Oracle同义词、索引、分区
同义词:是现有对象的一个别名
- 简化SQL语句
- 隐藏对象的名称和所有者
- 提供对对象的公共访问
同义词共有两种类型
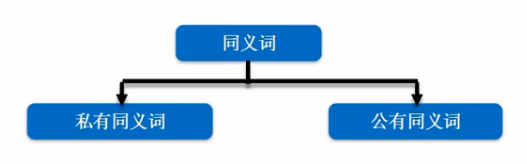
- 私有同义词只能在其模式内访问,且不能与当前模式的对象同名
- 公有同义词可被所有的数据库用户访问

Oracle同义词使用注意事项
- 使用同义词前,要获得同义词对应对象的访问权限
- 同名情况
- 对象与私有同义词不能同名
- 对象与共有同义词同名时,数据库优先选择对象作为目标
- 私有同义词与共有同义词同名时,数据库优先选择私有同义词作为目标
/*
===========================================================
| 将访问员工表的权限授予A_oe用户
============================================================
*/
GRANT SELECT ON employee TO A_oe; --以A_oe用户登录
SELECT * FROM A_hr.employee; --是否有更好的解决方案?
/*
===========================================================
| 在订单表中,只允许当前员工查看自己的订单记录
============================================================
*/
--当前用户A_oe
--获得create view权限 CREATE OR REPLACE VIEW v_myOrders
AS
SELECT *
FROM orders
WHERE sales_rep_id=(SELECT empno
FROM employee
WHERE ename=(SELECT USER FROM dual)); SELECT * FROM v_myOrders;
/*
===========================================================
| 在员工表中,普通职员只允许看姓名、部门列
============================================================
*/
--当前用户A_hr
CREATE OR REPLACE VIEW v_employee
AS
SELECT empno,ename,e.deptno,dname
FROM employee e INNER JOIN dept d
ON e.deptno=d.deptno;
/*
===========================================================
| 创建私有同义词
============================================================
*/
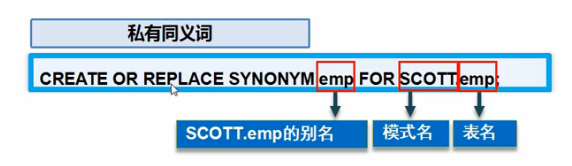
CREATE OR REPLACE SYNONYM emp FOR employee;
/*
===========================================================
| 创建公有同义词
============================================================
*/
CREATE PUBLIC SYNONYM employee FOR A_hr.employee; GRANT SELECT ON employee TO A_oe;
----以A_oe用户登录
--SELECT * FROM A_hr.employee;
SELECT * FROM employee;
/*
===========================================================
| 删除同义词
============================================================
