[大牛翻译系列]Hadoop(21)附录D.1 优化后的重分区框架
附录D.1 优化后的重分区框架
Hadoop社区连接包需要将每个键的所有值都读取到内存中。如何才能在reduce端的连接减少内存开销呢?本文提供的优化中,只需要缓存较小的数据集,然后在连接中遍历较大数据集中的数据。这个方法中还包括针对map的输出数据的次排序,那么reducer先接收到较小的数据集,然后接收到较大的数据集。图D.1是这个过程的流程图。

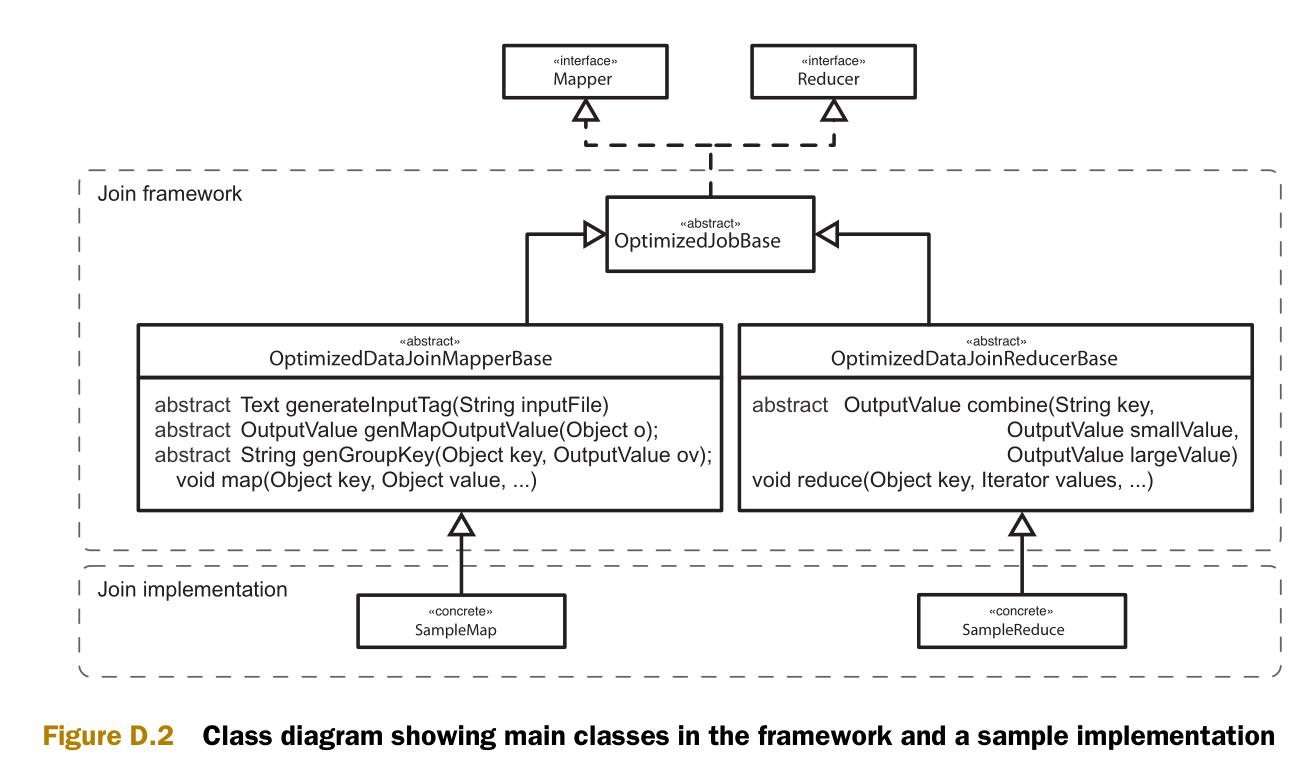
图D.2是实现的类图。类图中包含两个部分,一个通用框架和一些类的实现样例。
连接框架
我们以和Hadoop社区连接包的近似的风格编写连接的代码。目标是创建可以处理任意数据集的通用重分区机制。为简洁起见,我们重点说明主要部分。
首先是OptimizedDataJoinMapperBase类。这个类的作用是辨认出较小的数据集,并生成输出键和输出值。Configure方法在mapper创建时被调用。Configure方法的作用之一是标识每一个数据集,让reducer可以区分数据的源数据集。另一个作用是辨认当前的输入数据是否是较小的数据集。
protected abstract Text generateInputTag(String inputFile);
protected abstract boolean isInputSmaller(String inputFile);
public void configure(JobConf job) {
this.inputFile = job.get("map.input.file");
this.inputTag = generateInputTag(this.inputFile);
if(isInputSmaller(this.inputFile)) {
smaller = new BooleanWritable(true);
outputKey.setOrder(0);
} else {
smaller = new BooleanWritable(false);
outputKey.setOrder(1);
}
}
Map方法首先调用自定义的方法 (generateTaggedMapOutput) 来生成OutputValue对象。这个对象包含了在连接中需要使用的值(也可能包含了最终输出的值),和一个标识较大或较小数据集的布尔值。如果map方法可以调用自定义的方法 (generateGroupKey) 来得到可以在连接中使用的键,那么这个键就作为map的输出键。
protected abstract OptimizedTaggedMapOutput generateTaggedMapOutput(Object value); protected abstract String generateGroupKey(Object key, OptimizedTaggedMapOutput aRecord); public void map(Object key, Object value, OutputCollector output, Reporter reporter)
throws IOException { OptimizedTaggedMapOutput aRecord = generateTaggedMapOutput(value); if (aRecord == null) {
return;
} aRecord.setSmaller(smaller);
String groupKey = generateGroupKey(aRecord); if (groupKey == null) {
return;
} outputKey.setKey(groupKey);
output.collect(outputKey, aRecord);
}
图D.3 说明了map输出的组合键(composite 可以)和组合值。次排序将会根据连接键(join key)进行分区,并用整个组合键来进行排序。组合键包括一个标识源数据集(较大或较小)的整形值,因此可以根据这个整形值来保证较小源数据集的值先于较大源数据的值被reduce接收。

