFrame会自动加上索引(跟Series一样),且全部列会被有序排列。
对于特别大的DataFrame,head()方法会选取前五行。
如果指定了列序列,则DataFrame的列就会按照指定顺序进行排列。
如果传入的列在数据中找不到,就会在结果中产生缺失值NaN。
通过类似字典标记的方式或属性的方式,可以将DataFrame的列获取为一个Series。
行也可以通过位置或名称的方式进行获取,比如用loc属性。
列可以通过赋值的方式进行修改。
将列表或数组赋值给某个列时,其长度必须跟DataFrame的长度相匹配。如果赋值的是一个Series,就会精确匹配DataFrame的索引,所有的空位都将被填上缺失值。
del方法可以用来删除列。
如果嵌套字典传给DataFrame,pandas就会被解释为:外层字典的键作为列,内层键则作为行索引。
DataFrame构造函数所能接受的各种数据:

跟Series一样,values属性也会以二维ndarray的形式返回DataFrame中的数据。

基本功能
重新索引:
reindex:其作用是创建一个新对象,它的数据符合新的索引。
method:可以做一些插值处理。如:ffill可以实现向前填充。

丢弃指定轴上的项:
drop(索引值):返回一个在指定轴上删除了指定值的新对象。
通过传递axis=1或axis='columns'可以删除列的值。
索引的选取和过滤:
Series索引(obj[...])的工作方式类似于NumPy数组的索引,只不过Series的索引值不只是整数。
利用标签的切片运算与普通的Python切片运算不同,其末端是包含的。
用loc和iloc进行选取:它们可以让你用类似NumPy的标记,使用轴标签(loc)或整数索引(iloc),从DataFrame选择行和列的子集。
DataFrame的索引选项
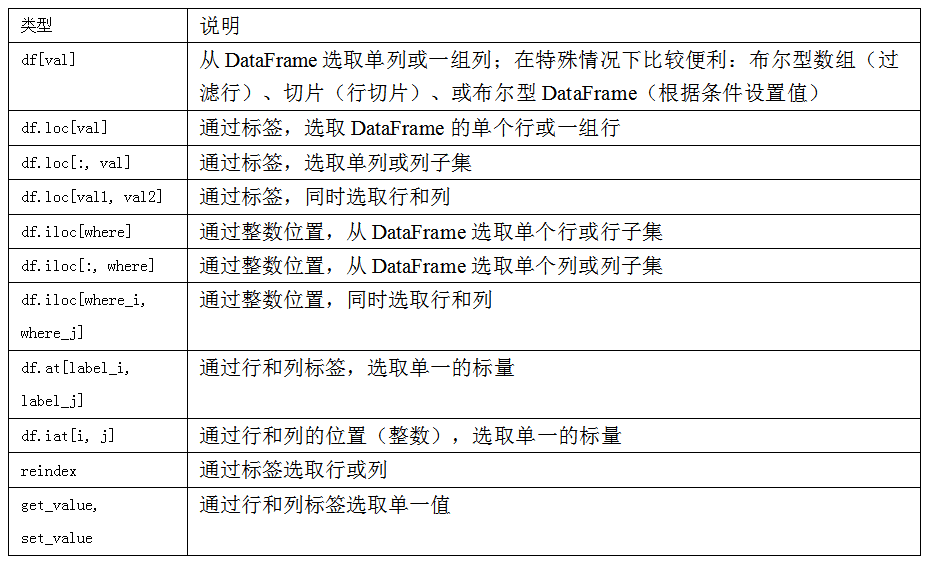
整数索引:
为了进行统一,如果轴索引含有整数,数据选取总会使用标签。为了更准确,请使用loc(标签)或iloc(整数)
算数运算和整数对齐:
pandas最重要的一个功能是,它可以对不同索引的对象进行算术运算。在将对象相加时,如果存在不同的索引对,则结果的索引就是该索引对的并集。
自动的数据对齐操作在不重叠的索引处引入了NA值,缺失值会在算术运算过程中传播。
对于DataFrame,对齐操作会同时发生在行和列上。
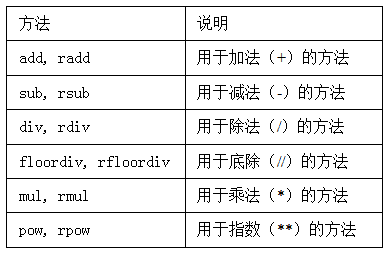
在算数方法中填充值:
在一个对象中某个轴标签在另一个对象中找不到时填充一个特殊值。
DataFrame和Series之间的运算:
DataFrame和Series之间算术运算是有明确规定的。
默认情况下,DataFrame和Series之间的算术运算会将Series的索引匹配到DataFrame的列,然后沿着行一直向下广播
如果某个索引值在DataFrame的列或Series的索引中找不到,则参与运算的两个对象就会被重新索引以形成并集。
如果你希望匹配行且在列上广播,则必须使用算术运算方法。
函数的应用和映射:
NumPy的ufuncs(元素级数组方法)也可用于操作pandas对象。
apply方法:将函数应用到由各列或行所形成的一维数组上。如果传递axis='columns'到apply,这个函数会在每行执行。
假如你想得到frame中各个浮点值的格式化字符串,使用applymap即可.
排序和排名:
sort_index方法:对行或列索引进行排序(按字典顺序),返回一个已排序的新对象。
对于DataFrame,则可以根据任意一个轴上的索引进行排序,如:frame.sort_index(axis=1)
数据默认是按升序排序的,但也可以降序排序,如:frame.sort_index(axis=1, ascending=False)
若要按值对Series进行排序,可使用其sort_values方法,如:obj.sort_values()
在排序时,任何缺失值默认都会被放到Series的末尾。
当排序一个DataFrame时,你可能希望根据一个或多个列中的值进行排序。将一个或多个列的名字传递给sort_values的by选项即可达到该目的,如:frame.sort_values(by='b')
要根据多个列进行排序,传入名称的列表即可,如:frame.sort_values(by=['a', 'b'])
默认情况下,rank是通过“为各组分配一个平均排名”的方式破坏平级关系的,根据值在原数据中出现的顺序给出排名:obj.rank(method='first'),按降序进行排名:obj.rank(ascending=False, method='max')
排名时用于破坏平级关系的方法:

