【python】-- 模块、os、sys、time/datetime、random、logging、re
模块
模块,用一堆代码实现了某个功能的代码集合。
类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合。而对于一个复杂的功能来,可能需要多个函数才能完成(函数又可以在不同的.py文件中),n个 .py 文件组成的代码集合就称为模块。
如:os 是系统相关的模块;time是时间操作相关的模块
模块分为三种:
- 自定义模块
- 内置模块
- 开源模块
1、导入模块:
Python之所以应用越来越广泛,在一定程度上也依赖于其为程序员提供了大量的模块以供使用,如果想要使用模块,则需要导入。导入模块有一下几种方法:
import module
from module.xx.xx import xx
from module.xx.xx import xx as rename
from module.xx.xx import *
- 导入一个py文件,解释器解释该py文件
- 导入一个包,解释器解释该包下的 __init__.py 文件
导入模块时是根据sys.path那个路径作为基准来进行的,代码如下:
import sys
print sys.path 结果:
['/Users/wupeiqi/PycharmProjects/calculator/p1/pp1', '/usr/local/lib/python2.7/site-packages/setuptools-15.2-py2.7.egg', '/usr/local/lib/python2.7/site-packages/distribute-0.6.28-py2.7.egg', '/usr/local/lib/python2.7/site-packages/MySQL_python-1.2.4b4-py2.7-macosx-10.10-x86_64.egg', '/usr/local/lib/python2.7/site-packages/xlutils-1.7.1-py2.7.egg', '/usr/local/lib/python2.7/site-packages/xlwt-1.0.0-py2.7.egg', '/usr/local/lib/python2.7/site-packages/xlrd-0.9.3-py2.7.egg', '/usr/local/lib/python2.7/site-packages/tornado-4.1-py2.7-macosx-10.10-x86_64.egg', '/usr/local/lib/python2.7/site-packages/backports.ssl_match_hostname-3.4.0.2-py2.7.egg', '/usr/local/lib/python2.7/site-packages/certifi-2015.4.28-py2.7.egg', '/usr/local/lib/python2.7/site-packages/pyOpenSSL-0.15.1-py2.7.egg', '/usr/local/lib/python2.7/site-packages/six-1.9.0-py2.7.egg', '/usr/local/lib/python2.7/site-packages/cryptography-0.9.1-py2.7-macosx-10.10-x86_64.egg', '/usr/local/lib/python2.7/site-packages/cffi-1.1.1-py2.7-macosx-10.10-x86_64.egg', '/usr/local/lib/python2.7/site-packages/ipaddress-1.0.7-py2.7.egg', '/usr/local/lib/python2.7/site-packages/enum34-1.0.4-py2.7.egg', '/usr/local/lib/python2.7/site-packages/pyasn1-0.1.7-py2.7.egg', '/usr/local/lib/python2.7/site-packages/idna-2.0-py2.7.egg', '/usr/local/lib/python2.7/site-packages/pycparser-2.13-py2.7.egg', '/usr/local/lib/python2.7/site-packages/Django-1.7.8-py2.7.egg', '/usr/local/lib/python2.7/site-packages/paramiko-1.10.1-py2.7.egg', '/usr/local/lib/python2.7/site-packages/gevent-1.0.2-py2.7-macosx-10.10-x86_64.egg', '/usr/local/lib/python2.7/site-packages/greenlet-0.4.7-py2.7-macosx-10.10-x86_64.egg', '/Users/wupeiqi/PycharmProjects/calculator', '/usr/local/Cellar/python/2.7.9/Frameworks/Python.framework/Versions/2.7/lib/python27.zip', '/usr/local/Cellar/python/2.7.9/Frameworks/Python.framework/Versions/2.7/lib/python2.7', '/usr/local/Cellar/python/2.7.9/Frameworks/Python.framework/Versions/2.7/lib/python2.7/plat-darwin', '/usr/local/Cellar/python/2.7.9/Frameworks/Python.framework/Versions/2.7/lib/python2.7/plat-mac', '/usr/local/Cellar/python/2.7.9/Frameworks/Python.framework/Versions/2.7/lib/python2.7/plat-mac/lib-scriptpackages', '/usr/local/Cellar/python/2.7.9/Frameworks/Python.framework/Versions/2.7/lib/python2.7/lib-tk', '/usr/local/Cellar/python/2.7.9/Frameworks/Python.framework/Versions/2.7/lib/python2.7/lib-old', '/usr/local/Cellar/python/2.7.9/Frameworks/Python.framework/Versions/2.7/lib/python2.7/lib-dynload', '/usr/local/lib/python2.7/site-packages', '/Library/Python/2.7/site-packages']
如果sys.path路径列表没有想要的路径,可以通过 sys.path.append('路径') 添加,如:
import sys
import os pre_path = os.path.abspath('../')
sys.path.append(pre_path)
2、动态导入模块
前置条件:需要导入的模块的目录结构
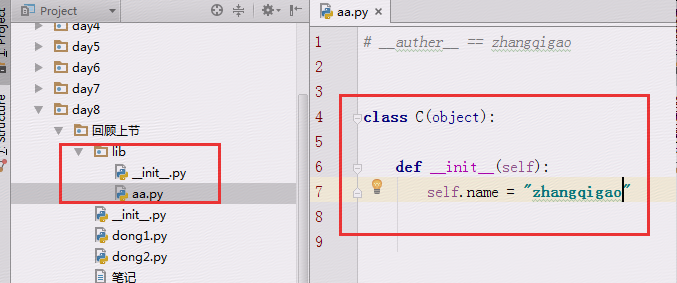
2.1、__import__方式
说明:这种方式只能到第一层级别
mod = __import__("lib.aa")
print(mod) #打印模块信息
c_instance = getattr(mod.aa,"C")#或者写成c_instance = mod.aa.C()
c_obj = c_instance()
print(c_obj.name)
#输出
<module 'lib' from 'D:\\PycharmProjects\\pyhomework\\day8\\回顾上节\\lib\\__init__.py'> #只导入lib级别
zhangqigao
2.2 importlib方式
说明:这种方式比较好,也是官方推荐的,它能助学导入到最后一个层级,就是你导入的哪个模块就到哪个层级
import importlib
