K均值
K-means算法的工作流程
首先,随机确定k个初始点的质心;然后将数据集中的每一个点分配到一个簇中,即为每一个点找到距其最近的质心,并将其分配给该质心所对应的簇;该步完成后,每一个簇的质心更新为该簇所有点的平均值。伪代码如下:

创建k个点作为起始质心,可以随机选择(位于数据边界内)
当任意一个点的簇分配结果发生改变时
对数据集中每一个点
对每个质心
计算质心与数据点之间的距离
将数据点分配到距其最近的簇
对每一个簇,计算簇中所有点的均值并将均值作为质心
再看实际的代码:
#导入numpy库
from numpy import *
#K-均值聚类辅助函数 #文本数据解析函数
def numpy import *
dataMat=[]
fr=open(fileName)
for line in fr.readlines():
curLine=line.strip().split('\t')
#将每一行的数据映射成float型
fltLine=map(float,curLine)
dataMat.append(fltLine)
return dataMat #数据向量计算欧式距离
def distEclud(vecA,vecB):
return sqrt(sum(power(vecA-vecB,2))) #随机初始化K个质心(质心满足数据边界之内)
def randCent(dataSet,k):
#得到数据样本的维度
n=shape(dataSet)[1]
#初始化为一个(k,n)的矩阵
centroids=mat(zeros((k,n)))
#遍历数据集的每一维度
for j in range(n):
#得到该列数据的最小值
minJ=min(dataSet[:,j])
#得到该列数据的范围(最大值-最小值)
rangeJ=float(max(dataSet[:,j])-minJ)
#k个质心向量的第j维数据值随机为位于(最小值,最大值)内的某一值
centroids[:,j]=minJ+rangeJ*random.rand(k,1)
#返回初始化得到的k个质心向量
return centroids #k-均值聚类算法
#@dataSet:聚类数据集
#@k:用户指定的k个类
#@distMeas:距离计算方法,默认欧氏距离distEclud()
#@createCent:获得k个质心的方法,默认随机获取randCent()
def kMeans(dataSet,k,distMeas=distEclud,createCent=randCent):
#获取数据集样本数
m=shape(dataSet)[0]
#初始化一个(m,2)的矩阵
clusterAssment=mat(zeros((m,2)))
#创建初始的k个质心向量
centroids=createCent(dataSet,k)
#聚类结果是否发生变化的布尔类型
clusterChanged=True
#只要聚类结果一直发生变化,就一直执行聚类算法,直至所有数据点聚类结果不变化
while clusterChanged:
#聚类结果变化布尔类型置为false
clusterChanged=False
#遍历数据集每一个样本向量
for i in range(m):
#初始化最小距离最正无穷;最小距离对应索引为-1
minDist=inf;minIndex=-1
#循环k个类的质心
for j in range(k):
#计算数据点到质心的欧氏距离
distJI=distMeas(centroids[j,:],dataSet[i,:])
#如果距离小于当前最小距离
if distJI<minDist:
#当前距离定为当前最小距离;最小距离对应索引对应为j(第j个类)
