PyCharm搭建Spark开发环境 + 第一个pyspark程序
一, PyCharm搭建Spark开发环境
Windows7, Java 1.8.0_74, Scala 2.12.6, Spark 2.2.1, Hadoop 2.7.6
通常情况下,Spark开发是基于Linux集群的,但这里作为初学者并且囊中羞涩,还是在windows环境下先学习吧。
参照这个配置本地的Spark环境。
之后就是配置PyCharm用来开发Spark。本人在这里浪费了不少时间,因为百度出来的无非就以下两种方式:
1. 在程序中设置环境变量
import os
import sys os.environ['SPARK_HOME'] = 'C:\xxx\spark-2.2.1-bin-hadoop2.7'
sys.path.append('C:\xxx\spark-2.2.1-bin-hadoop2.7\python')
2. 在Edit Configuration中添加环境变量

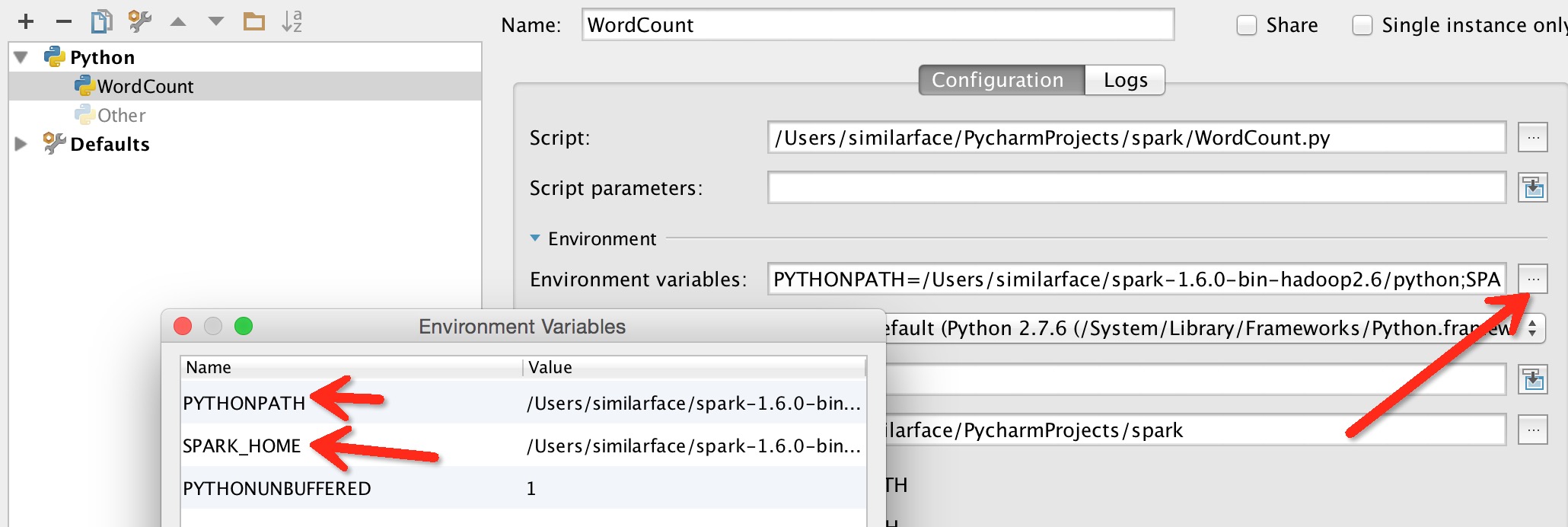
不过还是没有解决程序中代码自动补全。
想了半天,观察到spark提供的pyspark很像单独的安装包,应该可以考虑将pyspark包放到python的安装目录下,这样也就自动添加到之前所设置的python path里了,应该就能实现pyspark的代码补全提示。
将spark下的pyspark包放到python路径下(注意,不是spark下的python!)