mod = importlib.import_module("lib.aa")
print(mod) #打印导入模块信息
c_instance = mod.C #又可写成 c_instance = getattr(mod,"C")
c_object = c_instance()
print(c_object.name) #输出
<module 'lib.aa' from 'D:\\PycharmProjects\\pyhomework\\day8\\回顾上节\\lib\\aa.py'>#到aa.py级别
os
python编程时,经常和文件、目录打交道,这是就离不了os模块。os模块包含普遍的操作系统功能,与具体的平台无关
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
更多os详情:点击
sys
此模块可供访问由解释器使用或维护的变量和与解释器进行交互的函数
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit(0)
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
sys.stdout.write('please:')
val = sys.stdin.readline()[:-1]
更多sys详情:点击
time
时间相关的操作,时间有三种表示方式:
- 时间戳 1970年1月1日之后的秒,即:time.time()
- 格式化的字符串 2014-11-11 11:11, 即:time.strftime('%Y-%m-%d')
- 结构化时间 元组包含了:年、日、星期等... time.struct_time 即:time.localtime()
1、time模块主要函数演示:
1、time.process_time() 功能:测量处理器的运算时间,但是不包括sleep时间,因为sleep只是把你的程序挂起,不太稳定。 >>> import time
>>> time.process_time()
0.8736056 ########################################
2、time.altzone() 功能:返回与utc的时间的时间差,以秒计算 >>> import time
>>> time.altzone
-32400
>>> time.altzone/3600
-9.0
注:感觉有点不太准确,为什么是-9时呢?无解,先忘记它吧! ########################################
3、time.asctime() 功能:返回时间格式:'Thu Mar 30 16:47:39 2017'(星期 月 日 时间 年) >>> import time
>>> time.asctime()
'Thu Mar 30 16:47:39 2017' #返回 星期 月 日 时间 年 ########################################
4、time.localtime() 功能:返回本地时间的struct _time的格式的对象,也可以把时间戳转换成成struct _time的格式的对象 >>> import time
>>> t = time.localtime() #返回本地时间的对象,通过对象获取对应的年月日等信息
>>> t
time.struct_time(tm_year=2017, tm_mon=3, tm_mday=30, tm_hour=16, tm_min=52, tm_sec=10, tm_wday=3, tm_yday=89, tm_isdst=0)
>>> t.tm_hour # 获取小时数
16 ########################################
5、time.time() 功能:返回当前时间的时间戳(1970年纪元后经过的浮点秒数) >>> import time
#返回当前时间的时间戳
>>> time.time()
1490864724.061428
#跟localtime()结合起来返回当前时间对象
>>> time.localtime(time.time())
time.struct_time(tm_year=2017, tm_mon=3, tm_mday=30, tm_hour=17, tm_min=5, tm_sec=38, tm_wday=3, tm_yday=89, tm_isdst=0)
# 给当前时间加上3个小时,注意了,localtime中只能介绍秒级别的,所以是3600*3表示3个小时
>>> time.localtime(time.time() + 3600*3)
time.struct_time(tm_year=2017, tm_mon=3, tm_mday=30, tm_hour=20, tm_min=5, tm_sec=53, tm_wday=3, tm_yday=89, tm_isdst=0)
#跟asctime结合起来用 生成当前时间格式
>>> time.asctime( time.localtime( time.time() ) )
'Thu Mar 30 17:06:26 2017'
注:为啥是1970年呢?因为1970年1月1日被当做unix操作系统的诞生元年。 ########################################
6.time.gmtime() 功能:返回当前utc时间(伦敦时间) >>> import time
>>> time.gmtime() #返回utc的时间struct time 格式
time.struct_time(tm_year=2017, tm_mon=3, tm_mday=30, tm_hour=9, tm_min=25, tm_sec=13, tm_wday=3, tm_yday=89, tm_isdst=0)
>>> time.asctime(time.gmtime())
'Thu Mar 30 09:26:14 2017' #伦敦时间
>>> time.asctime(time.localtime())
'Thu Mar 30 17:26:14 2017' #北京时间,两者正好相差8个小时
注:没啥用处?知道就行。 ########################################
7、time.strptime() 功能:把时间格式的字符串转成struct_time格式的时间对象 >>> import time
>>> time.strptime("2017-03-30 17:30","%Y-%m-%d %H:%M")
#转换为struct_time格式的时间对象
time.struct_time(tm_year=2017, tm_mon=3, tm_mday=30, tm_hour=17, tm_min=30, tm_sec=0, tm_wday=3, tm_yday=89, tm_isdst=-1) ########################################
8、time.mktime() 功能:把struct_time时间对象转成时间戳 >>> import time
#生成struct_time时间对象
>>> t = time.strptime("2017-03-30 17:30","%Y-%m-%d %H:%M")
#时间对象转成时间戳
>>> t2_stamp = time.mktime(t)
>>> t2_stamp
1490866200.0 ########################################
9、time.strftime() 功能:struct_time时间对象转换成时间字符串 >>> import time
#生成struct_time时间对象
>>> t = time.strptime("2017-03-30 17:30","%Y-%m-%d %H:%M")
#把时间对象转换成时间格式的字符串
>>> m = time.strftime("%Y-%m-%d-%H-%M.log",t)
>>> m
'2017-03-30-17-30.log'
#不传入时间对象,默认是当前时间
>>> m = time.strftime("%Y-%m-%d-%H-%M.log")
>>> m
'2017-03-30-17-56.log'
当然,中间如果需要用时间戳转换的话,你还可以这样,代码如下:
>>> import time
#生成struct_time时间对象