minDist=distJI;minIndex=j
#当前聚类结果中第i个样本的聚类结果发生变化:布尔类型置为true,继续聚类算法
if clusterAssment[i,0] !=minIndex:clusterChanged=True
#更新当前变化样本的聚类结果和平方误差
clusterAssment[i,:]=minIndex,minDist**2
#打印k-均值聚类的质心
print centroids
#遍历每一个质心
for cent in range(k):
#将数据集中所有属于当前质心类的样本通过条件过滤筛选出来
ptsInClust=dataSet[nonzero(clusterAssment[:,0].A==cent)[0]]
#计算这些数据的均值(axis=0:求列的均值),作为该类质心向量
centroids[cent,:]=mean(ptsInClust,axis=0)
#返回k个聚类,聚类结果及误差
return centroids,clusterAssment
需要说明的是,在算法中,相似度的计算方法默认的是欧氏距离计算,当然也可以使用其他相似度计算函数,比如余弦距离;算法中,k个类的初始化方式为随机初始化,并且初始化的质心必须在整个数据集的边界之内,这可以通过找到数据集每一维的最大值和最小值;然后最小值+取值范围*0到1的随机数,来确保随机点在数据边界之内。
在实际的K-means算法中,采用计算质心-分配-重新计算质心的方式反复迭代,算法停止的条件是,当然数据集所有的点分配的距其最近的簇不在发生变化时,就停止分配,更新所有簇的质心后,返回k个类的质心(一般是向量的形式)组成的质心列表,以及存储各个数据点的分类结果和误差距离的平方的二维矩阵。
上面返回的结果中,之所以存储每个数据点距离其质心误差距离平方,是便于后续的算法预处理。因为K-means算法采取的是随机初始化k个簇的质心的方式,因此聚类效果又可能陷入局部最优解的情况,局部最优解虽然效果不错,但不如全局最优解的聚类效果更好。所以,后续会在算法结束后,采取相应的后处理,使算法跳出局部最优解,达到全局最优解,获得最好的聚类效果。
可以看一个聚类的例子:


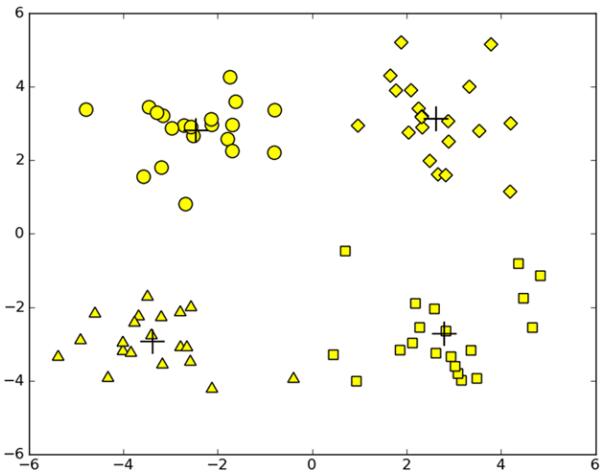
3 后处理提高聚类性能
 有时候当我们观察聚类的结果图时,发现聚类的效果没有那么好,如上图所示,K-means算法在k值选取为3时的聚类结果,我们发现,算法能够收敛但效果较差。显然,这种情况的原因是,算法收敛到了局部最小值,而并不是全局最小值,局部最小值显然没有全局最小值的结果好。
有时候当我们观察聚类的结果图时,发现聚类的效果没有那么好,如上图所示,K-means算法在k值选取为3时的聚类结果,我们发现,算法能够收敛但效果较差。显然,这种情况的原因是,算法收敛到了局部最小值,而并不是全局最小值,局部最小值显然没有全局最小值的结果好。
那么,既然知道了算法已经陷入了局部最小值,如何才能够进一步提升K-means算法的效果呢?
一种用于度量聚类效果的指标是SSE,即误差平方和, 为所有簇中的全部数据点到簇中心的误差距离的平方累加和。SSE的值如果越小,表示数据点越接近于它们的簇中心,即质心,聚类效果也越好。因为,对误差取平方后,就会更加重视那些远离中心的数据点。
显然,我们知道了一种改善聚类效果的做法就是降低SSE,那么如何在保持簇数目不变的情况下提高簇的质量呢?
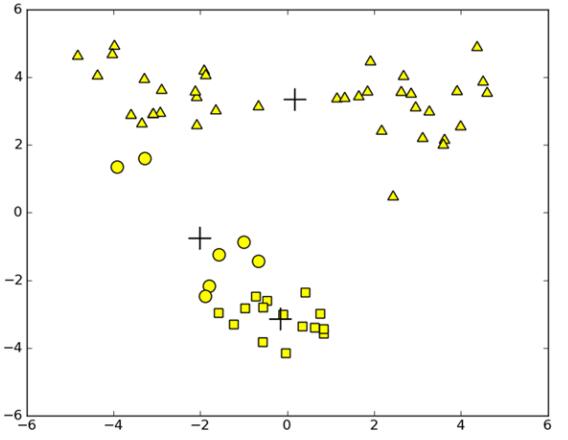
一种方法是:我们可以将具有最大SSE值得簇划分为两个簇(因为,SSE最大的簇一般情况下,意味着簇内的数据点距离簇中心较远),具体地,可以将最大簇包含的点过滤出来并在这些点上运行K-means算法,其中k设为2.