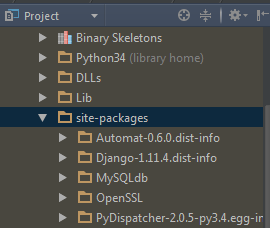
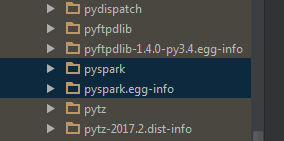
最后,实现了pyspark代码补全功能。
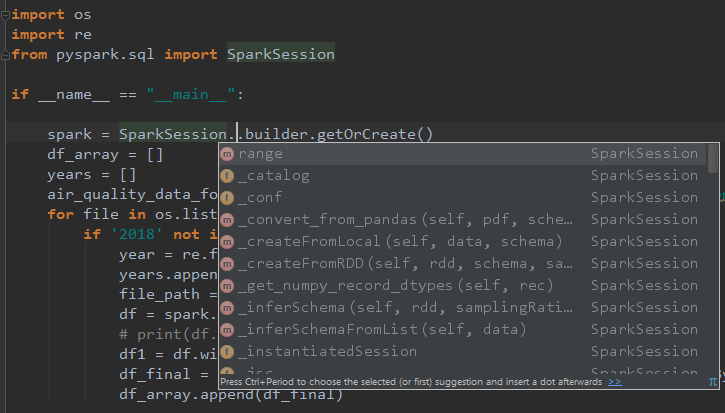
二. 第一个pyspark程序
作为小白,只能先简单用下python+pyspark了。
数据: Air Quality in Madrid (2001-2018)
需求: 根据历史数据统计出每个月平均指标值
import os
import re
from pyspark.sql import SparkSession if __name__ == "__main__": spark = SparkSession.builder.getOrCreate()
df_array = []
years = []
air_quality_data_folder = "C:/xxx/spark/air-quality-madrid/csvs_per_year"
for file in os.listdir(air_quality_data_folder):
if '' not in file:
year = re.findall("\d{4}", file)
years.append(year[0])
file_path = os.path.join(air_quality_data_folder, file)
df = spark.read.csv(file_path, header="true")
# print(df.columns)
df1 = df.withColumn('yyyymm', df['date'].substr(0, 7))
df_final = df1.filter(df1['yyyymm'].substr(0, 4) == year[0]).groupBy(df1['yyyymm']).agg({'PM10': 'avg'})
df_array.append(df_final) pm10_months = [0] * 12
# print(range(12))
for df in df_array:
for i in range(12):
rows = df.filter(df['yyyymm'].contains('-'+str(i+1).zfill(2))).first()
# print(rows[1])
pm10_months[i] += (rows[1]/12) years.sort()
print(years[0] + ' - ' + years[len(years)-1] + '年,每月平均PM10统计')
m_index = 1
for data in pm10_months:
print(str(m_index).zfill(2) + '月份: ' + '||' * round(data))
m_index += 1
运行结果:
2001 - 2017年,每月平均PM10统计
01月份: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
02月份: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
03月份: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
04月份: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
05月份: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
06月份: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
07月份: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
08月份: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
09月份: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
10月份: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
11月份: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
12月份: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
由以上统计结果,可以看出4月份的PM10最低。
Done!
PyCharm搭建Spark开发环境 + 第一个pyspark程序的更多相关文章
- Pycharm搭建Django开发环境
Pycharm搭建Django开发环境 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我们大家都知道Django是python都一个web框架,因此大家需要自行安装python环境 ...
- PyCharm搭建pyqt5开发环境
PyCharm搭建PyQt5开发环境 1.安装PyQt5 2.PyCharm环境配置 2.1 添加QtDesigner 2.2 添加PyUIC 2.3 添加Pyrcc 2.4 添加assistant ...
- Intellij IDEA使用Maven搭建spark开发环境(scala)
如何一步一步地在Intellij IDEA使用Maven搭建spark开发环境,并基于scala编写简单的spark中wordcount实例. 1.准备工作 首先需要在你电脑上安装jdk和scala以 ...
