pig(数据流语言和编译器)学习https://www.w3cschool.cn/apache_pig/apache_pig_execution.html
当我们配置了hadoop集群执行的时候
可以通过命令ls进行查看
存储语法
STORE Relation_name INTO ' required_directory_path ' [USING function];
STORE student INTO ' hdfs://localhost:9000/pig_Output/ ' USING PigStorage (',');
练习
可以先写一个run.pig脚本,文件内容为下面例子的全部过程,(w3school看store 保存数据到文件中),包装好后,
放入一个.sh文件里去执行.sh文件内容,(.sh文件里的内容要写
#!/usr/bin/env bash 必须要写
source /home/hadoop/.profile 避免没有执行配置文件
pig -x local run.pig
)
然后可以在crontab -e里进行操作(还可以再加一层,python调用shell,当然要加上python执行命令的路径配上#!)
定时后面直接跟 run.sh 记得写全部run.sh的路径
py文件写入内容为
Shell 命令
Apache Pig的Grunt shell主要用于编写Pig Latin脚本。在此之前,我们可以使用 sh 和 fs 来调用任何shell命令。
sh 命令 可以看到本地Linux文件内容
使用 sh 命令,我们可以从Grunt shell调用任何shell命令,但无法执行作为shell环境( ex - cd)一部分的命令。
语法
下面给出了 sh 命令的语法
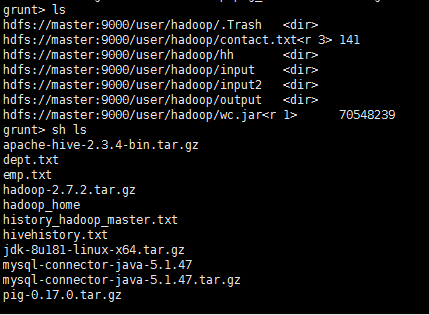
输入fs -ls命令查看详细
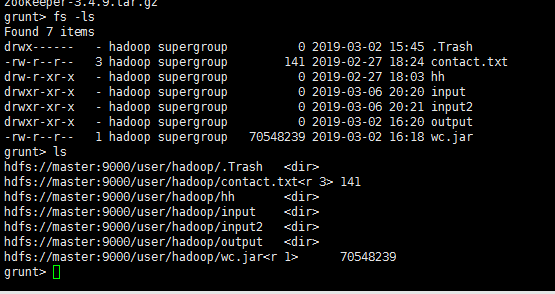
使用方法命令
pig -x local 本地模式启动
(所有文件和执行过程都在本地,一般用于测试程序)
pig -x mapreduce 集群启动
在本地模式下可以运行
pig -x local
sh /home/hadoop/hadoop_home/jdk1.8.0_181/bin/jps
可以执行
一定不要忘的是开启任务历史
开启任务历史
mr-jobhistory-daemon.sh start historyserver
Pig数据模型
Bag:表
Tuple:行,记录
Field:属性
Pig不要求同一个bag里的哥哥tuple有相同数量或者相同类型的field
PigLatin
Load:载入数据的方法
foreach:逐行扫描进行某种处理
filter:过滤行
dump:把结果显示到屏幕
store:把结果保存到文件
一个实例:为天气温度数据集编写脚本计算一年中的最高纪录(本例是在MapReduce下面一条条运行)
pig -x mapreduce
records = load ‘/user/hadoop/input5/temperature.txt’ USING PigStorage('\t') as (year:chararray,temperature:int); 使用\t进行分割
dump records;
describe records;
valid_records = filter records by temperature!=999;过滤掉不合法数值
grouped_records = group valid_records by year;按照年份分组
dump grouped_records;打印信息
describe grouped_records;描述信息(这时候从下面描述信息可以看到,给分组起了别名group,对应的数据为分组字段内容,第二个字段和被分组的关系结构相同)
上述分组过程分了两个元组,每个元组对应于输入数据中的一个年度,每个元组的第一个字段是用于进行分组的字段即年度,第二个字段是该年度的元组的包,包是元组的无序集,包用大括号表示,元组用括号,(map键值对是中括号)
例: (grouped_records:{group : chararray,valid_records : {year:chararray,temperature : int,quality :int}})
max_temperature = foreach grouped_records generate group,MAX(valid_records.temperature); 找出每个年份最大的温度值,foreach放入max里,放的是一个类似集合
--备注:valid_records是字段名,在上一语句的describe命令结果中可以查看到group_records 的具体结构。
dump max_temperature;
上述操作过程很重要的一点是:只有dump 或者descrip 描述的时候才会执行,之前的group 等等语句,只是把他们加入到逻辑计划中,pig开始执行的是dump 语句,此时逻辑计划被编译成物理计划
最终结果为:

或者将其放在一个文件里面去执行
pig -x mapreduce test.pig


第二个例子,统计每个ip的出现次数
数据源,网站log文件,已经上传到hdfs

grunt> A = LOAD ' /user/hadoop/input6/web.log' USING PigStorage(' ') AS (ip,others);
grunt> B = FOREACH A GENERATE ip;
grunt> C = FOREACH (GROUP B BY ip) GENERATE group AS ip,COUNT(B) as amount ;
grunt> E = ORDER C by amount DESC,ip;
grunt> DUMP E;
(218.20.24.203,4597)
(221.194.180.166,4576)
(119.146.220.12,1850)
(117.136.31.144,1647)
(121.28.95.48,1597)
(113.109.183.126,1596)
以下SQL在Pig中的实现refer to http://guoyunsky.iteye.com/blog/1317084
我这里以Mysql 5.1.x为例,Pig的版本是0.17
同时我将数据放在了两个文件,存放在/tmp/data_file_1和/tmp/data_file_2中.文件内容如下:
tmp_file_1:
Txt代码
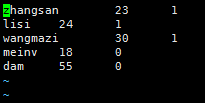
- zhangsan 23 1
- lisi 24 1
- wangmazi 30 1
- meinv 18 0
- dama 55 0
tmp_file_2:
Txt代码
- 1 a
- 23 bb
- 50 ccc
- 30 dddd
- 66 eeeee
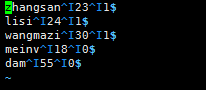
vim tmp_file_1
末行模式:set list
1.从文件导入数据
1)Mysql (Mysql需要先创建表).
CREATE TABLE TMP_TABLE(USER VARCHAR(32),AGE INT,IS_MALE BOOLEAN);
CREATE TABLE TMP_TABLE_2(AGE INT,OPTIONS VARCHAR(50)); -- 用于Join
LOAD DATA LOCAL INFILE '/tmp/data_file_1' INTO TABLE TMP_TABLE ;
LOAD DATA LOCAL INFILE '/tmp/data_file_2' INTO TABLE TMP_TABLE_2;
2)Pig
tmp_table = LOAD '/tmp/data_file_1' USING PigStorage('\t') AS (user:chararray, age:int,is_male:int);
tmp_table_2= LOAD '/tmp/data_file_2' USING PigStorage('\t') AS (age:int,options:chararray);
2.查询整张表
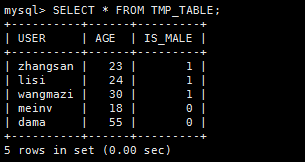
1)Mysql
SELECT * FROM TMP_TABLE;
2)Pig
DUMP tmp_table;

3. 查询前50行
1)Mysql
SELECT * FROM TMP_TABLE LIMIT 50;
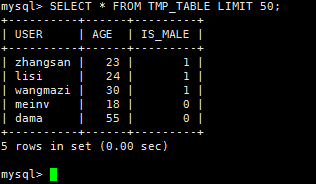
2)Pig
tmp_table_limit = LIMIT tmp_table 50;
DUMP tmp_table_limit;

