day43 数据库知识欠缺的
一 什么是存储引擎
mysql中建立的库===>文件夹 库中建立的表===>文件 现实生活中我们用来存储数据的文件有不同的类型,每种文件类型对应各自不同的处理机制:比如处理文本用txt类型,处理表格用excel,处理图片用png等 数据库中的表也应该有不同的类型,表的类型不同,会对应mysql不同的存取机制,表类型又称为存储引擎。 存储引擎说白了就是如何存储数据、如何为存储的数据建立索引和如何更新、查询数据等技术的实现方
法。因为在关系数据库中数据的存储是以表的形式存储的,所以存储引擎也可以称为表类型(即存储和
操作此表的类型) 在Oracle 和SQL Server等数据库中只有一种存储引擎,所有数据存储管理机制都是一样的。而MySql
数据库提供了多种存储引擎。用户可以根据不同的需求为数据表选择不同的存储引擎,用户也可以根据
自己的需要编写自己的存储引擎
MySQL存储引擎介绍
#InnoDB 存储引擎
支持事务,其设计目标主要面向联机事务处理(OLTP)的应用。其
特点是行锁设计、支持外键,并支持类似 Oracle 的非锁定读,即默认读取操作不会产生锁。 从 MySQL 5.5.8 版本开始是默认的存储引擎。
InnoDB 存储引擎将数据放在一个逻辑的表空间中,这个表空间就像黑盒一样由 InnoDB 存储引擎自身来管理。从 MySQL 4.1(包括 4.1)版本开始,可以将每个 InnoDB 存储引擎的 表单独存放到一个独立的 ibd 文件中。此外,InnoDB 存储引擎支持将裸设备(row disk)用 于建立其表空间。
InnoDB 通过使用多版本并发控制(MVCC)来获得高并发性,并且实现了 SQL 标准 的 4 种隔离级别,默认为 REPEATABLE 级别,同时使用一种称为 netx-key locking 的策略来 避免幻读(phantom)现象的产生。除此之外,InnoDB 存储引擎还提供了插入缓冲(insert buffer)、二次写(double write)、自适应哈希索引(adaptive hash index)、预读(read ahead) 等高性能和高可用的功能。
对于表中数据的存储,InnoDB 存储引擎采用了聚集(clustered)的方式,每张表都是按 主键的顺序进行存储的,如果没有显式地在表定义时指定主键,InnoDB 存储引擎会为每一 行生成一个 6 字节的 ROWID,并以此作为主键。
InnoDB 存储引擎是 MySQL 数据库最为常用的一种引擎,Facebook、Google、Yahoo 等 公司的成功应用已经证明了 InnoDB 存储引擎具备高可用性、高性能以及高可扩展性。对其 底层实现的掌握和理解也需要时间和技术的积累。如果想深入了解 InnoDB 存储引擎的工作 原理、实现和应用,可以参考《MySQL 技术内幕:InnoDB 存储引擎》一书。 #MyISAM 存储引擎
不支持事务、表锁设计、支持全文索引,主要面向一些 OLAP 数 据库应用,在 MySQL 5.5.8 版本之前是默认的存储引擎(除 Windows 版本外)。数据库系统 与文件系统一个很大的不同在于对事务的支持,MyISAM 存储引擎是不支持事务的。究其根 本,这也并不难理解。用户在所有的应用中是否都需要事务呢?在数据仓库中,如果没有 ETL 这些操作,只是简单地通过报表查询还需要事务的支持吗?此外,MyISAM 存储引擎的 另一个与众不同的地方是,它的缓冲池只缓存(cache)索引文件,而不缓存数据文件,这与 大多数的数据库都不相同。 #NDB 存储引擎
2003 年,MySQL AB 公司从 Sony Ericsson 公司收购了 NDB 存储引擎。 NDB 存储引擎是一个集群存储引擎,类似于 Oracle 的 RAC 集群,不过与 Oracle RAC 的 share everything 结构不同的是,其结构是 share nothing 的集群架构,因此能提供更高级别的 高可用性。NDB 存储引擎的特点是数据全部放在内存中(从 5.1 版本开始,可以将非索引数 据放在磁盘上),因此主键查找(primary key lookups)的速度极快,并且能够在线添加 NDB 数据存储节点(data node)以便线性地提高数据库性能。由此可见,NDB 存储引擎是高可用、 高性能、高可扩展性的数据库集群系统,其面向的也是 OLTP 的数据库应用类型。 #Memory 存储引擎
正如其名,Memory 存储引擎中的数据都存放在内存中,数据库重 启或发生崩溃,表中的数据都将消失。它非常适合于存储 OLTP 数据库应用中临时数据的临时表,也可以作为 OLAP 数据库应用中数据仓库的维度表。Memory 存储引擎默认使用哈希 索引,而不是通常熟悉的 B+ 树索引。 #Infobright 存储引擎
第三方的存储引擎。其特点是存储是按照列而非行的,因此非常 适合 OLAP 的数据库应用。其官方网站是 http://www.infobright.org/,上面有不少成功的数据 仓库案例可供分析。 #NTSE 存储引擎
网易公司开发的面向其内部使用的存储引擎。目前的版本不支持事务, 但提供压缩、行级缓存等特性,不久的将来会实现面向内存的事务支持。 #BLACKHOLE
黑洞存储引擎,可以应用于主备复制中的分发主库。 MySQL 数据库还有很多其他存储引擎,上述只是列举了最为常用的一些引擎。如果 你喜欢,完全可以编写专属于自己的引擎,这就是开源赋予我们的能力,也是开源的魅 力所在。
1、整数类型
