【原创】我的KM算法详解
0.二分图
二分图的概念
二分图的判定
二分图博客推荐
1.KM算法初步
增广路径

- 如果是深搜,x2找到y0匹配,但发现y0已经被x1匹配了,于是就深入到x1,去为x1找新的匹配节点,结果发现x1没有其他的匹配节点,于是匹配失败,x2接着找y1,发现y1可以匹配,于是就找到了新的增广路径。
- 如果是宽搜,x1找到y0节点的时候,由于不能马上得到一个合法的匹配,于是将它做为候选项放入队列中,并接着找y1,由于y1已经匹配,于是匹配成功返回了。
匈牙利算法
匈牙利算法步骤
匈牙利算法博客推荐
KM算法
KM算法步骤
KM算法标杆(又名顶标)的引入
- 所以我们可以把这匈牙利算法和FF算法结合起来。这就是KM算法的思路了:尽量找最大的边进行连边,如果不能则换一条较大的。
- FF算法里面,我们每次是找最长(短)路进行通流,所以二分图匹配里面我们也按照FF算法找最大边进行连边!
- 但是遇到某个点被匹配了两次怎么办?那就用匈牙利算法进行更改匹配!
- 所以,根据KM算法的思路,我们一开始要对边权值最大的进行连线。
- 那问题就来了,我们如何让计算机知道该点对应的权值最大的边是哪一条?或许我们可以通过某种方式记录边的另一端点,但是呢,后面还要涉及改边,又要记录边权值总和,而这个记录端点方法似乎有点麻烦。
- 于是KM采用了一种十分巧妙的办法(也是KM算法思想的精髓):添加标杆(顶标)
- 我们对左边每个点Xi和右边每个点Yi添加标杆Cx和Cy。其中我们要满足Cx+Cy>=w[x][y](w[x][y]即为点Xi、Yi之间的边权值)
- 对于一开始的初始化,我们对于每个点分别进行如下操作:Cx=max(w[x][y]); Cy=0;
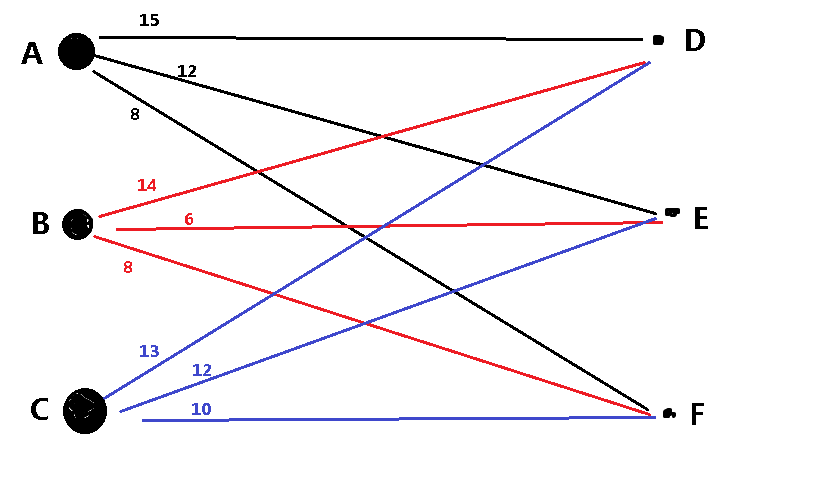
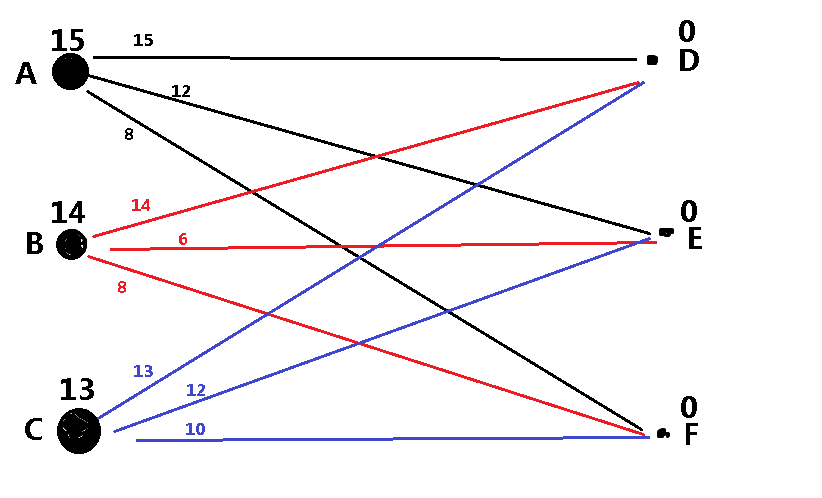
KM流程详解
- 初始化可行顶标的值 (设定lx,ly的初始值)
- 用匈牙利算法寻找相等子图的完备匹配
- 若未找到增广路则修改可行顶标的值
- 重复(2)(3)直到找到相等子图的完备匹配为止
- 于是乎我们连了AD,形成一个新的二分图(我们下面叫它二分子图好了)
- 接下来就尴尬了,计算机接下来要连B点的BD,但是D点已经和A点连了,怎么办呢???
- 根据匈牙利算法,我们做的是将A点与其他点进行连线,但此时的子图里“不存在”与A点相连的其他边,怎么办呢???
- 为此,我们就需要加上这些边!很明显,我们添边,自然要加上不在子图中边权最大的边,也就是和子图里这个边权值差最小的边。
- 于是,我们再一度引入了一变量d,d=min{Cx[i]+Cy[j]-w[i][j]},其中,在这个题目里Cx[i]指的是A的标杆,Cy[j]是除D点(即已连点)以外的点的标杆。
- 随后,对于原先存在于子图的边AD,我们将A的标杆Cx[i]减去d,D的标杆Cy[d]加上d。
- 这样,这就保证了原先存在AD边保留在了子图中,并且把不在子图的最大权值的与A点相连的边AE添加到了子图。
- 因为计算机判断一条边是否在该子图的条件是其两端的顶点的标杆满足Cx+Cy==w[x][y]
- 对于原先的边,我们对左端点的标杆减去了d,对右端点的标杆加上了d,所以最终的结果还是不变,仍然是w[x][y]。
- 对于我们要添加的边,我们对于左端点减去了d,即Cx[i]=Cx[i]-d;为方便表示我们把更改后的的Cx[i]视为Cz[i],即Cz[i]=Cx[i]-d;
