LINUX 高可用群集之 ~Corosync~
Corosync:它属于OpenAIS(开放式应用接口规范)中的一个项目corosync一版本中本身不具 备投票功能,到了corosync 2.0之后引入了votequorum子系统也具备了投票功能了,如果我们用的是1版本的,又需要用到票数做决策时那该如何是好呢;当然,在红帽上把 cman + corosync结合起来用,但是早期cman跟pacemaker没法结合起来,如果想用pacemaker又想用投票功能的话,那就把cman当成 corosync的插件来用,把cman当成corodync的投票功能,当然,这里结合了两个了Messaging Lader;Corosync目前有两个主流的版本:一个是2系列的,另一个是1系列的稳定版;2版本和1版本差别很大,1版本不具有投票功能,2版本之 后引入了votequorum后支持投票功能了;OpenAIS自从诞生之后,红帽就基于这个规范研发了一个高可用集群的解决方案叫cman,并为cman提供了rgmangaer作为资源管理器,并且容合conga全生命周期的管理接口形成了RHCS;
Conrosync是从OpenAIS这个大项目中分支出来的一个项目,而Pacemaker是heartbeat v3版本中分裂出来专门用于提供高可用集群CRM的组件,功能十分强大, Coreosync在传递信息的时候可以通过一个简单的配置文件来定义信息传递的方式和协议等,Corosync可以提供一个完整的HA功 能,Corosync是未来的发展方向,在以后的新项目里,一般采用Corosync,而heartbeat_gui可以提供很好的HA管理功能,可以实 现图形化的管理。
Pacemaker是一个集群管理器。它利用首选集群基础设施(OpenAIS 或heartbeat)提供的消息和成员能力,由辅助节点和系统进行故障检测和回收,实现性群集服务(亦称资源)的高可用性。
corosync+pacemaker:在配置corosync时最好具有三个以上的节点,并且节点个数为奇数个,如果使用偶数个节点的话也没关系,只是要关闭不具有法定票数的决策策略功能;
实现过程:
1、双机互信需要设置好,hosts文件需要解析好,时间要同步
# vim /etc/hosts
172.16.27.1 node1.tanxw.com
172.16.27.2 node2.tanxw.com
# ssh-keygen -t rsa -P ‘’
# ssh-copy-id -i id_rsa.pub node2.tanxw.com
2、安装corosync,这里我们用ansible来安装,要使用ansible在一台主机上操作多台主机得需要事先安装ansible,那这里我们 就先说说安装和配置使用ansible,安装ansible也可以用yum来安装,不过需要解决依赖关系:
# yum -y install python-jinja2 解决依赖关系
# yum -y install ansible
安装好之后再去/etc/ansible下配置两个节点的hostname:
# vim /etc/ansible/hosts 把里面的内容全都注释掉,加下面你的节点hostname
[corosync]
node1.tanxw.com
node2.tanxw.com
保存退出!
我们这里使用172.16.27.0这台主机安装ansible,操作172.16.27.1和.2这两台主机,测试一下:
# yum -y install python-jinja2 解决依赖关系
# yum -y install ansible
安装好之后再去/etc/ansible下配置两个节点的hostname:
# vim /etc/ansible/hosts 把里面的内容全都注释掉,加下面你的节点hostname
[corosync]
node1.tanxw.com
node2.tanxw.com
3、时间同步,需要事先配置好一台时间服务器,然后在crontab -e中输入:
# crontab -e
*/ * * * * /usr/sbin/ntpdte 172.16.27.0 &> /dev/null 表示每隔5分钟同步一次
好,准备工作做好了之后就可以安装corosync了,使用ansible查看两个节点是否已经安装了corosync:
[root@node0 ~]# ansible corosync -m shell -a 'rpm -q corosync'
node2.tanxw.com | FAILED | rc= >>
package corosync is not installed
node1.tanxw.com | FAILED | rc= >>
package corosync is not installed
# ansible corosync -m yum -a "name=corosync state=present" 全部输出显示为绿色说明安装成功
[root@node0 ~]# ansible corosync -m shell -a 'rpm -q corosync' 再查看一下corosync的安装版本