同时,当把最大的簇(上图中的下半部分)分为两个簇之后,为了保证簇的数目是不变的,我们可以再合并两个簇。具体地:
一方面我们可以合并两个最近的质心所对应的簇,即计算所有质心之间的距离,合并质心距离最近的两个质心所对应的簇。
另一方面,我们可以合并两个使得SSE增幅最小的簇,显然,合并两个簇之后SSE的值会有所上升,那么为了最好的聚类效果,应该尽可能使总的SSE值小,所以就选择合并两个簇后SSE涨幅最小的簇。具体地,就是计算合并任意两个簇之后的总得SSE,选取合并后最小的SSE对应的两个簇进行合并。这样,就可以满足簇的数目不变。
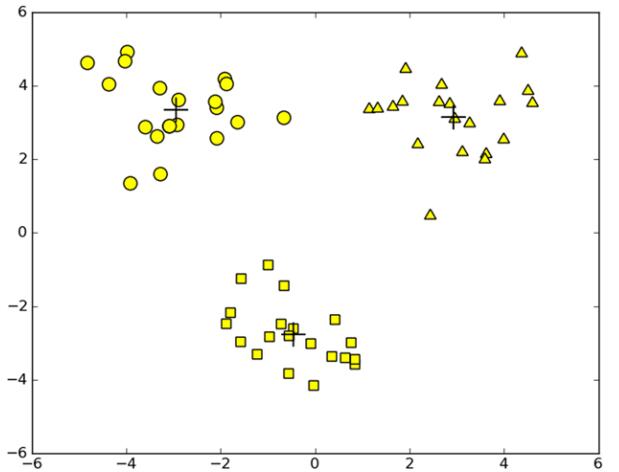
上面,是对已经聚类完成的结果进行改善的方法,在不改变k值的情况下,上述方法能够起到一定的作用,会使得聚类效果得到一定的改善。那么,下面要讲到的是一种克服算法收敛于局部最小值问题的K-means算法。即二分k-均值算法。
二分K-means算法
二分K-means算法首先将所有点作为一个簇,然后将簇一分为二。之后选择其中一个簇继续进行划分,选择哪一个簇取决于对其进行划分是否能够最大程度的降低SSE的值。上述划分过程不断重复,直至划分的簇的数目达到用户指定的值为止。
二分K-means算法的伪代码如下:
将所有点看成一个簇
当簇数目小于k时
对于每一个簇
计算总误差
在给定的簇上面进行k-均值聚类(k=2)
计算将该簇一分为二之后的总误差
选择使得总误差最小的簇进行划分
当然,也可以选择SSE最大的簇进行划分,知道簇数目达到用户指定的数目为止。下面看具体的代码:
#二分K-均值聚类算法
#@dataSet:待聚类数据集
#@k:用户指定的聚类个数
#@distMeas:用户指定的距离计算方法,默认为欧式距离计算
def biKmeans(dataSet,k,distMeas=distEclud):
#获得数据集的样本数
m=shape(dataSet)[0]
#初始化一个元素均值0的(m,2)矩阵
clusterAssment=mat(zeros((m,2)))
#获取数据集每一列数据的均值,组成一个长为列数的列表
centroid0=mean(dataSet,axis=0).tolist()[0]
#当前聚类列表为将数据集聚为一类
centList=[centroid0]
#遍历每个数据集样本
for j in range(m):
#计算当前聚为一类时各个数据点距离质心的平方距离
clusterAssment[j,1]=distMeas(mat(centroid0),dataSet[j,:])**2
#循环,直至二分k-均值达到k类为止
while (len(centList)<k):
#将当前最小平方误差置为正无穷
lowerSSE=inf
#遍历当前每个聚类
for i in range(len(centList)):
#通过数组过滤筛选出属于第i类的数据集合
ptsInCurrCluster=\
dataSet[nonzero(clusterAssment[:,0].A==i)[0],:]
#对该类利用二分k-均值算法进行划分,返回划分后结果,及误差
centroidMat,splitClustAss=\
kMeans(ptsInCurrCluster,2,distMeas)
#计算该类划分后两个类的误差平方和
sseSplit=sum(splitClustAss[:,1])
#计算数据集中不属于该类的数据的误差平方和
sseNotSplit=\
sum(clusterAssment[nonzero(clusterAssment[:,0].A!=i)[0],1])
#打印这两项误差值
print('sseSplit,and notSplit:',%(sseSplit,sseNotSplit))
#划分第i类后总误差小于当前最小总误差
if(sseSplit+sseNotSplit)<lowerSSE:
#第i类作为本次划分类
