ORACLE体系结构一 (实例(instance))--ORACLE_SID
数据库实例(也称为服务器Server)就是用来访问一个数据库文件集的一个存储结构及后台进程的集合。它使一个单独的数据库可以被多个实例访问(也就是ORACLE并行服务器-- OPS)。
实例在操作系统中用ORACLE_SID来标识,在Oracle中用参数INSTANCE_NAME来标识, 它们两个的值是相同的。数据库启动时,系统首先在服务器内存中分配系统全局区(SGA),构成了Oracle的内存结构,然后启动若干个常驻内存的操作系统进程,即组成了Oracle的 进程结构,内存区域和后台进程合称为一个Oracle实例。
Oracle Server
一个Oracle Server由一个Oracle实例和一个Oracle数据库组成。
即:Oracle Server = Oracle Instance + Oracle Database
Oracle实例
包括了内存结构(SGA)和一系列后台进程(Background Process)
即:Oracle Instance = SGA + Background Process
Oracle内存结构
包含系统全局区(SGA)和程序全局区(PGA)
即Oracle Memory Structures = SGA + PGA
SGA由服务器和后台进程共享
PGA包含单个服务器进程或单个后台进程的数据和控制信息,与几个进程共享的SGA 正相反,PGA是只被一个进程使用的区域,PGA 在创建进程时分配在终止进程时回收。即由服务器进程产生。

oracle实例
一、memory structures
1.系统全局区(SGA)
SGA是一组为系统分配的共享的内存结构,可以包含一个数据库实例的数据或控制信息。如果多个用户连接到同一个数据库实例,在实例的SGA中,数据可以被多个用户共享, 当数据库实例启动时,SGA的内存被自动分配;当数据库实例关闭时,SGA内存被回收。 SGA是占用内存最大的一个区域,同时也是影响数据库性能的重要因素。
主要包括:
1)数据块缓存区(data block buffer cache)
数据块缓存区(data block buffer cache)是SGA中的一个高速缓存区域,用来存储从数据库中读取数据段的数据块(如表、索引和簇)。数据块缓存区的大小由数据库服务器init.ora文件中的DB_LOCK_BUFFERS参数决定(用数据库块的个数表示)。在调整和管理数据库时,调整数据块缓存区的大小是一个重要的部分。
因为数据块缓存区的大小固定,并且其大小通常小于数据库段所使用的空间,所以它不能一次装载下内存中所有的数据库段。通常,数据块缓存区只是数据库大小的1%~2%,Oracle使用最近最少使用(LRU,leastrecentlyused)算法来管理可用空间。当存储区需要自由空间时,最近最少使用块将被移出,新数据块将在存储区代替它的位置。通过这种方法,将最频繁使用的数据保存在存储区中。
然而,如果SGA的大小不足以容纳所有最常使用的数据,那么,不同的对象将争用数据块缓存区中的空间。当多个应用程序共享同一个SGA时,很有可能发生这种情况。此时,每个应用的最近使用段都将与其他应用的最近使用段争夺SGA中的空间。其结果是,对数据块缓存区的数据请求将出现较低的命中率,导致系统性能下降。
大小由db_cache_size 决定
查看:show parameter db_cache_size;
设置:alter system set db_cache_size=800M;
2)重做日志缓冲区 (redo log buffer cache)
重做项描述对数据库进行的修改。它们写到联机重做日志文件中,以便在数据库恢复过程中用于向前滚动操作。然而,在被写入联机重做日志文件之前,事务首先被记录在称作重做日志缓冲区(redologbuffer)的SGA中。数据库可以周期地分批向联机重做日志文件中写重做项的内容,从而优化这个操作。重做日志缓冲区的大小(以字节为单位)由init.ora文件中的LOG_BUFFER参数决定。
3) 共享池(Shared pool):是SGA中最关键的内存片段,共享池主要由库缓存(共享SQL区和PL/SQL区)和数据字典缓存组成,它的作用是存放频繁使用的sql,在有限的容量下,数据库系统根据一定的算法决定何时释放共享池中的sql。
库缓存大小由shared_pool_size 决定
查看:show parameter shared_pool_size
修改:alter system set shared_pool_size=120m;
