Lucene底层原理和优化经验分享(1)-Lucene简介和索引原理
Lucene底层原理和优化经验分享(1)-Lucene简介和索引原理
基于Lucene检索引擎我们开发了自己的全文检索系统,承担起后台PB级、万亿条数据记录的检索工作,这里向大家分享下Lucene底层原理研究和一些优化经验。
从两个方面介绍:
1. Lucene简介和索引原理
2. Lucene优化经验总结
1. Lucene简介和索引原理
该部分从三方面展开:Lucene简介、索引原理、Lucene索引实现。
1.1 Lucene简介
Lucene最初由鼎鼎大名Doug Cutting开发,2000年开源,现在也是开源全文检索方案的不二选择,它的特点概述起来就是:全Java实现、开源、高性能、功能完整、易拓展,功能完整体现在对分词的支持、各种查询方式(前缀、模糊、正则等)、打分高亮、列式存储(DocValues)等等。
而且Lucene虽已发展10余年,但仍保持着一个活跃的开发度,以适应着日益增长的数据分析需求,最新的6.0版本里引入block k-d trees,全面提升了数字类型和地理位置信息的检索性能,另基于Lucene的Solr和ElasticSearch分布式检索分析系统也发展地如火如荼,ElasticSearch也在我们项目中有所应用。
Lucene整体使用如图所示:
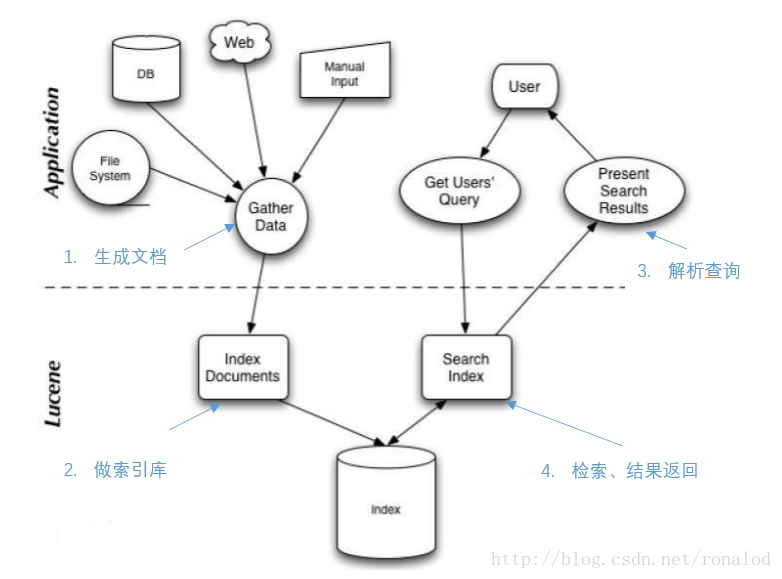
结合代码说明一下四个步骤:
IndexWriter iw=new IndexWriter();//创建IndexWriter
Document doc=new Document( new StringField("name", "Donald Trump", Field.Store.YES)); //构建索引文档
iw.addDocument(doc); //做索引库
IndexReader reader = DirectoryReader.open(FSDirectory.open(new File(index)));
IndexSearcher searcher = new IndexSearcher(reader); //打开索引
Query query = parser.parse("name:trump");//解析查询
TopDocs results =searcher.search(query, 100);//检索并取回前100个文档号
for(ScoreDoc hit:results.hits)
{
Document doc=searcher .doc(hit.doc)//真正取文档
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