*/
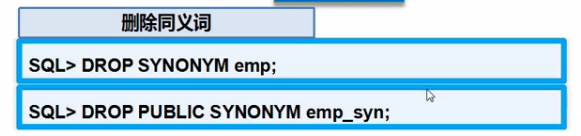
DROP SYNONYM emp;
DROP PUBLIC SYNONYM employee;
/*
===========================================================
| 其他用户都可以访问A_hr用户下的employee表
============================================================
*/
GRANT SELECT ON A_hr.employee TO public;
CREATE PUBLIC SYNONYM employee FOR A_hr.employee;
--以其他用户登录
SELECT * FROM employee;
索引
- 索引是与表关联的可选结构,一种快速访问数据的途径
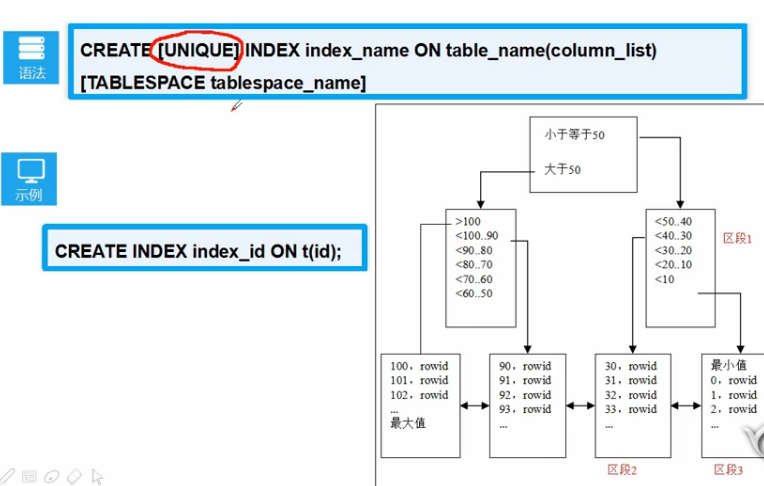
- 索引分类

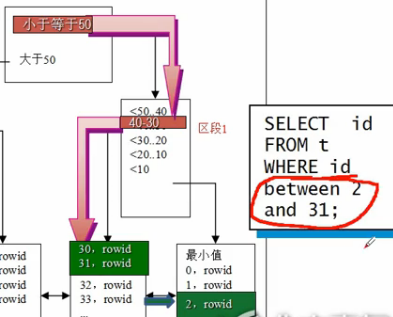
1.B树索引:标准索引,默认是为非唯一索引
1.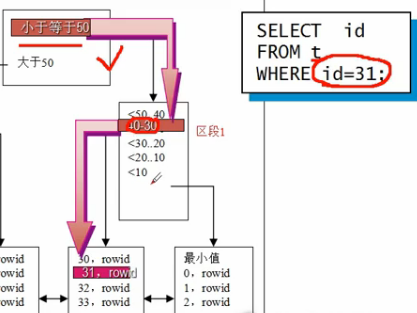 2.
2.
--创建B树索引
CREATE INDEX idx_emp_department
ON employee(deptno);
2.反向键索引:通常建立在值连续增长的列上
与常规B树索引相反,反向键索引在保持列顺序的同时反转索引列的字节

/*
===========================================================
| 为employee表创建索引
============================================================
*/
-- 主键列创建反向键索引
CREATE UNIQUE INDEX idx_empno ON employee(empno) REVERSE; ALTER TABLE employee
ADD CONSTRAINT PK_empno
PRIMARY KEY(empno) USING INDEX ix_empno;
3.位图索引:适用于低基数列
使用bitmap数组进行存储

--创建位图索引
CREATE BITMAP INDEX idx_emp_job
ON employee(job);
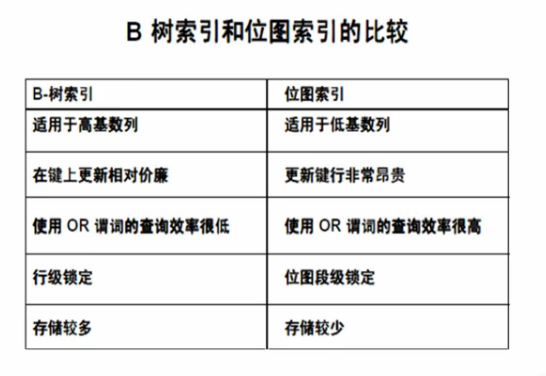
索引管理

- 将正常索引修改成反向键索引:加上PEBUILD NOREVERSE;
- 将反向键索引修改成正常索引:加上PEBUILD REVERSE;
- 正常情况下,一般用ALTER INDEX index_reverse_empno REBUILD;
--创建组合索引
CREATE INDEX idx_emp_name
ON employee(last_name,first_name);
/*
===========================================================
| 主键列创建反向键索引
============================================================
*/
CREATE UNIQUE INDEX idx_empno ON employee(empno) REVERSE; ALTER TABLE employee ADD CONSTRAINT PK_empno PRIMARY KEY(empno) USING INDEX idx_empno; select * FROM employee WHERE empno=7900;
- 频繁搜索、排序、分组的列可以作为索引
- 经常用作连接的列(主键、外键)可作为索引
- 将索引放在一个单独的表空间中
- 使用NOLOGGING子句可减少日志信息
- 定期重建索引
- 仅包含几个不同值的列建议使用位图索引
- 不要在仅包含几行的表中创建索引
何时删除索引?