4.查询某些列
1)Mysql
SELECT USER FROM TMP_TABLE;
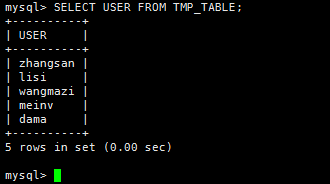
2)Pig
tmp_table_user = FOREACH tmp_table GENERATE user;
DUMP tmp_table_user;

5. 给列取别名
1)Mysql
SELECT USER AS USER_NAME,AGE AS USER_AGE FROM TMP_TABLE;

2)Pig
tmp_table_column_alias = FOREACH tmp_table GENERATE user AS user_name,age AS user_age;
DUMP tmp_table_column_alias;

6.排序
1)Mysql
SELECT * FROM TMP_TABLE ORDER BY AGE;

2)Pig
tmp_table_order = ORDER tmp_table BY age ASC;
DUMP tmp_table_order;

7.条件查询
1)Mysql
SELECT * FROM TMP_TABLE WHERE AGE>20;
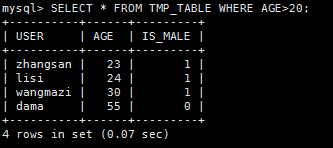
2) Pig
tmp_table_where = FILTER tmp_table by age > 20;
DUMP tmp_table_where;

8.内连接Inner Join
1)Mysql
SELECT * FROM TMP_TABLE A JOIN TMP_TABLE_2 B ON A.AGE=B.AGE;
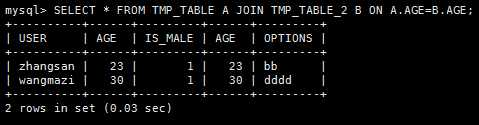
2)Pig
tmp_table_inner_join = JOIN tmp_table BY age,tmp_table_2 BY age;
DUMP tmp_table_inner_join;

9.左连接Left Join
1)Mysql
SELECT * FROM TMP_TABLE A LEFT JOIN TMP_TABLE_2 B ON A.AGE=B.AGE;
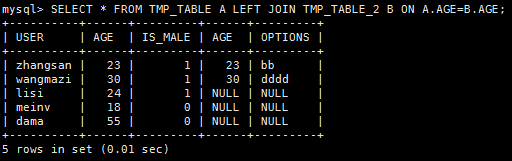
2)Pig
tmp_table_left_join = JOIN tmp_table BY age LEFT OUTER,tmp_table_2 BY age;
DUMP tmp_table_left_join;
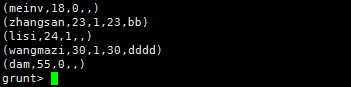
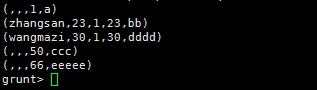
10.右连接Right Join
1)Mysql
SELECT * FROM TMP_TABLE A RIGHT JOIN TMP_TABLE_2 B ON A.AGE=B.AGE;

2)Pig
tmp_table_right_join = JOIN tmp_table BY age RIGHT OUTER,tmp_table_2 BY age;
DUMP tmp_table_right_join;
11.全连接Full Join
1)Mysql
SELECT * FROM TMP_TABLE A JOIN TMP_TABLE_2 B ON A.AGE=B.AGE
UNION SELECT * FROM TMP_TABLE A LEFT JOIN TMP_TABLE_2 B ON A.AGE=B.AGE
UNION SELECT * FROM TMP_TABLE A RIGHT JOIN TMP_TABLE_2 B ON A.AGE=B.AGE;
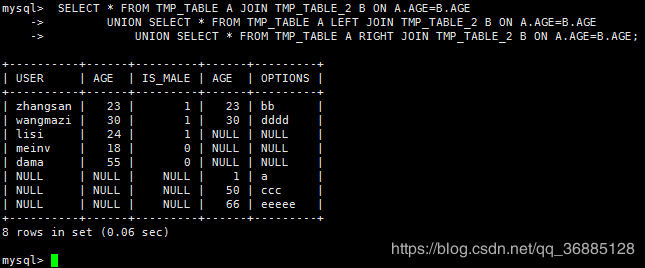
2)Pig
tmp_table_full_join = JOIN tmp_table BY age FULL OUTER,tmp_table_2 BY age;
DUMP tmp_table_full_join;