- Intellij Idea搭建Spark开发环境
在Spark高速入门指南 – Spark安装与基础使用中介绍了Spark的安装与配置.在那里还介绍了使用spark-submit提交应用.只是不能使用vim来开发Spark应用.放着IDE的方便不用. ...
- 通过搭建一个精简的C语言开发环境了解一个C程序的执行过程
一.如何搭建一个精简的C语言开发环境 准备:下载TC2.0,并解压,比如说“d:\tc2.0\tc”目录 1.在C盘建立一个目录minic c:\ md minic 2.从解压的目录中将以下文件拷贝到 ...
- 服务器上搭建spark开发环境
1.安装相应的软件 (1)安装jdk 下载地址:http://www.Oracle.com/technetwork/java/javase/downloads/index.html (2)安装scal ...
- Spark(八) -- 使用Intellij Idea搭建Spark开发环境
Intellij Idea下载地址: 官方下载 选择右下角的Community Edition版本下载安装即可 本文中使用的是windows系统 环境为: jdk1.6.0_45 scala2.10. ...
- 大数据学习(25)—— 用IDEA搭建Spark开发环境
IDEA是一个优秀的Java IDE工具,它同样支持其他语言.Spark是用Scala语言编写的,用Scala开发Spark是最舒畅的.当然,Spark也提供Java和Python的API. Java ...
- spark学习10(win下利用Intellij IDEA搭建spark开发环境)
第一步:启动IntelliJ IDEA,选择Create New Project,然后选择Scala,点击下一步,输入项目名称wujiadong.spark继续下一步 第二步:导入spark-asse ...
随机推荐
- Codeforces 1028E. Restore Array
题目直通车:http://codeforces.com/problemset/problem/1028/E 解法:设原数组为ar[],求ar中的最大值的下标ins,依次向前遍历一遍,每一个答案值都为前 ...
- tyvj——P1001 第K极值
P1001 第K极值 时间: 1000ms / 空间: 131072KiB / Java类名: Main 背景 成成第一次模拟赛 第一道 描述 给定一个长度为N(0<n<=10000)的序 ...
- POJ 2441 Arrange the Bulls(状压DP)
[题目链接] http://poj.org/problem?id=2441 [题目大意] 每个人有过个喜欢的篮球场地,但是一个场地只能给一个人, 问所有人都有自己喜欢的场地的方案数. [题解] 状态S ...
- [CF617E]XOR and Favorite Number/[CQOI2018]异或序列
题目大意: 给定一个长度为$n(n\leq10^5)$的数列$A$和数$k$$(A_i,k\leq10^6)$.$m$组询问,每次询问区间$[l,r]$中有多少对$i,j(l\leq i\leq j\ ...
- 八. 输入输出(IO)操作8.文件的压缩处理
Java.util.zip 包中提供了可对文件的压缩和解压缩进行处理的类,它们继承自字节流类OutputSteam 和 InputStream.其中 GZIPOutputStream 和 ZipOut ...
- Linux Whois命令安装与使用
大家都知道查看域名的详细信息,都是跑去whois服务器去查询,如 http://whois.chinaz.com 其实在Linux下直接有一个whois的命令,不过需要安装jwhois才可以,以Cen ...
- linux-网络监控命令-netstat初级
简介 Netstat 命令用于显示各种网络相关信息,如网络连接,路由表,接口状态 (Interface Statistics),masquerade 连接,多播成员 (Multicast Member ...
- MySQL配置参数:wait_timeout
作者:老王 如果你没有修改过MySQL的配置,缺省情况下,wait_timeout 的初始值是. wait_timeout过大有弊端,其体现就是MySQL里大量的SLEEP进程无法及时释放,拖累系统性 ...
- Android kernel Crash后,定位出错点的方法
转载:http://blog.csdn.net/wlwl0071986/article/details/11635749 1. 将/prebuild/gcc/linux-x86/arm/arm-lin ...
- tq2440实验手册qt编译问题
转载:http://blog.sina.com.cn/s/blog_6182b82201015ym1.html 编译qtopia最好使用的是低版本的gcc和g++. 举个简单的例子在qtopia的源代 ...