scrapy-redis介绍(一)
scrapy是python里面一个非常完善的爬虫框架,实现了非常多的功能,比如内存检测,对象引用查看,命令行,shell终端,还有各种中间件和扩展等,相信开发过scrapy的朋友都会觉得这个框架非常的强大。但是它有一个致命的缺点,不支持分布式。所以本文介绍的是scrapy_redis,继承了scrapy的所有优点,还支持分布式。
1.安装scrapy
安装scrapy非常简单:
sudo pip install scrapysudo pip install scrapy_redis#如果下载的不顺利,可以试试这样,换一个国内的源,下载速度会飙升sudo pip install --index https://pypi.mirrors.ustc.edu.cn/simple/ scrapy
- 1
- 2
- 3
- 4
- 5
在这里建议开发scrapy_redis使用python 2.7版本,虽然也支持3.x,但总觉得会出bug.
安装完成,选择一个恰当的目录,并进入那个目录,运行构建项目的命令行即可自动为我们创建一个spider目录:
scrapy startproject myspider
- 1
简单的一行即可完成。scrapy有非常多的命令行,大家自行去查询官方文档。
2.scrapy_redis原理
scrapy-redis原理:
1.spider解析下载器下载下来的response,返回item或者是links
2.item或者links经过spidermiddleware的process_spider_out()方法,交给engine。
3.engine将item交给itempipeline,将links交给调度器
4.在调度器中,先将request对象利用scrapy内置的指纹函数,生成一个指纹对象
5.如果request对象中的dont_filter参数设置为False,并且该request对象的指纹不在信息指纹的队列中,那么就把该request对象放到优先级的队列中
6.从优先级队列中获取request对象,交给engine
7.engine将request对象交给下载器下载,期间会通过downloadmiddleware的process_request()方法
8.下载器完成下载,获得response对象,将该对象交给engine,期间会通过downloadmiddleware的process_response()方法
9.engine将获得的response对象交给spider进行解析,期间会经过spidermiddleware的process_spider_input()方法
10.从第一步开始循环
上面的十个步骤就是scrapy-redis的整体框架,与scrapy相差无几。本质的区别就是,将scrapy的内置的去重的队列和待抓取的request队列换成了redis的集合。就这一个小小的改动,就使得了scrapy-redis支持了分布式抓取。
在redis的服务器中,会至少存在三个队列:
a.用于请求对象去重的集合,队列的名称为spider.name:dupefilter,其中spider.name就是我们自定义的spider的名字,下同。
b.待抓取的request对象的有序集合,队列的名称为spider.name:requests
c.保存提取到item的列表,队列的名称为spider.name:items
d.可能存在存放初始url的集合或者是列表,队列的名称可能是spider.name:start_urls
如下图所示 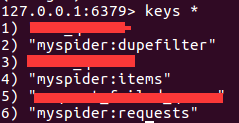
我自定义了一个spider,name属性为myspider。当开始运行这个spider的时候,就可以看到在redis的服务器中出现了三个队列的名字,分别用来去重request对象,存储提取到的item,存放待抓取的request对象。
那至于spider.name:start_urls这个队列,里面存放的是我们第一次启动爬虫存放的url,注意是url,而不是scrapy.http.Request对象。如果我们只向这个队列中存放一条初始的url,那么这个队列只会短暂的存在。因为redis中,如果一个key中没有数据了,那么这个key也就消失了。
当然,如果你本身就很了解redis的话,这对于你来说,根本就没有任何难度。
3.编写scrapy_redis爬虫
在编写基于scrapy-redis的爬虫的时候,我们既可以继承自scrapy.spiders.Spider这个类,又或者是scrapy.spiders.CrawlSpider,也可以继承自scrapy-redis的类,比如scrapy_redis.spiders.RedisSpider。
子类化scrapy自身的类时,还是按照scrapy给出的列子一样,非常的简单:
from scrapy.spiders import Spiderclass MySpider(Spider):name = 'myspider'allowed_domains = ['www.example.com']start_urls = ['http://www.example.com']def parse(self, response):#do_something_with_response
这里有一点需要明确一点,当我们没有为request对象显示的指定一个回调函数时,会使用默认的parse()作为回调函数。
运行上面的代码,我们就可以在redis服务器看到前面所说的队列了。
如果我们是子类化scrapy-redis的spider时,情况有些许的不同:
from scrapy_redis,spiders import RedisSpiderclass MySpider(RedisSpider):name = 'myspider'redis_key = 'myspider:start_urls'allowed_domains = ['www.example.com']def parse(self, response):#do_something_with_response
这里我们并没有指定初始url,所以这就需要我们手动的往redis的初始url队列中添加url,队列的名称为myspider:start_urls.默认情况下我们采用集合的命令进行添加,要不然会报错的。
sadd myspider:start_urls http://www.example.com
- 1
通过往这个队列中添加初始url,爬虫就会开始运行了。直到没有任何request对象,或者待抓取的url。
scrapy-redis介绍(一)的更多相关文章
- selenium模块使用详解、打码平台使用、xpath使用、使用selenium爬取京东商品信息、scrapy框架介绍与安装
今日内容概要 selenium的使用 打码平台使用 xpath使用 爬取京东商品信息 scrapy 介绍和安装 内容详细 1.selenium模块的使用 # 之前咱们学requests,可以发送htt ...