下一步是深入reduce。此前已经可以保证较小源数据集的值将会先于较大源数据集的值被接收。这里就可以将所有的较小源数据集的值放到缓存中。在开始接收较大源数据集的值的时候,就开始和缓存中的值做连接操作。
public void reduce(Object key, Iterator values, OutputCollector output, Reporter reporter)
throws IOException { CompositeKey k = (CompositeKey) key;
List<OptimizedTaggedMapOutput> smaller = new ArrayList<OptimizedTaggedMapOutput>(); while (values.hasNext()) {
Object value = values.next();
OptimizedTaggedMapOutput cloned =((OptimizedTaggedMapOutput) value).clone(job); if (cloned.isSmaller().get()) {
smaller.add(cloned);
} else {
joinAndCollect(k, smaller, cloned, output, reporter);
}
}
}
方法joinAndCollect包含了两个数据集的值,并输出它们。
protected abstract OptimizedTaggedMapOutput combine(
String key,
OptimizedTaggedMapOutput value1,
OptimizedTaggedMapOutput value2); private void joinAndCollect(CompositeKey key,
List<OptimizedTaggedMapOutput> smaller,
OptimizedTaggedMapOutput value,
OutputCollector output,
Reporter reporter)
throws IOException { if (smaller.size() < 1) {
OptimizedTaggedMapOutput combined = combine(key.getKey(), null, value);
collect(key, combined, output, reporter);
} else {
for (OptimizedTaggedMapOutput small : smaller) {
OptimizedTaggedMapOutput combined = combine(key.getKey(), small, value);
collect(key, combined, output, reporter);
}
}
}
这些就是这个框架的主要内容。第4章介绍能如何使用这个框架。
[大牛翻译系列]Hadoop(21)附录D.1 优化后的重分区框架的更多相关文章
- [大牛翻译系列]Hadoop 翻译文章索引
原书章节 原书章节题目 翻译文章序号 翻译文章题目 链接 4.1 Joining Hadoop(1) MapReduce 连接:重分区连接(Repartition join) http://www.c ...
- [大牛翻译系列]Hadoop(1)MapReduce 连接:重分区连接(Repartition join)
4.1 连接(Join) 连接是关系运算,可以用于合并关系(relation).对于数据库中的表连接操作,可能已经广为人知了.在MapReduce中,连接可以用于合并两个或多个数据集.例如,用户基本信 ...
- [大牛翻译系列]Hadoop(5)MapReduce 排序:次排序(Secondary sort)
4.2 排序(SORT) 在MapReduce中,排序的目的有两个: MapReduce可以通过排序将Map输出的键分组.然后每组键调用一次reduce. 在某些需要排序的特定场景中,用户可以将作业( ...
