【CV】ICCV2015_Unsupervised Visual Representation Learning by Context Prediction
Unsupervised Visual Representation Learning by Context Prediction
Note here: it's a learning note on unsupervised learning model from Prof. Gupta's group.
Motivation:
- Similar to most motivations of unsupervised learning method, cut it out here.
Proposed Model:
- Given one central patch of the object, and another one arounding it, the model must guess the relative spatial configuration between these two patches.
- Intuition: when human doing this assignment, we get higher accuracy once we recognize what object it is and what it’s like with a whole look. That is to say, a model plays well on this game would have percepted the features of each object.
(i.e. we can get right answer for the following quizz once we recognize what objects they are.)
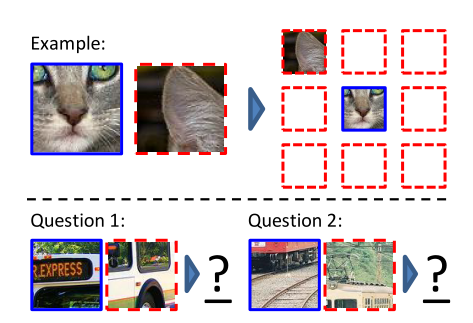
So the unsupervised representation learning can also be formulated as learning an embedding where images that are semantically similar close, while semantically different ones are far apart.
- Pipline:
- Feed two patches into a parallel convolutional network which share parameters.
- Fuse the feature vector of each patch and pass through stacked fully connected layers.
- Come out with an eight-dimension vector that predicts relative spatial configuration between the two patches.
- Compute loss, gradients and back propagate through this network to update weights.

Aoiding “trivial” solutions:
We need to preprocess images to avoid the model learns some trivial features, like:
- Low-level cues like boundary patterns or textures continuing between patches, which could potentially serve as a shortcut.
- Chromatic aberration: it arises from differences in the way the lens focuses light and different wavelengths. In some cameras, one color channel (commonly green) is shrunk toward the image center relative to the others. Once the network learns the absolute location on the lens, solving the relatve location task becomes trivial.
【CV】ICCV2015_Unsupervised Visual Representation Learning by Context Prediction的更多相关文章
- 【CV】ICCV2015_Unsupervised Learning of Visual Representations using Videos
Unsupervised Learning of Visual Representations using Videos Note here: it's a learning note on Prof ...
- 【CV】ICCV2015_Unsupervised Learning of Spatiotemporally Coherent Metrics
Unsupervised Learning of Spatiotemporally Coherent Metrics Note here: it's a learning note on the to ...
- 论文解读《Momentum Contrast for Unsupervised Visual Representation Learning》俗称 MoCo
论文题目:<Momentum Contrast for Unsupervised Visual Representation Learning> 论文作者: Kaiming He.Haoq ...
- Microsoft Azure Web Sites应用与实践【3】—— 通过Visual Studio Online在线编辑Microsoft Azure 网站
Microsoft Azure Web Sites应用与实践 系列: [1]—— 打造你的第一个Microsoft Azure Website [2]—— 通过本地IIS 远程管理Microsoft ...
- Momentum Contrast for Unsupervised Visual Representation Learning (MoCo)
Momentum Contrast for Unsupervised Visual Representation Learning 一.Methods Previously Proposed 1. E ...
- Momentum Contrast for Unsupervised Visual Representation Learning
Momentum Contrast for Unsupervised Visual Representation Learning 一.Methods Previously Proposed 1. E ...
- 论文阅读(Xiang Bai——【arXiv2016】Scene Text Detection via Holistic, Multi-Channel Prediction)
Xiang Bai--[arXiv2016]Scene Text Detection via Holistic, Multi-Channel Prediction 目录 作者和相关链接 方法概括 创新 ...
- 【VBS】使用Visual Studio调试VBS程序
首先要确保机器上安装了Visual Stuido, 然后打开命令行窗口执行如下命令,会弹出是否使用Visual Studio进行调试的确认窗口. 点[是]进行调试. WScript.exe [vbs文 ...
- 论文阅读笔记(五)【CVPR2012】:Large Scale Metric Learning from Equivalence Constraints
由于在读文献期间多次遇见KISSME,都引自这篇CVPR,所以详细学习一下. Introduction 度量学习在机器学习领域有很大作用,其中一类是马氏度量学习(Mahalanobis metric ...
随机推荐
- Django之form表单认证
Model常用操作: - 参数:filter 三种传参方式 - all(得到的是列表),values(字典),values_list(元祖) [obj(id,name,pwd,email),obj(i ...
- IDEA多线程调试设置
转至:http://blog.csdn.net/kevindai007/article/details/71412324 使用idea调试多线程的时候发现多线程无法调试,后来经过搜索发现,idea的断 ...
- Find a multiple POJ - 2356 (抽屉原理)
抽屉原理: 形式一:设把n+1个元素划分至n个集合中(A1,A2,…,An),用a1,a2,…,an分别表示这n个集合对应包含的元素个数,则:至少存在某个集合Ai,其包含元素个数值ai大于或等于2. ...
- 【转】android笔记--保存和恢复activity的状态数据
一般来说, 调用onPause()和onStop()方法后的activity实例仍然存在于内存中, activity的所有信息和状态数据不会消失, 当activity重新回到前台之后, 所有的改变都会 ...
- Arduino IDE for ESP8266 项目(3)创建AP+STA
官网API:http://arduino-esp8266.readthedocs.io/en/latest/esp8266wifi/readme.html STA (客户端)手机连接路由器 S1 *简 ...
- attribute与parameter区别(转)
文章转自http://blog.csdn.net/saygoodbyetoyou/article/details/9006001 request.getParameter取得Web客户端到web服务端 ...
- python在图片上写汉字
1.python opencv的putText只能画英文上去 2.借鉴这个https://blog.csdn.net/dcrmg/article/details/79108491 使用pil 首先,你 ...
- MyBatis之反射技术+JDK动态代理+cglib代理
一.反射 引用百度百科说明: JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法:对于任意一个对象,都能够调用它的任意方法和属性:这种动态获取信息以及动态调用对象方法的功 ...
- SSM框架之整合(Maven实例)
有不少朋友在maven中因为pom文件依赖的事导致报错 今天我这个快速搭建ssm框架,确保在jdk7或者jdk8的环境,tomcat没什么要求.但如果要用jdk8的话,最好用run as中的serve ...
- junit常用注解详细说明
Java注解((Annotation)的使用方法是@注解名 ,能通过简单的词语来实现一些功能.在junit中常用的注解有@Test.@Ignore.@BeforeClass.@AfterClass.@ ...