>>> t = time.strptime("2017-03-30 17:30","%Y-%m-%d %H:%M")
#把时间对象转成时间戳
>>> t2_stamp = time.mktime(t)
#再通过localtime函数把时间戳转成struct_time时间对象
>>> t3 = time.localtime(t2_stamp)
#把时间对象转换成时间格式的字符串
>>> m = time.strftime("%Y-%m-%d-%H-%M.log",t)
>>> m
'2017-03-30-17-30.log'
2、时间格式转换关系图
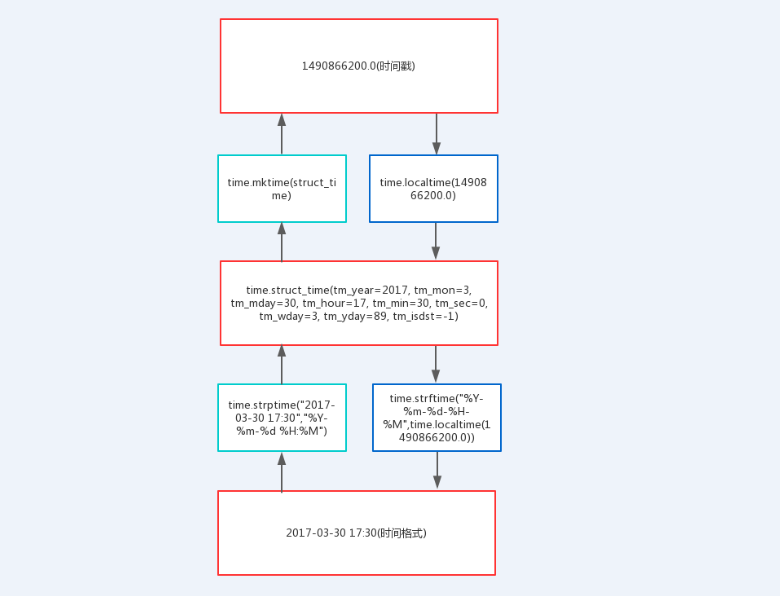
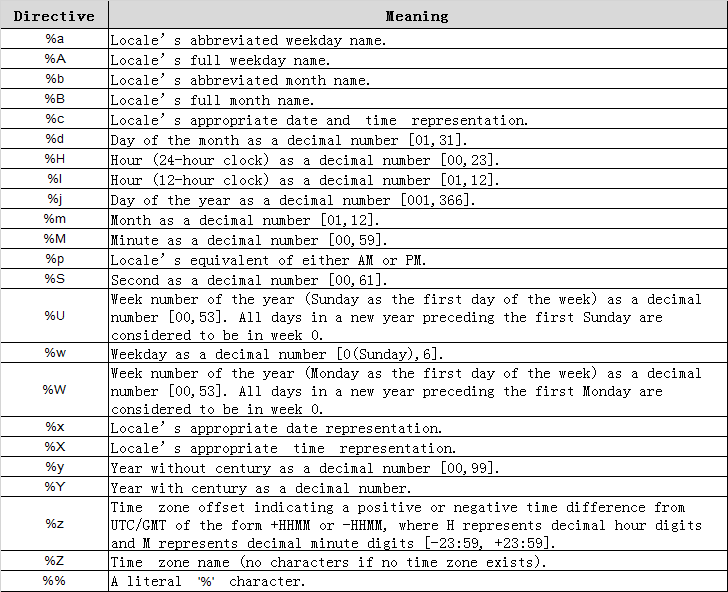
3、转换表格
datetime
datatime模块重新封装了time模块,提供更多接口,提供的类有:date,time,datetime,timedelta,tzinfo
1、datetime.datetime.now() 功能:返回当前时间,格式如:2016-08-19 12:47:03.941925 >>> import datetime
>>> print(datetime.datetime.now())
2017-03-31 10:22:09.819373 ######################################
2、datetime.date.fromtimestamp() 功能:时间戳转换为日期格式 >>> import datetime,time
>>> t = datetime.date.fromtimestamp(time.time())
>>> print(t) #把当天日期的时间戳转换为当天日期
2017-03-31 ########################################
3、datetime.timedelta() 功能:对某个时间的加减 >>> import datetime
#当前时间加3天
>>> t1 = datetime.datetime.now() + datetime.timedelta(days=3)
>>> print(t1)
2017-04-03 10:42:50.714910
#当前时间减3天
>>> t1 = datetime.datetime.now() - datetime.timedelta(days=3)
>>> print(t1)
2017-03-28 10:43:17.260111
#当前时间减3天
>>> t1 = datetime.datetime.now() + datetime.timedelta(days=-3)
>>> print(t1)
2017-03-28 10:43:35.758742
#当前时间加3个小时
>>> t1 = datetime.datetime.now() + datetime.timedelta(hours=3)
>>> print(t1)
2017-03-31 13:44:24.805354
#当前时间加30分钟
>>> t1 = datetime.datetime.now() + datetime.timedelta(minutes=30)
>>> print(t1)
2017-03-31 11:14:55.990195 ####################################
4、时间替换 >>> import datetime
>>> c_time = datetime.datetime.now()
#当前时间输出
>>> print(c_time)
2017-03-31 10:47:22.682289
#时间替换
>>> update_c_time = c_time.replace(minute=3,hour=2)
#替换后的时间输出
>>> print(update_c_time)
2017-03-31 02:03:22.682289 #######################################
5、日期提取
time = datetime.datetime.now()
#提前周几
week_time = date_conversion(time.weekday())
#提取当前时间
date_time = time.date()
#提取当前日期并且格式化
time_time = time.time().strftime("%H:%M:%S")
random
我们经常会使用一些随机数,或者需要写一些随机数的代码,random就能很好的解决这些问题。
random:
关于数字的一些随机操作函数:
1、random.random() 功能:随机返回一个小数 >>> import random
>>> random.random()
0.14090974546903268 #随机返回一个小数 ########################################
2、random.randint(a,b) 功能:随机返回a到b之间任意一个数,包括b >>> import random
>>> random.randint(1,5)
5 #可以返回5
>>> random.randint(1,5)
2 ########################################
3、random.randrange(start, stop=None, step=1) 功能:随机返回start到stop,但是不包括stop值 >>> import random
>>> random.randrange(5) #不能随机返回5
4
>>> random.randrange(5)
1 ########################################
4、random.sample(population, k) 功能:从population中随机获取k个值,以列表的形式返回 >>> import random
>>> random.sample(range(10),3) #从0-9返回3个随机数
[3, 1, 0]
>>> random.sample('abcdefghi',3) #从'abcdefghi'中返回3个字符
['a', 'h', 'b']
string:
关于字符串一些随机操作函数:
1、string.ascii_letters 功能:返回大小写字母的字符串
>>> import string
>>> string.ascii_letters
'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ' #返回大小写字母字符串 ########################################
2、string.ascii_lowercase 功能:返回小写字母的字符串
>>> import string
>>> string.ascii_lowercase
'abcdefghijklmnopqrstuvwxyz' #返回小写字母的字符串 ######################################
3、string.ascii_uppercase 功能:返回大写字母的字符串 >>> import string
>>> string.ascii_uppercase
'ABCDEFGHIJKLMNOPQRSTUVWXYZ' #返回大写字母的字符串 #######################################
4、string.digits 功能:返回0-9数字的字符串 >>> import string
>>> string.digits
'' #返回0-9数字的字符串 #######################################
5、string.punctuation 功能:返回所有特殊字符,并以字符串形式返回 >>> import string
>>> string.punctuation
'!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~' #返回所有特殊字符,并以字符串的形式返回
验证码小例子:
>>> import random,string
>>> str_source = string.ascii_lowercase + string.digits #大写字母字符和0-9数字字符串拼接
>>> random.sample(str_source,6) #取6个随机字符
['f', '', 'a', 'm', 'j', 'h']
