python的scrapy框架
scrapy是python中数据抓取的框架。简单的逻辑如下所示
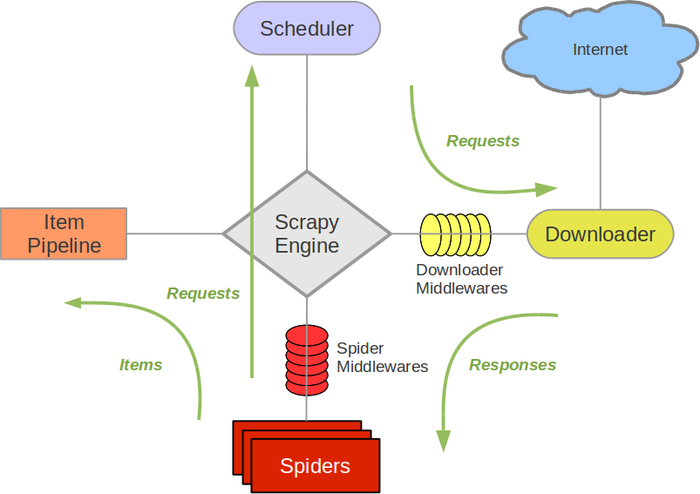
scrapy的结构如图所示,包括scrapy engine、scheduler、downloader、spider、item pipeline。
scrapy engine:引擎,是负责scheduler、downloader、spider、item pipeline之间的消息的传递等等
scheduler:调度器,是负责接受scrapy engine 的request请求,并将request进行整理排列,入队,等待scrapy engine来请求时,交给引擎
downloader:下载器,是用来下载scrapy engine的请求,并将response返回给spider。
spider:爬虫,是将downloader的response,由spider分析并提取item所要抓取的数据,并将所要跟进的url再次交给scrapy engine,再次进入scheduler。
item pipeline:项目管道,是将spider中提取到的数据,进行处理,存储。
还有两个:
download middlewares:下载中间件,是一个可以扩展的下载功能的组件,介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应
spider middlewares:spider的中间件:是一个可以扩展和操作引擎和spider中间通信的功能组件(比如进入spider的response,和从spider传出去的request),介于Scrapy引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出
这俩当前还没有试过~
经过:
1.scrapy engine获取到spider要获取的第一个url
2.scrapy engine将要获取的url给scheduler,并将url入队,整理,并将处理好的request请求返回
3.scrapy engine将处理好的request给downloader,通过downloader下载数据,如果下载失败,会将下载失败的结果告诉scrapy engine,然后会让scrapy engine等会再次请求下载。
4.scrapy engine获取到downloader下载的数据,并且将数据给spider,经由spider进行数据处理,spider将需要跟进的request交给scrapy engine,将处理的结果返回给item pipeline
5.item pipeline将spider反悔的结果进行去重,持久化,写入数据库等操作。
只有当scheduler中没有任何request了,整个过程才会停止。
python的scrapy框架的更多相关文章
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- Python爬虫Scrapy框架入门(1)
也许是很少接触python的原因,我觉得是Scrapy框架和以往Java框架很不一样:它真的是个框架. 从表层来看,与Java框架引入jar包.配置xml或.property文件不同,Scrapy的模 ...
- Python爬虫Scrapy框架入门(0)
想学习爬虫,又想了解python语言,有个python高手推荐我看看scrapy. scrapy是一个python爬虫框架,据说很灵活,网上介绍该框架的信息很多,此处不再赘述.专心记录我自己遇到的问题 ...
- Python使用Scrapy框架爬取数据存入CSV文件(Python爬虫实战4)
1. Scrapy框架 Scrapy是python下实现爬虫功能的框架,能够将数据解析.数据处理.数据存储合为一体功能的爬虫框架. 2. Scrapy安装 1. 安装依赖包 yum install g ...
- 基于python的scrapy框架爬取豆瓣电影及其可视化
1.Scrapy框架介绍 主要介绍,spiders,engine,scheduler,downloader,Item pipeline scrapy常见命令如下: 对应在scrapy文件中有,自己增加 ...
- Python爬虫-- Scrapy框架
Scrapy框架 Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是事件驱动的,并且比较适合异步的代码.对于会阻塞线程的操作包含访问文件.数据库或者Web.产生新的进程并需要 ...
- Python爬虫 ---scrapy框架初探及实战
目录 Scrapy框架安装 操作环境介绍 安装scrapy框架(linux系统下) 检测安装是否成功 Scrapy框架爬取原理 Scrapy框架的主体结构分为五个部分: 它还有两个可以自定义下载功能的 ...
- python爬虫scrapy框架
Scrapy 框架 关注公众号"轻松学编程"了解更多. 一.简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量 ...
- python安装Scrapy框架
看到自己写的惨不忍睹的爬虫,觉得还是学一下Scrapy框架,停止一直造轮子的行为 我这里是windows10平台,python2和python3共存,这里就写python2.7安装配置Scrapy框架 ...
- Python爬虫Scrapy框架入门(2)
本文是跟着大神博客,尝试从网站上爬一堆东西,一堆你懂得的东西 附上原创链接: http://www.cnblogs.com/qiyeboy/p/5428240.html 基本思路是,查看网页元素,填写 ...
随机推荐
- 洛谷 P4503 [CTSC2014]企鹅QQ 解题报告
P4503 [CTSC2014]企鹅QQ 题目背景 PenguinQQ是中国最大.最具影响力的SNS(Social Networking Services)网站,以实名制为基础,为用户提供日志.群.即 ...
- docker基础学习
docker的定义: Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化.容器是完全使用沙箱机 ...
- Linux内核分析第三周学习博客——跟踪分析Linux内核的启动过程
Linux内核分析第三周学习博客--跟踪分析Linux内核的启动过程 实验过程截图: 过程分析: 在Linux内核的启动过程中,一共经历了start_kernel,rest_init,kernel_t ...
- C++实现人员信息管理系统模拟
利用C++语言实现基本的学生信息管理系统: 要求: 1-设置管理员密码 2-人员数据有:姓名,性别等基本的信息 3-可以添加,删除,保存,统计 #include<iostream> #in ...
- OD常见指令和快捷键
声明: 1.本表来自各论坛.博客,欢迎补充讨论 指令 解释 OD汇编指令 NOP 无操作 PUSH 将数据压如堆栈中 POP 出栈(与PUSH相反) PUSHAD 所有通用寄存器的内容按一定顺序压 ...
- 小程序navigatorTo缺点和修正方法
1.不好带参数跳转到tabbar,即下部的导航栏目. reLauntch方法可以传递参数到导航栏目: go_to_prolist: function (e) { var datatype = e.cu ...
- Python学习笔记(十八)@property
# 请利用@property给一个Screen对象加上width和height属性, # 以及一个只读属性resolution: # -*- coding: utf-8 -*- class Scree ...
- Jugs(回溯法)
ZOJ Problem Set - 1005 Jugs Time Limit: 2 Seconds Memory Limit: 65536 KB Special Judge In ...
- 【CodeForces】915 E. Physical Education Lessons 线段树
[题目]E. Physical Education Lessons [题意]10^9范围的区间覆盖,至多3*10^5次区间询问. [算法]线段树 [题解]每次询问至多增加两段区间,提前括号分段后线段树 ...
- [洛谷P1823]音乐会的等待 题解(单调栈)
[洛谷P1823]音乐会的等待 Description N个人正在排队进入一个音乐会.人们等得很无聊,于是他们开始转来转去,想在队伍里寻找自己的熟人.队列中任意两个人A和B,如果他们是相邻或他们之间没 ...