- [大牛翻译系列]Hadoop(3)MapReduce 连接:半连接(Semi-join)
4.1.3 半连接(Semi-join) 假设一个场景,需要连接两个很大的数据集,例如,用户日志和OLTP的用户数据.任何一个数据集都不是足够小到可以缓存在map作业的内存中.这样看来,似乎就不能使用 ...
- [大牛翻译系列]Hadoop(2)MapReduce 连接:复制连接(Replication join)
4.1.2 复制连接(Replication join) 复制连接是map端的连接.复制连接得名于它的具体实现:连接中最小的数据集将会被复制到所有的map主机节点.复制连接有一个假设前提:在被连接的数 ...
- [大牛翻译系列]Hadoop(22)附录D.2 复制连接框架
附录D.2 复制连接框架 复制连接是map端连接,得名于它的具体实现:连接中最小的数据集将会被复制到所有的map主机节点.复制连接的实现非常直接明了.更具体的内容可以参考Chunk Lam的<H ...
- [大牛翻译系列]Hadoop(20)附录A.10 压缩格式LZOP编译安装配置
附录A.10 LZOP LZOP是一种压缩解码器,在MapReduce中可以支持可分块的压缩.第5章中有一节介绍了如何应用LZOP.在这一节中,将介绍如何编译LZOP,在集群做相应配置. A.10.1 ...
- [大牛翻译系列]Hadoop(19)MapReduce 文件处理:基于压缩的高效存储(二)
5.2 基于压缩的高效存储(续) (仅包括技术27) 技术27 在MapReduce,Hive和Pig中使用可分块的LZOP 如果一个文本文件即使经过压缩后仍然比HDFS的块的大小要大,就需要考虑选择 ...
- [大牛翻译系列]Hadoop(18)MapReduce 文件处理:基于压缩的高效存储(一)
5.2 基于压缩的高效存储 (仅包括技术25,和技术26) 数据压缩可以减小数据的大小,节约空间,提高数据传输的效率.在处理文件中,压缩很重要.在处理Hadoop的文件时,更是如此.为了让Hadoop ...
随机推荐
- iOS-自定义导航栏后侧滑返回功能失效
iPhone有一个回退按钮在所有的导航条上.这是一个简单的没有文字箭头. 在一开始写项目的时候,就要做好一个准备,导航栏是自定义还是使用系统的,后期有什么改动,有什么比较特殊的需求.当然这些在更改需求 ...
- C语言中将数字转换为字符串的方法
C语言提供了几个标准库函数,可以将任意类型(整型.长整型.浮点型等)的数字转换为字符串.以下是用itoa()函数将整数转换为字符串的一个例子: # include <stdio. h># ...
- A Simple Problem with Integers poj 3468 多树状数组解决区间修改问题。
A Simple Problem with Integers Time Limit: 5000MS Memory Limit: 131072K Total Submissions: 69589 ...
- a letter and a number
描述we define f(A) = 1, f(a) = -1, f(B) = 2, f(b) = -2, ... f(Z) = 26, f(z) = -26;Give you a letter x ...
- 1.7.3 Relevance-相关性
1. 相关性 相关性是一个查询响应满足用户搜索信息的一个度(程度). 查询响应的相关性主要依赖于上下文的查询.单个搜索应用程序可以通过用户的不同需求和期望被用来在不同的上下文.例如,气候数据的搜索引擎 ...
- double数值多时系统默认科学计数法解决方法
比如 Double d = new Double("1234567890.12"); System.out.println("d:="+d); java.tex ...
- Remap BMW F11 2010 all ECUs with E-Sys and ENET cable
Just wanted to share some experiences remaping all the ECUs in my F11 2010 BMW, hopefully other BMW ...
- 2dx关于js响应layer触摸消息的bug
cocos2dx关于js响应layer触摸消息的bug cocos2d-x 3.7 问题描述: 目前这个版本中(3.7),c++层的layer触摸消息只能通过消息的方式发送给js,不能像lua一样直接 ...
- [MySQL] 数据统计 —— 按周,按月,按日分组统计数据
知识关键词:DATE_FORMAT select DATE_FORMAT(create_time,'%Y%u') weeks,count(caseid) count from tc_case grou ...
- Java内存管理的9个小技巧
Java内存管理的9个小技巧很多人都说“Java完了,只等着衰亡吧!”,为什么呢?最简单的的例子就是Java做的系统时非常占内存!一听到这样的话,一定会有不少人站出来为Java辩护,并举出一堆的性能测 ...