>>> ''.join(random.sample(str_source,6)) #生成一个随机数字符串
'f84bsj'
import random
checkcode = ''
for i in range(4):
current = random.randrange(0,4)
if current != i: #如果当前的loop i不等于随机数,就取出65-90中的随机字符
temp = chr(random.randint(65,90))
else:
temp = random.randint(0,9)
checkcode += str(temp)
print(checkcode)
logging
程序都有记录日志的需求,并且日志中包含的信息即有正常的程序访问日志,还可能有错误,警告等信息输出,python的logging模块提供了标准的日志接口,你可以通过它存储各种格式的日志,logging的日志可以分为debug,info,warning,error和critical 5个级别
一、日志等级
| Level | When it’s used |
|---|---|
DEBUG |
Detailed information, typically of interest only when diagnosing problems. |
INFO |
Confirmation that things are working as expected. |
WARNING |
An indication that something unexpected happened, or indicative of some problem in the near future (e.g. ‘disk space low’). The software is still working as expected. |
ERROR |
Due to a more serious problem, the software has not been able to perform some function. |
CRITICAL |
A serious error, indicating that the program itself may be unable to continue running. |
日志级别有五个,分别是:debug,info,warning,error和critical,其中debug级别最低,critical级别最高,级别越低,打印的日志等级越多
二、format的日志格式
|
%(name)s |
Logger的名字 |
|
%(levelno)s |
数字形式的日志级别 |
|
%(levelname)s |
文本形式的日志级别 |
|
%(pathname)s |
调用日志输出函数的模块的完整路径名,可能没有 |
|
%(filename)s |
调用日志输出函数的模块的文件名 |
|
%(module)s |
调用日志输出函数的模块名 |
|
%(funcName)s |
调用日志输出函数的函数名 |
|
%(lineno)d |
调用日志输出函数的语句所在的代码行 |
|
%(created)f |
当前时间,用UNIX标准的表示时间的浮 点数表示 |
|
%(relativeCreated)d |
输出日志信息时的,自Logger创建以 来的毫秒数 |
|
%(asctime)s |
字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 |
|
%(thread)d |
线程ID。可能没有 |
|
%(threadName)s |
线程名。可能没有 |
|
%(process)d |
进程ID。可能没有 |
|
%(message)s |
用户输出的消息 |
日志写入文件+format日子格式:
import logging logging.basicConfig(filename="catalina.log",
level=logging.INFO,
format='%(asctime)s %(module)s:%(levelname)s %(message)s', #格式请见第5点内容
datefmt='%m/%d/%Y %H:%M:%S %p') #需要加上format和datefmt #----日志内容-----
logging.debug("logging debug")
logging.info("logging info")
logging.warning("logging warning") #文件输出
04/11/2017 14:20:22 PM logging_mod:INFO logging info
04/11/2017 14:20:22 PM logging_mod:WARNING logging warning
注:level=loggin.INFO意思是,把日志纪录级别设置为INFO,也就是说,只有比日志是INFO或比INFO级别更高的日志才会被纪录到文件里,所以debug日志没有记录,如果想记录,则级别设置成debug也就是level=loggin.DEBUG
三、日志输出语句释义
1、简介
python使用logging模块记录日志涉及的四个主要类:
①logger:提供了应用程序可以直接使用的接口。
②handler:将(logger创建的)日志记录发送到合适的目的输出。
③filter:提供了细度设备来决定输出哪条日志记录。
④formatter:决定日志记录的最终输出格式。
2、logger
每个程序在输出信息之前都要获得一个Logger。Logger通常对应了程序的模块名,比如聊天工具的图形界面模块可以这样获得它的Logger:
LOG=logging.getLogger(”chat.gui”)
而核心模块可以这样:
LOG=logging.getLogger(”chat.kernel”)
Logger.setLevel(lel):指定最低的日志级别,低于lel的级别将被忽略。debug是最低的内置级别,critical为最高
Logger.addFilter(filt)、Logger.removeFilter(filt):添加或删除指定的filter
Logger.addHandler(hdlr)、Logger.removeHandler(hdlr):增加或删除指定的handler
Logger.debug()、Logger.info()、Logger.warning()、Logger.error()、Logger.critical():可以设置的日志级别
3、hander
handler对象负责发送相关的信息到指定目的地。Python的日志系统有多种Handler可以使用。有些Handler可以把信息输出到控制台,有些Logger可以把信息输出到文件,还有些 Handler可以把信息发送到网络上。如果觉得不够用,还可以编写自己的Handler。可以②Handler.setFormatter()通过addHandler()方法添加多个多handler 。
①Handler.setLevel(lel) 指定被处理的信息级别,低于lel级别的信息将被忽略。
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)
②Handler.setFormatter() 给这个handler选择一个格式
ch_formatter = logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s") #生成格式
ch.setFormatter(ch_formatter) #设置格式
③Handler.addFilter(filt)、Handler.removeFilter(filt)
说明:新增或删除一个filter对象
四、handler详解
1、logging.StreamHandler
说明:使用这个Handler可以向类似与sys.stdout或者sys.stderr的任何文件对象(file object)输出信息,也就是屏幕输出。
它的构造函数是:StreamHandler([strm]),其中strm参数是一个文件对象,默认是sys.stderr。
import logging
logger = logging.getLogger("TEST-LOG")
logger.setLevel(logging.DEBUG)
ch = logging.StreamHandler() #创建一个StreamHandler对象
