MoreEffectiveC++Item35(效率)(条款16-24)
条款16 谨记80-20法则
条款17 考虑使用 lazy evaluation(缓释评估)
条款18 分期摊还预期的计算成本
条款19 了解临时对象的来源
条款20 协助完成"返回值的优化"("RVO" return value optimization)
条款21 利用重载技术(overload)避免隐式类型转换(implicit type conversion)
条款22 考虑以操作符的复合形式(op=)取代其单独形式(op)
条款23 考虑使用其他库函数
条款24 了解virtual functions/ multiple inheritance/ virtual base class/ runtime type identification的成本
条款16 谨记80-20法则
80-20 准则说的是大约 20%的代码使用了 80%的程序资源;大约 20%的代码耗用了大约 80%的运行时间;大约 20%的代码使用了 80%的内存;大约 20%的代码执行 80%的磁盘访问;80%的维护投入于大约 20%的代码上;通过无数台机器、操作系统和应用程序上的实验这条准则已经被再三地验证过。80-20 准则不只是一条好记的惯用语,它更是一条有关系统性能的指导方针,它有着广泛的适用性和坚实的实验基础
条款17 考虑使用 lazy evaluation(缓释评估)
从效率上来看,最好的运算就是未被执行过的运算,但是这是不可能的,既然不用我们就没有必要将它加到程序中.
那么下面介绍一种战术"lazy evaluation(缓释评估)",所谓的缓释平时评估就是拖延战术,如果你采用缓式评估来编写你的类,使他们延缓运算,直到哪些运算结果刻不容缓地被迫切需要为止.如果其运算结果一直不被需要,也就一直不执行.
那么我们先介绍一种缓式评估
1.Reference Counting(引用计数)
考虑下面的代码
class String { ... }; // 一个字符串类(标准的string类型,为了描述下面的技术实现,不过并非一定如此)
String s1 = "Hello";
String s2 = s1; //调用 string 拷贝构造函数
一旦s2 = s1,那么其拷贝构造函数就会被调用,那么我们就存在两个"Hello"的副本(eager evaluation急式评估),调用new operator 来为s2分配内存
这时我们考虑一下,如果s2只做一些类似于读的操作(例如下面的代码),那么我么就没有必要去新new出一个String,我们只需要将s1和s2共享即可
cout << s1; // 读 s1 的值
cout << s1 + s2; // 读 s1 和 s2 的值
但是如果我们即要读又要写的话那么数据共享就行不通,比如说我只想修改s2那么我们就 必须要为s2创建一个"副本".为了处理这样的case,我们需要添加如下语句
s2.convertToUpperCase();
在这个方法实现中我们必须令String.converToUpperCase()函数为s2的内容做一个副本,并且在修改s2之前先让该副本成为s2的私有数据,在converToUpperCase()函数内我们不能再拖延了,我们必须将s2(被共享的内容做一个副本,给s2私人使用).另一方面如果s2从未被改变,如果我们够幸运,s2从未被改过,那么我们就始终不用去new它.(相应实现我们会在条款29和条款30中详细叙述)
2.Lazy Fetching(缓式取出)
缓式取出:只取出需要使用的部分
假设你的程序使用了一些包含许多字段的大型对象。这些象的生存期超越了程序运行期,所以它们必须被存储在数据库里。每一个对都有一个唯一的对象标识符,用来从数据库中重新获得对象
class LargeObject { // 大型持久对象
bbs.theithome.com
public:
LargeObject(ObjectID id); // 从磁盘中恢复对象
const string& field1() const; // field 1 的值
int field2() const; // field 2 的值
double field3() const; // ...
const string& field4() const;
const string& field5() const;
...
};
//现在考虑一下从磁盘中恢复 LargeObject 的开销
void restoreAndProcessObject(ObjectID id)
{
LargeObject object(id); // 恢复对象
...