12.同时对多张表交叉查询
1)Mysql
SELECT * FROM TMP_TABLE,TMP_TABLE_2;
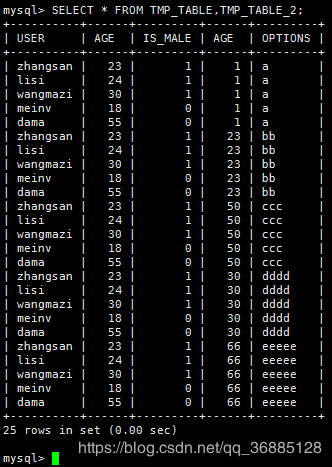
2)Pig
tmp_table_cross = CROSS tmp_table,tmp_table_2;
DUMP tmp_table_cross;

13.分组GROUP BY
1)Mysql
SELECT * FROM TMP_TABLE GROUP BY IS_MALE;
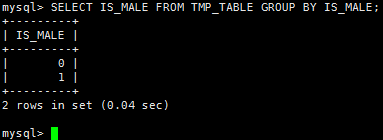
2)Pig
tmp_table_group = GROUP tmp_table BY is_male;
DUMP tmp_table_group;

14.分组并统计
1)Mysql
SELECT IS_MALE,COUNT(*) FROM TMP_TABLE GROUP BY IS_MALE;

2)Pig
tmp_table_group_count = GROUP tmp_table BY is_male;
tmp_table_group_count = FOREACH tmp_table_group_count GENERATE group,COUNT($1);--(第n个字段,以0开始)
DUMP tmp_table_group_count;
15.查询去重DISTINCT
1)MYSQL
SELECT DISTINCT IS_MALE FROM TMP_TABLE;
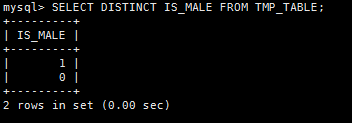
2)Pig
tmp_table_distinct = FOREACH tmp_table GENERATE is_male;
tmp_table_distinct = DISTINCT tmp_table_distinct;
DUMP tmp_table_distinct;

16split用法
SPLIT 运算符用于将关系拆分为两个或多个关系。
student_details = LOAD 'hdfs://localhost:9000/pig_data/student_details.txt' USING PigStorage(',')
as (id:int, firstname:chararray, lastname:chararray, age:int, phone:chararray, city:chararray);
现在,让我们将关系分为两个,一个列出年龄小于23岁的员工,另一个列出年龄在22到25岁之间的员工。
SPLIT student_details into student_details1 if age<23, student_details2 if (22<age and age>25);
https://www.cnblogs.com/dadadechengzi/p/6718112.html
Pig适用场景
Pig并不适合所有的数据处理任务,和MapReduce一样,它是为数据批处理而设计的,如果想执行的查询只涉及一个大型数据集的一小部分数据,Pig的实现不会很好,因为它要扫描整个数据集或其中很大一部分。
随着新版本发布,Pig的表现和原生MapRedece程序差距越来越小,因为Pig的开发团队使用了复杂、精巧的算法来实现Pig的关系操作。除非你愿意花大量时间来优化Java MapReduce程序,否则使用Pig Latin来编写查询的确能帮你节约时间。
附录:
执行Pig程序的方法
- 脚本:Pig可以运行包含Pig命令的脚本文件,例如,pig script.pig,对于很短的脚本可以通过使用-e选项直接在命令行中输入脚本字符串。
- Grunt:Pig shell,就是上文的运行模式
- 嵌入式方法:也可以在Java中运行Pig程序,和使用JDBC运行SQL程序很像,详情:https://wiki.apache.org/pig/EmbeddedPig
Pig与RDBMS、Hive比较
- Pig Latin是一种数据流编程语言,而SQL是一种描述性编程语言。换句话说,Pig程序是相对于输入的一步步操作,其中每一步是对数据的一个简答的变换。相反,SQL语句是一个约束的集合,这些约束的集合在一起,定义了输出。
- 示例也可以看出,Pig其实是对Java的Mapreduce的封装,进一步的抽象,运行的也是java程序,并在此基础上提供其他特性。
- Hive介于Pig和传统RDBMS(关系数据库管理系统Relational Database Management System)之间,Hive的设计目的是让精通SQL既能的分析师能够在存放在HDFS的大规模数据集上运行查询。
- Hive在很多方面和传统数据库类似,但是它底层对HDFS和MapReduce的依赖意味着它的体系结构有别于传统数据库。
- Hive本身不存储数据,完全依赖于HDFS和MapReduce,Hive可以将结构化的数据文件映射为一张数据库表,Hive中表纯逻辑,就是表的元数据。而HBase是物理表,定位是NoSQL。
pig也可以用table补全
ctr+E光标已到行末
ctr+P和ctr+N查看历史命令(或者上下光标)
quit命令结束
group函数进行分组,多个元组
注释用-- 双减号,单行注释,pig Latin 会忽略从第一个减号开始到行尾的内容
多行注释:/* */
dump是一个诊断工具,因此它总是会触发语句的执行,