ch.setLevel(logging.DEBUG) #设置输出StreamHandler日志级别
ch_formatter = logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s")
ch.setFormatter(ch_formatter) #设置时间格式
logger.addHandler(ch)
# 'application' code
logger.debug('debug message')
logger.info('info message')
logger.warn('warn message')
logger.error('error message')
logger.critical('critical message')
#输出
2017-04-11 16:42:49,764 - TEST-LOG - DEBUG - debug message
2017-04-11 16:42:49,764 - TEST-LOG - INFO - info message
2017-04-11 16:42:49,764 - TEST-LOG - WARNING - warn message
2017-04-11 16:42:49,765 - TEST-LOG - ERROR - error message
2017-04-11 16:42:49,765 - TEST-LOG - CRITICAL - critical message
2、logging.FileHandler
说明:和StreamHandler类似,用于向一个文件输出日志信息,不过FileHandler会帮你打开这个文件。
它的构造函数是:FileHandler(filename[,mode])。filename是文件名,必须指定一个文件名。mode是文件的打开方式。参见Python内置函数open()的用法。默认是’a',即添加到文件末尾。
import logging #create logging
logger = logging.getLogger("TEST-LOG")
logger.setLevel(logging.DEBUG) fh = logging.FileHandler("debug.log",encoding="utf-8") #日志输出到debug.log文件中
fh.setLevel(logging.INFO) #设置FileHandler日志级别 fh_formatter = logging.Formatter("%(asctime)s %(module)s:%(levelname)s %(message)s") fh.setFormatter(fh_formatter) logger.addHandler(fh) # 'application' code
logger.info('info message')
logger.warn('warn message')
logger.error('error message')
logger.critical('critical message') #输出到文件中
2017-04-11 17:09:50,035 logging_screen_output:INFO info message
2017-04-11 17:09:50,035 logging_screen_output:WARNING warn message
2017-04-11 17:09:50,035 logging_screen_output:ERROR error message
2017-04-11 17:09:50,035 logging_screen_output:CRITICAL critical message
3、logging.handlers.RotatingFileHandler
说明:这个Handler类似于上面的FileHandler,但是它可以管理文件大小。当文件达到一定大小之后,它会自动将当前日志文件改名,然后创建 一个新的同名日志文件继续输出。比如日志文件是chat.log。当chat.log达到指定的大小之后,RotatingFileHandler自动把 文件改名为chat.log.1。不过,如果chat.log.1已经存在,会先把chat.log.1重命名为chat.log.2。。。最后重新创建 chat.log,继续输出日志信息。
它的构造函数是:RotatingFileHandler( filename[, mode[, maxBytes[, backupCount]]]),其中filename和mode两个参数和FileHandler一样。
maxBytes用于指定日志文件的最大文件大小。如果maxBytes为0,意味着日志文件可以无限大,这时上面描述的重命名过程就不会发生。
backupCount用于指定保留的备份文件的个数。比如,如果指定为2,当上面描述的重命名过程发生时,原有的chat.log.2并不会被更名,而是被删除。
mport logging #create logging
logger = logging.getLogger("TEST-LOG")
logger.setLevel(logging.DEBUG) fh = logging.FileHandler("debug.log",encoding="utf-8") #日志输出到debug.log文件中
fh.setLevel(logging.INFO) #设置FileHandler日志级别 fh_formatter = logging.Formatter("%(asctime)s %(module)s:%(levelname)s %(message)s") fh.setFormatter(fh_formatter) logger.addHandler(fh) # 'application' code
logger.info('info message')
logger.warn('warn message')
logger.error('error message')
logger.critical('critical message') #输出到文件中
2017-04-11 17:09:50,035 logging_screen_output:INFO info message
2017-04-11 17:09:50,035 logging_screen_output:WARNING warn message
2017-04-11 17:09:50,035 logging_screen_output:ERROR error message
2017-04-11 17:09:50,035 logging_screen_output:CRITICAL critical message
3、logging.handlers.RotatingFileHandler 说明:这个Handler类似于上面的FileHandler,但是它可以管理文件大小。当文件达到一定大小之后,它会自动将当前日志文件改名,然后创建 一个新的同名日志文件继续输出。比如日志文件是chat.log。当chat.log达到指定的大小之后,RotatingFileHandler自动把 文件改名为chat.log.1。不过,如果chat.log.1已经存在,会先把chat.log.1重命名为chat.log.2。。。最后重新创建 chat.log,继续输出日志信息。 它的构造函数是:RotatingFileHandler( filename[, mode[, maxBytes[, backupCount]]]),其中filename和mode两个参数和FileHandler一样。 maxBytes用于指定日志文件的最大文件大小。如果maxBytes为0,意味着日志文件可以无限大,这时上面描述的重命名过程就不会发生。 backupCount用于指定保留的备份文件的个数。比如,如果指定为2,当上面描述的重命名过程发生时,原有的chat.log.2并不会被更名,而是被删除。 import logging
from logging import handlers #需要导入handlers logger = logging.getLogger(__name__)
log_file = "timelog.log" #按文件大小来分割,10个字节,保留个数是3个
fh = handlers.RotatingFileHandler(filename=log_file,maxBytes=10,backupCount=3)
