【cs229-Lecture11】贝叶斯统计正则化
本节知识点:
贝叶斯统计及规范化
在线学习
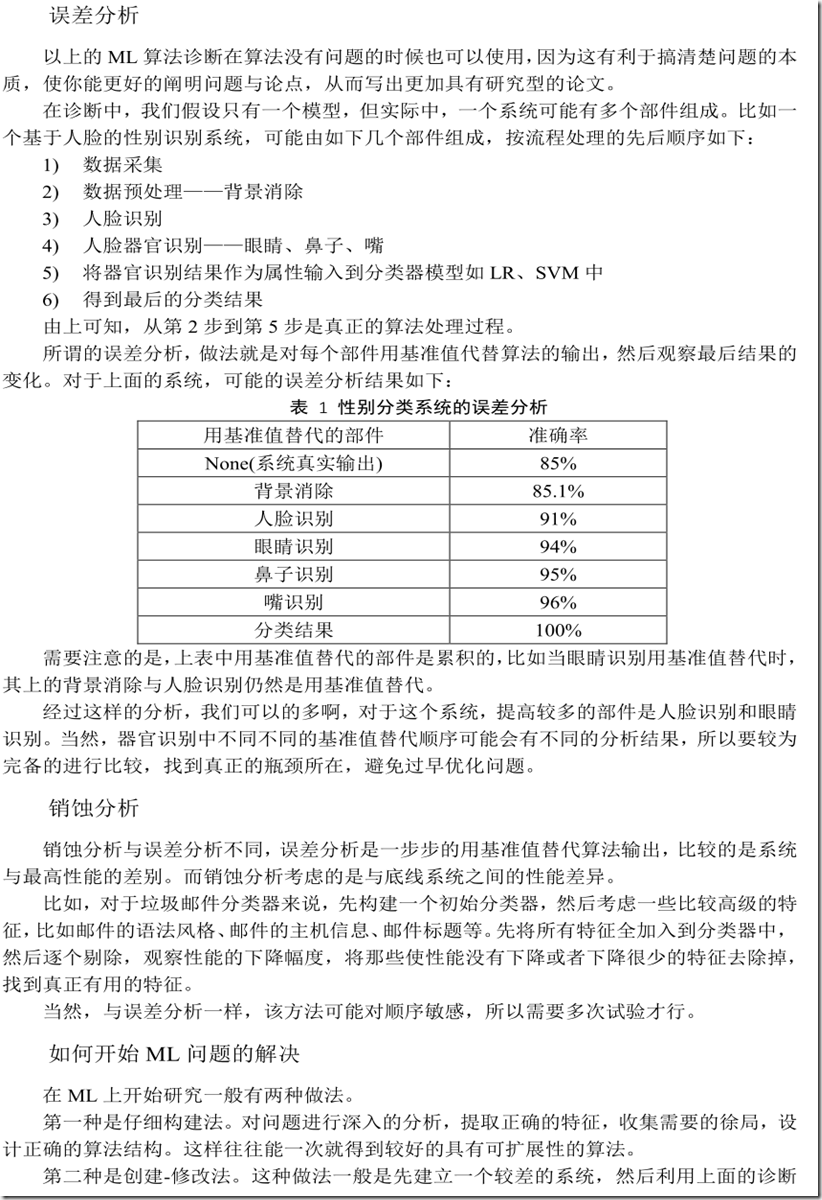
如何使用机器学习算法解决具体问题:设定诊断方法,迅速发现问题
贝叶斯统计及规范化(防止过拟合的方法)
就是要找更好的估计方法来减少过度拟合情况的发生。
回顾一下,线性回归中使用的估计方法是最小二乘法,logistic 回归是条件概率的最大
似然估计,朴素贝叶斯是联合概率的最大似然估计,SVM 是二次规划。
一下转自:http://52opencourse.com/133/coursera
斯坦福大学机器学习第七课"正则化“学习笔记,本次课程主要包括4部分:
1) The Problem of Overfitting(过拟合问题)
2) Cost Function(成本函数)
3) Regularized Linear Regression(线性回归的正则化)
4) Regularized Logistic Regression(逻辑回归的正则化)
以下是每一部分的详细解读。
1) The Problem of Overfitting(过拟合问题)
拟合问题举例-线性回归之房价问题:
a) 欠拟合(underfit, 也称High-bias)
b) 合适的拟合:
c) 过拟合(overfit,也称High variance)
什么是过拟合(Overfitting):
如果我们有非常多的特征,那么所学的Hypothesis有可能对训练集拟合的非常好(


