使用起来很简单,但只有知道这背后的原理,才能更好地用好Lucene,后面将介绍通用检索原理和Lucene的实现细节。
1.2 索引原理
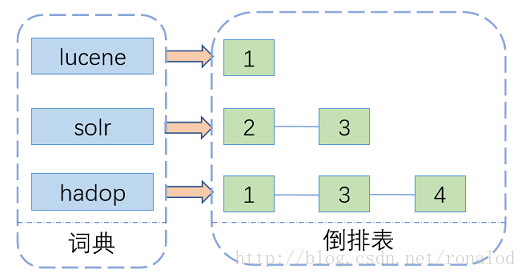
全文检索技术由来已久,绝大多数都基于倒排索引来做,曾经也有过一些其他方案如文件指纹。倒排索引,顾名思义,它相反于一篇文章包含了哪些词,它从词出发,记载了这个词在哪些文档中出现过,由两部分组成——词典和倒排表。
其中词典结构尤为重要,有很多种词典结构,各有各的优缺点,最简单如排序数组,通过二分查找来检索数据,更快的有哈希表,磁盘查找有B树、B+树,但一个能支持TB级数据的倒排索引结构需要在时间和空间上有个平衡,下图列了一些常见词典的优缺点:
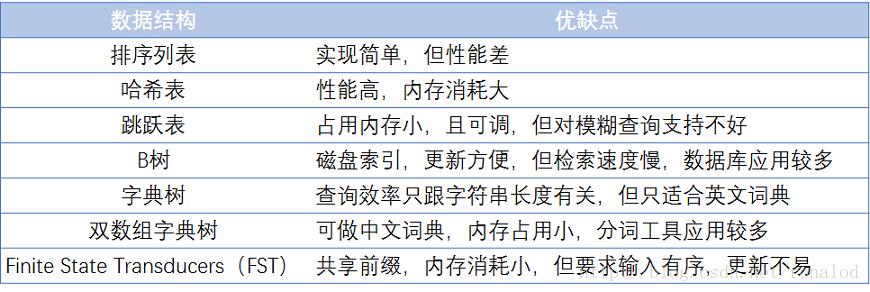
其中可用的有:B+树、跳跃表、FST
B+树:
mysql的InnoDB B+数结构
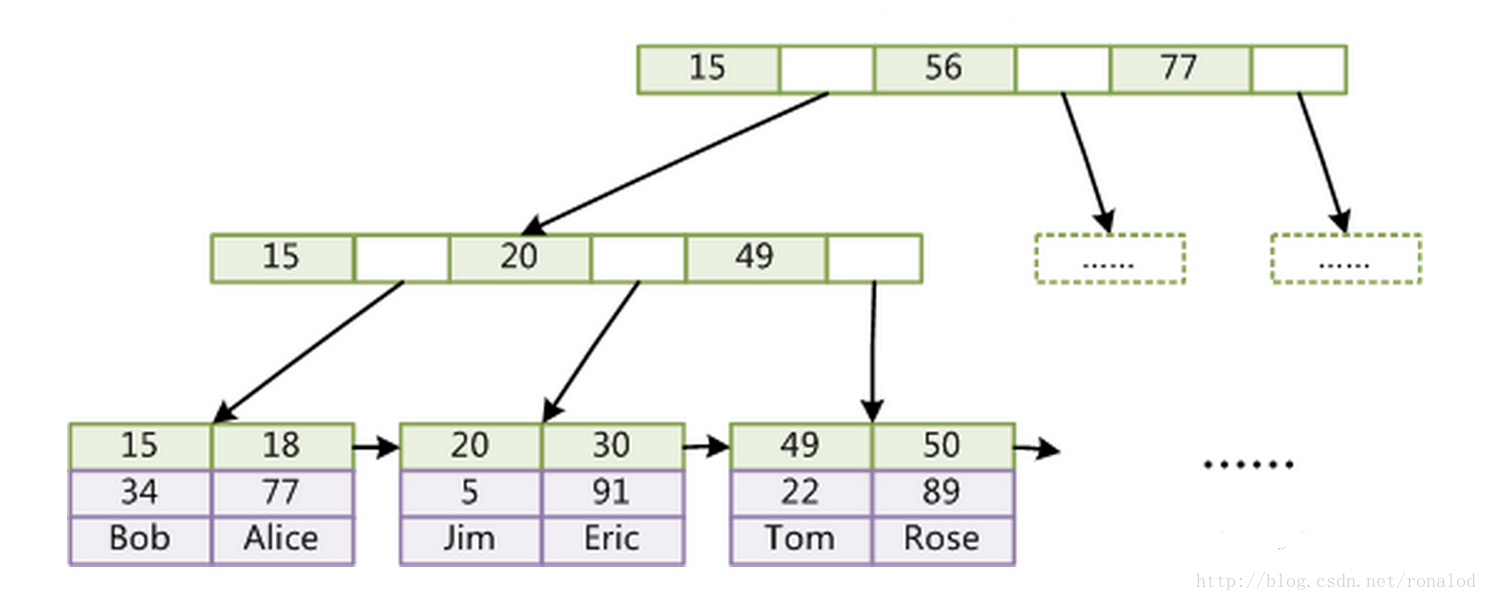
理论基础:平衡多路查找树
优点:外存索引、可更新
缺点:空间大、速度不够快
- 1
- 2
- 3
- 4
跳跃表:
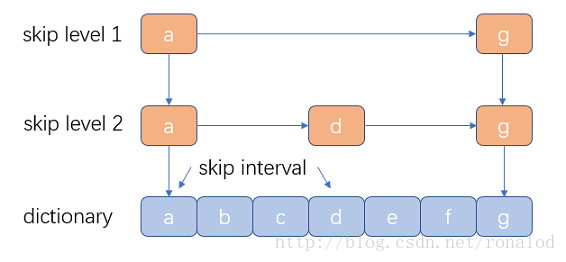
优点:结构简单、跳跃间隔、级数可控,Lucene3.0之前使用的也是跳跃表结构,后换成了FST,但跳跃表在Lucene其他地方还有应用如倒排表合并和文档号索引。
缺点:模糊查询支持不好
- 1
- 2
- 3
FST
Lucene现在使用的索引结构
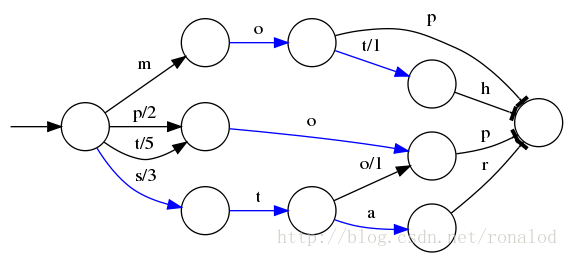
理论基础: 《Direct construction of minimal acyclic subsequential transducers》,通过输入有序字符串构建最小有向无环图。
优点:内存占用率低,压缩率一般在3倍~20倍之间、模糊查询支持好、查询快
缺点:结构复杂、输入要求有序、更新不易
Lucene里有个FST的实现,从对外接口上看,它跟Map结构很相似,有查找,有迭代:
- 1
- 2
- 3
- 4
- 5
String inputs={"abc","abd","acf","acg"}; //keys
long outputs={1,3,5,7}; //values
FST<Long> fst=new FST<>();
for(int i=0;i<inputs.length;i++)
{
fst.add(inputs[i],outputs[i])
}
//get
Long value=fst.get("abd"); //得到3
//迭代