node2.tanxw.com | success | rc= >>
corosync-1.4.-.el6.x86_64
node1.tanxw.com | success | rc= >>
corosync-1.4.-.el6.x86_64
# cp /etc/corosync/corosync.conf.example /etc/corosync.conf 复制一份corosync的样本配置文件
# vim /etc/corosync/corosync.conf 编辑配置文件修改如下内容
compatibility: whitetank #这个表示是否兼容0.8之前的版本
totem { #图腾,这是用来定义集群中各节点中是怎么通信的以及参数
version: #图腾的协议版本,它是种协议,协议是有版本的,它是用于各节点互相通信的协议,这是定义版本的
secauth: on #表示安全认证功能是否启用的
threads: #实现认证时的并行线程数,0表示默认配置
interface { # 指定在哪个接口上发心跳信息的,它是个子模块
ringnumber: #环号码,集群中有多个节点,每个节点上有多个网卡,别的节点可以接收,同时我们本机的别一块网卡也可以接收,为了避免这些信息在这样的环状发送,因此要为这个网卡定义一个唯一的环号码,以避免心跳信息环发送。
bindnetaddr: 192.168.1.1 # 绑定的网络地址
mcastaddr: 226.94.1.1 #多播地址,一对多通信
mcastport: # 多播端口
ttl: # 表示只向外播一次
}
}
logging { # 跟日志相关
fileline: off
to_stderr: no # 表示是否需要发送到错误输出
to_logfile: yes #是不是送给日志文件
to_syslog: no #是不是送给系统日志
logfile: /var/log/cluster/corosync.log #日志文件路径
debug: off #是否启动调试
timestamp: on #日志是否需要记录时间戳
logger_subsys { #日志的子系统
subsys: AMF
debug: off
}
}
amf { # 跟编程接口相关的
mode: disabled
}
service { #定义一个服务来启动pacemaker
ver: #定义版本
name: pacemaker #这个表示启动corosync时会自动启动pacemaker
}
aisexec { #表示启动ais的功能时以哪个用户的身份去运行的
user: root
group: root #其实这个块定义不定义都可以,corosync默认就是以root身份去运行的
}
这里我们改一个随机数墒池,再把配置好的corosync的配置和认证文件复制到另一个节点上去:
# mv /dev/random /dev/m
# ln /dev/urandom /dev/random 如果这把这个随机数墒池改了可以会产生随机数不够用,这个就要敲击键盘给这个墒池一些随机数;生成完这个key后把链接删除,再把墒池改回来;不过这样改可以会有点为安全,不过做测试的应该不要紧;
# corosync-keygen
# rm -rf /dev/random
# mv /dev/m /dev/random
对于corosync而言,我们各节点之间通信时必须要能够实现安全认证的,要用到一个密钥文件:
# corosync-keygen # 生成密钥文件,用于双机通信互信,会生成一authkey的文件
# scp authkey corosync.conf node2.tanxw.com:/etc/corosync/ 在配置好的节点上把这两个文件复制给另一个节点上的corosync的配置文件中去
安装pacemaker
# ansible corosync -m yum -a “name=pacemaker state=present”
我们要想使用pacemaker配置的话需要安装一个pacemaker的接口,它的这个程序的接口叫crmshell,它在新版本的 pacemaker已经被独立出来了,不再是pacemaker的组成部分了,早期装上pacemaker就会自带有crmshell,因此要想用 crmshell的话得去安装crmshell,而安装crmshell又依赖于pssh的相关包,因此得安装这两个组件,(这里的这两个包是自己制件 的),哪个节点配置就安装在哪个节点上就可以了,也无需两个节点都安装这两个包:
crmsh-1.2.-.el6.x86_64.rpm
pssh-2.3.-.el6.x86_64.rpm
# yum -y install crmsh-1.2.-.el6.x86_64.rpm pssh-2.3.-.el6.x86_64.rpm
一切都OK了之后就可以启动服务了,两个节点都需要启动:


在这里crm是一个很复杂的命令,可以在命令行直接输入crm进入crm的命令行模式:# crm
那在这里,我们如何去配置一个资源呢,虽然它跟heartbeat略有区别,但是概念基本上是一样的,下面我们就来配置一个web资源吧!