}
如果我只用该对象的一小部分,那么这么庞大的开销就有些浪费了
void restoreAndProcessObject(ObjectID id)
{
LargeObject object(id);
if (object.field2() == ) {
cout << "Object " << id << ": null field2.\n";
}
}
//这里仅仅需要 filed2 的值,所以为获取其它字段而付出的努力都是浪费
此问题的缓式做法为:我们产生LargeObject时,只产生该对象的外壳,不从磁盘中取任何数据.当哪个字段被需要了在去取
class LargeObject {
public:
LargeObject(ObjectID id);
const string& field1() const;
int field2() const;
bbs.theithome.com
double field3() const;
const string& field4() const;
...
private:
ObjectID oid;
mutable string *field1Value; //mutable是易变的指针,意思是可以让任何的member function都可以修改,甚至是const menber function
mutable int *field2Value;
mutable double *field3Value;
mutable string *field4Value;
...
};
LargeObject::LargeObject(ObjectID id)
: oid(id), field1Value(), field2Value(), field3Value(), ...
{}
const string& LargeObject::field1() const
{
if (field1Value == ) {//如果指针为null,则获取数据
//从数据库中为 filed 读取数据,使field1Value 指向这个值;
}
return *field1Value;
}
对象中每个字段都用一个指向数据的指针来表示,LargeObject 构造函数把每个指针初始化为空。这些空指针表示字段还没有从数据库中读取数值。每个 LargeObject 成员函数在访问字段指针所指向的数据之前必须字段指针检查的状态。如果指针为空,在对数据进行操作之前必须从数据库中读取对应的数据.
3.lazy Expression Evaluation(表达式缓评估)
如果做2个矩阵的加法运算
template<class T>
class Matrix{...}
Matrix<int> m1(,);//1000*1000的矩阵
Matrix<int> m2(,);
...
Matrix<int>m3=m1+m2
如果我们这样做,那我们将分配3个1000*1000的矩阵内存(m1,m2,m3),和1 000 000次的运算
此问题的缓式做法为:可以先设一个数据结构于m3中,用于标记m3是m1和m2的总和,这个数据结构可能只由两个指针和一个enum组成,前者指向m1和m2,后者用来表示运算动作.这样我们只分配了两个指针和一个enum的内存和1 000 000次的运算
假设在m3被使用之前,程序又执行以下动作
Matrix<int> m4(, );
... // 赋给 m4 一些值
m3 = m4 * m1
那么我可以直接将m3定位为m4和m1的乘积
当然,lazy evaluation在此处还有更大用法——只计算大型运算中需要的部分运算结果.对于以下代码
cout << m3[];
这时我们就不能再懒惰了,但也只需要计算m3第四行的值,除此以外,不需要计算其他任何值.实际上,正是这种策略使得APL(20世纪60年代的一款如软件,允许用户以交谈方式使用软件执行矩阵运算)能够快速处理加法,减法,乘法甚至除法.
有些时候我们不能使用缓式表达式
m3=m1+m2;
m1=m4 //或者
cout << m3
其实缓式评估有的时候半点便宜都占不到,反而会加重我们的"负担",如果你的计算是必要的,lazy evaluation甚至会使程序缓慢,并增加内存用量.因为你除了要做原本的运算外,还要做一些为了 lazu evaluation而设计的数据结构.
只有当你的软件被要求执行某些计算,而这些运算可以避免的情况下 lazy evaluation才有作用
条款18 分期摊还预期的计算成本
分期摊还: 及时处理+预先处理某些事件
其意义好像与缓式评估相反,但是并不矛盾.有的时候一个大型的运算,我们将其分批处理会比一下子处理完所用的成本低,例如下面
template<class NumericalType>
class DataCollection {
public:
NumericalType min() const;
NumericalType max() const;
NumericalType avg() const;//平均值
...