BytesRefFSTEnum<Long> iterator=new BytesRefFSTEnum<>(fst);
while(iterator.next!=null){...}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
100万数据性能测试:
- 1
- 2
| 数据结构 | HashMap | TreeMap | FST |
|---|---|---|---|
| 构建时间(ms) | 185 | 500 | 1512 |
| 查询所有key(ms) | 106 | 218 | 890 |
可以看出,FST性能基本跟HaspMap差距不大,但FST有个不可比拟的优势就是占用内存小,只有HashMap10分之一左右,这对大数据规模检索是至关重要的,毕竟速度再快放不进内存也是没用的。
因此一个合格的词典结构要求有:
1. 查询速度。
2. 内存占用。
3. 内存+磁盘结合。
后面我们将解析Lucene索引结构,重点从Lucene的FST实现特点来阐述这三点。
1.3 Lucene索引实现
*(本文对Lucene的原理介绍都是基于4.10.3)*
- 1
- 2
Lucene经多年演进优化,现在的一个索引文件结构如图所示,基本可以分为三个部分:词典、倒排表、正向文件、列式存储DocValues。
下面详细介绍各部分结构:
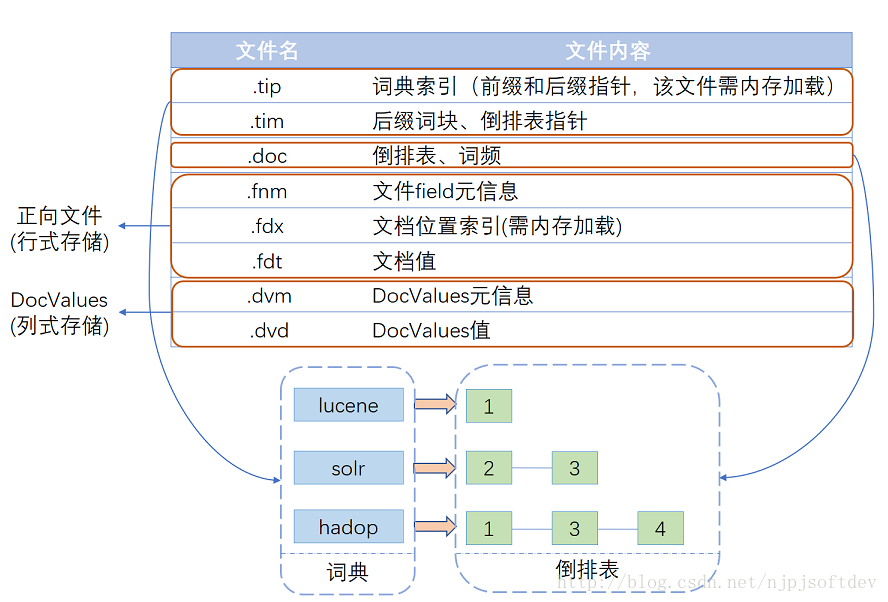
索引结构
Lucene现在采用的数据结构为FST,它的特点就是:
1、词查找复杂度为O(len(str))
2、共享前缀、节省空间
3、内存存放前缀索引、磁盘存放后缀词块
这跟我们前面说到的词典结构三要素是一致的:1. 查询速度。2. 内存占用。3. 内存+磁盘结合。我们往索引库里插入四个单词abd、abe、acf、acg,看看它的索引文件内容。
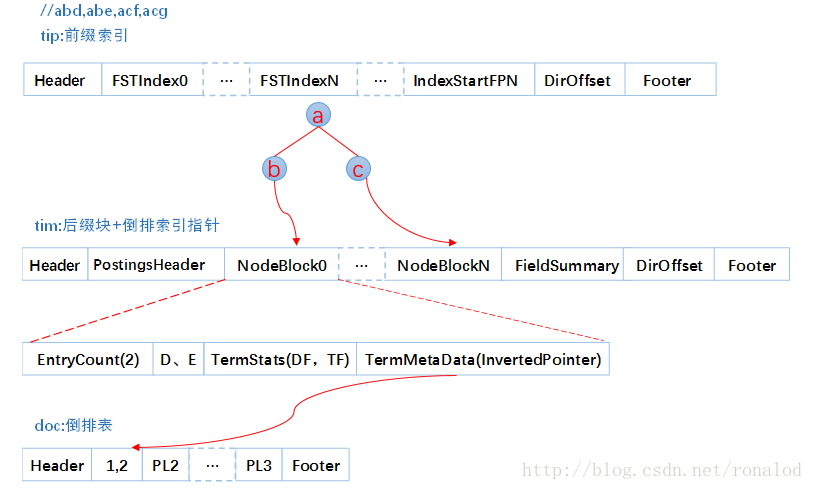
tip部分,每列一个FST索引,所以会有多个FST,每个FST存放前缀和后缀块指针,这里前缀就为a、ab、ac。tim里面存放后缀块和词的其他信息如倒排表指针、TFDF等,doc文件里就为每个单词的倒排表。
所以它的检索过程分为三个步骤:
1. 内存加载tip文件,通过FST匹配前缀找到后缀词块位置。
2. 根据词块位置,读取磁盘中tim文件中后缀块并找到后缀和相应的倒排表位置信息。
3. 根据倒排表位置去doc文件中加载倒排表。
这里就会有两个问题,第一就是前缀如何计算,第二就是后缀如何写磁盘并通过FST定位,下面将描述下Lucene构建FST过程:
已知FST要求输入有序,所以Lucene会将解析出来的文档单词预先排序,然后构建FST,我们假设输入为abd,abd,acf,acg,那么整个构建过程如下:
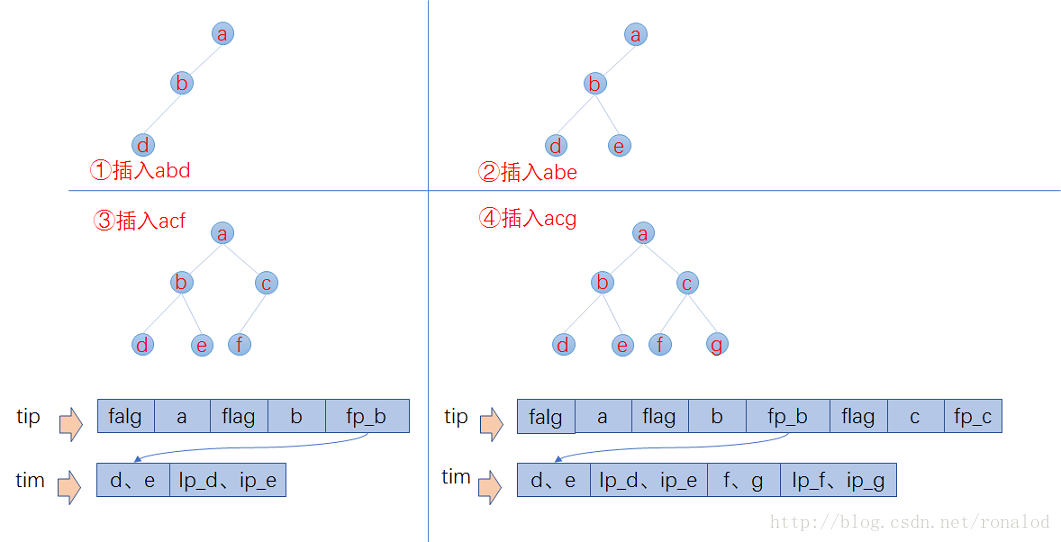
1. 插入abd时,没有输出。
2. 插入abe时,计算出前缀ab,但此时不知道后续还不会有其他以ab为前缀的词,所以此时无输出。
3. 插入acf时,因为是有序的,知道不会再有ab前缀的词了,这时就可以写tip和tim了,tim中写入后缀词块d、e和它们的倒排表位置ip_d,ip_e,tip中写入a,b和以ab为前缀的后缀词块位置(真实情况下会写入更多信息如词频等)。
4. 插入acg时,计算出和acf共享前缀ac,这时输入已经结束,所有数据写入磁盘。tim中写入后缀词块f、g和相对应的倒排表位置,tip中写入c和以ac为前缀的后缀词块位置。
- 1
- 2
- 3
- 4
- 5
以上是一个简化过程,Lucene的FST实现的主要优化策略有:
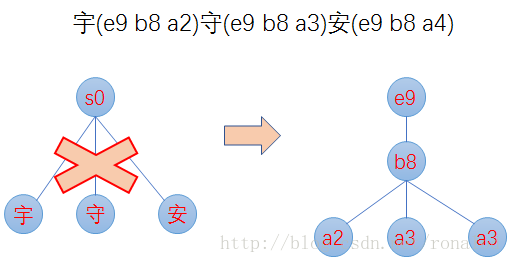
1. 最小后缀数。Lucene对写入tip的前缀有个最小后缀数要求,默认25,这时为了进一步减少内存使用。如果按照25的后缀数,那么就不存在ab、ac前缀,将只有一个跟节点,abd、abe、acf、acg将都作为后缀存在tim文件中。我们的10g的一个索引库,索引内存消耗只占20M左右。
2. 前缀计算基于byte,而不是char,这样可以减少后缀数,防止后缀数太多,影响性能。如对宇(e9 b8 a2)、守(e9 b8 a3)、安(e9 b8 a4)这三个汉字,FST构建出来,不是只有根节点,三个汉字为后缀,而是从unicode码出发,以e9、b8为前缀,a2、a3、a4为后缀,如下图:
- 1
- 2
- 3
倒排表结构
倒排表就是文档号集合,但怎么存,怎么取也有很多讲究,Lucene现使用的倒排表结构叫Frame of reference,它主要有两个特点:
1. 数据压缩,可以看下图怎么将6个数字从原先的24bytes压缩到7bytes。 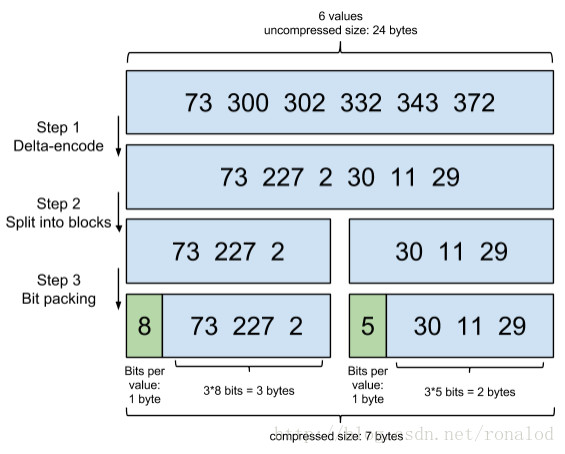
2. 跳跃表加速合并,因为布尔查询时,and 和or 操作都需要合并倒排表,这时就需要快速定位相同文档号,所以利用跳跃表来进行相同文档号查找。
这部分可参考ElasticSearch的一篇博客,里面有一些性能测试:
ElasticSearch 倒排表
正向文件
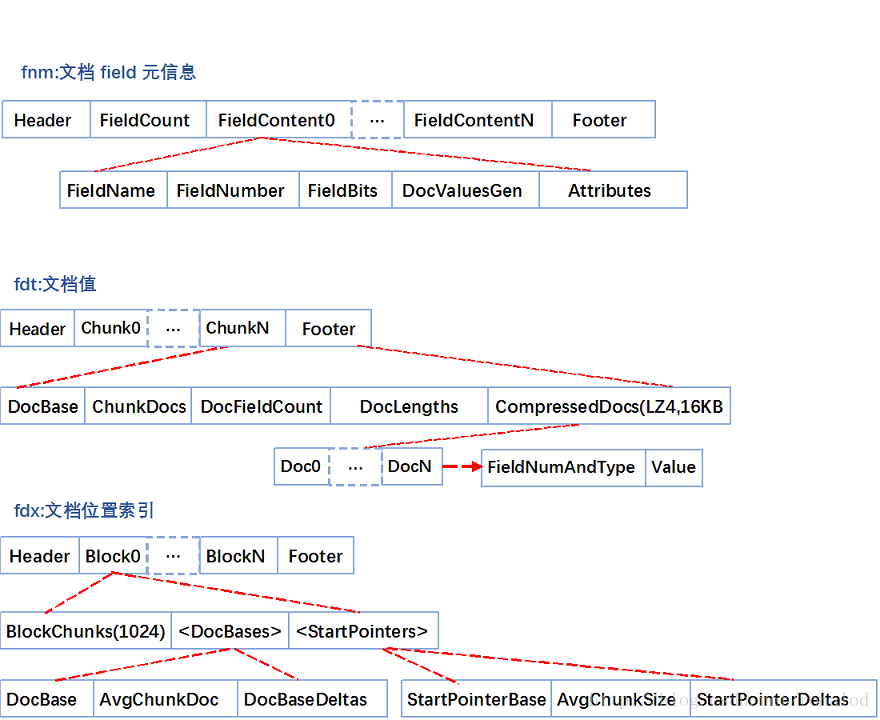
正向文件指的就是原始文档,Lucene对原始文档也提供了存储功能,它存储特点就是分块+压缩,fdt文件就是存放原始文档的文件,它占了索引库90%的磁盘空间,fdx文件为索引文件,通过文档号(自增数字)快速得到文档位置,它们的文件结构如下:
fnm中为元信息存放了各列类型、列名、存储方式等信息。
fdt为文档值,里面一个chunk就是一个块,Lucene索引文档时,先缓存文档,缓存大于16KB时,就会把文档压缩存储。一个chunk包含了该chunk起始文档、多少个文档、压缩后的文档内容。
fdx为文档号索引,倒排表存放的时文档号,通过fdx才能快速定位到文档位置即chunk位置,它的索引结构比较简单,就是跳跃表结构,首先它会把1024个chunk归为一个block,每个block记载了起始文档值,block就相当于一级跳表。
所以查找文档,就分为三步:
第一步二分查找block,定位属于哪个block。
第二步就是根据从block里根据每个chunk的起始文档号,找到属于哪个chunk和chunk位置。
第三步就是去加载fdt的chunk,找到文档。这里还有一个细节就是存放chunk起始文档值和chunk位置不是简单的数组,而是采用了平均值压缩法。所以第N个chunk的起始文档值由 DocBase + AvgChunkDocs * n + DocBaseDeltas[n]恢复而来,而第N个chunk再fdt中的位置由 StartPointerBase + AvgChunkSize * n + StartPointerDeltas[n]恢复而来。
从上面分析可以看出,lucene对原始文件的存放是行是存储,并且为了提高空间利用率,是多文档一起压缩,因此取文档时需要读入和解压额外文档,因此取文档过程非常依赖随机IO,以及lucene虽然提供了取特定列,但从存储结构可以看出,并不会减少取文档时间。
列式存储DocValues
我们知道倒排索引能够解决从词到文档的快速映射,但当我们需要对检索结果进行分类、排序、数学计算等聚合操作时需要文档号到值的快速映射,而原先不管是倒排索引还是行式存储的文档都无法满足要求。
原先4.0版本之前,Lucene实现这种需求是通过FieldCache,它的原理是通过按列逆转倒排表将(field value ->doc)映射变成(doc -> field value)映射,但这种实现方法有着两大显著问题:
1. 构建时间长。
2. 内存占用大,易OutOfMemory,且影响垃圾回收。
因此4.0版本后Lucene推出了DocValues来解决这一问题,它和FieldCache一样,都为列式存储,但它有如下优点:
1. 预先构建,写入文件。
2. 基于映射文件来做,脱离JVM堆内存,系统调度缺页。
DocValues这种实现方法只比内存FieldCache慢大概10~25%,但稳定性却得到了极大提升。
Lucene目前有五种类型的DocValues:NUMERIC、BINARY、SORTED、SORTED_SET、SORTED_NUMERIC,针对每种类型Lucene都有特定的压缩方法。