由于我们的corosync默认是启用stonith功能的,但是我们这里没有stonith设备,如果我们直接去配置资源的话,由于没有
stonith功能,所以资源的切换并不会完成,所以要禁用stonith功能,但禁用stonoith需要我们去配置集群的全局stonith属性,全
局属性是对所有的节点都生效;
[root@node1 corosync]# crm configure #进入crm命令行模式配置资源等
crm(live)configure# property #切换到property目录下,可以用两次tab键进行补全和查看
usage: property [$id=<set_id>] <option>=<value> # property的用法和格式
crm(live)configure# property stonith-enabled=false #禁用stonith-enabled
crm(live)configure# verify #检查设置的属性是否正确
crm(live)configure# commit #检查没问题就可以提交了
crm(live)configure# show #查看当前集群的所有配置信息
node node1.tanxw.com
node node2.tanxw.com #两个节点
property $id="cib-bootstrap-options" \
dc-version="1.1.10-14.el6-368c726" \ #DC的版本号
cluster-infrastructure="classic openais (with plugin)" \ #集群的基础架构,使用的是OpenAIS,插件式的
expected-quorum-votes="" \ #期望节点的票数
stonith-enabled="false" #禁用stonith功能
crm(live)configure#
查看一下节点的运行状态:
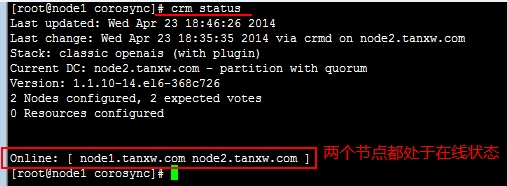
要注意:如果一个节点挂了,就不拥有法定票数了,那资源是不会切换的
集群的策略有几种:
stopped :停止服务
ignore :忽略,继续运行
freeze :冻结,已经连接的请求继续响应,新的请求不再响应
suicide :自杀,将服务kill掉
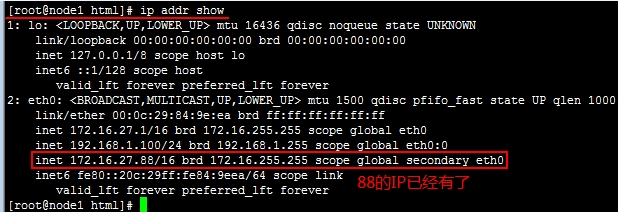
再进入crm定义我们所需要的资源吧!
crm(live)# configure
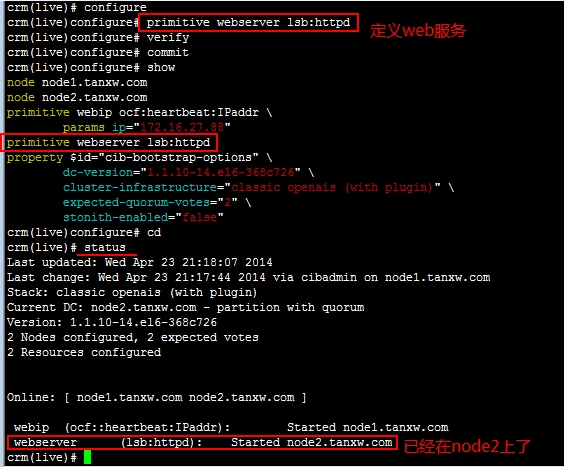
crm(live)configure# primitive webip ocf:heartbeat:IPaddr params ip=172.16.27.88
crm(live)configure# verify
crm(live)configure# commit
crm(live)configure# show
node node1.tanxw.com
node node2.tanxw.com
primitive webip ocf:heartbeat:IPaddr \
params ip="172.16.27.88"
property $id="cib-bootstrap-options" \
dc-version="1.1.10-14.el6-368c726" \
cluster-infrastructure="classic openais (with plugin)" \
expected-quorum-votes="" \
stonith-enabled="false"
crm(live)configure#
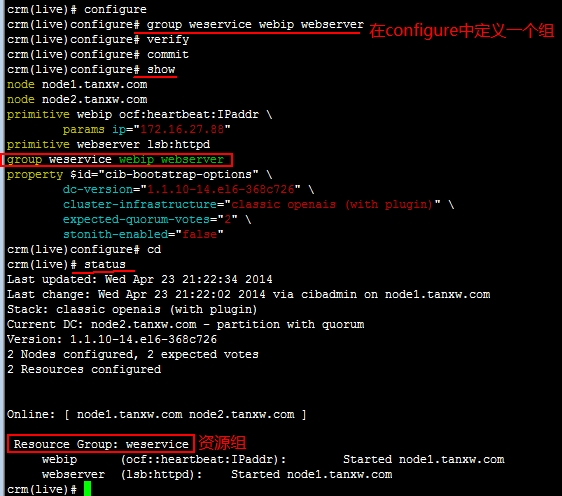
定义一个组,把之后定义的资源加到这个组里面去:
# group weservice webip webserver
让node1节点离线:
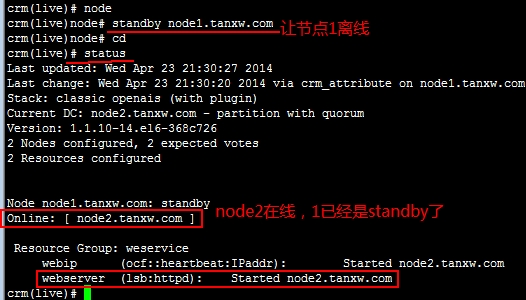
好了,这种功能我们也完成了,如果让node1上线它也不会转回的,因为我们没有定义它的倾向性和故障转回,所以node1回来就回来吧,而服务依然运行在node2上;
crm(live)node# online node1.tanxw.com 让node1从新上线
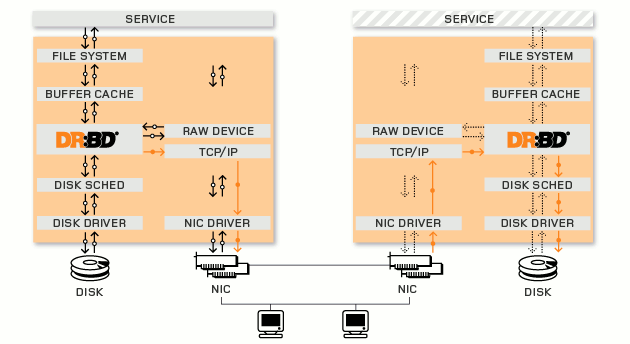
DRBD (Distributed Replicated Block Device)分布式复制块设备,它是 Linux 平台上的分散式储存系统,通常用于高可用性(high availability, HA)集群中。DRBD 类似磁盘阵列的RAID 1(镜像),只不过 RAID 1 是在同一台电脑内,而 DRBD 是透过网络。