带有重复标签的轴索引:
索引的is_unique属性可以判断它的值是否是唯一的。
对于带有重复值的索引,数据选取的行为将会有些不同。如果某个索引对应多个值,则返回一个Series;而对应单个值的,则返回一个标量值。
汇总和计算描述统计:
andas对象拥有一组常用的数学和统计方法。它们大部分都属于约简和汇总统计,用于从Series中提取单个值(如sum或mean)或从DataFrame的行或列中提取一个Series。跟对应的NumPy数组方法相比,它们都是基于没有缺失数据的假设而构建的。
调用DataFrame的sum方法将会返回一个含有列的和的Series。
传入axis='columns'或axis=1将会按行进行求和运算。
NA值会自动被排除,除非整个切片(这里指的是行或列)都是NA。通过skipna选项可以禁用该功能。

有些方法(如idxmin和idxmax)返回的是间接统计(比如达到最小值或最大值的索引)。
describe(描述性统计):一次性产生多个汇总统计

相关系数与协方差:
Series的corr方法用于计算两个Series中重叠的、非NA的、按索引对齐的值的相关系数。与此类似,cov用于计算协方差。
DataFrame的corr和cov方法将以DataFrame的形式分别返回完整的相关系数或协方差矩阵。
利用DataFrame的corrwith方法,你可以计算其列或行跟另一个Series或DataFrame之间的相关系数。
唯一值、值计数以及成员资格:
unique:它可以得到Series中的唯一值数组。uniques.sort()可以进行排序。
value_counts:用于计算一个Series中各值出现的频率。结果Series是按值频率降序排列的,value_counts还是一个顶级pandas方法,可用于任何数组或序列。
isin:用于判断矢量化集合的成员资格,可用于过滤Series中或DataFrame列中数据的子集。
Index.get_indexer:它可以给你一个索引数组,从可能包含重复值的数组到另一个不同值的数组。