(1)应用程序不再需要索引
(2)执行批量加载前
(3)索引已损坏
何时重建索引?
(1)表迁移至新表空间后
(2)索引中已包含很多已删除项
(3)需将现有的正常索引转换成反向键索引
分区表
- 允许用户将一个表分成多个分区
- 用户可以执行查询,只访问表中的特定分区
- 将不同的分区存储在不同的磁盘,提高访问性能和安全性
- 可以独立地备份和恢复每个分区
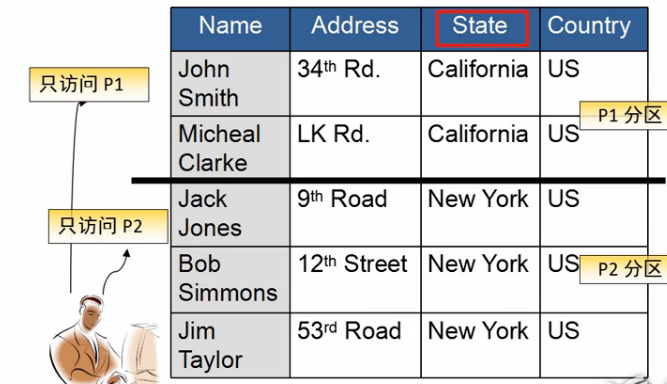
范围分区:以表中的一个列或一组列的值的范围分区

间隔分区:实现范围分区的自动化(在11g才出现的)

- INTERVAL代表“间隔”,按照后面括号中的低谷已间隔添加分区
- NUMTOYMINTERVAL(n,'interval_unit')函数
- 将n转换成interval_unit所指定的值
- inter_unit可以为:YEAR,MONTH
- 表分区允许将一个表划分成几部分,以改善大型应用系统的性能
- 表分区对用户是透明的,即应用程序可以不知道表已被分区
1.创建范围分区
/*
===========================================================
| 创建范围分区表
============================================================
*/
CREATE TABLE sales_range1
(sales_id NUMBER NOT NULL,
product_id VARCHAR2(5),
sales_date DATE,
sales_cost NUMBER(10),
areacode VARCHAR2(5)
)
partition by range(sales_date)
(partition part1 values less than (to_date('2011/01/01','yyyy/mm/dd')) TABLESPACE tp_orders,
partition part2 values less than (to_date('2012/01/01','yyyy/mm/dd')),
partition part3 values less than (to_date('2013/01/01','yyyy/mm/dd')),
partition part4 values less than (to_date('2014/01/01','yyyy/mm/dd'))
);
--查询分区情况
SELECT table_name,partition_name
FROM user_tab_partitions
WHERE table_name=UPPER('sales_range1');
--插入数据
insert into sales_range1 values (1000,'p1',to_date('2011-01-01','yyyy-mm-dd'),1000,'A1');
--查询数据 select * from sales_range1 PARTITION (part2);
2.分区表的管理
/*
===========================================================
| 分区表的管理
============================================================
*/ --查询分区情况
SELECT table_name,partition_name
FROM user_tab_partitions
WHERE table_name=UPPER('sales_range1'); SELECT * FROM sales_range1 PARTITION (part1);--11前
SELECT * FROM sales_range1 PARTITION (part2);--12前
SELECT * FROM sales_range1 PARTITION (part3);--13前
SELECT * FROM sales_range1 PARTITION (part4);--14前
--插入数据
INSERT INTO sales_range1 VALUES (2000,'p1',to_date('2014-01-01','yyyy-mm-dd'),1000,'A1');
--添加分区
ALTER TABLE sales_range1 ADD PARTITION part5 VALUES LESS THAN (to_date('2015-01-01','yyyy-mm-dd'));
ALTER TABLE sales_range1 ADD PARTITION part6 VALUES LESS THAN (MAXVALUE); SELECT * FROM sales_range1 PARTITION (part5);--15前
--删除分区
ALTER TABLE sales_range1 DROP PARTITION part5 SELECT * FROM sales_range1 WHERE sales_id=2000;
--移动分区