DRBD Resource:DRBD所具有的几种属性:
resource name:可以使用除空白字符外的任意ACSII表中的字符;
drbd设备:drbd的设备的访问路径,设备文件/dev/drbd#;
disk:各节点为组成此drbd设备所提供的块设备,通常是一个磁盘分区;
网络属性:节点间为了实现跨主机磁盘镜像而使用的网络配置;
注意:用户空间工具与drdb与内核中使用的模块版本要保持一致,只有在使用drbdadm工具时才会读取配置文件,对多个资源的公共配置,可以提取出来只配置一次,通常保存在Common中,此外还有global配置,这种配置跟资源本身没有关系的;
drbd的组成部分:第一部分用户空间工具;第二部分是内核模块(在2.6.33及以后版本的内核直接在内核中就有了)
用户空间工具:跟内核版本关系比较松散,只要是能适用于CentOS 6及对应硬件平台的就OK;
内核模块:必须与当下内核版本严格对应;其中drbd内核模块代码已经整合进Linux内核2.6.33以后的版本中,因此,如果您的内核版本高于此版本的话,你只需要安装管理工具即可;否则,您需要同时安装内核模块和管理工具两个软件包,并且此两者的版本号一定要保持对应。
进程间通信的三种方式:消息序列、旗语及共享内存:
什么是消息队列:
消息被发送到队列中,"消息队列"是在消息的传输过程中保存消息的容器。消息队列管理器在将消息从它的源中继到它的目标时充当中间人。队列的主要目的是
提供路由并保证消息的传递;如果发送消息时接收者不可用,消息队列会保留消息,直到可以成功地传递它;消息队列就是一个消息的链表。可以把消息看作一个记
录,具有特定的格式以及特定的优先级。对消息队列有写权限的进程可以向消息队列中按照一定的规则添加新消息;对消息队列有读权限的进程则可以从消息队列中
读走消息。消息队列是随内核持续的。
什么是旗语、什么是信号量:
Linux的旗语就是操作系统原理中的信号量,有PV操作,释放旗语会自动唤醒下一个等待获取旗语的进程;
为了防止出现因多个程序同时访问一个共享资源而引发的一系列问题,我们需要一种方法,它可以通过生成并使用令牌来授权,在任一时刻只能有一个执行线程访
问代码的临界区域。临界区域是指执行数据更新的代码需要独占式地执行。而信号量就可以提供这样的一种访问机制,让一个临界区同一时间只有一个线程在访问
它,也就是说信号量是用来调协进程对共享资源的访问的。
信号量是一个特殊的变量,程序对其访问都是原子操作,且只允许对它进行等待(即P(信号变量))和发送(即V(信号变量))信息操作。最简单的信号量是只能取0和1的变量,这也是信号量最常见的一种形式,叫做二进制信号量。而可以取多个正整数的信号量被称为通用信号量。
什么是共享内存:
顾名思义,共享内存就是允许两个不相关的进程访问同一个逻辑内存。共享内存是在两个正在运行的进程之间共享和传递数据的一种非常有效的方式。不同进程之
间共享的内存通常安排为同一段物理内存。进程可以将同一段共享内存连接到它们自己的地址空间中,所有进程都可以访问共享内存中的地址,就好像它们是由用C
语言函数malloc分配的内存一样。而如果某个进程向共享内存写入数据,所做的改动将立即影响到可以访问同一段共享内存的任何其他进程。
数据存储的几种类型:
 9
9
1.1存储的概念与术语
1.1.3 DAS 介绍
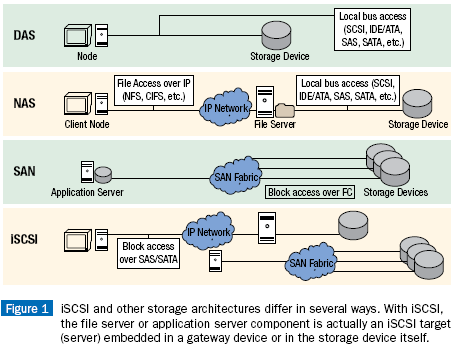
DAS 是直连式存储(Direct-Attached Storage)的简称,是指将存储设备通过SCSI接口 或光纤通道直接连接到一台计算机上。当服务器在地理上比较分散,很难通过远程进行互连 时,DAS是比较好的解决方案。但是这种式存储只能通过与之连接的主机进行访问,不能实现数据与其他主机的共享,同时,DAS会占用服务器操作系统资源, 例如CPU资源、IO资 源等,并且数据置越大,占用操作系统资源就越严重。
NAS:(Network Attach Srorage)网络附加存储,它
就是个文件服务器,是文件系统级别,NAS和传统的文件存储服务或直接存储设备不同的地方在于NAS设备上面的操作系统和软件只提供了数据存储、数据访
问、以及相关的管理功能;此外,NAS设备也提供了不止一种文件传输协议。NAS系统通常有一个以上的硬盘,而且和传统的文件服务器一样,通常会把它们组
成RAID来提供服务;有了NAS以后,网络上的其他服务器就可以不必再兼任文件服务器的功能。NAS的型式很多样化,可以是一个大量生产的嵌入式设备,
也可以在一般的计算机上运行NAS的软件。
NAS用的是以文件为单位的通信协议,例如像是NFS(在UNIX系统上很常见)或是SMB(常
用于Windows系统)。NAS所用的是以文件为单位的通信协议,大家都很清楚它们的运作模式,相对之下,存储区域网络(SAN)用的则是以区块为单位