}
class DataCollection 为了一个数据收集类,它的三个函数分别代表着取这个数据类的最大值,最小值,和平均值
实现这三个函数我们有三种方法
1.采取eager evaluation(急式评估),调用时立刻检查所有数据
2.采取lazy evaluation(缓式评估),令这个函数返回某些数据结构,只有其返回值真正的派上用场时,才去处检查所有数据
3.采用voer-eager evaluation(分摊),在收集数据时我们就计算出其max min avg,所里当这几个函数被调用时我们能立刻做出回应,无需再计算
如果数据比较大的时候,我们的及时处理会比急式评估,缓式评估节省很多开销(就好像上学时的寒暑假作业,每天写一点会比快开学那几天一起写完,无论从质量上还是时间分配上都会好很多)
以上就是及时处理的例子,那么下面我们来介绍一下预先处理
预先处理如其字面含义,就是打好提前量
例1:如果我们有一个程序,用来提供有关雇员的信息,这些信息中的经常被需要的部分是雇员的办公隔间号码.而假设雇员信息存储在数据库里,但是对于大多数应用程序来说,雇员隔间号都是不相关的,所以数据库不对查抄它们进行优化。为了避免你的程序给数据库造成沉重的负担,可以编写一个函数 findCubicleNumber,用来缓存查找到的数据。以后需要已经被获取的隔间号时,可以在 cache 里找到,而不用向数据库查询
int findCubicleNumber(const string& employeeName)
{
// 定义静态 map,存储 (employee name, cubicle number)pairs. 这个 map 是 local cache。
typedef map<string, int> CubicleMap;
static CubicleMap cubes;
// 尝试在cache中使用employeeName来找到详细记录
CubicleMap::iterator it = cubes.find(employeeName);
// 如果循环到cubes,end()都没有找到,那么将意味着我们最近没有使用将其加入cache
if (it == cubes.end()) {
int cubicle =
the result of looking up employeeName's cubicle
number in the database;
cubes[employeeName] = cubicle; // add the pair
// (employeeName, cubicle)
// to the cache
return cubicle;
}else {
//如果找到就说明在缓存区中,直接返回
return (*it).second;
}
}
下面我们来介绍另一种概念""预先创建""我们以动态数组为例
template<class T>//该数组为自动扩张的数组
T& DynArray<T>::operator[](int index)
{
if (index < ) {
throw an exception; // 负数索引仍不合法
}
if (index >当前最大的索引值) {
//调用 new 分配足够的额外内存,以使得索引合法;
}
返回 index 位置上的数组元素;
}
调用new的开销非常大,且非常影响效率,如果每次传入的索引值都比当前数组容量剁一的话,那么我们每次调用都会调用new,于是我们可以尝试下面的方法
DynArray::operator[]:
template<class T>
T& DynArray<T>::operator[](int index)
{
if (index < ) throw an exception;
if (index > 当前最大的索引值) {
int diff = index – 当前最大的索引值;
//调用 new 分配足够的额外内存,使得 index+diff 合法;
}
返回 index 位置上的数组元素;
}
上面的方法不在每次只new出一个空间,假设我们每次传入索引大于当前最大容量的话,我们就将动态数组扩大2倍
那么下面的调用
DynArray<double> a; // 仅仅 a[0]是合法的
a[] = 3.5; // 调用 new 扩展
// a 的存储空间到索引 44 a 的逻辑尺寸变为 23
a[] = ; // a 的逻辑尺寸被改变,允许使用 a[32],但是没有调用 new ,因为当前数组的最大容量为44,因为上面提过new属于系统函数调用时开销非常大,减少调用可以增加效率.
条款19 了解临时对象的来源
在C++中真正的临时变量是看不见的,他们不出现我们的源代码中.我们口中所谓的"临时变量其实是函数的局部变量"
template<class T>
void swap(T& object1, T& object2)
{
T temp = object1;
object1 = object2;
bbs.theithome.com
object2 = temp;//其实temp只是一个函数的局部变量
}
在C++中建立一个没有命名的非堆(non-heap)对象会产生临时变量,这种未命名的对象通常有两种方式会产生:为了使函数成功调用的隐式转换类型和函数返回对象时
首先考虑为使函数成功调用而建立临时对象这种情况。当传送给函数的对象类型与参数类型不匹配时会产生这种情况
// 返回 ch 在 str 中出现的次数
size_t countChar(const string& str, char ch);
char buffer[MAX_STRING_LEN];
char c;
// 读入到一个字符和字符串中,用 setw
// 避免缓存溢出,当读取一个字符串时
cin >> c >> setw(MAX_STRING_LEN) >> buffer;
cout << "There are " << countChar(buffer, c)
<< " occurrences of the character " << c
<< " in " << buffer << endl;
看一下 countChar 的调用。第一个被传送的参数是字符数组,但是对应函数的正被绑定的参数的类型是 const string&。仅当消除类型不匹配后,才能成功进行这个调用,你的编译器很乐意替你消除它,方法是建立一个 string 类型的临时对象。通过以 buffer 做为参数调用 string 的构造函数来初始化这个临时对象。countChar 的参数 str 被绑定在这个临时的 string 对象上。当 countChar 返回时,临时对象自动释放.