formatter = logging.Formatter('%(asctime)s %(module)s:%(lineno)d %(message)s')
fh.setFormatter(formatter)
logger.addHandler(fh) logger.warning("test1")
logger.warning("test12")
logger.warning("test13")
logger.warning("test14")
4、logging.handlers.TimedRotatingFileHandler
说明:这个Handler和RotatingFileHandler类似,不过,它没有通过判断文件大小来决定何时重新创建日志文件,而是间隔一定时间就 自动创建新的日志文件。重命名的过程与RotatingFileHandler类似,不过新的文件不是附加数字,而是当前时间。
它的构造函数是:TimedRotatingFileHandler( filename [,when [,interval [,backupCount]]]),其中filename参数和backupCount参数和RotatingFileHandler具有相同的意义。
interval是时间间隔。when参数是一个字符串。表示时间间隔的单位,不区分大小写。它有以下取值:①S:秒②M:分③H:小时④D:天⑤W :每星期(interval==0时代表星期一)⑥midnight:每天凌晨
import logging
from logging import handlers
import time logger = logging.getLogger(__name__)
log_file = "timelog.log"
#按时间来分割文件,按5秒一次分割,保留日志个数是3个
fh = handlers.TimedRotatingFileHandler(filename=log_file,when="S",interval=5,backupCount=3)
formatter = logging.Formatter('%(asctime)s %(module)s:%(lineno)d %(message)s')
fh.setFormatter(formatter)
logger.addHandler(fh) logger.warning("test1")
time.sleep(2)
logger.warning("test12")
time.sleep(2)
logger.warning("test13")
time.sleep(2)
logger.warning("test14")
logger.warning("test15")
5、loggin实例
logging 控制台和文件共同输出日志,需要什么样的输出,只需要添加相应的handler。
流程图:

代码如下:
def log_print(log):
"""
指定文件打印日志
:param log 需打印的日志
:return 返回logger 对象
"""
# 创建一个logger对象
logger = logging.getLogger("test.log")
logger.setLevel(logging.DEBUG) # 创建一个向屏幕输入的handler对象
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG) # 创建一个像文件输入的handler对象
log_file = os.path.join(os.path.join(log_path, "log"), "log") # 向指定路径下文件写入日志
fh = logging.FileHandler(log_file, encoding="utf-8")
fh.setLevel(logging.DEBUG)
# 设置log输入格式
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
ch.setFormatter(formatter)
fh.setFormatter(formatter)
# logger,添加handler对象
logger.addHandler(ch)
logger.addHandler(fh)
logger.info(log)
# 在记录日志之后移除句柄, 不然会重复打印日志
logger.removeHandler(ch)
logger.removeHandler(fh)
return logger
re
正则表达式(或 RE)是一种小型的、高度专业化的编程语言,(在Python中)它内嵌在Python中,并通过 re 模块实现。你可以为想要匹配的相应字符串集指定规则;该字符串集可能包含英文语句、e-mail地址、TeX命令或任何你想搞定的东西。然后你可以问诸如“这个字符串匹配该模式吗?”或“在这个字符串中是否有部分匹配该模式呢?”。你也可以使用 RE 以各种方式来修改或分割字符串
一、常用的正在表达式符号
'.' 默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行
'^' 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE)
'$' 匹配字符结尾,或e.search("foo$","bfoo\nsdfsf",flags=re.MULTILINE).group()也可以
'*' 匹配*号前的字符0次或多次,re.findall("ab*","cabb3abcbbac") 结果为['abb', 'ab', 'a']
'+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb']
'?' 匹配前一个字符1次或0次
'{m}' 匹配前一个字符m次
'{n,m}' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb']
'|' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC'
'(...)' 分组匹配,re.search("(abc){2}a(123|456)c", "abcabca456c").group() 结果 abcabca456c '\A' 只从字符开头匹配,re.search("\Aabc","alexabc") 是匹配不到的
'\Z' 匹配字符结尾,同$
'\d' 匹配数字0-9
'\D' 匹配非数字
'\w' 匹配[A-Za-z0-9]
'\W' 匹配非[A-Za-z0-9]
's' 匹配空白字符、\t、\n、\r , re.search("\s+","ab\tc1\n3").group() 结果 '\t' '(?P<name>...)' 分组匹配 re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","").groupdict("city") 结果{'province': '', 'city': '', 'birthday': ''}
详细匹配符号:点击
二、常用的匹配方法
1、re.match(pattern, string, flags=0) 说明:在string的开始处匹配模式 >>> import re
>>> a = re.match('in',"inet addr:10.161.146.134") #从头开始匹配in字符
>>> a.group()
'in' >>> a = re.match('addr',"inet addr:10.161.146.134") #开头匹配不到,所以返回none
>>> print(a)
None #######################################
2、re.search(pattern, string, flags=0) 说明:在string中寻找模式
>>> import re
>>> a = re.search('addr',"inet addr:10.161.146.134") #在字符串中寻找
>>> a.group()
'addr' ########################################
3、re.findall(pattern, string, flags=0) 说明:把匹配到的字符以列表的形式返回 >>> import re
>>> re.findall('[0-9]{1,3}',"inet addri:10.161.146.134")
['', '', '', ''] #符合条件的以列表的形式返回 ########################################