有两个命令可以运行pig脚本,exec和run
它们的区别是exec在一个新的grunt外壳程序中以批处理的方式运行脚本,因此所有脚本中定义的别名在脚本运行后不能在外壳程序中再被访问。另一方面,如果用run运行脚本,那么效果就和在外壳中手工输入脚本吗的内容是一样的。因此运行该脚本的外壳的命令历史中包含脚本的所有语句。只有用exec进行多查询执行,即pig以批处理方式一次执行一批语句(详见多查询执行)。不能用run命令进行多查询执行

在UDF(用户定义函数)里面
pig把函数名作为java类名并试图用该类名来加载类以完成函数调用(这也是为什么函数名是大小写敏感的,因为java类名是大小写敏感度),在搜索类的时候pig会使用包含已注册jar文件的类加载器,运行与分布式模式时,pig会确保jar文件传输到集群
pig能使用java类打包后的全名通过注册的jar文件找到,
而内置函数是pig自己搜索内置包(例如MAX函数是org.apache.pig.builtin.MAX,但是并不想写全),可以通过在调用grunt命令行参数
-Dudf.import.list=com.hadoopbook.pig
把我们的包加入到内置包搜索路径里
或者用define命令,为函数定义别名
define isGood com.hadoopbook.pig.IsGoodQuality();
这样就可以直接用isGood代替完整函数名了(在一个脚本里多次使用一个函数时,定义别名是一个好方法,如果要向UDF传递参数,必须定义别名)
pig(数据流语言和编译器)学习https://www.w3cschool.cn/apache_pig/apache_pig_execution.html的更多相关文章
- 小猿圈-IT自学人的小圈子 https://book.apeland.cn/details/54/
笔记链接 https://book.apeland.cn/details/54/ 学习视频 https://www.apeland.cn/python
- 项目管理软件伙伴https://www.huobanyun.cn/
现在项目管理软件市面上很多,但能够完全适合每家公司需求的比较难找,因为众口难调,每家公司都有自己的特殊情况,所以,建议考虑下有比较齐全的基础功能的标准化软件产品,同时又在项目管理开发能力上比较突出. ...
- Google机器学习课程基于TensorFlow : https://developers.google.cn/machine-learning/crash-course
Google机器学习课程基于TensorFlow : https://developers.google.cn/machine-learning/crash-course https ...
- https://www.52pojie.cn/thread-688820-1-1.html
https://www.52pojie.cn/thread-688820-1-1.html
- 资源下载https://msdn.itellyou.cn/
资源下载https://msdn.itellyou.cn/ 迅雷
- 当中台遇上DDD,我们该如何设计微服务? - InfoQ https://www.infoq.cn/article/7QgXyp4Jh3-5Pk6LydWw
当中台遇上DDD,我们该如何设计微服务? - InfoQ https://www.infoq.cn/article/7QgXyp4Jh3-5Pk6LydWw
- 【Azure Developer】Azure Graph SDK获取用户列表的问题: SDK中GraphServiceClient如何指向中国区的Endpoint:https://microsoftgraph.chinacloudapi.cn/v1.0