bestCentToSplit=i
#第i类划分后得到的两个质心向量
bestNewCents=centroidMat
#复制第i类中数据点的聚类结果即误差值
bestClustAss=splitClustAss.copy()
#将划分第i类后的总误差作为当前最小误差
lowerSSE=sseSplit+sseNotSplit
#数组过滤筛选出本次2-均值聚类划分后类编号为1数据点,将这些数据点类编号变为
#当前类个数+1,作为新的一个聚类
bestClustAss[nonzero(bestClustAss[:,0].A==1)[0],0]=\
len(centList)
#同理,将划分数据集中类编号为0的数据点的类编号仍置为被划分的类编号,使类编号
#连续不出现空缺
bestClustAss[nonzero(bestClustAss[:,0].A==0)[0],0]=\
bestCentToSplit
#打印本次执行2-均值聚类算法的类
print('the bestCentToSplit is:',%bestCentToSplit)
#打印被划分的类的数据个数
print('the len of bestClustAss is:',%(len(bestClustAss)))
#更新质心列表中的变化后的质心向量
centList[bestCentToSplit]=bestNewCents[0,:]
#添加新的类的质心向量
centList.append(bestNewCents[1,:])
#更新clusterAssment列表中参与2-均值聚类数据点变化后的分类编号,及数据该类的误差平方
clusterAssment[nonzero(clusterAssment[:,0].A==\
bestCentToSplit)[0],:]=bestClustAss
#返回聚类结果
return mat(centList),clusterAssment
在上述算法中,直到簇的数目达到k值,算法才会停止。在算法中通过将所有的簇进行划分,然后分别计算划分后所有簇的误差。选择使得总误差最小的那个簇进行划分。划分完成后,要更新簇的质心列表,数据点的分类结果及误差平方。具体地,假设划分的簇为m(m<k)个簇中的第i个簇,那么这个簇分成的两个簇后,其中一个取代该被划分的簇,成为第i个簇,并计算该簇的质心;此外,将划分得到的另外一个簇,作为一个新的簇,成为第m+1个簇,并计算该簇的质心。此外,算法中还存储了各个数据点的划分结果和误差平方,此时也应更新相应的存储信息。这样,重复该过程,直至簇个数达到k。
通过上述算法,之前陷入局部最小值的的这些数据,经过二分K-means算法多次划分后,逐渐收敛到全局最小值,从而达到了令人满意的聚类效果。
四,示例:对地图上的点进行聚类
现在有一个存有70个地址和城市名的文本,而没有这些地点的距离信息。而我们想要对这些地点进行聚类,找到每个簇的质心地点,从而可以安排合理的行程,即质心之间选择交通工具抵达,而位于每个质心附近的地点就可以采取步行的方法抵达。显然,K-means算法可以为我们找到一种更加经济而且高效的出行方式。
1 通过地址信息获取相应的经纬度信息
那么,既然没有地点之间的距离信息,怎么计算地点之间的距离呢?又如何比较地点之间的远近呢?
我们手里只有各个地点的地址信息,那么如果有一个API,可以让我们输入地点信息,返回该地点的经度和纬度信息,那么我们就可以通过球面距离计算方法得到两个地点之间的距离了。而Yahoo!PlaceFinder API可以帮助我们实现这一目标。获取地点信息对应经纬度的代码如下:
#Yahoo!PlaceFinder API
#导入urllib
import urllib
#导入json模块
import json #利用地名,城市获取位置经纬度函数
def geoGrab(stAddress,city):
#获取经纬度网址
apiStem='http://where.yahooapis.com/geocode?'
