三维计算机视觉 —— 中层次视觉 —— RCNN Family
RCNN是从图像中检测物体位置的方法,严格来讲不属于三维计算机视觉。但是这种方法却又非常非常重要,对三维物体的检测非常有启发,所以在这里做个总结。
1、RCNN - the original idea
—— <Rich feature hierarchies for accurate object detection and semantic segmentation>
这篇文章提出了用CNN网络来对物体进行检测的思路。
Q:
a. CNN网络中存在卷积层和池化层,每次池化都会弱化物体的位置信息,强化物体的特征信息,所以CNN网络最终会告诉我们是什么,而不是在哪儿
b. 要使用CNN网络来检测,直觉上我们可以训练一个识别某物体的网络,来对小方块进行分类。但是这需要大量的训练集,可能对于待检测物体,我们没有收集大量训练集的机会
c. CNN网络的图像输入层具有固定的维度,任意大小的小方块是无法直接输入到CNN网络里的
A:
a. 文章提出了可以在已经训练好的网络上利用小规模的训练集进行优化,也能达到很好的效果。
b.通过 selective search来确定可能含有物体的小方块
c.将消方块进行拉伸(warp),送入CNN进行分类,最终实现检测
细节:
1、使用了ILSVRC 2012对网络进行预训练,步长0.01
2、精训练使用的步长是0.001
3、mini-batch size = 128, 其中背景96,带东西的32。有意的bias,让网络更大概率判为背景
4、loss function 中,IoU超过50%判为1,否则为0
5、使用svm对物体类别进行判断
6、对box进行线性回归,获得更高的精度(后面还会提到)
2、SPPNet - 结合金字塔
—— <Spatial pyramid pooling in deep convolutional networks for visual recognition>
在第一步使用rcnn中,检测需要将图片拉伸成特定的大小,便于输入网络。这显然很不合理,很多东西拉伸以后就完全变形了,这会降低检测的精度。所以需要一种不拉伸方块的方法,来对物体进行检测。
Q:
a.拉伸图像会带来识别精度的下降,在r-cnn中尤其明显
A:
a.金字塔池化:将任意维度的图片池化成同一维度。例如,图片为256*256,金字塔接受的就是maxpool2dlayer(16,'stride',16),如果图片为128*128,金字塔接受的就是maxpool2dlayer(8,'stride',8)
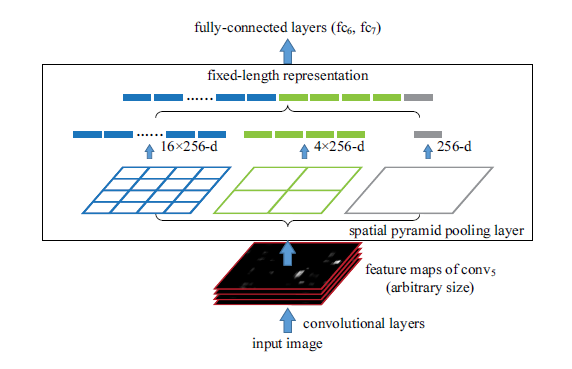
细节:
只用了两种bin size 来构建训练集,180 * 180, 224 * 224. 因为只有两种情况,所以可以很方便的构建bp函数
3、FastCNN - 要啥金字塔,一层就够啦
—— <Fast R-CNN>
Q:
a.对于每个 box/proposal 都需要进行一次feed forward.
b.训练时需要对分类函数和回归函数分开训练
A:
a.对图像进行一次整体的feed forward,得到总的卷积结果;对总结果中的box,每个box一次,分别进行ROI pooling (其实就是金字塔的第一层)
b. ROI pooling 后会得到固定维度的向量,送入多次全连接层,直接映射成类别和box的回归
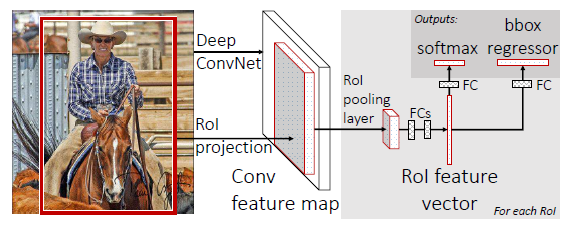
细节:
1、训练时,所有的权重都得到迭代
4、Faster R-CNN — 这才是颠覆
——<Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks>
Q:
a. 对每张图都要进行一次 selective search 以获得proposal太耗时了
A:
a.设计一个神经网络 Region Proposal Net 自动来提出proposal 吧!
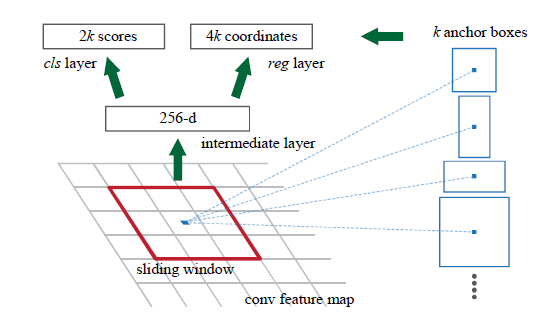
RPN 本质上可以看作一个非常独立的部分,虽然它号称使用了整幅图像的feature,但功能上RPN是独立的。RPN的任务是输入图像,输出一系列Proposal(四点坐标+是否有物体)
1、使用卷积网络的最后一个卷积层卷积完的结果 Last_Image * final_convolution2dlayer(n,d). 作为RPN的真正输入(前面都是公用的,后面才是RPN)
2、使用一个3*3的小卷积掩模将1中的结果抽象成d 维向量。
3、将该向量送入2个全连接层——分类全连接(2K输出)和坐标全连接(4K输出)————k个proposal (3 scale,2 aspect ratio)
4、在2中,掩模的位置决定了全连接输出参数的"原点"
5、总结
在神经网络中,全连接是最强的非线性映射方式,也是花费最重的。在结果层少量的使用全连接以换取强大的映射方程是很有意义的。
说了那么多,和三维视觉有毛关系?其实关系在这里,在二维图像中检测物体位置和在三维图像中检测物体位姿是对偶的。不信?见 <Deep Sliding Shapes for amodal 3D object detection in RGB-D images>
三维计算机视觉 —— 中层次视觉 —— RCNN Family的更多相关文章
- 三维计算机视觉 — 中层次视觉 — Point Pair Feature
机器人视觉中有一项重要人物就是从场景中提取物体的位置,姿态.图像处理算法借助Deep Learning 的东风已经在图像的物体标记领域耍的飞起了.而从三维场景中提取物体还有待研究.目前已有的思路是先提 ...