问题描述 想通过Java SDK的方式来获取Azure 门户中所列举的用户.一直报错无法正常调用接口,错误信息与AAD登录认证相关,提示tenant not found. 想要实现的目的,通过代码方式 ...
- 【新人福利】使用CSDN 官方插件,赠永久免站内广告特权 >>电脑端访问:https://t.csdnimg.cn/PVqS
[新人福利]使用CSDN 官方插件,赠永久免站内广告特权 >>电脑端访问:CSDN开发助手 [新人福利]使用CSDN 官方插件,赠永久免站内广告特权 >>电脑端访问:https ...
- mdk编译器学习笔记(1)——序
这两天,学习了keil-mdk编译器的特性,这基本上独立于c语言语法,平时基本上都在强调c语言的学习,但是编译器的学习我们也要注重,类似于gcc一样,不也有很多网上的资料,讲述gcc的特性和用法吗.作 ...
随机推荐
- sed、grep、awk -- 三剑客笔记记录
sed常用操作笔记 1.删除文件最后一行: sed -i '$d' filename 2.递归替换内容:sed -i 's/内容A/内容B/g' filename sed -i "s/S ...
- ubuntu安装Theano+cuda
由于学习需要用到GPU加速机器学习算法,需要安装theano+cuda. 开源库的一大问题就是:难安装. 为了搞好这个配置,我是前前后后花了3天,重装了3次ubuntu重装了5次驱动才搞定. 故发此贴 ...
- 深入浅出 Java Concurrency (15): 锁机制 part 10 锁的一些其它问题
主要谈谈锁的性能以及其它一些理论知识,内容主要的出处是<Java Concurrency in Practice>,结合自己的理解和实际应用对锁机制进行一个小小的总结. 首先需要强调的 ...
- 机器学习,数据挖掘,统计学,云计算,众包(crowdsourcing),人工智能,降维(Dimension reduction)
机器学习 Machine Learning:提供数据分析的能力,机器学习是大数据时代必不可少的核心技术,道理很简单:收集.存储.传输.管理大数据的目的,是为了“利用”大数据,而如果没有机器学习技术分析 ...
- 归纳一下:C#线程同步的几种方法
转自原文 归纳一下:C#线程同步的几种方法 我们在编程的时候,有时会使用多线程来解决问题,比如你的程序需要在后台处理一大堆数据,但还要使用户界面处于可操作状态:或者你的程序需要访问一些外部资源如数据库 ...
- Java安全框架 Apache Shiro学习-1-ini 配置
简单登录流程: 1. SecurityManager 2. SecurityUtils.setSecurityManager 3. SecurityUtils.getSubject ...
- java反射(Field的应用)
//$Id: DirectPropertyAccessor.java 11405 2007-04-15 12:50:34Z max.andersen@jboss.com $ package org.h ...
- 深入探究jvm之GC的参数调优
在上一篇博客记录了GC的算法及种类,这篇博客主要记录一下GC的参数如何调整以提高jvm的性能. 一.堆的回顾: 堆的内存空间总体分为新生代和老年代,老年代存放的老年对象,新构造的对象分配在eden区中 ...
- 前面部分(WCF全面解析1)
WCF全面解析 [同力推荐] 我经历了COM时代,一直把Don BOx的<COM本质论>奉为我的指路明灯.能把SOA机理和WCF这种特定厂商实现的技术讲得如<COM本质论>一样 ...
- built-in SpecularType of Unity
[built-in SpecularType of Unity] 1.声明变量. 注意并没有在Shader中声明_SpecColor,因为Lighting.cginc中已经帮我们声明. 2.声明使用B ...