的通信协议、通常是通过SCSI再转为光纤通道或是iSCSI。(还有其他各种不同的SAN通信协议,像是ATA over
Ethernet和HyperSCSI,不过这些都不常见。)
SAN:(Storage Area Network)存储区域网络,把
SCSI协议借助于其它网络协议实现传送的;1991年,IBM公司在S/390服务器中推出了ESCON(Enterprise System
Connection)技术。它是基于光纤介质,最大传输速率达17MB/s的服务器访问存储器的一种连接方式。在此基础上,进一步推出了功能更强的
ESCON Director(FC SWitch),构建了一套最原始的SAN系统。
它是一种高速网络或子网络,提供在计算机与存储系统之间的数据传输。存储设备是指一台或多台用以存储计算机数据的磁盘设备,通常指磁盘阵列。
DAS、NAS和SAN三种存储方式比较
存储应用最大的特点是没有标准的体系结构,这三种存储方式共存,互相补充,已经很好满足企业信息化应用。
从
连接方式上对比,DAS采用了存储设备直接连接应用服务器,具有一定的灵活性和限制性;NAS通过网络(TCP/IP,ATM,FDDI)技术连接存储
设备和应用服务器,存储设备位置灵活,随着万兆网的出现,传输速率有了很大的提高;SAN则是通过光纤通道(Fibre
Channel)技术连接存储设备和应用服务器,具有很好的传输速率和扩展性能。三种存储方式各有优势,相互共存,占到了磁盘存储市场的70%以上。
SAN和NAS产品的价格仍然远远高于DAS.许多用户出于价格因素考虑选择了低效率的直连存储而不是高效率的共享存储。
客观的说,SAN和NAS系统已经可以利用类似自动精简配置(thin
provisioning)这样的技术来弥补早期存储分配不灵活的短板。然而,之前它们消耗了太多的时间来解决存储分配的问题,以至于给DAS留有足够的
时间在数据中心领域站稳脚跟。此外,SAN和NAS依然问题多多,至今无法解决。
DRBD在远程传输上支持三种模式:
1、异步:所谓异步就是指数据只需要发给本地的TCP/IP协议栈就可以了,本地存完就OK;而DRBD只需要把数据放到TCP/IP协议栈,放到发送队列中准备发送就返回了;这种方式更高效;
2、半同步:数据已经发送到对方的TCP/IP协议栈上,对方的TCP/IP协议栈已经把数据接收下来了就返回,数据存不存下来就不管了;
3、同步:数据必须确保对方把数据写入对方的磁盘再返回的就叫同步;这种方式数据更可靠;
官方提供的DRBD的工作流程图:
====================DRBD + Corosync、Pacemaker实现DRBD角色自动切换=======================
在
运行drbd时,他并不会自动完成角色的切换,那怎么让它具有这样的功能呢,这里就得用到Corosync+Pacemaker了,结合
corosync+pacemaker的drbd就可以自动完成角色的切换,一旦一个drbd的节点出现故障就可以自动切换到别一个节点上继续提供服务,
那接下来我们就来配置一下drbd + corosync、pacemaker的实现;
第一步:配置两个节点上的双机互信,这步我前面的博文中已经写到过了,可以参数前面的博文:CentOS 6.5 heartbeat高可用集群的详解实现以及工作流程;
第二步:安装DRBD程序包,这一步一定要格外注意版本匹配问题:
内核模块程序包一定要跟你的系统内核保持一致,uname -r查看你的内核版本,内核模块的版本必须要严格对应,而用户空间的模块就不那么严格要求了,两个节点的时间也需要保持一致性;
drbd-8.4.3-33.el6.x86_64.rpm -->用户空间工具
drbd-kmdl-2.6.32-431.el6-8.4.3-33.el6.x86_64.rpm -->内核空间模块,这个必须要跟内核版本保持一致

# yum -y install drbd-8.4.3-33.el6.x86_64.rpm drbd-kmdl-2.6.32-431.el6-8.4.3-33.el6.x86_64.rpm 每个节点都需要安装上这两个程序包
安装完成可以看一下drbd的配置文件:
# vim /etc/drbd.conf 主配置文件
# vim /etc/drbd.d/global_common.conf 全局和common的配置
global { #全局配置
usage-count no; #这个为yes表示如果你本机可以连接互联网时drbd会通过互联网收集到你安装drbd的信息,官方统计说又多了一个人使用drbd实例,不用可以改为no
# minor-count dialog-refresh disable-ip-verification
}
common {
handlers { #处理器