整数类型:TINYINT SMALLINT MEDIUMINT INT BIGINT
作用:存储年龄,等级,id,各种号码等
int[(m)][unsigned][zerofill]
整数,数据类型用于保存一些范围的整数数值范围:
有符号: 默认有符号
-2147483648 ~ 2147483647
无符号: creact table t1 (money int unsigned)
0 ~ 4294967295
=======================================
bigint[(m)][unsigned][zerofill]
大整数,数据类型用于保存一些范围的整数数值范围:
有符号:
-9223372036854775808 ~ 9223372036854775807
无符号:
0 ~ 18446744073709551615
=========有符号和无符号tinyint==========
#tinyint默认为有符号
MariaDB [db1]> create table t1(x tinyint); #默认为有符号,即数字前有正负号
MariaDB [db1]> desc t1;
MariaDB [db1]> insert into t1 values
-> (-129),
-> (-128),
-> (127),
-> (128);
MariaDB [db1]> select * from t1;
+------+
| x |
+------+
| -128 | #-129存成了-128
| -128 | #有符号,最小值为-128
| 127 | #有符号,最大值127
| 127 | #128存成了127
+------+ #设置无符号tinyint
MariaDB [db1]> create table t2(x tinyint unsigned);
MariaDB [db1]> insert into t2 values
-> (-1),
-> (0),
-> (255),
-> (256);
MariaDB [db1]> select * from t2;
+------+
| x |
+------+
| 0 | -1存成了0
| 0 | #无符号,最小值为0
| 255 | #无符号,最大值为255
| 255 | #256存成了255
+------+ ============有符号和无符号int=============
#int默认为有符号
MariaDB [db1]> create table t3(x int); #默认为有符号整数
MariaDB [db1]> insert into t3 values
-> (-2147483649),
-> (-2147483648),
-> (2147483647),
-> (2147483648);
MariaDB [db1]> select * from t3;
+-------------+
| x |
+-------------+
| -2147483648 | #-2147483649存成了-2147483648
| -2147483648 | #有符号,最小值为-2147483648
| 2147483647 | #有符号,最大值为2147483647
| 2147483647 | #2147483648存成了2147483647
+-------------+ #设置无符号int
MariaDB [db1]> create table t4(x int unsigned);
MariaDB [db1]> insert into t4 values
-> (-1),
-> (0),
-> (4294967295),
-> (4294967296);
MariaDB [db1]> select * from t4;
+------------+
| x |
+------------+
| 0 | #-1存成了0
| 0 | #无符号,最小值为0
| 4294967295 | #无符号,最大值为4294967295
| 4294967295 | #4294967296存成了4294967295
+------------+ ==============有符号和无符号bigint=============
MariaDB [db1]> create table t6(x bigint);
MariaDB [db1]> insert into t5 values
-> (-9223372036854775809),
-> (-9223372036854775808),
-> (9223372036854775807),
-> (9223372036854775808); MariaDB [db1]> select * from t5;
+----------------------+
| x |
+----------------------+
| -9223372036854775808 |
| -9223372036854775808 |
| 9223372036854775807 |
| 9223372036854775807 |
+----------------------+ MariaDB [db1]> create table t6(x bigint unsigned);
MariaDB [db1]> insert into t6 values
-> (-1),
-> (0),