4、re.split(pattern, string, maxsplit=0, flags=0) 说明:匹配到的字符被当做列表分割符 1
2
3
>>> import re
>>> re.split('\.',"inet addri:10.161.146.134")
['inet addri:10', '', '', ''] ######################################
5、re.sub(pattern, repl, string, count=0, flags=0) 说明:匹配字符并替换 >>> import re
>>> re.sub('\.','-',"inet addri:10.161.146.134")
'inet addri:10-161-146-134' #默认全部替换 >>> re.sub('\.','-',"inet addri:10.161.146.134",count=2)
'inet addri:10-161-146.134' #用count控制替换次数 #######################################
6、finditer(pattern, string) 说明:返回迭代器 >>> import re
>>> re.finditer('addr',"inet addr:10.161.146.134")
<callable_iterator object at 0x00000000030C4BE0> #返回一个迭代器
三、常用方法
1、group([group1, ...]) 说明:获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。 >>> import re
>>> a = re.search('addr',"inet addr:10.161.146.134")
>>> a.group()
'addr'
>>> a.group(0)
'addr' #######################################
2、groups(default=None) 说明:以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。这个要跟分组匹配结合起来使用'(...)' >>> import re
>>> a = re.search("(\d{2})(\d{2})(\d{2})(\d{4})","") #一个小括号表示一个组,有4个括号,就是4个组
>>> a.groups()
('', '', '', '') #######################################
3、groupdict(default=None) 说明:返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。这个是跟另外一个分组匹配结合起来用的,即:'(?P<name>...)' >>> import re
>>> a = re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","")
#以下两种情况获取的值都是一样的
>>> a.groupdict()
{'birthday': '', 'city': '', 'province': ''}
>>> a.groupdict("city")
{'birthday': '', 'city': '', 'province': ''} #########################################
4、span([group]) 说明:返回(start(group), end(group)) >>> import re
>>> a = re.search('addr',"inet addr:10.161.146.134")
>>> a.group()
'addr'
>>> a.span() #获取'addr'在字符串中的开始位置和结束位置
(5, 9) ########################################
5、start([group]) 说明:返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引),group默认值为0。
>>> import re
>>> a = re.search('addr',"inet addr:10.161.146.134")
>>> a.group()
'addr'
>>> a.span()
(5, 9)
>>> a.start() #获取字符串的起始索引
5 #########################################
6、end([group]) 说明:返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1),group默认值为0。 >>> import re
>>> a = re.search('addr',"inet addr:10.161.146.134")
>>> a.group()
'addr'
>>> a.span()
(5, 9)
>>> a.end() #获取string中的结束索引
9 ########################################
7、compile(pattern[, flags]) 说明:根据包含正则表达式的字符串创建模式对象 1
2
3
4
5
>>> import re
>>> m = re.compile("addr") #创建正则模式对象
>>> n = m.search("inet addr:10.161.146.134") #通过模式对象去匹配
>>> n.group()
'addr'
四、反斜杠、其他匹配模式
反斜杠:
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\\"表示。同样,匹配一个数字的"\\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
>>> import re
>>> a = re.split("\\\\","C:\ \zhangqigao\yhd_settings")
>>> a
['C:', ' ', 'zhangqigao', 'yhd_settings'] >>> re.findall('\\','abc\com')
Traceback (most recent call last) >>> re.findall('\\\\','abc\com')
['\\'] >>> re.findall(r'\\','abc\com')
['\\']
其他匹配模式:
1、re.I(re.IGNORECASE) 说明:忽略大小写(括号内是完整的写法,下同) >>> import re
>>> a = re.search('addr',"inet Addr:10.161.146.134",flags=re.I)
>>> a.group()
'Addr' #忽略大小写 ########################################
2、re.M(MULTILINE) 说明:多行模式,改变'^'和'$'的行为,详细请见第2点 >>> import re
>>> a = re.search('^a',"inet\naddr:10.161.146.134",flags=re.M)
>>> a.group()
'a' ########################################
3、re.S(DOTALL) 说明:点任意匹配模式,改变'.'的行为 >>> import re
>>> a = re.search('.+',"inet\naddr:10.161.146.134",flags=re.S)
>>> a.group()
'inet\naddr:10.161.146.134'
【python】-- 模块、os、sys、time/datetime、random、logging、re的更多相关文章
- 6 - 常用模块(os,sys,time&datetime,random,json&picle,shelve,hashlib)
导入模块 想使用 Python 源文件,只需在另一个源文件里执行 import 语句 import module1[, module2[,... moduleN] from语句让你从模块中导入一个指定 ...