建立临时对象的第二种环境是函数返回对象时。例如 operator+必须返回一个对象,以表示它的两个操作数的和(参见 Effective C++ 条款 23)。例如给定一个类型 Number,这种类型的 operator+被这样声明:
const Number operator+(const Number& lhs,
const Number& rhs);
这个函数的返回值是临时的,因为它没有被命名;它只是函数的返回值。你必须为每次调用operator+构造和释放这个对象而付出代价综上所述,临时对象是有开销的,所以你应该尽可能地去除它们,然而更重要的是训练自己寻找可能建立临时对象的地方。在任何时候只要见到常量引用(reference-to-const)参数,就存在建立临时对象而绑定在参数上的可能性。在任何时候只要见到函数返回对象,就会有一个临时对象被建立(以后被释放)。学会寻找这些对象构造,你就能显著地增强透过编译器表面动作而看到其背后开销的能力
条款20 协助完成"返回值的优化"("RVO" return value optimization)
在条款19中我们了解到 by value的方式返回对象,被后隐藏着构造和析构函数都将无法消除
那我们应该怎样尽可能的减少它所带来的开销呢?
考虑 rational(有理数)类的成员函数 operator*
class Rational {
public:
Rational(int numerator = , int denominator = );
...
int numerator() const;
int denominator() const;
};
const Rational operator*(const Rational& lhs,
const Rational& rhs);
Rational operator*(const Rational& lhs,const Rational& rhs){
Rational result(lhs.getNumerator()*rhs.getNumerator()+lhs.getDenominator()+rhs.getDenominator());
return result;//result是Rational类型的对象,用于存储结果
}
由于operator*要返回一个Rational对象,那么就涉及到临时对象的构造和析构问题:调用operator*时,编译器需要构造一个临时的Rational对象用于存储result的内容(因为程序一operator*的作用域result就被销毁),相应的也需要适时销毁该临时对象,这就导致了额外的成本.
那么我们会想到,返回指针和引用可以吗,其实返回指针和引用是一种非常不好的习惯.如果返回的指针指向非static对象,那么当函数调用结束后,该指针会指向一个被销毁的对象,任何企图通过指针访问其指向的内存的行为都会导致程序错误;如果函数返回的是堆(heap)对象,那么就增加了额外的手动释放内存的负担.因此应尽量避免令函数返回指针.返回引用的缺点类似
其实这些问题,我们的编译器已经帮我们解决过,那就是大多数编译器都具有的方法---RVO(返回值优化)
如果函数返回匿名对象,那么函数就有可能避免临时对象的构造,也就是说当opreator*这样实现的话
const Rational operator*(const Rational& lhs,
const Rational& rhs)
{
return Rational(lhs.numerator() * rhs.numerator(),
lhs.denominator() * rhs.denominator());
}
函数返回一个临时对象就传达给编译器这样一个信息:允许编译器在合适的时候采取RVO优化(消除临时对象的狗仔和析构成本)
仔细观察被返回的表达式。它看上去好象正在调用 Rational 的构造函数,实际上确是这样。你通过这个表达式建立一个临时的 Rational 对象,并且这个临时对象,函数把它拷贝给函数的返回值,以construction arguments取代局部对象,但是你还是必须得为函数内的临时对象的构造和析构付出代价
Rational a = ;
Rational b(, );
Rational c = a * b;
当你再次调用 Rational c = a * b时,编译器就会被允许消除在 operator*内的临时变量和 operator*返回的临时变量。它们能在为目标 c 分配的内存里构造 return 表达式定义的对象。如果你的编译器这样去做,调用 operator*的临时对象的开销就是零:没有建立临时对象。你的代价就是调用一个构造函数――建立 c 时调用的构造函数。而且你不能比这做得更好了,因为 c 是命名对象,命名对象不能被消除(参见条款 M22)。不过你还可以通过把函数声明为 inline 来消除 operator*的调用开销
inline const Rational operator*(const Rational& lhs,
const Rational& rhs)
{
return Rational(lhs.numerator() * rhs.numerator(),
lhs.denominator() * rhs.denominator());
}
条款21 利用重载技术(overload)避免隐式类型转换(implicit type conversion)
看下面的代码
class UPInt { // unlimited precision
public: // integers 类
UPInt();
UPInt(int value);
...