- 因为Cz[i]=Cx[i]-d;d=Cx[i]+Cy[j]-w[i][j];
- 把d代入左式可得Cz[i]=Cx[i]-(Cx[i]+Cy[j]-w[i][j]);
- 化简得Cz[i]+Cy[j]=w[i][j];
- 满足了要求!即添加了新的边。
- 重复进行上述流程。(匈牙利算法以及FF算法的结合)
KM算法博客推荐
2.DFS版本的KM算法
/*==================================================*\
| 二分图匹配(匈牙利算法DFS 实现)
| INIT: graph[][]邻接矩阵;
| CALL: res = dfsHungarian ();
| 优点:实现简洁容易理解,适用于稠密图,DFS 找增广路快。
| 找一条增广路的复杂度为O(E),最多找V条增广路,故时间复杂度为O(VE)
| 算法简述:
| 从二分图中找出一条路径来,让路径的起点和终点都是还没有匹配过的点,
| 并且路径经过的连线是一条没被匹配、一条已经匹配过,再下一条又没匹配这样交替地出现。
| 找到这样的路径后,显然路径里没被匹配的连线比已经匹配了的连线多一条,
| 于是修改匹配图,把路径里所有匹配过的连线去掉匹配关系,把没有匹配的连线变成匹配的。
| 这样匹配数就比原来多1个。不断执行上述操作,直到找不到这样的路径为止。
\*==================================================*/
#include<iostream>
#include<memory.h>
using namespace std; #define MAXN 10
int graph[MAXN][MAXN];
int match[MAXN];
int visitX[MAXN], visitY[MAXN];
int nx, ny; bool findPath( int u )
{
visitX[u] = ;
for( int v=; v<ny; v++ )
{
if( !visitY[v] && graph[u][v] )
{
visitY[v] = ;
if( match[v] == - //第一次,用到了短路计算,否则findPath(-1)会出问题
|| findPath(match[v]) )//这里就表示深度优先遍历 不撞南山头不回 不见黄河心不死
{
match[v] = u;
return true;
}
}
}
return false;
} int dfsHungarian()
{
int res = ;
memset( match, -, sizeof(match) );
for( int i=; i<nx; i++ )
{
memset( visitX, , sizeof(visitX) );
memset( visitY, , sizeof(visitY) );
if( findPath(i) )
res++;
}
return res;
}
3.BFS版本的KM算法
/*==================================================*\
| 二分图匹配(匈牙利算法BFS 实现)
| INIT: graph[][]邻接矩阵;
| CALL: res = bfsHungarian ();
| 优点:适用于稀疏二分图,边较少,增广路较短。
