搞懂分布式技术12:分布式ID生成方案
搞懂分布式技术12:分布式ID生成方案
##
转自: 58沈剑 架构师之路 2017-06-25
一、需求缘起
几乎所有的业务系统,都有生成一个唯一记录标识的需求,例如:
消息标识:message-id
订单标识:order-id
帖子标识:tiezi-id
这个记录标识往往就是数据库中的主键,数据库上会建立聚集索引(cluster index),即在物理存储上以这个字段排序。
这个记录标识上的查询,往往又有分页或者排序的业务需求,例如:
拉取最新的一页消息
select message-id/ order by time/ limit 100
拉取最新的一页订单
select order-id/ order by time/ limit 100
拉取最新的一页帖子
select tiezi-id/ order by time/ limit 100
所以往往要有一个time字段,并且在time字段上建立普通索引(non-cluster index)。
普通索引存储的是实际记录的指针,其访问效率会比聚集索引慢,如果记录标识在生成时能够基本按照时间有序,则可以省去这个time字段的索引查询:
select message-id/ (order by message-id)/limit 100
强调,能这么做的前提是,message-id的生成基本是趋势时间递增的。
这就引出了记录标识生成(也就是上文提到的三个XXX-id)的两大核心需求:
全局唯一
趋势有序
这也是本文要讨论的核心问题:如何高效生成趋势有序的全局唯一ID。
二、常见方法、不足与优化
方法一:使用数据库的 auto_increment 来生成全局唯一递增ID
优点:
简单,使用数据库已有的功能
能够保证唯一性
能够保证递增性
步长固定
缺点:
可用性难以保证:数据库常见架构是一主多从+读写分离,生成自增ID是写请求,主库挂了就玩不转了
扩展性差,性能有上限:因为写入是单点,数据库主库的写性能决定ID的生成性能上限,并且难以扩展
改进方法:
冗余主库,避免写入单点
数据水平切分,保证各主库生成的ID不重复
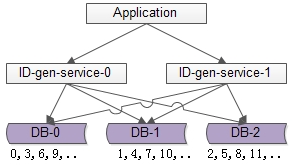
如上图所述,由1个写库变成3个写库,每个写库设置不同的auto_increment初始值,以及相同的增长步长,以保证每个数据库生成的ID是不同的(上图中库0生成0,3,6,9…,库1生成1,4,7,10,库2生成2,5,8,11…)
改进后的架构保证了可用性,但缺点是:
丧失了ID生成的“绝对递增性”:先访问库0生成0,3,再访问库1生成1,可能导致在非常短的时间内,ID生成不是绝对递增的(这个问题不大,目标是趋势递增,不是绝对递增)
数据库的写压力依然很大,每次生成ID都要访问数据库
为了解决上述两个问题,引出了第二个常见的方案。
方法二:单点批量ID生成服务
分布式系统之所以难,很重要的原因之一是“没有一个全局时钟,难以保证绝对的时序”,要想保证绝对的时序,还是只能使用单点服务,用本地时钟保证“绝对时序”。
数据库写压力大,是因为每次生成ID都访问了数据库,可以使用批量的方式降低数据库写压力。
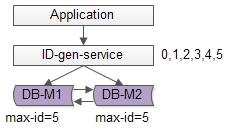
如上图所述,数据库使用双master保证可用性,数据库中只存储当前ID的最大值,例如0。
ID生成服务假设每次批量拉取6个ID,服务访问数据库,将当前ID的最大值修改为5,这样应用访问ID生成服务索要ID,ID生成服务不需要每次访问数据库,就能依次派发0,1,2,3,4,5这些ID了。
当ID发完后,再将ID的最大值修改为11,就能再次派发6,7,8,9,10,11这些ID了,于是数据库的压力就降低到原来的1/6。
优点:
保证了ID生成的绝对递增有序
大大的降低了数据库的压力,ID生成可以做到每秒生成几万几十万个
缺点:
服务仍然是单点
如果服务挂了,服务重启起来之后,继续生成ID可能会不连续,中间出现空洞(服务内存是保存着0,1,2,3,4,5,数据库中max-id是5,分配到3时,服务重启了,下次会从6开始分配,4和5就成了空洞,不过这个问题也不大)
虽然每秒可以生成几万几十万个ID,但毕竟还是有性能上限,无法进行水平扩展
改进方法:
单点服务的常用高可用优化方案是“备用服务”,也叫“影子服务”,所以我们能用以下方法优化上述缺点(1):
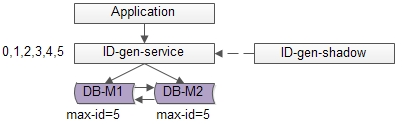
如上图,对外提供的服务是主服务,有一个影子服务时刻处于备用状态,当主服务挂了的时候影子服务顶上。
这个切换的过程对调用方是透明的,可以自动完成,常用的技术是vip+keepalived,具体就不在这里展开。
另外,ID-gen-service也可以实施水平扩展,以解决上述缺点(3),但会引发一致性问题,具体解决方案详见《》。
方法三:uuid/guid
不管是通过数据库,还是通过服务来生成ID,业务方Application都需要进行一次远程调用,比较耗时。
有没有一种本地生成ID的方法,即高性能,又时延低呢?