# These are EXAMPLE handlers only.
# They may have severe implications,
# like hard resetting the node under certain circumstances.
# Be careful when chosing your poison.
pri-on-incon-degr "/usr/lib/drbd/notify-pri-on-incon-degr.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f"; 定义了如果主节点降级了怎么处理的
pri-lost-after-sb "/usr/lib/drbd/notify-pri-lost-after-sb.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f"; 这个定义了如果有脑裂了之后找不到主节点怎么处理的
local-io-error "/usr/lib/drbd/notify-io-error.sh; /usr/lib/drbd/notify-emergency-shutdown.sh; echo o > /proc/sysrq-trigger ; halt -f"; 定义了一旦本地节点发生IO错误时应该怎么处理
# fence-peer "/usr/lib/drbd/crm-fence-peer.sh";
# split-brain "/usr/lib/drbd/notify-split-brain.sh root";
# out-of-sync "/usr/lib/drbd/notify-out-of-sync.sh root";
# before-resync-target "/usr/lib/drbd/snapshot-resync-target-lvm.sh -p 15 -- -c 16k";
# after-resync-target /usr/lib/drbd/unsnapshot-resync-target-lvm.sh;
}
startup { 定义一个节点启动时另一个节点应该怎么做
# wfc-timeout(等待另一个节点上线的超时时长)
# degr-wfc-timeout(等待超时后做降级处理)
# outdated-wfc-timeout(过期的等待超时)
# wait-after-sb(脑裂之后等待多长时长)
}
options {
# cpu-mask on-no-data-accessible
}
disk {
on-io-error detach;
# size max-bio-bvecs on-io-error fencing disk-barrier disk-flushes
# disk-drain md-flushes resync-rate resync-after al-extents
# c-plan-ahead c-delay-target c-fill-target c-max-rate
# c-min-rate disk-timeout
}
net {
protocol C;
cram-hmac-alg "sha1";
shared-secret "drbd.tanxw.com";
# protocol timeout max-epoch-size max-buffers unplug-watermark
# connect-int ping-int sndbuf-size rcvbuf-size ko-count
# allow-two-primaries cram-hmac-alg shared-secret after-sb-0pri
# after-sb-1pri after-sb-2pri always-asbp rr-conflict
# ping-timeout data-integrity-alg tcp-cork on-congestion
# congestion-fill congestion-extents csums-alg verify-alg
# use-rle
}
syncer {
rate 1000M;
}
}
保存退出。
第三步:为两个节点准备等同大小的磁盘分区,分区好之后不需要格式化,分好区并且识别出就可以了;
[root@node2 drbd.d]# fdisk /dev/sda
WARNING: DOS-compatible mode is deprecated. It's strongly recommended to
switch off the mode (command 'c') and change display units to
sectors (command 'u').
