poj 1330 Nearest Common Ancestors(LCA 基于二分搜索+st&rmq的LCA)
| Time Limit: 1000MS | Memory Limit: 10000K | |
| Total Submissions: 30147 | Accepted: 15413 |
Description
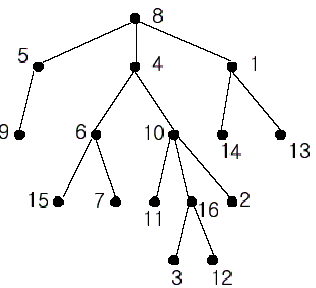
In the figure, each node is labeled with an integer from {1, 2,...,16}. Node 8 is the root of the tree. Node x is an ancestor of node y if node x is in the path between the root and node y. For example, node 4 is an ancestor of node 16. Node 10 is also an ancestor of node 16. As a matter of fact, nodes 8, 4, 10, and 16 are the ancestors of node 16. Remember that a node is an ancestor of itself. Nodes 8, 4, 6, and 7 are the ancestors of node 7. A node x is called a common ancestor of two different nodes y and z if node x is an ancestor of node y and an ancestor of node z. Thus, nodes 8 and 4 are the common ancestors of nodes 16 and 7. A node x is called the nearest common ancestor of nodes y and z if x is a common ancestor of y and z and nearest to y and z among their common ancestors. Hence, the nearest common ancestor of nodes 16 and 7 is node 4. Node 4 is nearer to nodes 16 and 7 than node 8 is.
For other examples, the nearest common ancestor of nodes 2 and 3 is node 10, the nearest common ancestor of nodes 6 and 13 is node 8, and the nearest common ancestor of nodes 4 and 12 is node 4. In the last example, if y is an ancestor of z, then the nearest common ancestor of y and z is y.
Write a program that finds the nearest common ancestor of two distinct nodes in a tree.
Input
Output
Sample Input
2
16
1 14
8 5
10 16
5 9
4 6
8 4
4 10
1 13
6 15
10 11
6 7
10 2
16 3
8 1
16 12
16 7
5
2 3
3 4
3 1
1 5
3 5
Sample Output
4
3
Source
#include<iostream>
#include<vector>
#include<cstdio>
#include<cmath>
#include<algorithm>
using namespace std;
const int N=;
const int logN=;
vector<int> G[N];
int root;
int parent[][N];
int fa[N],n,x,y,s,t;
int depth[N]; void dfs(int v,int p,int d)
{
parent[][v]=p;
depth[v]=d;
for(int i=;i<G[v].size();i++)
if (G[v][i]!=p)
{
fa[G[v][i]]=v;
dfs(G[v][i],v,d+);
}
}
void init(int V)
{
int root;
for(int i=;i<=n;i++)
if (fa[i]==) {root=i; break;}
dfs(root,-,);
for(int k=;k+<logN;k++)
{
for(int v=;v<=V;v++)
{
if(parent[k][v]<) parent[k+][v]=-;
else parent[k+][v]=parent[k][parent[k][v]];
}
}
}
int lca(int u,int v)
{
if (depth[u]>depth[v]) swap(u,v);
for(int k=;k<logN;k++)
{
if ((depth[v]-depth[u])>>k & )
v=parent[k][v];
}
if (u==v) return u;
for(int k=logN-;k>=;k--)
{
if (parent[k][u]!=parent[k][v])
{
u=parent[k][u];
v=parent[k][v];
}
}
return parent[][u];
}
int main()
{
int T;
scanf("%d",&T);
while(T--)
{
scanf("%d",&n);
for(int i=;i<=n;i++) {G[i].clear(); fa[i]=;}
for(int i=;i<=n-;i++)
{
scanf("%d%d",&x,&y);
G[x].push_back(y);
fa[y]=x;
}
init(n);
scanf("%d%d",&s,&t);
int croot=lca(s,t);
printf("%d\n",croot);
}
return ;
}
ST&RMQ 的LCA
#include<iostream>
#include<vector>
#include<cstdio>
#include<cmath>
#include<algorithm>
#include<cstring>
using namespace std;
const int N=;
const int M=;
int tot,cnt,n,T,s,t;
int head[N]; //记录i节点在e数组中的其实位置
int ver[*N]; //ver:保存遍历的节点序列,长度为2n-1,从下标1开始保存
int R[*N]; // R:和遍历序列对应的节点深度数组,长度为2n-1,从下标1开始保存
int first[N]; //first:每个节点在遍历序列中第一次出现的位置
bool vis[N]; //遍历时的标记数组
int dp[*N][M],fa[N]; struct edge
{
int u,v,next;
}e[*N];
void dfs(int u ,int dep)
{
vis[u] = true;
ver[++tot] = u;
first[u] = tot;
R[tot] = dep;
for(int k=head[u]; k!=-; k=e[k].next)
if( !vis[e[k].v] ) //这里可以省个vis数组,如果在dfs改成dfs(当前节点,当前节点的父亲,当前节点的深度) 具体可以参照connections with cities {
int v=e[k].v;
dfs(v,dep+);
ver[++tot]=u;
R[tot]=dep;
}
}
void ST(int n)
{
for(int i=;i<=n;i++)
dp[i][] = i;
for(int j=;(<<j)<=n;j++)
{
for(int i=;i+(<<j)-<=n;i++)
{
int a = dp[i][j-] , b = dp[i+(<<(j-))][j-];
dp[i][j] = R[a]<R[b]?a:b;
}
}
} int RMQ(int l,int r)
{
int k=(int)(log((double)(r-l+))/log(2.0));
int a = dp[l][k], b = dp[r-(<<k)+][k]; //保存的是编号
return R[a]<R[b]?a:b;
} int LCA(int u ,int v)
{
int x = first[u] , y = first[v];
if(x > y) swap(x,y);
int res = RMQ(x,y);
return ver[res];
} void addedge(int u,int v)
{
e[++cnt].u=u;
e[cnt].v=v;
e[cnt].next=head[u];
head[u]=cnt;
} int main()
{
int T;
scanf("%d",&T);
while(T--)
{
scanf("%d",&n);
memset(head,-,sizeof(head));
memset(vis,,sizeof(vis));
memset(fa,,sizeof(fa));
cnt=; tot=;
for(int i=;i<n;i++)
{
int x,y;
scanf("%d%d",&x,&y);
addedge(x,y);
fa[y]=x;
}
for(int i=;i<=n;i++)
if (fa[i]==) { dfs(i,); break;}
ST(*n-);
scanf("%d%d",&s,&t);
printf("%d\n",LCA(s,t));
}
return ;
}
poj 1330 Nearest Common Ancestors(LCA 基于二分搜索+st&rmq的LCA)的更多相关文章
- POJ 1330 Nearest Common Ancestors / UVALive 2525 Nearest Common Ancestors (最近公共祖先LCA)
POJ 1330 Nearest Common Ancestors / UVALive 2525 Nearest Common Ancestors (最近公共祖先LCA) Description A ...