uuid是一种常见的方案:
string ID =GenUUID();
优点:
本地生成ID,不需要进行远程调用,时延低
扩展性好,基本可以认为没有性能上限
缺点:
无法保证趋势递增
uuid过长,往往用字符串表示,作为主键建立索引查询效率低,常见优化方案为“转化为两个uint64整数存储”或者“折半存储”(折半后不能保证唯一性)
方法四:取当前毫秒数
uuid是一个本地算法,生成性能高,但无法保证趋势递增,且作为字符串ID检索效率低,有没有一种能保证递增的本地算法呢?
取当前毫秒数是一种常见方案:
uint64 ID = GenTimeMS();
优点:
本地生成ID,不需要进行远程调用,时延低
生成的ID趋势递增
生成的ID是整数,建立索引后查询效率高
缺点:
如果并发量超过1000,会生成重复的ID
这个缺点要了命了,不能保证ID的唯一性。当然,使用微秒可以降低冲突概率,但每秒最多只能生成1000000个ID,再多的话就一定会冲突了,所以使用微秒并不从根本上解决问题。
方法五:类snowflake算法
snowflake是twitter开源的分布式ID生成算法,其核心思想为,一个long型的ID:
41bit作为毫秒数
10bit作为机器编号
12bit作为毫秒内序列号
算法单机每秒内理论上最多可以生成1000*(2^12),也就是400W的ID,完全能满足业务的需求。
借鉴snowflake的思想,结合各公司的业务逻辑和并发量,可以实现自己的分布式ID生成算法。
举例,假设某公司ID生成器服务的需求如下:
单机高峰并发量小于1W,预计未来5年单机高峰并发量小于10W
有2个机房,预计未来5年机房数量小于4个
每个机房机器数小于100台
目前有5个业务线有ID生成需求,预计未来业务线数量小于10个
…
分析过程如下:
高位取从2017年1月1日到现在的毫秒数(假设系统ID生成器服务在这个时间之后上线),假设系统至少运行10年,那至少需要10年365天24小时3600秒1000毫秒=320*10^9,差不多预留39bit给毫秒数
每秒的单机高峰并发量小于10W,即平均每毫秒的单机高峰并发量小于100,差不多预留7bit给每毫秒内序列号
5年内机房数小于4个,预留2bit给机房标识
每个机房小于100台机器,预留7bit给每个机房内的服务器标识
业务线小于10个,预留4bit给业务线标识
这样设计的64bit标识,可以保证:
每个业务线、每个机房、每个机器生成的ID都是不同的
同一个机器,每个毫秒内生成的ID都是不同的
同一个机器,同一个毫秒内,以序列号区区分保证生成的ID是不同的
将毫秒数放在最高位,保证生成的ID是趋势递增的
缺点:
由于“没有一个全局时钟”,每台服务器分配的ID是绝对递增的,但从全局看,生成的ID只是趋势递增的(有些服务器的时间早,有些服务器的时间晚)
方法六:Redis生成ID
Redis实现了一个原子操作INCR和INCRBY实现递增的操作。当使用数据库性能不够时,可以采用Redis来代替,同时使用Redis集群来提高吞吐量。可以初始化每台Redis的初始值为1,2,3,4,5,然后步长为5。各个Redis生成的ID为:
A:1,6,11,16,21
B:2,7,12,17,22
C:3,8,13,18,23
D:4,9,14,19,24
E:5,10,15,20,25
优点
不依赖于数据库,灵活方便,且性能优于数据库。
数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
如果系统中没有Redis,还需要引入新的组件,增加系统复杂度。
需要编码和配置的工作量比较大。这个都不是最大的问题。
方法七: 利用zookeeper生成唯一ID
zookeeper主要通过其znode数据版本来生成序列号,可以生成32位和64位的数据版本号,客户端可以使用这个版本号来作为唯一的序列号。
很少会使用zookeeper来生成唯一ID。主要是由于需要依赖zookeeper,并且是多步调用API,如果在竞争较大的情况下,需要考虑使用分布式锁。因此,性能在高并发的分布式环境下,也不甚理想。
搞懂分布式技术12:分布式ID生成方案的更多相关文章
- 分库分表的 9种分布式主键ID 生成方案,挺全乎的
<sharding-jdbc 分库分表的 4种分片策略> 中我们介绍了 sharding-jdbc 4种分片策略的使用场景,可以满足基础的分片功能开发,这篇我们来看看分库分表后,应该如何为 ...