};
//有关为什么返回值是 const 的解释,参见 EffectiveC++ 条款 21
const UPInt operator+(const UPInt& lhs, const UPInt& rhs);
UPInt upi1, upi2;
...
UPInt upi3 = upi1 + upi2;//这个实现没什么惊讶的地方
那么现在看下面
upi3 = upi1 + ;
upi3 = + upi2
如果这两个也能实现的话,说明编译器使用隐式类型转换产生了临时变量,虽然这样很方便,但是避免不了的是临时对象带来的开销,那么我们怎么样才能避免这样的开销呢-----重载技术
我们可以重载opreator+
const UPInt operator+(const UPInt& lhs,const UPInt & rhs);// add UPInt and UPInt
const UPInt operator+(const UPInt& lhs, int rhs); // add UPInt and int
const UPInt operator+(int lhs,const UPInt & rhs); // add int and UPint
const UPInt operator+(int lhs, int rhs);//add int and int
这时我们调用
UPInt upi1, upi2;
UPInt upi3 = upi1 + upi2;
upi3 = upi1 + ;
upi3 = + upi2;
upi3 = + ;
将不会产生临时变量
但是我们要切记,增加一大堆重载函数不见得是件韩式,除非你有好的理由相信,使用重载函数后,程序的整体效率可以得到很大的改善
条款22 考虑以操作符的复合形式(op=)取代其单独形式(op)
单独形式类似于operator+,复合形式类似于opreator+=
如果用operator+=实现opreator+,我们不但可以使用RVO,来减少这个临时变量的开销,使用这种设计方法,只用维护 operator 的赋值形式就行了
class Rational {
public:
...
Rational& operator+=(const Rational& rhs);
Rational& operator-=(const Rational& rhs);
};
operator+=实现opreator+
const Rational operator+(const Rational& lhs,
const Rational& rhs)
{
return Rational(lhs) += rhs;//RVO
}
操作符的复合形式通常比其独身形式效率更高:独身形式需要返回新对象,因而需要承担临时对象的构造和析构成本,复合形式直接将结果写入右端变量,不需要临时对象的构造过程
独立形式
Rational a, b, c, d, result;
...
result = a + b + c + d;//效率没有使用复合形式的效率高,产生了3个临时变量
复合形式
result = a; //不用临时对象
result += b; //不用临时对象
result += c; //不用临时对象
result += d; //不用临时对象
前者(独立形式),同意撰写,调试,维护,并在80%的时间内供应足可接受的性能.后者(复合)效率更高
条款23 考虑使用其他库函数
程序库的设计就是一个折衷的过程.理想的程序库应该是短小的、快速的、强大的、灵活的、可扩展的、直观的、普遍适用的、具有良好的支持、没有使用约束、没有错误的.这也是不存在的.
为尺寸和速度而进行优化的程序库一般不能被移植.
具有大量功能的的程序库不会具有直观性.
没有错误的程序库在使用范围上会有限制.
真实的世界里,你不能拥有每一件东西,总得有付出
例如 stdio 和 iostream
iostream 是类型安全的(type-safe),它是可扩展的
但是stdio的的开销更小且效率更高
这两种库的取舍更在于你侧重,如果程序对I/O效率要求较高,那么stdio是最佳选择,否则,iostream的健壮性和可扩展性可能成为选择它的理由
关于C++比较著名的程序库的介绍,可见:http://www.cnblogs.com/shenlian/archive/2011/08/25/2153826.html
条款24 了解virtual functions/ multiple inheritance/ virtual base class/ runtime type identification的成本 一 vtbls和vptrs
某些特性语言的实现可能对其对象的大小和其member functions 的执行速度将带来一些冲击,这种冲击的典型就是虚函数
大部分编译器实现虚函数的方式为 vtbls和vptrs
vtbls通常是由一个"函数指针"架构而成的数组,某些编译器会以链表代替数组,但是基本策略基本相同
vptrs是负责连接class于其vtbls(指向虚函数表的指针)
定义一个类
class C1 {
public:
C1();
virtual ~C1();
virtual void f1();
virtual int f2(char c) const;
virtual void f3(const string& s);
void f4() const;
...