 ),但是对于新数据预测的很差。
),但是对于新数据预测的很差。
过拟合例子2-逻辑回归:
与上一个例子相似,依次是欠拟合,合适的拟合以及过拟合:
a) 欠拟合
b) 合适的拟合
c) 过拟合
如何解决过拟合问题:
首先,过拟合问题往往源自过多的特征,例如房价问题,如果我们定义了如下的特征:
那么对于训练集,拟合的会非常完美:
所以针对过拟合问题,通常会考虑两种途径来解决:
a) 减少特征的数量:
-人工的选择保留哪些特征;
-模型选择算法(之后的课程会介绍)
b) 正则化
-保留所有的特征,但是降低参数 的量/值;
的量/值;
-正则化的好处是当特征很多时,每一个特征都会对预测y贡献一份合适的力量;
2) Cost Function(成本函数)
依然从房价预测问题开始,这次采用的是多项式回归:
a) 合适的拟合:
b) 过拟合
直观来看,如果我们想解决这个例子中的过拟合问题,最好能将

 的影响消除,也就是让.
的影响消除,也就是让.
假设我们对进行惩罚,并且令其很小,一个简单的办法就是给原有的Cost function加上两个略大惩罚项,例如:
这样在最小化Cost function的时候,.
正则化:
参数

 取小一点的值,这样的优点:
取小一点的值,这样的优点:
-“简化”的hypothesis;
-不容易过拟合;
对于房价问题:
-特征包括:
-参数包括:
我们对除以为的参数进行惩罚,也就是正则化:
正式的定义-经过正则化的Cost Function有如下的形式:
其中 称为正则化参数,我们的目标依然是最小化:
称为正则化参数,我们的目标依然是最小化: 


例如,对于正则化的线性回归模型来说,我们选择来最小化如下的正则化成本函数:
如果将 设置为一个极大的值(例如对于我们的问题,设  )? 那么
)? 那么
-算法依然会正常的工作, 将 设置的很大不会影响算法本身;
-算法在去除过拟合问题上会失败;
-算法的结构将是欠拟合(underfitting),即使训练数据非常好也会失败;
-梯度下降算法不一定会收敛;
这样的话,除了,其他的参数都约等于0, , 将得到类似如下的欠拟合图形:
关于正则化,以下引自李航博士《统计学习方法》1.5节关于正则化的一些描述:
模型选择的典型方法是正则化。正则化是结构风险最小化策略的实现,是在经验风险上加一个正则化项(regularizer)或罚项(penalty term)。正则化项一般是模型复杂度的单调递增函数,模型越复杂,正则化值就越大。比如,正则化项可以是模型参数向量的范数。
正则化符合奥卡姆剃刀(Occam's razor)原理。奥卡姆剃刀原理应用于模型选择时变为以下想法:在所有可能选择的模型中,能够很好地解释已知数据并且十分简单才是最好的模型,也就是应该选择的模型。从贝叶斯估计的角度来看,正则化项对应于模型的先验概率。可以假设复杂的模型有较大的先验概率,简单的模型有较小的先验概率。
3) Regularized Linear Regression(线性回归的正则化)
线性回归包括成本函数,梯度下降算法及正规方程解法等几个部分,不清楚的读者可以回顾第二课及第四课的笔记,这里将分别介绍正则化后的线性回归的成本函数,梯度下降算法及正规方程等。
首先来看一下线性回归正则化后的Cost function:
我们的目标依然是最小化,从而得到相应的参数. 梯度下降算法是其中的一种优化算法,由于正则化后的线性回归Cost function有了改变,因此梯度下降算法也需要相应的改变:
注意,对于参数,梯度下降算法需要区分和。
同样的正规方程的表达式也需要改变,对于:
X 是m * (n+1)矩阵
y是m维向量:
正则化后的线性回归的Normal Equation的公式为:
假设样本数m小于等于特征数x, 如果没有正则化,线性回归Normal eqation如下:



如果不可逆怎么办?之前的办法是删掉一些冗余的特征,但是线性回归正则化后,如果 ,之前的公式依然有效:
,之前的公式依然有效:
其中括号中的矩阵可逆。
4) Regularized Logistic Regression(逻辑回归的正则化)
和线性回归相似,逻辑回归的Cost Function也需要加上一个正则化项(惩罚项),梯度下降算法也需要区别对待参数\(\theta).
再次回顾一些逻辑回归过拟合的情况,形容下面这个例子:
其中Hypothesis是这样的:
逻辑回归正则化后的Cost Function如下:
梯度下降算法如下:
其中




 .
.
参考资料:
第七课“正则化”的课件资料下载链接,视频可以在Coursera机器学习课程上观看或下载:https://class.coursera.org/ml
李航博士《统计学习方法》
http://en.wikipedia.org/wiki/Regularization_%28mathematics%29
http://en.wikipedia.org/wiki/Overfitting
在线学习
之前学的算法都是批处理算法,即在训练集上得到模型后,再去对测试集或者训练集本身进行评测,得到训练误差和泛化误差。而在线学习并不这样,而是首先有一个初始的分类器,当第一个样本到来时,对该样本进行预测,得到预测结果,然后利用该样本的信息对分类器进行更新(比如,考虑感知器算法的更新规则,见笔记 1-2);然后第二个样本到来时做同样的操作,以此类推。这样,我们就对 m 个样本都有一个预测值,只不过它们都是在训练的过程中得到的,对这些预测值进行统计,就得到了在线训练误差。这就是过程上在线学习与批处理的不同之处。
对于感知器算法来说,若正负样本线性可分,那么在线学习算法也是收敛的。
以下转自:http://blog.csdn.net/stdcoutzyx