- python模块 os&sys&subprocess&hashlib模块
os模块 # os模块可根据带不带path分为两类 # 不带path print(os.getcwd()) # 得到当前工作目录 print(os.name) # 指定你正在使用的操作系统,windo ...
- Python模块 - os , sys.shutil
os 模块是与操作系统交互的一个接口 os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") 改变当前脚本工作目录: ...
- python模块之sys和subprocess以及编写简单的主机扫描脚本
python模块之sys和subprocess以及编写简单的主机扫描脚本 1.sys模块 sys.exit(n) 作用:执行到主程序末尾,解释器自动退出,但是如果需要中途退出程序,可以调用sys.e ...
- Python全栈--7模块--random os sys time datetime hashlib pickle json requests xml
模块分为三种: 自定义模块 内置模块 开源模块 一.安装第三方模块 # python 安装第三方模块 # 加入环境变量 : 右键计算机---属性---高级设置---环境变量---path--分号+py ...
- Python模块:time、datetime、random、os、sys、optparse
time模块的方法: 时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量. struct_time时间元组,共有九个元素组.如下图: time.localtime([secs]): ...
- python学习道路(day6note)(time &datetime,random,shutil,shelve,xml处理,configparser,hashlib,logging模块,re正则表达式)
1.tiim模块,因为方法较多我就写在code里面了,后面有注释 #!/usr/bin/env python #_*_coding:utf-8_*_ print("time".ce ...
- CSIC_716_20191116【常用模块的用法 time ,datetime, random, os, sys, hashlib】
import time import datetime import os import sys import random import hashlib time模块 时间戳(Timestamp) ...
- Python基础-列表推导式、匿名函数、os/sys/time/datetime/pymysql/xlwt/hashlib模块
列表推导式 [表达式 for 变量 in range(n) if 条件] 等效于 for 变量 in in range(n): if 条件: 表达式 优点:书写方便,缺点:不易读 注意:用的是方括号 ...
- python基础-7模块,第三方模块安装方法,使用方法。sys.path os sys time datetime hashlib pickle json requests xml
模块,用一砣代码实现了某个功能的代码集合. 类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合.而对于一个复杂的功能来,可能需要多个函数才 ...
随机推荐
- smarty在循环的时候计数来显示这是第几次循环的功能
想必有很多人比较喜欢这个smarty循环的时候有个变量增加的功能或比较需要这个功能吧?其实不需要额外的变量,当然你也许根本用不了.我们用smarty内置的就可以了.就是smarty有foreach和s ...
- 使用Spring开发和监控线程池服务
第1步:添加maven 项目 第2步:添加依赖库 将Spring的依赖添加到Maven的pom.xml文件中. 1 2 3 4 5 6 7 8 9 10 11 <!-- Spring 3 dep ...
- js 导入json配置文件
import AA from './menu.json' console.log(AA) 匹配好路径
- Android蓝牙
代码地址如下:http://www.demodashi.com/demo/12772.html 前言:最近,新换了一家公司,公司的软件需要通过蓝牙与硬件进行通讯,于是趁此机会将Android蓝牙详细的 ...
- curl测试Docker容器连通性
通过curl来测试docker对外访问是否正常,这里测试Docker tomcat容器访问: [root@mysqlserver ~]# curl http://172.17.0.8:8080 < ...
- Android事件的分发
1 http://blog.csdn.net/guolin_blog/article/details/9097463 2
- Linux Mint (应用软件— 虚拟机:Virtualbox)
近期想自己折腾一下Linux系统本身.比方Linux裁减或者移植.裁减或者移植Linux是一件麻烦的事情.而且出错后会影响到当前的系统.怎样才干不影响当前机器上的系统呢,于是便想到了虚拟机.在当前系统 ...
- 自己动手开发IOC容器
前两天写简历.写了一句:精通Spring IoC容器.怎么个精通法?还是自己动手写个IOC容器吧. 什么是IoC(Inversion of Control)?什么是DI(Dependency Inje ...
- SRIO常用缩写
HELLO:Header Encoded Logical Layer Optimized (HELLO) format FTYPE:format type TTYPE:transaction type ...
- 【转】Lua 操作系统库
转老帖子备份 转自:http://www.cnblogs.com/whiteyun/archive/2009/08/10/1542913.html os.clock () 功能:返回一个程序使用C ...