};
它的虚函数表应该是这样

f4由于不是虚函数 所以不在表中,构造函数同理
现有C2继承C1
class C2: public C1 {
public:
C2(); // 非虚函数
virtual ~C2(); // 重定义函数
virtual void f1(); // 重定义函数
bbs.theithome.com
virtual void f5(char *str); // 新的虚函数
...
};
则C2的虚函数表为

C2的虚函数表中应该含有其重载于C1的虚函数,其自身定义的虚函数,和从C1继承下来的虚函数
你必须为每个包含虚函数的类的 virtualtalbe 留出空间。类的 vtbl 的大小与类中声明的虚函数的数量成正比(包括从基类继承的虚函数),通常情况下vtbls占用的内存并不打,如果class中含有大量的虚汗数,那将是一笔不小的开销
问题来了,编译器把虚函数表放哪里了
编译器对虚函数表的存放一般采取两种策略
1以一种暴力方式的做法:为每一个可能需要 vtbl 的 object 文件生成一个 vtbl 拷贝。连接程序然后去除重复的拷贝,在最后的可执行文件或程序库里就为每个 vtbl 保留一个实例
2.更为常见的一种做法是 勘探式做法:要在一个 object 文件中生成一个类的 vtbl,要求该 object 文件包含该类的第一个非内联、非纯虚拟函数(non-inline non-pure virual function)定义(也就是类的实现体)
因此上述 C1 类的 vtbl 将被放置到包含 C1::~C1 定义的 object 文件里(不是内联的函数),C2 类的 vtbl 被放置到包含 C1::~C2 定义的 object 文件里(不是内联函数)
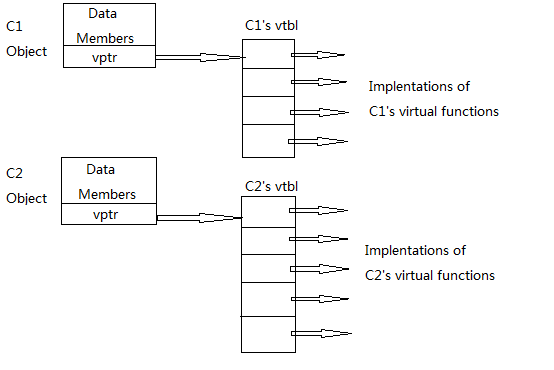
我们可以把一个拥有虚函数的对象的内存布局想象如下

我们一定会注意到,每一个拥有虚函数的对象必须付出一个"额外指针"的代价
4字节的vptr导致的对象大小膨胀所产生的影响可大可小(与对象大小和运行平台等相关),但较大的对象往往意味着较难塞入一个缓存分页(cache page)或虚内存分页(virtual memory page),也就意味着换页(paging)活动可能会增加
综合上述,object和vtbl的关系可能像这样
那么我考虑下面的函数
void makeACall(C1 *pC1)
{
pC1->f1();
}
为了实现上面的调用,我们的编译器必须帮我们完成以下动作
1. 通过对象的 vptr 找到类的 vtbl。这是一个简单的操作,因为编译器知道在对象内哪里能找到 vptr(毕竟是由编译器放置的它们).因此这个代价只是一个偏移调整(以得到vptr)和一个指针的间接寻址(以得到 vtbl).
2. 找到对应 vtbl 内的指向被调用函数的指针(在上例中是 f1).这也是很简单的,因为编译器为每个虚函数在 vtbl 内分配了一个唯一的索引。这步的代价只是在 vtbl 数组内的一个偏移.