如对NUMERIC类型即数字类型,数字类型压缩方法很多,如:增量、表压缩、最大公约数,根据数据特征选取不同压缩方法。
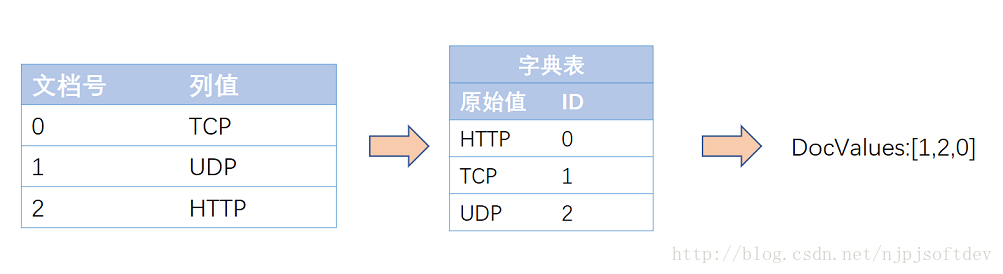
SORTED类型即字符串类型,压缩方法就是表压缩:预先对字符串字典排序分配数字ID,存储时只需存储字符串映射表,和数字数组即可,而这数字数组又可以采用NUMERIC压缩方法再压缩,图示如下:
这样就将原先的字符串数组变成数字数组,一是减少了空间,文件映射更有效率,二是原先变成访问方式变成固长访问。
对DocValues的应用,ElasticSearch功能实现地更系统、更完整,即ElasticSearch的Aggregations——聚合功能,它的聚合功能分为三类:
1. Metric -> 统计
典型功能:sum、min、max、avg、cardinality、percent等
2. Bucket ->分组
典型功能:日期直方图,分组,地理位置分区
3. Pipline -> 基于聚合再聚合
典型功能:基于各分组的平均值求最大值。
基于这些聚合功能,ElasticSearch不再局限与检索,而能够回答如下SQL的问题
select gender,count(*),avg(age) from employee where dept='sales' group by gender
销售部门男女人数、平均年龄是多少- 1
- 2
- 3
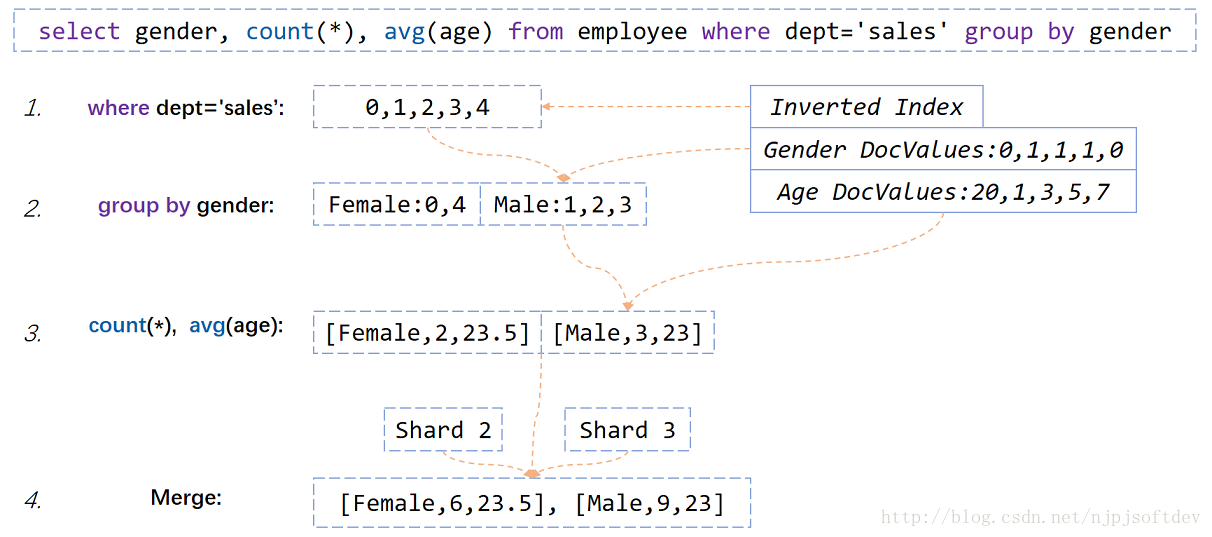
我们看下ElasticSearch如何基于倒排索引和DocValues实现上述SQL的。
1. 从倒排索引中找出销售部门的倒排表。
2. 根据倒排表去性别的DocValues里取出每个人对应的性别,并分组到Female和Male里。
3. 根据分组情况和年龄DocValues,计算各分组人数和平均年龄
4. 因为ElasticSearch是分区的,所以对每个分区的返回结果进行合并就是最终的结果。
上面就是ElasticSearch进行聚合的整体流程,也可以看出ElasticSearch做聚合的一个瓶颈就是最后一步的聚合只能单机聚合,也因此一些统计会有误差,比如count(*) group by producet limit 5,最终总数不是精确的。因为单点内存聚合,所以每个分区不可能返回所有分组统计信息,只能返回部分,汇总时就会导致最终结果不正确,具体如下:
原始数据:
| Shard 1 | Shard 2 | Shard 3 |
|---|---|---|
| Product A (25) | Product A (30) | Product A (45) |