【cs229-Lecture11】贝叶斯统计正则化的更多相关文章
- CS229 5.用正则化(Regularization)来解决过拟合
1 过拟合 过拟合就是训练模型的过程中,模型过度拟合训练数据,而不能很好的泛化到测试数据集上.出现over-fitting的原因是多方面的: 1) 训练数据过少,数据量与数据噪声是成反比的,少量数据导 ...
- Andrew Ng机器学习课程11之贝叶斯统计和正则化
Andrew Ng机器学习课程11之贝叶斯统计和正则化 声明:引用请注明出处http://blog.csdn.net/lg1259156776/ 在统计学中有两个学派,一个是频率学派,另一个是贝叶斯学 ...
- 学习理论之正则化(Regularization)与模型选择
一.引言 对于一个学习问题,可以假设很多不同的模型,我们要做的是根据某一标准选出最好的模型.例如,在多项式回归中,对于我们的假设模型,我们最要紧的是决定 k 到底取多少合适,能不能有一种方法可以自动选 ...
- 资源 | 源自斯坦福CS229,机器学习备忘录在集结
在 Github 上,afshinea 贡献了一个备忘录对经典的斯坦福 CS229 课程进行了总结,内容包括监督学习.无监督学习,以及进修所用的概率与统计.线性代数与微积分等知识. 项目地址:http ...
- 从MAP角度理解神经网络训练过程中的正则化
在前面的文章中,已经介绍了从有约束条件下的凸优化角度思考神经网络训练过程中的L2正则化,本次我们从最大后验概率点估计(MAP,maximum a posteriori point estimate)的 ...
- 数据预处理中归一化(Normalization)与损失函数中正则化(Regularization)解惑
背景:数据挖掘/机器学习中的术语较多,而且我的知识有限.之前一直疑惑正则这个概念.所以写了篇博文梳理下 摘要: 1.正则化(Regularization) 1.1 正则化的目的 1.2 正则化的L1范 ...
- 【原】关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
一.标准化(Z-Score),或者去除均值和方差缩放 公式为:(X-mean)/std 计算时对每个属性/每列分别进行. 将数据按期属性(按列进行)减去其均值,并处以其方差.得到的结果是,对于每个属 ...
- 正则化方法:L1和L2 regularization、数据集扩增、dropout
正则化方法:防止过拟合,提高泛化能力 在训练数据不够多时,或者overtraining时,常常会导致overfitting(过拟合).其直观的表现如下图所示,随着训练过程的进行,模型复杂度增加,在tr ...
- coursera机器学习-logistic回归,正则化
#对coursera上Andrew Ng老师开的机器学习课程的笔记和心得: #注:此笔记是我自己认为本节课里比较重要.难理解或容易忘记的内容并做了些补充,并非是课堂详细笔记和要点: #标记为<补 ...
随机推荐
- LigerUI可编辑表格左下角出现白色小方块遮罩层问题解决办法
LigerUI已经研究了一段时间,总体感觉还不错,基于jQuery开发,框架提供了丰富的UI组件,尤其LigerUI表格,功能还是挺强大的 在使用LigerUI可编辑表格的时候,发现一个小小的问题 当 ...
- Oracle触发器给表自身的字段重新赋值出现ORA-04091异常
业务描述如下: 在插入一个表的时候,需要根据一个字段的值更新另一个字段的值.当然也可以通过程序就能很简单得实现,只是这个字段只是数据交换用,和系统主业务没关系,不想修改程序,所以才用触发器的方式实现. ...
- java.lang.IllegalArgumentException: Request header is too large 解决方案
错误描述: java.lang.IllegalArgumentException: Request header is too large 问题分析: 请求头超过了tomcat的限值.本来post请求 ...
- CSS3小清新下拉菜单 简易大方
之前有分享过几款CSS3菜单和jQuery菜单,像这款HTML5/CSS3自定义下拉框 3D卡片折叠动画3D效果非常华丽,这次要分享的这款相对比较简单,很适合用在用户的操作面板上.先来看看效果图: 怎 ...
- iOS :UIPickerView reloadAllComponets not work
编辑信息页面用了很多选择栏,大部分都用 UIPickerView 来实现.在切换数据显示的时候, UIPickerView 不更新数据,不得其解.Google 无解,原因在于无法描述自己的问题,想想应 ...
- 新手windows安装nginx
windows安装nginx,下载地址:http://nginx.org/download/ 下载的时候,下载 .zip 后缀的压缩包,因为 .zip 的压缩包有nginx.exe 启动文件,其他没有 ...
- 文字描边css
-webkit-text-stroke: 3.3px #2A75BF; -webkit-text-fill-color:#fff; 该方法在安卓端貌似不支持,显示为一团 或: -webkit-text ...
- ADCD 1.9 ZOS 配置 CTCI-W32 TCPIP 网络
试验步骤:两步走,第一步修改Hercules的配置文件 在hercules 配置文件末尾加上 0E20-0E21 CTCI -n 0A-00-27-00-00-00 192.168.5 ...
- 关于High-Contrast的资料
SystemParameters.HighContrast Propertyhttp://msdn.microsoft.com/en-us/library/system.windows.systemp ...
- CorelDRAW中如何再制对象详解
再制对象指的是快捷地将对象按一定的方式复制为多个对象,此种复制是复制的复制,再制不仅可以节省复制的时间,再制间距还可以保证复制效果.本教程将详解如何在CorelDRAW软件中再制对象. CorelDR ...