斯坦福大学公开课机器学习:梯度下降运算的特征缩放(gradient descent in practice 1:feature scaling)
以房屋价格为例,假设有两个特征向量:X1:房子大小(1-2000 feets), X2:卧室数量(1-5)
关于这两个特征向量的代价函数如下图所示:
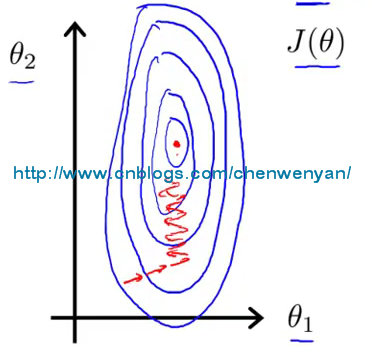
从上图可以看出,代价函数是一个又瘦又高的椭圆形轮廓图,如果用这个代价函数来运行梯度下降的话,得到最终的梯度值,可能需要花费很长的时间,甚至可能来回震动,最终才能收敛到全局最小值。为了减少梯度下来花费的时间,最好的办法就是对特征向量进行缩放(feature scaling)。
特征向量缩放(feature scaling):具体来说,还是以上面的房屋价格为例,假设有两个特征向量:X1:房子大小(1-2000 feets), X2:卧室数量(1-5),现在将它们转化为如下公式:

即将房子大小除以2000,卧室的数量除以5.
这个时候代价函数就会变得比较圆,计算最终梯度值的速度也会随之变快,如下图所示:

一般情况下,我们进行特征向量缩放的目的是将特征的取值约束到[-1 ,1]之间,而特征X0恒等于1,[-1,1]这个范围并不是很严格的,事实上,假如存在特征向量X1,其缩放以后为[0,3]或者[-2,0.5]之间,这也是允许的。但是如果是在[-100,100]或者[-0.0001,0.0001]之间,则是不允许的,跟[-1,1]差距太大了。
将特征向量除以最大值是特征缩放的其中一种方式,还有另一种方式是均值归一化(mean normalization),其思想如下:
假设将特征向量Xi用Xi-μi代替,使其均值接近0,假设房子平均大小为1000 feets,平均卧室数量为2,则特征向量可以转化为如下公式:
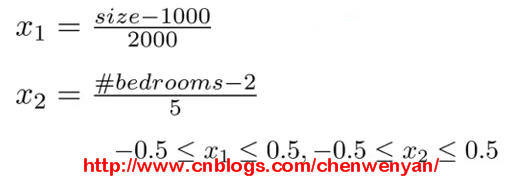
一般情况下,可以用X1来代替原来的特征X1,具体公式如下:
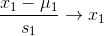
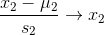
x1,x2指的是原来的特征向量,u1,u2指的是在训练集中,特征向量x1,x2分别的平均值,s1,s2指的是该特征值的范围(即最大值减去最小值),也可以把s1,s2改为变量的标准差
斯坦福大学公开课机器学习:梯度下降运算的特征缩放(gradient descent in practice 1:feature scaling)的更多相关文章
- 斯坦福大学公开课机器学习:advice for applying machine learning | diagnosing bias vs. variance(机器学习:诊断偏差和方差问题)
当我们运行一个学习算法时,如果这个算法的表现不理想,那么有两种原因导致:要么偏差比较大.要么方差比较大.换句话说,要么是欠拟合.要么是过拟合.那么这两种情况,哪个和偏差有关.哪个和方差有关,或者是不是 ...
- 第19月第8天 斯坦福大学公开课机器学习 (吴恩达 Andrew Ng)
1.斯坦福大学公开课机器学习 (吴恩达 Andrew Ng) http://open.163.com/special/opencourse/machinelearning.html 笔记 http:/ ...
- 斯坦福大学公开课机器学习:梯度下降运算的学习率a(gradient descent in practice 2:learning rate alpha)
本章节主要讲怎么确定梯度下降的工作是正确的,第二是怎么选择学习率α,如下图所示: 上图显示的是梯度下降算法迭代过程中的代价函数j(θ)的值,横轴是迭代步数,纵轴是j(θ)的值 如果梯度算法正常工作,那 ...
- 斯坦福大学公开课机器学习: machine learning system design | error analysis(误差分析:检验算法是否有高偏差和高方差)
误差分析可以更系统地做出决定.如果你准备研究机器学习的东西或者构造机器学习应用程序,最好的实践方法不是建立一个非常复杂的系统.拥有多么复杂的变量,而是构建一个简单的算法.这样你可以很快地实现它.研究机 ...