3. 调用2找到的的指针所指向的函数
如果我们假设每个对象有一个隐藏的数据叫做 vptr,而且 f1 在 vtbl 中的索引为 i,那么先前的语句应该为
(*pC1->vptr[i])(pC1); //调用被 vtbl 中第 i 个单元指向的函数,而 pC1->vptr指向的是 vtbl;pC1 被做为 this 指针传递给函数
在实际运行中,虚函数所需的代价与内联函数有关.实际上虚函数不能是内联的。这是因为“内联”是指“在编译期间用被调用的函数体本身来代替函数调用的指令,”但是虚函数的“虚”是指“直到运行时才能知道要调用的是哪一个函数.”如果编译器在某个函数的调用点不知道具体是哪个函数被调用,你就能知道为什么它不会内联该函数的调用。这是虚函数所需的第三个代价:你实际上放弃了使用内联函数.(当通过对象调用虚函数时,它可以被内联,但是大多数虚函数是通过对象的指针或引用被调用的,这种调用不能被内联。因为这种调用是标准的调用方式,所以虚函数实际上不能被内联.)
二 多重继承
多继承经常导致对虚基类的需求。没有虚基类,如果一个派生类有一个以上从基类的继承路径,基类的数据成员被复制到每一个继承类对象里,继承类与基类间的每条路径都有一个拷贝。程序员一般不会希望发生这种复制,而把基类定义为虚基类则可以消除这种复制。然而虚基类本身会引起它们自己的代价,因为虚基类的实现经常使用指向虚基类的指针做为避免复制的手段,一个或者更多的指针被存储在对象里
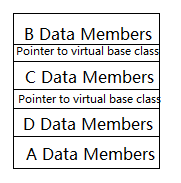
考虑下面代码(多重菱形)
class A{...};
class B:virtual public A{...};
class C:virtual public A{...};
class D:pulic B,public C{...};
A是个虚基类,B和C都采用虚继承,在某些编译器下,D对象的内存布局可能如下
在没有虚函数参与的情况下,如果A类有虚函数,那么D的布局类似这样

一个奇怪之处在于明明有4个类,却只有三个vptr,原因在于B和D可以共享同一个vptr,大多数编译器会采取此策略
三 RTTI(运行时动态识别)
RTTI使得可以在运行时获得objects和classes的相关信息,因此其实现必须需要一些内存来存储那些信息:类型信息用type_info类型的对象存放,可以用typeid操作符取得class对应的type_info对象
一个类只需要一份RTTI信息,但必须要使得属于这个类的每个对象都能够取得该信息,这和vtbl的要求相同,因此RTTI的的设计理念便是根据class的vtbl来实现.通常在vtbl索引为0的元素存放一指针,用来指向"该vtbl所对应的class"的相应的 type_info对象,因此2中的C1的vtbl实际上可能像这样

使用这种实现方法,RTTI 耗费的空间是在每个类的 vtbl 中的占用的额外单元再加上存储 type_info 对象的空间.就象在多数程序里 virtual table 所占的内存空间并不值得注意一样,你也不太可能因为 type_info 对象大小而遇到问题
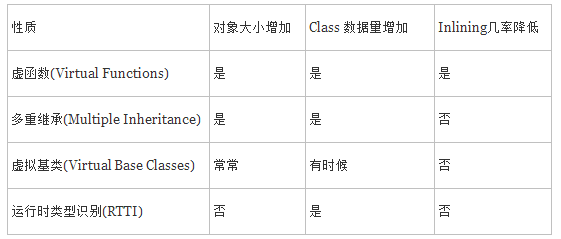
四 虚函数,多重继承,虚拟基类和RTTI的主要成本摘要
MoreEffectiveC++Item35(效率)(条款16-24)的更多相关文章
- MoreEffectiveC++Item35(异常)(条款9-15)
条款9 使用析构函数防止内存泄漏 条款10 在构造函数中防止内存泄漏 条款11 禁止异常信息传递到析构函数外 条款12 理解"抛出一个异常''与"传递一个参数"或调用一个 ...
- MoreEffectiveC++Item35(操作符)(条款5-8)
条款5 对定制的"类型转换函数"保持警惕 条款6 区别increment/decrement操作符的前值和后置形式 条款7 千万不要重载&&,||,和,操作符 条款 ...
- EC读书笔记系列之9:条款16、17
条款16 成对使用new和delete时要采取相同形式 记住: ★若你在new表达式中使用[ ],必须在相应的delete中也使用[ ],反之亦然 -------------------------- ...