- POJ - 1330 Nearest Common Ancestors(基础LCA)
POJ - 1330 Nearest Common Ancestors Time Limit: 1000MS Memory Limit: 10000KB 64bit IO Format: %l ...
- POJ.1330 Nearest Common Ancestors (LCA 倍增)
POJ.1330 Nearest Common Ancestors (LCA 倍增) 题意分析 给出一棵树,树上有n个点(n-1)条边,n-1个父子的边的关系a-b.接下来给出xy,求出xy的lca节 ...
- POJ 1330 Nearest Common Ancestors(lca)
POJ 1330 Nearest Common Ancestors A rooted tree is a well-known data structure in computer science a ...
- POJ 1330 Nearest Common Ancestors 倍增算法的LCA
POJ 1330 Nearest Common Ancestors 题意:最近公共祖先的裸题 思路:LCA和ST我们已经很熟悉了,但是这里的f[i][j]却有相似却又不同的含义.f[i][j]表示i节 ...
- LCA POJ 1330 Nearest Common Ancestors
POJ 1330 Nearest Common Ancestors Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 24209 ...
- POJ 1330 Nearest Common Ancestors 【LCA模板题】
任意门:http://poj.org/problem?id=1330 Nearest Common Ancestors Time Limit: 1000MS Memory Limit: 10000 ...
- POJ 1330 Nearest Common Ancestors (LCA,dfs+ST在线算法)
Nearest Common Ancestors Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 14902 Accept ...
- POJ 1330 Nearest Common Ancestors(Targin求LCA)
传送门 Nearest Common Ancestors Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 26612 Ac ...
随机推荐
- 卸载vs2017
卸载enterprise版本 Microsoft.FSharp.SDK.Core卸载失败Package 'Microsoft.FSharp.SDK.Core,version=15.7.20180605 ...
- 51nod 1137 矩阵乘法
基本的矩阵乘法 中间for(int j=0;i<n;i++) //这里写错了 应该是j<n 晚上果然 效率不行 等会早点儿睡 //矩阵乘法 就是 两个矩阵 第一个矩阵的列 等与 第 ...
- 51nod 1080 两个数的平方和
没心情写数学题啦啊 好难啊 #include<bits/stdc++.h> using namespace std; set<int> s; set<int>: ...
- spring实现定时任务的两种方式
本文为博主原创,未经允许不得转载 项目中要经常事项定时功能,在网上学习了下用spring的定时功能,基本有两种方式,在这里进行简单的总结, 以供后续参考,此篇只做简单的应用. 1.在spring-se ...
- java面试项目经验:框架及应用
Java项目经验 Java就是用来做项目的!Java的主要应用领域就是企业级的项目开发!要想从事企业级的项目开发,你必须掌握如下要点:1.掌握项目开发的基本步骤2.具备极强的面向对象的分析与设计技巧3 ...
- 分布式事务之——tcc-transaction分布式TCC型事务框架搭建与实战案例(基于Dubbo/Dubbox)
转载请注明出处:http://blog.csdn.net/l1028386804/article/details/73731363 一.背景 有一定分布式开发经验的朋友都知道,产品/项目/系统最初为了 ...
- UVa 10603 倒水问题
https://vjudge.net/problem/UVA-10603 题意:三个杯子,倒水问题.找出最少倒水量. 思路:路径寻找问题.不难,暴力枚举. #include<iostream&g ...
- asp.net <asp:Repeater>下的 asp:LinkButton CommandArgument点击事件
前台 <asp:Repeater ID="rptData" runat="server" OnItemCommand="rptData_Item ...
- MarkChanges: Jmeter
1. 20180627 调整启动的内存set HEAP=-Xms1024m -Xmx1024m2. 20180627 调整输出格式为xml #jmeter.save.saveservice.outpu ...
- Python day17 模块介绍1(time,random)
module模块和包的介绍(略掉了) 常用模块 # time模块 import time print(time.time())#时间戳,在1970年开始到现在一共多少秒 print(time.gmti ...