4)数据字典缓存(data dictionary cache):存储数据库中数据文件、表、索引、列、用户和其它数据对象的定义和权限信息
大小由shared_pool_size 决定,不能单独指定
5)大池(Large pool):是一个可选的区域,用于一些大型的进程如Oracle的备份恢复操作、IO服务器进程等
6)Java 池:该程序缓冲区就是为Java 程序保留的。如果不用Java程序没有必要改变该缓冲区的默认大小
7)流池(Stream pool):被Oracle流所使用
2.PGA 是为每个用户进程连接ORACLE数据库保留的内存,进程创建时分配,进程结束时释放,只能被一个进程使用。
PGA包括了以下几个结构:
(1)排序区
(2)游标状态区
(3)会话信息区
(4)堆栈区
由参数:pga_aggregate_target 决定
二、 background structures
几类进程:用户进程(User Process)、服务进程(Server Process)、后台进程(Background Processes),其它可选进程
用户进程:在用户连接数据库产生,请求oracle服务器连接,必须要先建立一个连接,不会直接和oracle服务器连接
服务器进程:当连接实例并建立用户会话时产生,独立服务器或者提供共享服务器都能产生
后台进程:维持物理和内存之间的联系,用来管理数据库的读写,恢复和监视等工作。Server Process主要是通过他和user process进行联系和沟通,并由他和user process进行数据的交换。
在Unix机器上,Oracle后台进程相对于操作系统进程,也就是说,一个Oracle后台进程将启动一个操作系统进程。
在Windows机器上,Oracle后台进程相对于操作系统线程,打开任务管理器,我们只能看到一个ORACLE.EXE的进程,但是通过另外的工具,就可以看到包含在这里进程中的线程。
必有的进程:
PMON -->程序监控进程
SMON -->系统监控进程
DBWn -->数据库写进程
LGWr -->日志写进程
CKPT -->检查点进程
可选的进程:
ARCN 归档进程
RECO
Snnn
pnnn
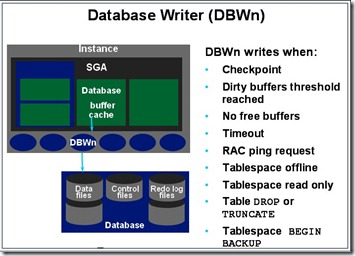
1)DBWR进程:该进程执行将缓冲区写入数据文件,是负责缓冲存储区管理的一个Oracle后台进程。当缓冲区中的一缓冲区被修改,它被标志为“弄脏”,DBWR的主要任务是将“弄脏”的缓冲区写入磁盘,使缓冲区保持“干净”。由于缓冲存储区的缓冲区填入数据库或被用户进程弄脏,未用的缓冲区的数目减少。当未用的缓冲区下降到很少,以致用户进程要从磁盘读入块到内存存储区时无法找到未用的缓冲区时,DBWR将管理缓冲存储区,使用户进程总可得到未用的缓冲区。
Oracle采用LRU(LEAST RECENTLY USED)算法(最近最少使用算法)保持内存中的数据块是最近使用的,使I/O最小。在下列情况预示DBWR 要将弄脏的缓冲区写入磁盘:
当一个服务器进程将一缓冲区移入“弄脏”表,该弄脏表达到临界长度时,该服务进程将通知DBWR进行写。该临界长度是为参数DB-BLOCK-WRITE-BATCH的值的一半。
当一个服务器进程在LRU表中查找DB-BLOCK-MAX-SCAN-CNT缓冲区时,没有查到未用的缓冲区,它停止查找并通知DBWR进行写。出现超时(每次3秒),DBWR 将通知本身。当出现检查点时,LGWR将通知DBWR.在前两种情况下,DBWR将弄脏表中的块写入磁盘,每次可写的块数由初始化参数DB-BLOCK- WRITE-BATCH所指定。如果弄脏表中没有该参数指定块数的缓冲区,DBWR从LUR表中查找另外一个弄脏缓冲区。
如果DBWR在三秒内未活动,则出现超时。在这种情况下DBWR对LRU表查找指定数目的缓冲区,将所找到任何弄脏缓冲区写入磁盘。每当出现超时,DBWR查找一个新的缓冲区组。每次由DBWR查找的缓冲区的数目是为寝化参数DB-BLOCK- WRITE-BATCH的值的二倍。如果数据库空运转,DBWR最终将全部缓冲区存储区写入磁盘。
在出现检查点时,LGWR指定一修改缓冲区表必须写入到磁盘。DBWR将指定的缓冲区写入磁盘。
在有些平台上,一个实例可有多个DBWR.在这样的实例中,一些块可写入一磁盘,另一些块可写入其它磁盘。参数DB-WRITERS控制DBWR进程个数。
2、LGWR进程:该进程将日志缓冲区写入磁盘上的一个日志文件,它是负责管理日志缓冲区的一个Oracle后台进程。LGWR进程将自上次写入磁盘以来的全部日志项输出,LGWR输出:
◆当用户进程提交一事务时写入一个提交记录。
◆每三秒将日志缓冲区输出。
◆当日志缓冲区的1/3已满时将日志缓冲区输出。