- PCL —— RCNN Family 中层次点云处理
博客转载自:http://www.cnblogs.com/ironstark/p/6046411.html RCNN是从图像中检测物体位置的方法,严格来讲不属于三维计算机视觉.但是这种方法却又非常非常 ...
- PCL—低层次视觉—关键点检测(NARF)
关键点检测本质上来说,并不是一个独立的部分,它往往和特征描述联系在一起,再将特征描述和识别.寻物联系在一起.关键点检测可以说是通往高层次视觉的重要基础.但本章节仅在低层次视觉上讨论点云处理问题,故所有 ...
- PCL—低层次视觉—关键点检测(rangeImage)
关键点又称为感兴趣的点,是低层次视觉通往高层次视觉的捷径,抑或是高层次感知对低层次处理手段的妥协. ——三维视觉关键点检测 1.关键点,线,面 关键点=特征点: 关键线=边缘: 关键面=foregro ...
- PCL—低层次视觉—点云分割(邻近信息)
分割给人最直观的影响大概就是邻居和我不一样.比如某条界线这边是中华文明,界线那边是西方文,最简单的分割方式就是在边界上找些居民问:"小伙子,你到底能不能上油管啊?”.然后把能上油管的居民坐标 ...
- [Deep-Learning-with-Python]计算机视觉中的深度学习
包括: 理解卷积神经网络 使用数据增强缓解过拟合 使用预训练卷积网络做特征提取 微调预训练网络模型 可视化卷积网络学习结果以及分类决策过程 介绍卷积神经网络,convnets,深度学习在计算机视觉方面 ...
- PCL — Point Pair Feature 中层次点云处理
博客转载自:http://www.cnblogs.com/ironstark/p/5971976.html 机器人视觉中有一项重要人物就是从场景中提取物体的位置,姿态.图像处理算法借助Deep Lea ...
- 计算机视觉中的词袋模型(Bow,Bag-of-words)
计算机视觉中的词袋模型(Bow,Bag-of-words) Bag-of-words 读 'xw20084898的专栏'的blogBag-of-words model in computer visi ...
- 三维场景中使用BillBoard技术
三维场景中对于渲染效果不是很精致的物体可以使用BillBoard技术实现,使用该技术需要将物体实时朝向摄像机,即计算billboard的旋转矩阵M. 首先根据摄像机位置cameraPos和billBo ...
随机推荐
- Python基础-列表、元祖、字典、字符串
列表和分组 序列概览: 数据结构是通过某种方式组织在一起的数据元素的集合.这些元素可以是数字.字符,甚至可以是其他数据结构. 在python中,最基本的数据结构是序列(sequence). 序列中的每 ...
- Nginx的https配置记录以及http强制跳转到https的方法梳理
一.Nginx安装(略)安装的时候需要注意加上 --with-http_ssl_module,因为http_ssl_module不属于Nginx的基本模块.Nginx安装方法: 1 2 # ./con ...
- vue定义全局变量
思路 将变量放到 window 对象上面 1.普通 创建 global.js window.a = 1; main.js 中引用 import './global.js' 实际使用 console.l ...
- Unity中调用DLL库
DLL -- Dynamic Link Library(动态链接库文件),这里以Window平台为例. Unity支持的两种语言生成的DLL库(C++.C#),这里以C#为例,C++网上可以搜索很详细 ...
- [web 前端] css3 transform方法常用属性
cp from : https://www.cnblogs.com/chrxc/p/5126569.html css3中transform方法是一个功能强大的属性,可以对元素进行移动.缩放.转动.拉长 ...
- SpringBoot(十):读取application.yml下配置参数信息,java -jar启动时项目修改参数
读取application.yml下配置参数信息 在application.yml文件内容 my: remote-address: 192.168.1.1 yarn: weburl: http://1 ...
- ACC自适应巡航控制系统介绍
本文是关于ACC自适应巡航控制系统的介绍,罗孚从个人视角出发,描述对ACC系统的理解,以及在一些使用场景下的思考. 什么是ACC? ACC系统是在定速巡航装置的基础上发展而来的,区别在于定速巡航只能限 ...
- 第三天:MDN CSS学习笔记
一:CSS基础 1:DOM 当浏览器显示文档时,它必须将文档的内容与其样式信息结合.它分两个阶段处理文档: 浏览器将 HTML 和 CSS 转化成 DOM (文档对象模型).DOM在计算机内存中表示文 ...
- 【PMP】项目管理ITTO概述
1.项目整合管理
- MongoDB地理空间数据存储及检索
目录 1.存入地理数据 GeoJSON数据存入 1.Ponit 点数据 2.LineString 线数据(多段线) 3. Polygon 多边形数据 4.MultiPoint多点.MultiLineS ...