| 匈牙利算法的理论复杂度是O(VE)
\*==================================================*/
#include<iostream>
#include<memory.h>
using namespace std; #define MAXN 10
int graph[MAXN][MAXN];
//在bfs中,增广路径的搜索是一层一层展开的,所以必须通过prevX来记录上一层的顶点
//chkY用于标记某个Y顶点是否被目前的X顶点访问尝试过。
int matchX[MAXN], matchY[MAXN], prevX[MAXN], chkY[MAXN];
int queue[MAXN];
int nx, ny; int bfsHungarian()
{
int res = ;
int qs, qe;
memset( matchX, -, sizeof(matchX) );
memset( matchY, -, sizeof(matchY) );
memset( chkY, -, sizeof(chkY) ); for( int i=; i<nx; i++ )
{
if( matchX[i] == - ) //如果该X顶点未找到匹配点,将其放入队列。
{
qs = qe = ;
queue[qe++] = i;
prevX[i] = -; //并且标记,它是路径的起点
bool flag = ; while( qs<qe && !flag )
{
int u = queue[qs];
for( int v=; v<ny&&!flag; v++ )
{
if( graph[u][v] && chkY[v]!=i ) //如果该节点与u有边且未被访问过
{
chkY[v] = i; //标记且将它的前一个顶点放入队列中,也就是下次可能尝试这个顶点看能否为它找到新的节点
queue[qe++] = matchY[v];
if( matchY[v] >= )
prevX[matchY[v]] = u;
else //到达了增广路径的最后一站
{
flag = ;
int d=u, e=v;
while( d!=- ) //一路通过prevX找到路径的起点
{
int t = matchX[d];
matchX[d] = e;
matchY[e] = d;
d = prevX[d];
e = t;
}
}
}
}
qs++;
}
if( matchX[i] != - )
res++;
}
}
return res;
}
【原创】我的KM算法详解的更多相关文章
- KM算法详解[转]
KM算法详解 原帖链接:http://www.cnblogs.com/zpfbuaa/p/7218607.html#_label0 阅读目录 二分图博客推荐 匈牙利算法步骤 匈牙利算法博客推荐 KM算 ...
- KM算法 详解+模板
先说KM算法求二分图的最佳匹配思想,再详讲KM的实现.[KM算法求二分图的最佳匹配思想] 对于具有二部划分( V1, V2 )的加权完全二分图,其中 V1= { x1, x2, x3, ... , x ...
- KM算法详解+模板
http://www.cnblogs.com/wenruo/p/5264235.html KM算法用来求二分图最大权完美匹配. 本文配合该博文服用更佳:趣写算法系列之--匈牙利算法 现在有N男N女,男 ...