- 分布式ID生成方案总结整理
目录 1.为什么需要分布式ID? 2.业务系统对分布式ID有什么要求? 3.分布式ID生成方案 3.1 UUID 3.2.数据库自增 3.3.号段模式 3.4. Redis实现 3.4. 雪花算法(S ...
- 分布式全局不重复ID生成算法
分布式全局不重复ID生成算法 算法全局id唯一id 在分布式系统中经常会使用到生成全局唯一不重复ID的情况.本篇博客介绍生成的一些方法. 常见的一些方式: 1.通过DB做全局自增操作 优点:简单.高 ...
- 分布式环境下的id生成方法
分布式环境下的id生成方法 前几天研究数据库分表分库的问题,其中有一个关键的地方就是生成唯一键的问题,假如数据表有1亿条数据,而且还在不断的增加,这里我们就需要考虑到分表分库,假设我们采用Hash ...
- 分布式唯一ID生成方案是什么样的?(转)
一.前言 分布式系统中我们会对一些数据量大的业务进行分拆,如:用户表,订单表.因为数据量巨大一张表无法承接,就会对其进行分库分表. 但一旦涉及到分库分表,就会引申出分布式系统中唯一主键ID的生成问题, ...
- 基于数据库构建分布式的ID生成方案
在分布式系统中,生成全局唯一ID,有很多种方案,但是在这多种方案中,每种方案都有有缺点,下面我们之针对通过常用数据库来生成分布式ID的方案,其它方法会在其它文中讨论: 1,RDBMS生成ID: 这里我 ...
- 【系统设计】分布式唯一ID生成方案总结
目录 分布式系统中唯一ID生成方案 1. 唯一ID简介 2. 全局ID常见生成方案 2.1 UUID生成 2.2 数据库生成 2.3 Redis生成 2.4 利用zookeeper生成 2.5 雪花算 ...
- 分布式id生成方案总结
本文已经收录自 JavaGuide (60k+ Star[Java学习+面试指南] 一份涵盖大部分Java程序员所需要掌握的核心知识.) 本文授权转载自:https://juejin.im/post/ ...
- 一线大厂的分布式唯一ID生成方案是什么样的?
本人免费整理了Java高级资料,涵盖了Java.Redis.MongoDB.MySQL.Zookeeper.Spring Cloud.Dubbo高并发分布式等教程,一共30G,需要自己领取.传送门:h ...
随机推荐
- linux上scp远程复制的使用
一.实例展示 两台机器IP分别为:A.104.238.161.75,B.43.224.34.73. ------把别的服务器上的资源拿到自己的上边 在A服务器上操作,将B服务器上/home/lk/目录 ...
- for…else和while…else
当while语句配备else子句时,如果while子句内嵌的循环体在整个循环过程中没有执行break语句(循环体中没有break语句,或者循环体中有break语句但是始终未执行),那么循环过程结束后, ...
- convention over configuration
惯例优先原则:也称为约定大于配置或规约大于配置(convention over configuration),即通过约定代码结构或命名规范来减少配置数量,同样不会减少配置文件:即通过约定好默认规范来提 ...
- oracle中length、lengthb、substr、substrb用法小结
我记得我曾经在开发form的时候犯过这样一个错误,对于form中的某个字段,对应于数据库中某张表的字段,假设在数据库中这个字段一般也就用到20个汉字的长度,后来我在开发form的时候,设置item类型 ...
- linux下多线程之pthread_detach(pthread_self())
写个碰到的问题,记录下自己的技术之路点滴pthread_detach(pthread_self())linux线程执行和windows不同,pthread有两种状态joinable状态和unjoina ...
- java中hashSet原理
转自: http://blog.csdn.net/guoweimelon/article/details/50804799 HashSet是JavaMap类型的集合类中最常使用的,本文基于Java1. ...
- mysql搜索不区分大小写
mysql搜索是不区分大小写的,这种情况下我们有两种方法解决 知识前提: BINARY binary不是函数,而是一个类型转换运算符,它用来强制字符串为一个二进制字符串,可以理解为在字符串比较的时候区 ...
- 20145313张雪纯 《Java程序设计》第5周学习总结
20145313张雪纯 <Java程序设计>第5周学习总结 教材学习内容总结 JAVA中所有错误都会被打包成对象,可以用尝试(try)捕捉(catch)代表错误的对象后做一些处理.使用tr ...
- [BZOJ1217]消防局的设立
Description 2020年,人类在火星上建立了一个庞大的基地群,总共有n个基地.起初为了节约材料,人类只修建了n-1条道路来 连接这些基地,并且每两个基地都能够通过道路到达,所以所有的基地形成 ...
- vue.js的一些小语法v-bind,v-if,v-show,v-else
知识点: v-bind 动态绑定标签属性 v-bind 可简写为 : 使用v-bind 绑定class和内联样式 使用v-if,v-show,v-else进行条件渲染 <template> ...