- Redis介绍以及安装(Linux)
Redis介绍以及安装(Linux) redis是当前比较热门的NOSQL系统之一,它是一个key-value存储系统.和Memcached类似,但很大程度补偿了memcached的不足,它支持存储的 ...
- Redis介绍及常用命令
一 Redis介绍 Redis是一个开源的使用ANSI C语言编写.支持网络.可基于内存亦可持久化的日志型.Key-Value数据库,并提供多种语言的API.从2010年3月15日起,Redis的开发 ...
- redis 介绍和常用命令
redis 介绍和常用命令 redis简介 Redis 是一款开源的,基于 BSD 许可的,高级键值 (key-value) 缓存 (cache) 和存储 (store) 系统.由于 Redis 的键 ...
- Redis介绍及Jedis测试
1.Redis简介 Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库.缓存和消息中间件. 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes ...
- redis笔记总结之redis介绍
一.Redis介绍: redis的发展历史简单的理解为因为使用类似MySql这类关系型数据库不方便进而开发的开源的.轻量级的.非关系型的,直到现在一直不断完善的一款NoSql数据库.具体的介绍大家可以 ...
- redis介绍、安装、redis持久化、redis数据类型
1.redis介绍 2.安装管网:https://redis.io/下载:wget -c http://download.redis.io/releases/redis-4.0.11.tar.gz解 ...
- scrapy -->CrawlSpider 介绍
scrapy -->CrawlSpider 介绍 1.首先,通过crawl 模板新建爬虫: scrapy genspider -t crawl lagou www.lagou.com 创建出来的 ...
- redis介绍以及安装
一.redis介绍 redis是一个key-value存储系统.和Memcached类似,它支持存储的values类型相对更多,包括字符串.列表.哈希散列表.集合,有序集合. 这些数据类型都支持pus ...
- Redis介绍以及安装(Linux)
Redis介绍以及安装(Linux) redis是当前比较热门的NOSQL系统之一,它是一个key-value存储系统.和Memcached类似,但很大程度补偿了memcached的不足,它支持存储的 ...
随机推荐
- Cocoa 初识
1,判断程序是否第一次启动 OC: if (![[NSUserDefaults stringOfKeyInStandardDefaults:FirstOpenApp] boolValue]) { [s ...
- 【maven】在IDEA上 使用maven进行打包时报错:Failed to execute goal org.apache.maven.plugins:maven-javadoc-plugin:2.10.3:jar
报错内容如下: [INFO] ------------------------------------------------------------------------ [INFO] BUILD ...
- 【Tomcat部署】Linux环境部署war包到tomcat
以turbine为例. 一.部署 1.下载或者生成war包(从maven上下载war包,并改名字为turbine.war) 2.将turbine.war拷贝到$TOMCAT_HOME/webapps中 ...
- 【附10】kibana创建新的index patterns
elk整体架构图: 一.logstash indexer 配置文件: input { stdin{} } filter { } output { elasticsearch { hosts => ...
- dp专题训练
****************************************************************************************** 动态规划 专题训练 ...
- guulp配置编译ES6
下面是gulp的配置文件,gulp具体使用点击查看 首先全局安装下 cnpm install gulp -g gulpfile.js gulp配置文件 var gulp = require(&quo ...
- BZOJ 1006: [HNOI2008]神奇的国度(弦图染色)
http://www.lydsy.com/JudgeOnline/problem.php?id=1006 题意: 思路: 这个就是弦图染色问题,弦图啥的反正我也不懂,具体看论文https://wenk ...
- LA 4254 处理器(二分+贪心)
https://icpcarchive.ecs.baylor.edu/index.php?option=com_onlinejudge&Itemid=8&page=show_probl ...
- LR学习资料
http://ajita.iteye.com/blog/1728243/ 选择哪种方式录制,有以下参考原则: 1 基于浏览器的应用程序推荐使用HTML-based Script 2 不是基于浏览器的应 ...
- Goroutines和Channels(一)
Go语言中的并发程序可以用两种手段来实现.本章讲解goroutine和channel,其支持“顺序通信进程”(communicating sequential processes)或被简称为CSP.C ...