Command (m for help): p
Disk /dev/sda: 85.9 GB, bytes
heads, sectors/track, cylinders
Units = cylinders of * = bytes
Sector size (logical/physical): bytes / bytes
I/O size (minimum/optimal): bytes / bytes
Disk identifier: 0x000e89e2
Device Boot Start End Blocks Id System
/dev/sda1 * Linux
Partition does not end on cylinder boundary.
/dev/sda2 8e Linux LVM
/dev/sda3 8e Linux LVM
Command (m for help): n
Command action
e extended
p primary partition (-)
e
Selected partition
First cylinder (-, default ):
Using default value
Last cylinder, +cylinders or +size{K,M,G} (-, default ):
Using default value
Command (m for help): n
First cylinder (-, default ):
Using default value
Last cylinder, +cylinders or +size{K,M,G} (-, default ): +3G
Command (m for help): p
Disk /dev/sda: 85.9 GB, bytes
heads, sectors/track, cylinders
Units = cylinders of * = bytes
Sector size (logical/physical): bytes / bytes
I/O size (minimum/optimal): bytes / bytes
Disk identifier: 0x000e89e2
Device Boot Start End Blocks Id System
/dev/sda1 * Linux
Partition does not end on cylinder boundary.
/dev/sda2 8e Linux LVM
/dev/sda3 8e Linux LVM
/dev/sda4 + Extended
/dev/sda5 Linux
Command (m for help): w
The partition table has been altered!
Calling ioctl() to re-read partition table.
WARNING: Re-reading the partition table failed with error : Device or resource busy.
The kernel still uses the old table. The new table will be used at
the next reboot or after you run partprobe() or kpartx()
Syncing disks.
[root@node2 drbd.d]# kpartx -af /dev/sda
device-mapper: reload ioctl on sda1 failed: Invalid argument
create/reload failed on sda1
device-mapper: reload ioctl on sda2 failed: Invalid argument
create/reload failed on sda2
device-mapper: reload ioctl on sda3 failed: Invalid argument
create/reload failed on sda3
device-mapper: reload ioctl on sda4 failed: Invalid argument
create/reload failed on sda4
device-mapper: reload ioctl on sda5 failed: Invalid argument
create/reload failed on sda5
[root@node2 drbd.d]# partx -a /dev/sda
BLKPG: Device or resource busy
error adding partition
BLKPG: Device or resource busy
error adding partition
BLKPG: Device or resource busy
error adding partition
[root@node2 drbd.d]# partx -a /dev/sda
BLKPG: Device or resource busy
error adding partition
BLKPG: Device or resource busy
error adding partition
BLKPG: Device or resource busy
error adding partition
BLKPG: Device or resource busy
error adding partition
BLKPG: Device or resource busy
error adding partition