- 斯坦福大学公开课机器学习:machine learning system design | error metrics for skewed classes(偏斜类问题的定义以及针对偏斜类问题的评估度量值:查准率(precision)和召回率(recall))
上篇文章提到了误差分析以及设定误差度量值的重要性.那就是设定某个实数来评估学习算法并衡量它的表现.有了算法的评估和误差度量值,有一件重要的事情要注意,就是使用一个合适的误差度量值,有时会对学习算法造成 ...
- 斯坦福大学公开课机器学习: machine learning system design | prioritizing what to work on : spam classification example(设计复杂机器学习系统的主要问题及构建复杂的机器学习系统的建议)
当我们在进行机器学习时着重要考虑什么问题.以垃圾邮件分类为例子.假如你想建立一个垃圾邮件分类器,看这些垃圾邮件与非垃圾邮件的例子.左边这封邮件想向你推销东西.注意这封垃圾邮件有意的拼错一些单词,就像M ...
- 斯坦福大学公开课机器学习:advice for applying machine learning | learning curves (改进学习算法:高偏差和高方差与学习曲线的关系)
绘制学习曲线非常有用,比如你想检查你的学习算法,运行是否正常.或者你希望改进算法的表现或效果.那么学习曲线就是一种很好的工具.学习曲线可以判断某一个学习算法,是偏差.方差问题,或是二者皆有. 为了绘制 ...
- 斯坦福大学公开课机器学习:advice for applying machine learning | model selection and training/validation/test sets(模型选择以及训练集、交叉验证集和测试集的概念)
怎样选用正确的特征构造学习算法或者如何选择学习算法中的正则化参数lambda?这些问题我们称之为模型选择问题. 在对于这一问题的讨论中,我们不仅将数据分为:训练集和测试集,而是将数据分为三个数据组:也 ...
- 斯坦福大学公开课机器学习:advice for applying machine learning - deciding what to try next(设计机器学习系统时,怎样确定最适合、最正确的方法)
假如我们在开发一个机器学习系统,想试着改进一个机器学习系统的性能,我们应该如何决定接下来应该选择哪条道路? 为了解释这一问题,以预测房价的学习例子.假如我们已经得到学习参数以后,要将我们的假设函数放到 ...
随机推荐
- Linux系统下本地yum镜像源环境部署-完整记录
之前介绍了Linux环境下本地yum源配置方法,不过这个是最简单最基础的配置,在yum安装的时候可能有些软件包不够齐全,下面说下完整yun镜像源系统环境部署记录(yum源更新脚本下载地址:https: ...
- jeecg的下拉列表
jeecg里面下拉列表的使用 ①建立数据字典seo_id <t:dictSelect field="operationPromotionAccount" typeGroupC ...
- 第三个Sprint ------第十天
上传到Github github 地址:https://github.com/be821/MyCat 百度云盘: 链接: http://pan.baidu.com/s/1hrxL6lu 密码: k9t ...
- myBatis外部的resultMap高级应用
resultMap:外部的resultMap的引用,和resultType不能同时使用. <resultMap id="BaseResultMap" type="c ...
- Vue中常用的三种传值方式
父传子 父子组件的关系可以总结为prop向下传递,事件向上传递.父组件通过prop给子组件下发数据,子组件通过事件给父组件发送消息. 父组件: <template> <div> ...
- MySQL的basedir
C:\Documents and Settings\All Users\Application Data\MySQL\MySQL Server 5.7\Data
- HP 4411s Install Red Hat Enterprise Linux 5.8) Wireless Driver
pick up from http://blog.163.com/wangkangming2008%40126/blog/static/78277928201131994053617/ # cp iw ...
- Java和Android的Lru缓存,及其实现原理
一.概述 Android提供了LRUCache类,可以方便的使用它来实现LRU算法的缓存.Java提供了LinkedHashMap,可以用该类很方便的实现LRU算法,Java的LRULinkedHas ...
- pxe+kickstart 自动化部署linux操作系统
kickstart 是什么? 批量部署Linux服务器操作系统 运行模式: C/S client/server 服务器上要部署: DHCP tftp(非交互式文件共享) 安装系统的三个步骤: 1.加载 ...
- shell if [[ ]]和[ ]区别 || &&
[]和test 两者是一样的,在命令行里test expr和[ expr ]的效果相同. test的三个基本作用是判断文件.判断字符串.判断整数.支持使用 ”与或非“ 将表达式连接起来. test中可 ...