- effctive C++ 读书笔记 条款 16
条款16 成对使用new和delete时要採取同样形式 #include <iostream> #include <string> using namespace std; / ...
- MoreEffectiveC++Item35(基础议题)(条款1-4)
条款1:区别指针和引用 条款2:最好使用C++转换操作符 条款3: 绝对不要以多态的方式处理数组 条款4: 避免无用的缺省构造函数 条款1:区别指针和引用 1.指针(pointer) 使用[*/-&g ...
- MoreEffectiveC++Item35 条款27: 要求或禁止对象产生于heap中
一 要求对象产生在heap中 阻止对象产生产生在non-heap中最简单的方法是将其构造或析构函数声明在private下,用一个public的函数去调用起构造和析构函数 class UPNumber ...
- MoreEffectiveC++Item35 条款26: 限制某个class所能产生的对象个数
一 允许零个或一个对象 我们知道每当即将产生一个对象,我们有一个constructor被调用,那么我们现在想组织某个对象的产生,最简单的方法就是将其构造函数声明成private(这样做同事防止了这个类 ...
- MoreEffectiveC++Item35 条款25 将constructor和non-member functions虚化
1.virtual constructor 在语法上是不可将构造函数声明成虚函数,虚函数用于实现"因类型而异的行为",也就是根据指针或引用所绑定对象的动态类型而调用不同实体.现在所 ...
- Linux-IP地址后边加个/8(16,24,32)是什么意思?
是掩码的位数 A类IP地址的默认子网掩码为255.0.0.0(由于255相当于二进制的8位1,所以也缩写成“/8”,表示网络号占了8位); B类的为255.255.0.0(/16) ...
随机推荐
- HCNP学习笔记之PXE原理详解及实践
一.PXE简介 PXE(preboot execute environment,预启动执行环境)是由Intel公司开发的最新技术,工作于Client/Server的网络模式,支持工作站通过网络从远端服 ...
- axios配置大全
一.安装 1. 利用npm安装npm install axios --save 2. 利用bower安装bower install axios --save 3. 直接利用cdn引入<scrip ...
- saltstack之haproxy的安装配置
使用saltstack编译安装haproxy: 由于编译安装haproxy,所以安装之前需要建立编译环境,将编译环境需要安装的包单独放置在一个目录中,当编译haproxy或其他时,直接include这 ...
- 20145313张雪纯 《Java程序设计》第1周学习总结
20145313 <Java程序设计>第1周学习总结 教材学习内容总结 java有三大平台,分别为Java SE(J2SE).Java EE(J2EE).Java ME(J2 ME). J ...
- 20145314郑凯杰 《Java程序设计》第8周学习总结
20145314郑凯杰 <Java程序设计>第8周学习总结 教材学习内容总结 代码已托管 第十五章 通用API ①日志: 日志对信息安全意义重大,审计.取证.入侵检测等都会用到日志信息 使 ...
- Ubuntu 下安装Beyond Compare【转】
本文转载自:https://blog.csdn.net/bingyu9875/article/details/52856675 官网下载安装包:http://www.scootersoftware.c ...
- Rank - 第二类斯特灵数
2017-08-10 20:32:37 writer:pprp 题意如下: Recently in Teddy's hometown there is a competition named &quo ...
- cocos2d-x入门二 helloworld实例运行与创建
本机环境:win7+VS2012+python2.7.8+cocos2d-x-3.8,另外本机已经配置android开发环境(java+eclipse+SDK+ADT),针对环境搭建后续会有一篇详细说 ...
- ***使用jQuery去封装插件(组件化、模块化的思想),即扩展方法
如何使用jQuery去封装插件,区分扩展全局方法与扩展一个普通的jQuery实例对象的方法 1.给全局对象扩展方法:①$.方法 = function(参数可加可不加){} ②使用:$.方法(有参数的 ...
- redis——redis主从复制
和MySQL主从复制的原因一样,Redis虽然读取写入的速度都特别快,但是也会产生读压力特别大的情况.为了分担读压力,Redis支持主从复制,Redis的主从结构可以采用一主多从或者级联结构,Redi ...