| Product B (18) | Product B (25) | Product C (44) |
| Product C (6) | Product F (17) | Product Z (36) |
| Product D (3) | Product Z (16) | Product G (30) |
| Product E (2) | Product G (15) | Product E (29) |
| Product F (2) | Product H (14) | Product H (28) |
| Product G (2) | Product I (10) | Product Q (2) |
| Product H (2) | Product Q (6) | Product D (1) |
| Product I (1) | Product J (8) | |
| Product J (1) | Product C (4) |
count(*) group by producet limit 5,每个节点返回的数据如下:
| Shard 1 | Shard 2 | Shard 3 |
|---|---|---|
| Product A (25) | Product A (30) | Product A (45) |
| Product B (18) | Product B (25) | Product C (44) |
| Product C (6) | Product F (17) | Product Z (36) |
| Product D (3) | Product Z (16) | Product G (30) |
| Product E (2) | Product G (15) | Product E (29) |
合并后:
| Merged |
|---|
| Product A (100) |
| Product Z (52) |
| Product C (50) |
| Product G (45) |
| Product B (43) |
商品A的总数是对的,因为每个节点都返回了,但商品C在节点2因为排不到前5所以没有返回,因此总数是错的。
总结
以上就是Lucene简介和底层原理分析,侧重于Lucene实现策略与特点,下一篇将介绍我们如何从这些底层原理出发来优化我们的全文检索系统。
Lucene底层原理和优化经验分享(1)-Lucene简介和索引原理的更多相关文章
- Unity MMORPG游戏优化经验分享
https://mp.weixin.qq.com/s/thGF2WVUkIQYQDrz5DISxA 今天由Unity技术支持工程师高岩,根据实际的技术支持工作经验积累,分享如何对Unity MMORP ...