◆当DBWR将修改缓冲区写入磁盘时则将日志缓冲区输出。
LGWR进程同步地写入到活动的镜象在线日志文件组。如果组中一个文件被删除或不可用,LGWR可继续地写入该组的其它文件。
日志缓冲区是一个循环缓冲区。当LGWR将日志缓冲区的日志项写入日志文件后,服务器进程可将新的日志项写入到该日志缓冲区。LGWR 通常写得很快,可确保日志缓冲区总有空间可写入新的日志项。
注意:有时候当需要更多的日志缓冲区时,LWGR在一个事务提交前就将日志项写出,而这些日志项仅当在以后事务提交后才永久化。
ORACLE使用快速提交机制,当用户发出COMMIT语句时,一个COMMIT记录立即放入日志缓冲区,但相应的数据缓冲区改变是被延迟,直到在更有效时才将它们写入数据文件。当一事务提交时,被赋给一个系统修改号(SCN),它同事务日志项一起记录在日志中。由于SCN记录在日志中,以致在并行服务器选项配置情况下,恢复操作可以同步。

3、CKPT进程:该进程在检查点出现时,对全部数据文件的标题进行修改,指示该检查点。在通常的情况下,该任务由LGWR执行。然而,如果检查点明显地降低系统性能时,可使CKPT进程运行,将原来由LGWR进程执行的检查点的工作分离出来,由CKPT进程实现。对于许多应用情况,CKPT进程是不必要的。只有当数据库有许多数据文件,LGWR在检查点时明显地降低性能才使CKPT运行。 CKPT进程不将块写入磁盘,该工作是由DBWR完成的。初始化参数CHECKPOINT-PROCESS控制CKPT进程的使能或使不能。缺省时为FALSE,即为使不能。
由于Oracle中LGWR和DBWR工作的不一致,Oracle引入了检查点的概念,用于同步数据库,保证数据库的一致性。在Oracle里面,检查点分为两种:完全检查点和增量检查点。下面我们分别介绍这两种检查点的作用:
1、完全检查点
在Oracle8i之前,数据库的发生的检查点都是完全检查点,完全检查点会将数据缓冲区里面所有的脏数据块写入相应的数据文件中,并且同步数据文件头和控制文件,保证数据库的一致。完全检查点在8i之后只有在下列两种情况下才会发生:
(1)DBA手工执行alter system checkpoint的命令;
(2)数据库正常shutdown(immediate,transcational,normal)。
由于完全检查点会将所有的脏数据库块写入,巨大的IO往往会影响到数据库的性能。因此Oracle从8i开始引入了增量检查点的概念。
2、 增量检查点
Oracle从8i开始引入了检查点队列这么一种概念,用于记录数据库里面当前所有的脏数据块的信息,DBWR根据这个队列而将脏数据块写入到数据文件中。检查点队列按时间先后记录着数据库里面脏数据块的信息,里面的条目包含RBA(Redo Block Address,重做日志里面用于标识检查点期间数据块在重做日志里面第一次发生更改的编号)和数据块的数据文件号和块号。在检查点期间不论数据块更改几次,它在检查点队列里面的位置始终保持不变,检查点队列也只会记录它最早的RBA,从而保证最早更改的数据块能够尽快写入。当DBWR将检查点队列里面的脏数据块写入到数据文件后,检查点的位置也要相应地往后移,CKPT每三秒会在控制文件中记录检查点的位置,以表示Instance Recovery时开始恢复的日志条目,这个概念称为检查点的“心跳”(heartbeat)。检查点位置发生变更后,Oracle里面通过4个参数用于控制检查点位置和最后的重做日志条目之间的距离。在这里面需要指出的是,多数人会将这4个参数看作控制增量检查点发生的时间。事实上这是错误的,这4个参数是用于控制检查点队列里面的条目数量,而不是控制检查点的发生。
(1)fast_start_io_target
该参数用于表示数据库发生Instance Recovery的时候需要产生的IO总数,它通过v$filestat的AVGIOTIM来估算的。比如我们一个数据库在发生Instance Crash后需要在10分钟内恢复完毕,假定OS的IO每秒为500个,那么这个数据库发生Instance Recovery的时候大概将产生500*10*60=30,000次IO,也就是我们将可以把fast_start_io_target设置为30000。
(2)fast_start_mttr_target
我们从上面可以看到fast_start_io_target来估算检查点位置比较麻烦。Oracle为了简化这个概念,从9i开始引入了fast_start_mttr_target这么一个参数,用于表示数据库发生Instance Recovery的时间,以秒为单位。这个参数我们从字面上也比较好理解,其中的mttr是mean time to recovery的简写,如上例中的情况我们可以将fast_start_mttr_target设置为600。当设置了fast_start_mttr_target后,fast_start_io_target这个参数将不再生效,从9i后fast_start_io_target这个参数被Oracle废除了。