- 【原创】RMQ - ST算法详解
ST算法: ID数组下标: 1 2 3 4 5 6 7 8 9 ID数组元素: 5 7 3 1 4 8 2 9 8 1.ST算法作 ...
- (原创)白话KMP算法详解
引子:BF暴力算法 KMP算法知名度相当高,燃鹅其理解难度以及代码实现对于初学数据结构和算法的同学并不友好,经过两天的总结,详细总结KMP算法如下: 初学串的模式匹配时,我们都会接触到,或者说应该能想 ...
- KMP算法详解(转自中学生OI写的。。ORZ!)
KMP算法详解 如果机房马上要关门了,或者你急着要和MM约会,请直接跳到第六个自然段. 我们这里说的KMP不是拿来放电影的(虽然我很喜欢这个软件),而是一种算法.KMP算法是拿来处理字符串匹配的.换句 ...
- FloodFill算法详解及应用
啥是 FloodFill 算法呢,最直接的一个应用就是「颜色填充」,就是 Windows 绘画本中那个小油漆桶的标志,可以把一块被圈起来的区域全部染色. 这种算法思想还在许多其他地方有应用.比如说扫雷 ...
- BM算法 Boyer-Moore高质量实现代码详解与算法详解
Boyer-Moore高质量实现代码详解与算法详解 鉴于我见到对算法本身分析非常透彻的文章以及实现的非常精巧的文章,所以就转载了,本文的贡献在于将两者结合起来,方便大家了解代码实现! 算法详解转自:h ...
- kmp算法详解
转自:http://blog.csdn.net/ddupd/article/details/19899263 KMP算法详解 KMP算法简介: KMP算法是一种高效的字符串匹配算法,关于字符串匹配最简 ...
随机推荐
- Servlet(4)—一个简单的Servlet实例
简单实例 页面请求登陆,提交表单数据 <body> <form action="loginServlet" method="get"> ...
- 如何修改maven的默认jdk版本
问题: 1.创建maven项目的时候,jdk版本是1.5版本,而自己安装的是1.7或者1.8版本. 2.每次右键项目名-maven->update project 时候,项目jdk版本变了,变回 ...
- WordPress主题开发:按分类调用文章
调用catid为2的分类下的文章,就是后台分类链接的tag_ID <?php $cat_query = new WP_Query(array( 'cat' => '2' )); ?> ...
- Reactor反应器模式 (epoll)
1. 背景 最近在看redis源码,主体流程看完了. 在网上看到了reactor模式,看了一下,其实我们经常使用这种模式. 2. 什么是reactor模式 反应器设计模式(Reactor patter ...
- [Python设计模式] 第18章 游戏角色备份——备忘录模式
github地址:https://github.com/cheesezh/python_design_patterns 题目 用代码模拟以下场景,一个游戏角色有生命力,攻击力,防御力等数据,在打Bos ...
- 使用Nodpad++正则替换
例如有以下格式数据: 现在需要将每一行的10位长度的数字串后面增加等号“=”
- Clion使用MinGW编译好的boost库
MinGW编译Boost库可以参考我之前写的编译Boost的文章. 以下是cmake链接boost静态库的配置: cmake_minimum_required(VERSION 3.8) project ...
- Mybatis Generator配置详解
参考:http://www.jianshu.com/p/e09d2370b796 http://mbg.cndocs.tk <?xml version="1.0" encod ...
- iOS实现pdf文件预览,上下翻页、缩放,读取pdf目录
最近有个朋友想做一个pdf预览,要求能够上下滑动翻页.带缩放.目录跳转功能. 因为之前我只做过简单的预览,那时直接用uiwebview实现的,这次找了下资料,发现一个比较好的库. 其原理实现: 自定义 ...
- Mac下的Chrome或Safari访问跨域设置,MBP上使用模拟器Simulator.app或iphone+Safari调试网页
Mac下的Chrome或Safari访问跨域设置: mac下终端启动Chrome $ open -a Google\ Chrome --args --disable-web-security 或 /A ...