ALTER TABLE sales_range1 MOVE PARTITION part1 TABLESPACE tp_sales_bak;
--表空间只读后测试插入数据,失败。
INSERT INTO sales_range1 VALUES (3000,'p1',to_date('2009-01-01','yyyy-mm-dd'),1000,'A1');
--表空间
CREATE TABLESPACE tp_sales_bak
DATAFILE 'd:\data\tp_sales_bak.dbf' SIZE 100M;
ALTER USER A_oe QUOTA UNLIMITED ON tp_sales_bak;
--移动完表空间后将表空间设置为只读
ALTER TABLESPACE tp_sales_bak READ ONLY; ALTER TABLESPACE tp_sales_bak READ WRITE;
3.间隔分区表
/*
===========================================================
| 间隔分区表
============================================================
*/
CREATE TABLE sales_interval1
(sales_id NUMBER NOT NULL,
product_id VARCHAR2(5),
sales_date DATE,
sales_cost NUMBER(10),
areacode VARCHAR2(5)
)
PARTITION BY RANGE(sales_date)
INTERVAL(NUMTOYMINTERVAL(1,'YEAR'))
(PARTITION part1 VALUES LESS THAN (to_date('2011/01/01','yyyy/mm/dd')))
--查询分区情况
SELECT table_name,partition_name,tablespace_name
FROM user_tab_partitions
WHERE table_name=UPPER('sales_interval1'); INSERT INTO sales_interval1 VALUES (1000,'p1',SYSDATE,2000,'A2'); SELECT * FROM sales_interval1 PARTITION (SYS_P142);
--现有表创建新表
CREATE TABLE sales_interval2
PARTITION BY RANGE(sales_date)
INTERVAL(NUMTOYMINTERVAL(1,'YEAR'))
(PARTITION part1 VALUES LESS THAN (to_date('2011/01/01','yyyy/mm/dd')))
AS SELECT * FROM sales;
4.现有表创建范围分区表
/*
===========================================================
| 现有表创建范围分区表
============================================================
*/ CREATE TABLE sales
(sales_id NUMBER NOT NULL,
product_id VARCHAR2(5),
sales_date DATE,
sales_cost NUMBER(10),
areacode VARCHAR2(5)
) CREATE TABLE sales_range2
partition by range(sales_date)
(partition part1 values less than (to_date('2011/01/01','yyyy/mm/dd')),
partition part2 values less than (to_date('2012/01/01','yyyy/mm/dd')),
partition part3 values less than (to_date('2013/01/01','yyyy/mm/dd')),
partition part4 values less than (to_date('2014/01/01','yyyy/mm/dd'))
)
as select * from sales;
--问题1 2014/01/01的数据落在哪个分区?
--问题2 2015年的数据落在哪个分区?
--2个解决办法:一个是添加分区;一个是创建间隔分区
Oracle同义词、索引、分区的更多相关文章
- Oracle用户权限授权以及索引、同义词、分区
本文为原创,如需转载,请标明出处 http://www.cnblogs.com/gudu1/p/7601765.html ---- 用户权限 1.创建表空间 (创建用户之前需要创建表空间和临时表空间, ...
- 深入学习Oracle分区表及分区索引
关于分区表和分区索引(About Partitioned Tables and Indexes)对于10gR2而言,基本上可以分成几类: • Range(范围)分区 • Has ...