(3)log_checkpoint_timeout
该参数用于表示检查点位置和重做日志文件末尾之间的时间间隔,以秒为单位,默认情况下是1800秒。
(4)log_checkpoint_interval
该参数是表示检查点位置和重做日志末尾的重做日志块的数量,以OS块表示。
(5)90% OF SMALLEST REDO LOG
除了以上4个初始化参数外,Oracle内部事实上还将重做日志文件末尾前面90%的位置设为检查点位置。在每个重做日志中,这么几个参数指定的位置可能不尽相同,Oracle将离日志文件末尾最近的那个位置确认为检查点位置。
4、SMON进程:该进程实例启动时,执行实例恢复,还负责清理不再使用的临时段。在具有并行服务器选项的环境下,SMON对有故障CPU或实例进行实例恢复。SMON进程有规律地被呼醒,检查是否需要,或者其它进程发现需要时可以被调用。
5、PMON进程:该进程在用户进程出现故障时执行进程恢复,负责清理内存储区和释放该进程所使用的资源。例:它要重置活动事务表的状态,释放封锁,将该故障的进程的ID从活动进程表中移去。PMON还周期地检查调度进程(DISPATCHER)和服务器进程的状态,如果已死,则重新启动(不包括有意删除的进程)。
PMON有规律地被呼醒,检查是否需要,或者其它进程发现需要时可以被调用。
6、RECO进程:该进程是在具有分布式选项时所使用的一个进程,自动地解决在分布式事务中的故障。一个结点RECO后台进程自动地连接到包含有悬而未决的分布式事务的其它数据库中,RECO自动地解决所有的悬而不决的事务。任何相应于已处理的悬而不决的事务的行将从每一个数据库的悬挂事务表中删去。
当一数据库服务器的RECO后台进程试图建立同一远程服务器的通信,如果远程服务器是不可用或者网络连接不能建立时,RECO自动地在一个时间间隔之后再次连接。
RECO后台进程仅当在允许分布式事务的系统中出现,而且DISTRIBUTED C TRANSACTIONS参数是大于0。
7、ARCH进程:该进程将已填满的在线日志文件拷贝到指定的存储设备。当日志是为ARCHIVELOG使用方式、并可自动地归档时ARCH进程才存在。
8、LCKn进程:是在具有并行服务器选件环境下使用,可多至10个进程(LCK0,LCK1……,LCK9),用于实例间的封锁。
9、Dnnn进程(调度进程):该进程允许用户进程共享有限的服务器进程(SERVER PROCESS)。没有调度进程时,每个用户进程需要一个专用服务进程(DEDICATEDSERVER PROCESS)。对于多线索服务器(MULTI-THREADED SERVER)可支持多个用户进程。如果在系统中具有大量用户,多线索服务器可支持大量用户,尤其在客户_服务器环境中。
在一个数据库实例中可建立多个调度进程。对每种网络协议至少建立一个调度进程。数据库管理员根据操作系统中每个进程可连接数目的限制决定启动的调度程序的最优数,在实例运行时可增加或删除调度进程。多线索服务器需要SQL*NET版本2或更后的版本。在多线索服务器的配置下,一个网络接收器进程等待客户应用连接请求,并将每一个发送到一个调度进程。如果不能将客户应用连接到一调度进程时,网络接收器进程将启动一个专用服务器进程。该网络接收器进程不是Oracle实例的组成部分,它是处理与Oracle有关的网络进程的组成部分。在实例启动时,该网络接收器被打开,为用户连接到Oracle建立一通信路径,然后每一个调度进程把连接请求的调度进程的地址给予它的接收器。当一个用户进程作连接请求时,网络接收器进程分析请求并决定该用户是否可使用一调度进程。如果是,该网络接收器进程返回该调度进程的地址,之后用户进程直接连接到该调度进程。有些用户进程不能调度进程通信(如果使用SQL*NET以前的版本的用户),网络接收器进程不能将此用户连接到一调度进程。在这种情况下,网络接收器建立一个专用服务器进程,建立一种合适的连接。
ORACLE体系结构一 (实例(instance))--ORACLE_SID的更多相关文章
- Oracle 体系结构2 - 实例和数据库
Oracle最最基本的概念: 实例和数据库 实例就是oracle进程和一块共享内存, 数据库就是静态的文件,如datafile, log file, redo logfile, control fil ...