第5章 pandas入门的更多相关文章
- < 利用Python进行数据分析 - 第2版 > 第五章 pandas入门 读书笔记
<利用Python进行数据分析·第2版>第五章 pandas入门--基础对象.操作.规则 python引用.浅拷贝.深拷贝 / 视图.副本 视图=引用 副本=浅拷贝/深拷贝 浅拷贝/深拷贝 ...
- 【学习笔记】 第05章 pandas入门
前言 上一篇学习中学成的随笔是我的第一篇随笔,撰写中有颇多不足,比如事无巨细的写入学习过程反而像是在抄书,失去了很多可读性也不利于自己反过头来复习,本章节学习需要多加注意,尽量写下较为关键的内容,犯下 ...
- 《利用python进行数据分析》读书笔记--第五章 pandas入门
http://www.cnblogs.com/batteryhp/p/5006274.html pandas是本书后续内容的首选库.pandas可以满足以下需求: 具备按轴自动或显式数据对齐功能的数据 ...
- 《利用Python进行数据分析》笔记---第5章pandas入门
写在前面的话: 实例中的所有数据都是在GitHub上下载的,打包下载即可. 地址是:http://github.com/pydata/pydata-book 还有一定要说明的: 我使用的是Python ...
- 利用Python进行数据分析 第5章 pandas入门(2)
5.2 基本功能 (1)重新索引 - 方法reindex 方法reindex是pandas对象地一个重要方法,其作用是:创建一个新对象,它地数据符合新地索引. 如,对下面的Series数据按新索引进行 ...
- 利用Python进行数据分析 第5章 pandas入门(1)
pandas库,含有使数据清洗和分析工作变得更快更简单的数据结构和操作工具.pandas是基于NumPy数组构建. pandas常结合数值计算工具NumPy和SciPy.分析库statsmodels和 ...
- 利用python进行数据分析之pandas入门
转自https://zhuanlan.zhihu.com/p/26100976 目录: 5.1 pandas 的数据结构介绍5.1.1 Series5.1.2 DataFrame5.1.3索引对象5. ...
- 利用python进行数据分析--pandas入门2
随书练习,第五章 pandas入门2 # coding: utf-8 # In[1]: from pandas import Series,DataFrame import pandas as pd ...
- 利用python进行数据分析--pandas入门1
随书练习,第五章 pandas入门1 # coding: utf-8 # In[1]: from pandas import Series, DataFrame # In[2]: import pa ...
随机推荐
- docker小demo
http://www.blogjava.net/yongboy/archive/2013/12/12/407498.html
- LINUX文件格式化读写(文件指针,缓冲)
body, table{font-family: 微软雅黑; font-size: 10pt} table{border-collapse: collapse; border: solid gray; ...
- Alphabet Cookies
Alphabet Cookies 题目描述 Kitty likes cookies very much, and especially the alphabet cookies. Now, she g ...
- 《Effective Java 第二版》读书笔记
想成为更优秀,更高效程序员,请阅读此书.总计78个条目,每个对应一个规则. 第二章 创建和销毁对象 一,考虑用静态工厂方法代替构造器 二, 遇到多个构造器参数时要考虑用builder模式 /** * ...
- 了解 .NET 的默认 TaskScheduler 和线程池(ThreadPool)设置,避免让 Task.Run 的性能急剧降低
.NET Framework 4.5 开始引入 Task.Run,它可以很方便的帮助我们使用 async / await 语法,同时还使用线程池来帮助我们管理线程.以至于我们编写异步代码可以像编写同步 ...
- 各种CTF的WP
http://l-team.org/archives/43.html PlaidCTF-2014-twenty/mtpox/doge_stege-Writeup http://l-team.org/a ...
- 网络流--最大流dinic模板
标准的大白书式模板,除了变量名并不一样……在主函数中只需要用到 init 函数.add 函数以及 mf 函数 #include<stdio.h> //差不多要加这么些头文件 #includ ...
- Nolia 给CC添加过滤器
思路: 1.使用jqurey-tagput ,做得不好看,领导不满意 2.使用bootstrap select2这个控件, 思路: 1.添加css和js的文件 2.添加标签的时候,根据id拼接标签,a ...
- SysRq魔法键的使用
SysRq魔法键的使用 1.SysRq简介它能够在系统处于极端环境时响应按键并完成相应的处理.这在大多数时候有用.SysRq 经常被称为 Magic System Request,它被定义为一系列按键 ...
- gridview 合并单元格 并原样导出数据
使用的方式都是比较简单的,asp.net 如何进行数据的导出有好多种方法,大家可以在网上找到, 一下提供一些合并并原样输出的一个简单的代码: public void ToExcel(System.We ...