- 转:深入学习Oracle分区表及分区索引
转自:http://database.ctocio.com.cn/tips/286/8104286.shtml 关于分区表和分区索引(About Partitioned Tables and Inde ...
- oracle 分区表和分区索引
很复杂的样子,自己都没有看完,以备后用 http://hi.baidu.com/jsshm/item/cbfed8491d3863ee1e19bc3e ORACLE分区表.分区索引ORACLE对于分区 ...
- ORACLE分区表、分区索引详解
详见:http://blog.yemou.net/article/query/info/tytfjhfascvhzxcyt160 ORACLE分区表.分区索引ORACLE对于分区表方式其实就是将表分段 ...
- 【三思笔记】 全面学习Oracle分区表及分区索引
[三思笔记]全面学习Oracle分区表及分区索引 2008-04-15 关于分区表和分区索引(About PartitionedTables and Indexes) 对于 10gR2 而言,基本上可 ...
- 简单ORACLE分区表、分区索引
前一段听说CSDN.COM里面很多好东西,同事建议看看合适自己也可以写一写,呵呵,今天第一次开通博客,随便写点东西,就以第一印象分区表简单写第一个吧. ORACLE对于分区表方式其实就是将表分段存储, ...
- oracle分区表和分区索引概述
㈠ 分区表技术概述 ⑴ Range 分区 ① 例子 create table t (...列定义...) ...
- 吴裕雄--天生自然ORACLE数据库学习笔记:表分区与索引分区
create table ware_retail_part --创建一个描述商品零售的数据表 ( id integer primary key,--销售编号 retail_date date,--销售 ...
随机推荐
- framwork maven的配置及使用
maven的配置及使用 一.什么是maven: 我们在开发项目的过程中,会使用一些开源框架.第三方的工具等等,这些都是以jar包的方式被项目所引用,并且有些jar包还会依赖其他的jar包,我们同样需要 ...
- dubbo心跳机制 (2)
此文已由作者赵计刚授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 来看一下HeaderExchangeServer.this.getChannels(): 1 p ...
- java泛型与object的比较
在Java SE 1.5之前,没有泛型的情况的下,通过对类型Object的引用来实现参数的“任意化”,“任意化”带来的缺点是要做显式的强制类型转换,而这种转换是要求开发者对实际参数类型可以预知的情况下 ...
- 利用Angular2的Observables实现交互控制
在Angular1.x中,我们使用Promise来处理各种异步.但是在angular2中,使用的是Reactive Extensions (Rx)的Observable.对于Promise和Obser ...
- SQL事务对并发处理的支持
前言 继上次技术分享后,学到了关于mysql事务的许多新知识,感觉还是蛮有收获的.后来反过来想想,这些东西其实我们都接触过,最起码在自学考试的数据库系统原理那本书里面对事务的讲解,在里面就提到了事务的 ...
- 【转】32位plsql连接64位oracle
源地址:http://www.cnblogs.com/ymj126/p/3712727.html
- oracle数据结构
数据类型: 1 字符数据:CHAR VARCHAR NCHAR NVARCHAR2 LONG CLOB NCLOB 2 数字数据类型:NUMBER 唯一用来存储数字型的类型 3 日期数据类型: 4 ...
- LCA 【bzoj 4281】 [ONTAK2015]Związek Harcerstwa Bajtockiego
[bzoj 4281] [ONTAK2015]Związek Harcerstwa Bajtockiego Description 给定一棵有n个点的无根树,相邻的点之间的距离为1,一开始你位于m点. ...
- getsockname()和getpeername()
对于server端: 以端口为通配符方式bind:对于服务器,bind(0,ip),则调用bind函数之后,就可以调用getsockname获取服务器得到的本地端口号 以ip地址为通配地址bind,只 ...
- GIS有关GP服务的发布和调用
打印服务范例:http://blog.csdn.net/jingxinwjb/article/details/51906464 1.通过Modelbuilder新建工具.(注意:假如工具输出两个以上的 ...