#初始化一个字典,存储相关参数
params={}
#返回类型为json
params['flags']='J'
#参数appid
params['appid']='ppp68N8t'
#参数地址位置信息
params['location']=('%s %s', %(stAddress,city))
#利用urlencode函数将字典转为URL可以传递的字符串格式
url_params=urllib.urlencode(params)
#组成完整的URL地址api
yahooApi=apiStem+url_params
#打印该URL地址
print('%s',yahooApi)
#打开URL,返回json格式的数据
c=urllib.urlopen(yahooApi)
#返回json解析后的数据字典
return json.load(c.read()) from time import sleep
#具体文本数据批量地址经纬度获取函数
def massPlaceFind(fileName):
#新建一个可写的文本文件,存储地址,城市,经纬度等信息
fw=open('places.txt','wb+')
#遍历文本的每一行
for line in open(fileName).readlines();
#去除首尾空格
line =line.strip()
#按tab键分隔开
lineArr=line.split('\t')
#利用获取经纬度函数获取该地址经纬度
retDict=geoGrab(lineArr[1],lineArr[2])
#如果错误编码为0,表示没有错误,获取到相应经纬度
if retDict['ResultSet']['Error']==0:
#从字典中获取经度
lat=float(retDict['ResultSet']['Results'][0]['latitute'])
#维度
lng=float(retDict['ResultSet']['Results'][0]['longitute'])
#打印地名及对应的经纬度信息
print('%s\t%f\t%f',%(lineArr[0],lat,lng))
#将上面的信息存入新的文件中
fw.write('%s\t%f\t%f\n',%(line,lat,lng))
#如果错误编码不为0,打印提示信息
else:print('error fetching')
#为防止频繁调用API,造成请求被封,使函数调用延迟一秒
sleep(1)
#文本写入关闭
fw.close()
在上述代码中,首先创建一个字典,字典里面存储的是通过URL获取经纬度所必要的参数,即我们想要的返回的数据格式flogs=J;获取数据的appid;以及要输入的地址信息(stAddress,city)。然后,通过urlencode()函数帮助我们将字典类型的信息转化为URL可以传递的字符串格式。最后,打开URL获取返回的JSON类型数据,通过JSON工具来解析返回的数据。且在返回的结果中,当错误编码为0时表示,得到了经纬度信息,而为其他值时,则表示返回经纬度信息失败。
此外,在代码中,每次获取完一个地点的经纬度信息后,延迟一秒钟。这样做的目的是为了避免频繁的调用API,请求被封掉的情况。
2 对地理位置进行聚类
我们已经得到了各个地点的经纬度信息,但是我们还要选择计算距离的合适的方式。我们知道,在北极每走几米的经度变化可能达到数十度,而沿着赤道附近走相同的距离,带来的经度变化可能是零。这是,我们可以使用球面余弦定理来计算两个经纬度之间的实际距离。具体代码如下:
#球面距离计算及簇绘图函数
def distSLC(vecA,vecB):
#sin()和cos()以弧度未输入,将float角度数值转为弧度,即*pi/180
a=sin(vecA[0,1]*pi/180)*sin(vecB[0,1]*pi/180)
b=cos(vecA[0,1]*pi/180)*cos(vecB[0,1]*pi/180)*\
cos(pi*(vecB[0,0]-vecA[0,0])/180)
return arcos(a+b)*6371.0 import matplotlib
import matplotlib.pyplot as plt #@numClust:聚类个数,默认为5
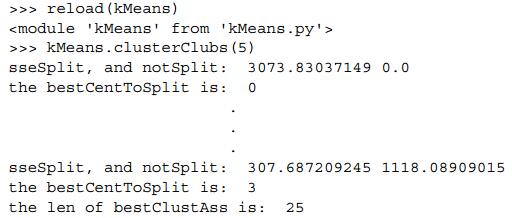
def clusterClubs(numClust=5):
datList=[]
#解析文本数据中的每一行中的数据特征值
for line in open('places.txt').readlines():