-> (18446744073709551615),
-> (18446744073709551616); MariaDB [db1]> select * from t6;
+----------------------+
| x |
+----------------------+
| 0 |
| 0 |
| 18446744073709551615 |
| 18446744073709551615 |
+----------------------+ ======用zerofill测试整数类型的显示宽度=============
MariaDB [db1]> create table t7(x int(3) zerofill);
MariaDB [db1]> insert into t7 values
-> (1),
-> (11),
-> (111),
-> (1111);
MariaDB [db1]> select * from t7;
+------+
| x |
+------+
| 001 |
| 011 |
| 111 |
| 1111 | #超过宽度限制仍然可以存
+------+
注意:为该类型指定宽度时,仅仅只是指定查询结果的显示宽度,与存储范围无关,存储范围如下
其实我们完全没必要为整数类型指定显示宽度,使用默认的就可以了
默认的显示宽度,都是在最大值的基础上加1

int的存储宽度是4个Bytes,即32个bit,即2**32
无符号最大值为:4294967296-1
有符号最大值:2147483648-1
有符号和无符号的最大数字需要的显示宽度均为10,而针对有符号的最小值则需要11位才能显示完全,所以int类型默认的显示宽度为11是非常合理的
最后:整形类型,其实没有必要指定显示宽度,使用默认的就ok
2、浮点型
定点数类型 DEC等同于DECIMAL(这个常用在钱上)
浮点类型:FLOAT DOUBLE
作用:存储薪资、身高、体重、体质参数等
DECIMA (常用于记录钱)decimal(a,b) a代表长度,b代表小数位的个数 4,1 就是总长度为4 小数位有一个数 当数字为1234.5时会报错 因为整数位只能为三
#FLOAT[(M,D)] [UNSIGNED] [ZEROFILL] 定义:
单精度浮点数(非准确小数值),m是数字总个数,d是小数点后个数。m最大值为255,d最大值为30 有符号:
-3.402823466E+38 to -1.175494351E-38,
1.175494351E-38 to 3.402823466E+38
无符号:
1.175494351E-38 to 3.402823466E+38 精确度:
**** 随着小数的增多,精度变得不准确 **** ======================================
#DOUBLE[(M,D)] [UNSIGNED] [ZEROFILL] 定义:
双精度浮点数(非准确小数值),m是数字总个数,d是小数点后个数。m最大值为255,d最大值为30 有符号:
-1.7976931348623157E+308 to -2.2250738585072014E-308
2.2250738585072014E-308 to 1.7976931348623157E+308 无符号:
2.2250738585072014E-308 to 1.7976931348623157E+308 精确度:
****随着小数的增多,精度比float要高,但也会变得不准确 **** ======================================
decimal[(m[,d])] [unsigned] [zerofill] 定义:
准确的小数值,m是数字总个数(负号不算),d是小数点后个数。 m最大值为65,d最大值为30。 精确度:
**** 随着小数的增多,精度始终准确 ****
对于精确数值计算时需要用此类型
decaimal能够存储精确值的原因在于其内部按照字符串存储。
复制代码
3、位类型(了解)
BIT(M)可以用来存放多位二进制数,M范围从1~64,如果不写默认为1位。
注意:对于位字段需要使用函数读取
bin()显示为二进制
hex()显示为十六进制
三 日期类型
DATE TIME DATETIME TIMESTAMP YEAR
作用:存储用户注册时间,文章发布时间,员工入职时间,出生时间,过期时间等
类型和它对应打印出来的内容
datetime/timestamp(注册时间):2017-11-11 11:11:11
date(出生日期):2017-11-11
time(上课时间):11:11:11
year:2017 实例如下 ↓
create table student(reg_time datetime,brith date,class_time time,born_year year);
insert into student values(now(),now(),now(),now())
insert into student values(20170301111111,'2017-03-01',111111,1999);
四 字符串类型
#注意:char和varchar括号内的参数指的都是字符的长度 #char类型:定长,简单粗暴,浪费空间,存取速度快
字符长度范围:0-255(一个中文是一个字符,是utf8编码的3个字节)
存储:
存储char类型的值时,会往右填充空格来满足长度