- 项目优化经验分享(八)TeamLeader经验总结
引言 通过前面的七篇博客.我把自己在项目优化过程的经验进行了分享,今天这篇博客,作为一个总结,就来讲讲作为一个TeamLeader,在项目管理中遇到的问题和解决经验! 正文 问题一:团队之间怎么沟通? ...
- 【MySQL 原理分析】之 Trace 分析 order by 的索引原理
一.背景 昨天早上,交流群有一位同学提出了一个问题.看下图: 我不是大佬,而且当时我自己的想法也只是猜测,所以并没有回复那位同学,只是接下来自己做了一个测试验证一下. 他只简单了说了一句话,就是同样的 ...
- Go程序GC优化经验分享
http://1234n.com/?post/yzsrwa 最近一段时间对<仙侠道>的服务端进行了一系列针对GC的调优,这里跟各位分享一下调优的经验. 游戏第一次上线的时候,大部分精力都投 ...
- Unity技术支持团队性能优化经验分享
https://mp.weixin.qq.com/s?__biz=MzU5MjQ1NTEwOA==&mid=2247490321&idx=1&sn=f9f34407ee5c5d ...
- Unite Europe案例项目《影子战术》层级优化经验分享
http://forum.china.unity3d.com/thread-25087-1-9.html 在Unite Europe 2017的Keynote主题演讲中,我们为大家分享了将主机游戏&l ...
- C#.NET 大型企业信息化系统 - 防黑客攻击 - SSO系统加固优化经验分享
好久没写文章了,突然间也不知道写什么好了一样,好多人可能以为我死了,写个文章分享一下.证明一下自己还在,很好的活着吧,刷个存在感. 放弃了很多娱乐.休闲.旅游.写文章.看书.陪伴家人,静心默默的用了接 ...
- 项目优化经验分享(六)SVN冲突和处理
上一篇博客我们分享了新增需求的确定思想<站在全局看问题>.今天我们来分享项目开发中SVN冲突的解决经验:SVN冲突和处理! 引言 开发过项目的人都知道,公司开发一个项目都会使用到版本号控制 ...
- Web前端性能优化经验分享
最近一直有给新同学做前端方面的培训,也有去参与公司前端的招聘,所以把自己资料库里面很多高效且有用的知识做了些 规整分类,然后再分享一篇关于前端优化方面的总结.而且春节一过就又是招聘的高峰期了,在校的. ...
随机推荐
- 《Software Design中文版01》
<Software Design中文版01> 基本信息 作者: (日)技术评论社 译者: 苏祎 出版社:人民邮电出版社 ISBN:9787115347053 上架时间:2014-3-18 ...
- ps -ef | grep 查看进程命令
通过 ps -ef | grep redis 查看当前Redis 的进程情况.
- Django创建自定义错误页面400/403/404/500等
直接参考: https://zhuanlan.zhihu.com/p/38006919 DEBUG =True的话,为开发环境,显示不了404页面.
- Team Viewer 远程链接一直显示-"正在初始化显示参数"
出现这个原因, 原因1: 可能是 通过(mstsc)远程桌面方式运行了teamviewer,被远程控制电脑就会出现这个现象. 可以试一下 服务-teamviewer-属性-登录-本地系统账户 -允许服 ...
- [leetcode]Gas Station @ Python
原题地址:https://oj.leetcode.com/problems/gas-station/ 题意: There are N gas stations along a circular rou ...
- 硬链接(hard link)和符号连接(symbolic link)
inode ====== 在Linux系统中,内核为每一个新创建的文件分配一个inode,每个文件都有一个惟一的inode号,我们可以将inode简单理解成一个指针,它永远指向本文件的具体存储位置.文 ...
- Permutation Sequence leetcode java
题目: The set [1,2,3,…,n] contains a total of n! unique permutations. By listing and labeling all of t ...
- 关于LINQ和SQL操作数据库的性能测试(转)
微软linq技术已经出现很久,很多公司已经开始商业使用,作为我们暂时没有用到的人来说,也应该适当的了解下相关知识,但是直到目前网络上对他的看法仍然是褒贬不一,当然任何事情都不可能完美的,下面就针对大多 ...
- vue项目实现列表页-详情页返回不刷新,再点其他菜单项返回刷新的需求
问题背景:有时候一些列表会有一些跳转的需求,比如跳到详情页.或者是其他相关的页面(比如跳到用户列表去查看用户的相关信息)等,此时再返回列表页,列表页会刷新重置.目前需求就是需要改成如下情况: 问题1. ...
- Android WindowManager实现悬浮窗效果 (一)——与当前Activity绑定
最近有学生做毕业设计,想使用悬浮窗这种效果,其实很简单,我们可以通过系统服务WindowManager来实现此功能,本章我们来试验一下在当前Activity之上创建一个悬浮的view. 第一步:认识W ...