lineArr=line.split('\t')
datList.append([float(lineArr[4]),float(lineArr[4])])
datMat=mat(datList)
#利用2-均值聚类算法进行聚类
myCentroids,clusterAssing=biKmeans(datMat,numClust,\
distMeas=distSLC)
#对聚类结果进行绘图
fig=plt.figure()
rect=[0.1,0.1,0.8,0.8]
scatterMarkers=['s','o','^','8'.'p',\
'd','v','h','>','<']
axprops=dict(xticks=[],ytick=[])
ax0=fig.add_axes(rect,label='ax0',**axprops)
imgP=plt.imread('Portland.png')
ax0.imshow(imgP)
ax1=fig.add_axes(rect,label='ax1',frameon=False)
for i in range(numClust):
ptsInCurrCluster=datMat[nonzero(clusterAssing[:,0].A==i)[0],:]
markerStyle=scatterMarkers[i % len(scatterMarkers))]
ax1.scatter(ptsInCurrCluster[:,0].flatten().A[0],\
ptsInCurrCluster[:,1].flatten().A[0],\
marker=markerStyle,s=90)
ax1.scatter(myCentroids[:,0].flatten().A[0],\
myCentroids[:,1].flatten().A[0],marker='+',s=300)
#绘制结果显示
plt.show()
最后,将聚类的结果绘制出来:
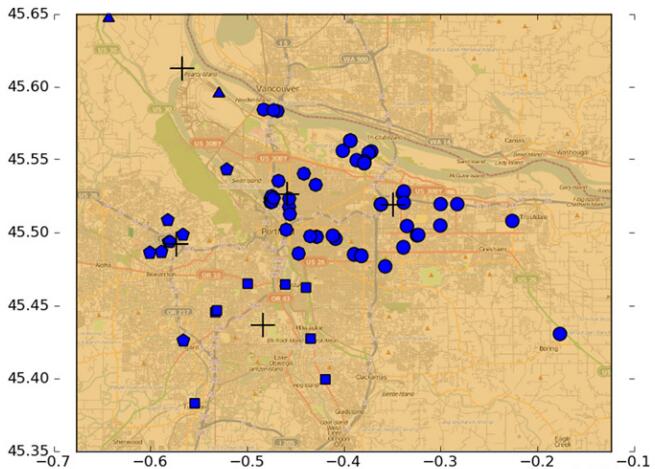
五,小结
1 聚类是一种无监督的学习方法。聚类区别于分类,即事先不知道要寻找的内容,没有预先设定好的目标变量。
2 聚类将数据点归到多个簇中,其中相似的数据点归为同一簇,而不相似的点归为不同的簇。相似度的计算方法有很多,具体的应用选择合适的相似度计算方法
3 K-means聚类算法,是一种广泛使用的聚类算法,其中k是需要指定的参数,即需要创建的簇的数目,K-means算法中的k个簇的质心可以通过随机的方式获得,但是这些点需要位于数据范围内。在算法中,计算每个点到质心得距离,选择距离最小的质心对应的簇作为该数据点的划分,然后再基于该分配过程后更新簇的质心。重复上述过程,直至各个簇的质心不再变化为止。
4 K-means算法虽然有效,但是容易受到初始簇质心的情况而影响,有可能陷入局部最优解。为了解决这个问题,可以使用另外一种称为二分K-means的聚类算法。二分K-means算法首先将所有数据点分为一个簇;然后使用K-means(k=2)对其进行划分;下一次迭代时,选择使得SSE下降程度最大的簇进行划分;重复该过程,直至簇的个数达到指定的数目为止。实验表明,二分K-means算法的聚类效果要好于普通的K-means聚类算法。
K均值的更多相关文章
- 基于改进人工蜂群算法的K均值聚类算法(附MATLAB版源代码)
其实一直以来也没有准备在园子里发这样的文章,相对来说,算法改进放在园子里还是会稍稍显得格格不入.但是最近邮箱收到的几封邮件让我觉得有必要通过我的博客把过去做过的东西分享出去更给更多需要的人.从论文刊登 ...
- 【转】算法杂货铺——k均值聚类(K-means)
k均值聚类(K-means) 4.1.摘要 在前面的文章中,介绍了三种常见的分类算法.分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别与之对应.但是很多时 ...
- 5-Spark高级数据分析-第五章 基于K均值聚类的网络流量异常检测
据我们所知,有‘已知的已知’,有些事,我们知道我们知道:我们也知道,有 ‘已知的未知’,也就是说,有些事,我们现在知道我们不知道.但是,同样存在‘不知的不知’——有些事,我们不知道我们不知道. 上一章 ...
- 机器学习实战5:k-means聚类:二分k均值聚类+地理位置聚簇实例
k-均值聚类是非监督学习的一种,输入必须指定聚簇中心个数k.k均值是基于相似度的聚类,为没有标签的一簇实例分为一类. 一 经典的k-均值聚类 思路: 1 随机创建k个质心(k必须指定,二维的很容易确定 ...