例如:指定长度为10,存>10个字符则报错,存<10个字符则用空格填充直到凑够10个字符存储 检索:
在检索或者说查询时,查出的结果会自动删除尾部的空格,除非我们打开pad_char_to_full_length SQL模式(SET sql_mode = 'PAD_CHAR_TO_FULL_LENGTH';) #varchar类型:变长,精准,节省空间,存取速度慢
字符长度范围:0-65535(如果大于21845会提示用其他类型 。mysql行最大限制为65535字节,字符编码为utf-8:
https://dev.mysql.com/doc/refman/5.7/en/column-count-limit.html)
存储:
varchar类型存储数据的真实内容,不会用空格填充,如果'ab ',尾部的空格也会被存起来
强调:varchar类型会在真实数据前加1-2Bytes的前缀,该前缀用来表示真实数据的bytes字节数(
1-2Bytes最大表示65535个数字,正好符合mysql对row的最大字节限制,即已经足够使用)
如果真实的数据<255bytes则需要1Bytes的前缀(1Bytes=8bit 2**8最大表示的数字为255)
如果真实的数据>255bytes则需要2Bytes的前缀(2Bytes=16bit 2**16最大表示的数字为65535) 检索:
尾部有空格会保存下来,在检索或者说查询时,也会正常显示包含空格在内的内容
复制代码
1. char填充空格来满足固定长度,但是在查询时却会很不要脸地删除尾部的空格(装作自己好像没有浪费过空间一样),然后修改sql_mode让其现出原形
2. 虽然 CHAR 和 VARCHAR 的存储方式不太相同,但是对于两个字符串的比较,都只比 较其值,忽略 CHAR 值存在的右填充,即使将 SQL _MODE 设置为 PAD_CHAR_TO_FULL_ LENGTH 也一样,,但这不适用于like
3. 总结
#常用字符串系列:char与varchar
注:虽然varchar使用起来较为灵活,但是从整个系统的性能角度来说,char数据类型的处理速度更快,有时甚至可以超出varchar处理速度的50% 。因此,用户在设计数据库时应当综合考虑各方面的因素,以求达到最佳的平衡 #其他字符串系列(效率:char>varchar>text)
TEXT系列 TINYTEXT TEXT MEDIUMTEXT LONGTEXT
BLOB 系列 TINYBLOB BLOB MEDIUMBLOB LONGBLOB
BINARY系列 BINARY VARBINARY text:text数据类型用于保存变长的大字符串,可以组多到65535 (2**16 − 1)个字符。
mediumtext:A TEXT column with a maximum length of 16,777,215 (2**24 − 1) characters.
longtext:A TEXT column with a maximum length of 4,294,967,295 or 4GB (2**32 − 1) character
五 枚举类型与集合类型
字段的值只能在给定范围中选择,如单选框,多选框
enum 单选 只能在给定的范围内选一个值,如性别 sex 男male/女female
set 多选 在给定的范围内可以选择一个或一个以上的值(爱好1,爱好2,爱好3...)
枚举类型(enum)
An ENUM column can have a maximum of 65,535 distinct elements. (The practical limit is less than 3000.)
示例:
CREATE TABLE shirts (
name VARCHAR(40),
size ENUM('x-small', 'small', 'medium', 'large', 'x-large')
);
INSERT INTO shirts (name, size) VALUES ('dress shirt','large'), ('t-shirt','medium'),('polo shirt','small'); 集合类型(set)
A SET column can have a maximum of 64 distinct members.
示例:
CREATE TABLE myset (col SET('a', 'b', 'c', 'd'));
INSERT INTO myset (col) VALUES ('a,d'), ('d,a'), ('a,d,a'), ('a,d,d'), ('d,a,d');
给mysql添加环境变量
并且执行时候在 cmd 窗口中输入的名字就是应用程序的名字 mysql 如果程序名字写的是mysql1 那么就写这个名字
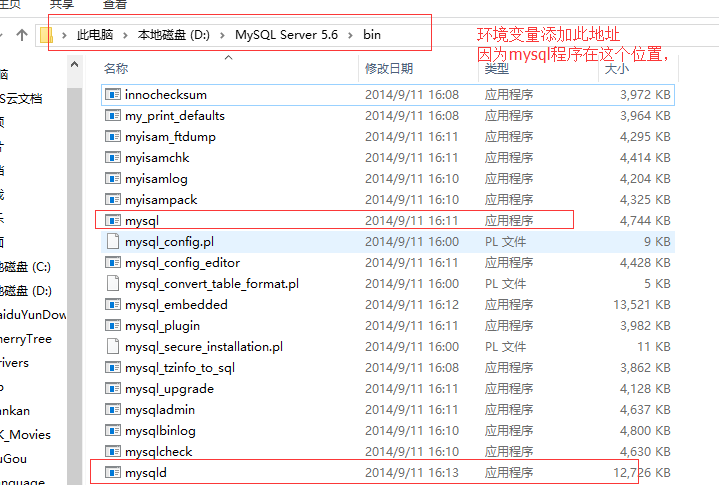
外键:
1表的创建顺序,先创建被关联的表 再创建另外的表
二.对应关系
一对一(如,潜在客户人员信息表和客户信息表)
一对多 (如 课程和学生是一对多的关系,被关联的表就是课程,学生是表)
多对多(这时候需要加一个表,
day43 数据库知识欠缺的的更多相关文章
- Oracle 数据库知识汇总篇
Oracle 数据库知识汇总篇(更新中..) 1.安装部署篇 2.管理维护篇 3.数据迁移篇 4.故障处理篇 5.性能调优篇 6.SQL PL/SQL篇 7.考试认证篇 8.原理体系篇 9.架构设计篇 ...