- Oracle体系结构学习笔记
Oracle体系结构由实例和一组数据文件组成,实例由SGA内存区,SGA意思是共享内存区,由share pool(共享池).data buffer(数据缓冲区).log buffer(日志缓冲区)组成 ...
- Oracle实例和Oracle数据库(Oracle体系结构)
--========================================== --Oracle实例和Oracle数据库(Oracle体系结构) --==================== ...
- 【转载】Oracle实例和Oracle数据库(Oracle体系结构)
免责声明: 本文转自网络文章,转载此文章仅为个人收藏,分享知识,如有侵权,请联系博主进行删除. 原文作者:Leshami 原文地址:http://blog.csdn.net/ ...
- Oracle 启动实例(instance)、打开数据库
Oracle启动实例(instance).打开数据库 by:授客 QQ:1033553122 启动实例(instance).打开数据库 1.开启sqlplus [laiyu@localhost ~ ...
- Oracle实例和Oracle数据库(Oracle体系结构)---转载
对于初接触Oracle 数据库的人来讲,很容易混淆的两个概念即是Oracle 实例和Oracle 数据库.这两 概念不同于SQL sever下的实例与数据库,当然也有些相似之处.只是在SQL serv ...
- [学习笔记] Oracle体系结构、下载安装、创建实例、客户端工具、网络服务名、服务管理
Oracle体系结构 实例: 一个操作系统只有一个 Oracle 数据库 一个 Oracle 数据库可以有多个 Oracle 实例(通常只安装一个实例) 一个实例对应着一系列的后台进程和内存结构 表空 ...
- Linux平台oracle 11g单实例 + ASM存储 安装部署 快速参考
操作环境:Citrix虚拟化环境中申请一个Linux6.4主机(模板)目标:创建单机11g + ASM存储 数据库 1. 主机准备 2. 创建ORACLE 用户和组成员 3. 创建以下目录并赋予对应权 ...
- oracle 体系结构
oracle 体系结构 数据库的体系结构是指数据库的组成.工作过程与原理,以及数据在数据库中的组织与管理机制. 1. oracle工作原理: 1).在数据库服务器上启动Oracle实例:2).应用程序 ...
随机推荐
- 02-大鸭梨博客系统数据库设计及Dapper的使用
毫无疑问,数据库的设计在一个系统中起了至关重要的作用.我们都知道,系统设计分为两部分,或者说是两个阶段,即数据库设计和功能设计.构建一个完善的系统需要这两个阶段的充分考量.周密设计.合理联接以及密切配 ...
- MySQL索引分析
索引的出现解决数据量上升导致查询越来越慢的问题,优化数据的查询,提高查询的速度. 索引 定义: 通过各种数据结构实现的值到行位置的映射.快速定位与访问特定的数据. 作用: 提高访问速度 实现主键.唯一 ...
- linux(ubuntu16.04)下安装和破解pycharm专业版
我用的linux 版本是ubuntu,查看版本命令是: lsb_release -a 因为学习Python爬虫,pycharm是Python很好用的IDE,但是专业版需要付费,所以开始安装: 首先在官 ...
- js 读取json数据 挖坑
一般遇到后台给的json数据格式不对 比如key和value都是单引号. 但真正的json 的key和value都是双引号,必须双引号才能取值. 再来一个例子看看 var test = [{ &quo ...
- 【集成学习】sklearn中xgboot模块中fit函数参数详解(fit model for train data)
参数解释,后续补上. # -*- coding: utf-8 -*- """ ############################################## ...
- ZOJ2314 Reactor Cooling(有上下界的网络流)
The terrorist group leaded by a well known international terrorist Ben Bladen is buliding a nuclear ...
- 19年博客flag
目录 为什么没有年终总结 为什么今天更新了 19年博客flag 个人博客链接:我在马路边 https://hhongwen.cn 更好的阅读体验点击查看原文:19年博客flag 原创博客,转载请注明出 ...
- 设置nodepad++的编码问题
- 微信无法跳转appstore总结--应用宝微下载申请
以前是有方法,可以实现微信下跳转appstore的. 大概就是把url改为:http://mp.weixin.qq.com/mp/redirect?url="跳转url"(可编码也 ...
- springboot启动异常:java.lang.IllegalArgumentException: Could not resolve placeholder 'xxx.xxx.xxx' in value "${xxx.xxx.xxx}"
场景: 本地启动正常,部署到服务器上启动时启动tomcat失败,显示上面的问题. 原因: 本地打包的时候没有修改指定的配置文件名称(本地只有一份配置文件). 在打包到服务器上时指定的配置文件命名会去查 ...