- 聚类算法:K-means 算法(k均值算法)
k-means算法: 第一步:选$K$个初始聚类中心,$z_1(1),z_2(1),\cdots,z_k(1)$,其中括号内的序号为寻找聚类中心的迭代运算的次序号. 聚类中心的向量值可任意设 ...
- Python实现kMeans(k均值聚类)
Python实现kMeans(k均值聚类) 运行环境 Pyhton3 numpy(科学计算包) matplotlib(画图所需,不画图可不必) 计算过程 st=>start: 开始 e=> ...
- 聚类算法:K均值、凝聚层次聚类和DBSCAN
聚类分析就仅根据在数据中发现的描述对象及其关系的信息,将数据对象分组(簇).其目标是,组内的对象相互之间是相似的,而不同组中的对象是不同的.组内相似性越大,组间差别越大,聚类就越好. 先介绍下聚类的不 ...
- 机器学习理论与实战(十)K均值聚类和二分K均值聚类
接下来就要说下无监督机器学习方法,所谓无监督机器学习前面也说过,就是没有标签的情况,对样本数据进行聚类分析.关联性分析等.主要包括K均值聚类(K-means clustering)和关联分析,这两大类 ...
- 第十篇:K均值聚类(KMeans)
前言 本文讲解如何使用R语言进行 KMeans 均值聚类分析,并以一个关于人口出生率死亡率的实例演示具体分析步骤. 聚类分析总体流程 1. 载入并了解数据集:2. 调用聚类函数进行聚类:3. 查看聚类 ...
- K均值聚类的失效性分析
K均值聚类是一种应用广泛的聚类技术,特别是它不依赖于任何对数据所做的假设,比如说,给定一个数据集合及对应的类数目,就可以运用K均值方法,通过最小化均方误差,来进行聚类分析. 因此,K均值实际上是一个最 ...
随机推荐
- js 对象转&拼接
function pars(param, key, encode) { if (param == null) return ''; var arr = []; var t = typeof (para ...
- mysql 表分区技术
表分区,是指根据一定规则,将数据库中的一张表分解成多个更小的,容易管理的部分.从逻辑上看,只有一张表,但是底层却是由多个物理分区组成. 表分区有什么好处: a.分区表的数据可以分布在不同的物理设备上, ...
- Spring-Cloud-Ribbon学习笔记(一):入门
简介 Spring Cloud Ribbon是一个基于Http和TCP的客户端负载均衡工具,它是基于Netflix Ribbon实现的.它不像服务注册中心.配置中心.API网关那样独立部署,但是它几乎 ...
- EnumUtil 链表转换工具类
package com.das.common.util; import org.springframework.util.CollectionUtils; import java.lang.refle ...
- 公开的免费WebService接口分享
天气预报Web服务,数据来源于中国气象局 Endpoint Disco WSDL IP地址来源搜索 WEB 服务(是目前最完整的IP地址数据) Endpoint Disco WSDL 随机英文 ...
- node.js用logio实时监控log
http://logio.org/ 1.先装好node.js $ yum install nodejs 2.安装log.io $sudo npm install -g log.io --user &q ...
- css的小知识4
---恢复内容开始--- 一.单位 1.px就是一个基本单位 像素 2.em也是一个单位 用父级元素的字体大小乘以em前面的数字.如果父级没有就继承上一个父级直到body,如果bod ...
- INFO Dispatcher:42 - Unable to find 'struts.multipart.saveDir' property setting. Defaulting to javax.servlet.context.tempdir
INFO Dispatcher:42 - Unable to find 'struts.multipart.saveDir' property setting. Defaulting to javax ...
- /编写一个函数,要求从给定的向量A中删除元素值在x到y之间的所有元素(向量要求各个元素之间不能有间断), 函数原型为int del(int A ,int n , int x , int y),其中n为输入向量的维数,返回值为删除元素后的维数
/** * @author:(LiberHome) * @date:Created in 2019/2/28 19:39 * @description: * @version:$ */ /* 编写一个 ...
- pytorch--nn.Sequential学习
nn.SequentialA sequential container. Modules will be added to it in the order they are passed in the ...