- Vertica 数据库知识汇总篇
Vertica 数据库知识汇总篇(更新中..) 1.Vertica 集群软件部署,各节点硬件性能测试 2.Vertica 创建数据库,创建业务用户测试 3.Vertica 数据库参数调整,资源池分配 ...
- 数据库知识整理<八>
联接: 8.1理解简单的单联接: 基本上联接的结果是每个集合的笛卡尔积.例如:两个集合{a,b,c}和{a,b}的笛卡尔积是如下的成对集合:{(a,a),(a,b),(b,a),(b,b),(c,a) ...
- 数据库知识整理<五>
简单的数据查询: 5.1查询的基本结构: Sql语句:select [distinct] (* | column [alias],...) from table [where condition] [ ...
- 数据库知识整理<二>
又继续写的博客,希望自己能坚持每天写博客.分享自己的点滴,对自己成长有帮助.今天下午高强度打了三个小时篮球,小腿都抽筋了.很爽,失落的心情似乎变得开明了一些.想到了一句话:“像SB式的坚持总会有好的收 ...
- 数据库知识整理<一>
关系型数据库知识整理: 一,关系型数据库管理系统简介: 1.1使用数据库的原因: 降低存储数据的冗余度 提高数据的一致性 可以建立数据库所遵循的标准 储存数据可以共享 便于维护数据的完整性 能够实现数 ...
- Mysql数据库知识-Mysql索引总结 mysql mysql数据库 mysql函数
mysql数据库知识-Mysql索引总结: 索引(Index)是帮助MySQL高效获取数据的数据结构. 下边是自己整理的资料与自己的学习总结,,做一个汇总. 一.真的有必要使用索引吗? 不是每一个性能 ...
- MongDB篇,第四章:数据库知识4
MongDB 数据库知识4 GridFS 大文件存储 文件的数据库存储 1,在数据库中以 字符串的方式 存储文件在本地的路径: 优点: 节省数据库空间 缺点: 当数据库或者文件位置发生变化时则无 ...
- MongDB篇,第三章:数据库知识3
MongDB 数据库知识3 修改器 $inc 对某个域的值进行加减修改 $mul 对某个域的值进行乘法修改 $min 如果筛选的文档指定的值小于min则不修改,如果大于min 给定的值则修改为m ...
随机推荐
- Confluence 6 快捷键
快捷键图标. 官方的下载地址为:https://atlassianblog.wpengine.com/wp-content/uploads/2018/01/keyboard-shortcuts-inf ...
- C++&C#外挂(内存修改)
大学时候因为主修C#语言(当然现在做的是javaweb开发),那时在网上学了用C#做外挂的教程,外挂嘛,大家都懂的.这里只是低级的修改内存,不涉及到截获数据包.如果是欺骗服务器,修改服务器数据,那就难 ...
- windows下apache利用SSL来配置https
第一步打开httpd.conf文件找到以下两个变量把注释去掉. #LoadModule ssl_module modules/mod_ssl.so (去掉前面的#号) #Include conf/ex ...
- hdu-4023-博弈(模拟)
Game Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65768/65768 K (Java/Others)Total Submis ...
- POJ-2415 Hike on a Graph (BFS)
Description "Hike on a Graph" is a game that is played on a board on which an undirected g ...
- 如何用SPY++工具查看窗体的句柄
我安装的是vs2012,先找到SPY++工具打开 打开方式: 方式1:通过路径(C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Microso ...
- LTrim、RTrim 和 Trim 函数
返回不带前导空格 (LTrim).后续空格 (RTrim) 或前导与后续空格 (Trim) 的字符串副本. LTrim(string) RTrim(string) Trim(string) strin ...
- json 与字符串相互转换,
<!doctype html> <html> <head> <meta charset="utf-8"> <meta name ...
- java代码获取客户端的真实ip
java代码获取客户端的真实ip protected String getIpAddr(HttpServletRequest request) { String ip = request.getHea ...
- sql server的远程连接
当一台服务器上的数据库需要用到另一台服务器上的数据库时,就需要远程连接 首先创建远程连接 exec sp_addlinkedserver linkname,'','SQLOLEDB',serverIP ...