[root@node2 drbd.d]#
第四步:根据上面的描述,我们要给它定义资源,包括资源名,drbd设备,disk以及网络属性,主要是这四个方面;
定义一个资源/etc/drbd.d/,内容如下:
# cd /etc/drbd.d/
# vim mystore.res
resource mystore { #定义一个资源,用关键字resource;
on node1.tanxw.com { #on说明在哪个节点上,跟uname -n保持一致,有多少个节点就定义多少个;
device /dev/drbd0; #在磁盘上表现的drbd叫什么名;
disk /dev/sda5; #所使用的磁盘设备是哪个;
address 172.16.27.1:; #在node1这个节点上监听的套接字,默认监听在7789端口上;
meta-disk internal; #保存drbd元数据信息的,表示就放在自己的磁盘区分上,也可以放在外部的磁盘上;
}
on node2.tanxw.com {
device /dev/drbd0;
disk /dev/sda5;
address 172.16.27.2:;
meta-disk internal;
}
}
保存退出,复制一份到别一个节点上,它们的配置文件要保持一致:
# scp global_common.conf mystore.res node2.tanxw.com:/etc/drbd.d/
# drdbadm create-md mystore 在各自的节点上初始化资源
# server drbd start 启动drbd
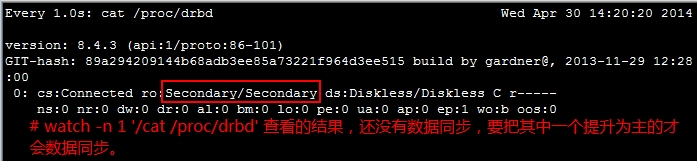
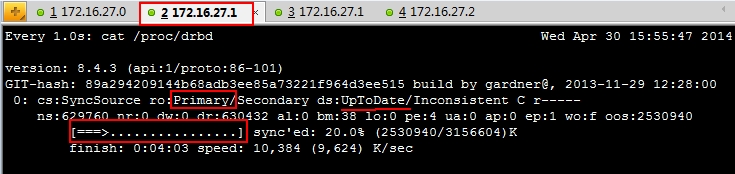
# watch -n 'cat /proc/drbd' 实现查看磁盘信息
# drbdadm primary --force mystore 在节点上把其中一个提升为主的
# watch -n 'cat /proc/drbd' 提升为主的之后再实现查看磁盘信息
注意:哪个是主节点哪个就可以挂载使用,不是主节点的连挂载都不可以挂载;
OK、看到两个节点上的数据正在同步了,磁盘越大同步时需要时间越久;
第五步:在其中一个节点上进行格式化:
# scp global_common.conf mystore.res node2.tanxw.com:/etc/drbd.d/
# drdbadm create-md mystore 在各自的节点上初始化资源
# server drbd start 启动drbd
# watch -n 'cat /proc/drbd' 实现查看磁盘信息
# drbdadm primary --force mystore 在节点上把其中一个提升为主的
# watch -n 'cat /proc/drbd' 提升为主的之后再实现查看磁盘信息
好了,到这里就完成的drbd的工作模式就这么顺利的完成了,我不知道我是否说明白了!
要完成drbd的角色自动切换得要借助于corosync+pacmaker,那接下来我们就来安装配置corosync和pacemaker吧;
为了让高可用的配置顺利,两个节点都不能设置为主的,而且都不能启动,也不能开机自动启动,所以卸载降级:
# cd
# umount /dev/drbd0
# drbdadm secondary mystore 哪个是主的就在哪相节点上降级
# service drbd stop 两个节点都需要停止服务
# chkconfig drbd off
第六步:安装corosync + pacemaker,这里直接用yum来安装,两个节点都要安装上;
# yum -y install corosync pacemaker
# yum -y install crmsh pssh
# cp /etc/corosync.conf.example /etc/corosync/corosync.conf
# vim /etc/corosync/corosync.conf
compatibility: whitetank
totem {
version:
secauth: on
threads:
interface {
ringnumber:
bindnetaddr: 172.16.0.0
mcastaddr: 226.98.188.188
mcastport:
ttl:
}
}
logging {
fileline: off
to_stderr: no
to_logfile: yes
to_syslog: no
logfile: /var/log/cluster/corosync.log
debug: off
timestamp: on
logger_subsys {
subsys: AMF
debug: off
}
}
amf {
mode: disabled
}
service {
name: pacemaker
ver:
}
aisexce {
user: root
group: root
}
# mv /dev/random /dev/m
# ln /dev/urandom /dev/random 如果这把这个随机数墒池改了可以会产生随机数不够用,这个就要敲击键盘给这个墒池一些随机数;生成完这个key后把链接删除,再把墒池改回来;不过这样改可以会有点为安全,不过做测试的应该不要紧;
# corosync-keygen
# rm -rf /dev/random
# mv /dev/m /dev/random
再把改好的配置复制一份到别一个节点上去,也保留一份给另一个节点:
# scp -p authkey corosync.conf node2.tanxw.com:/etc/corosync/
启动Corosync,每个节点都需要启动;


第七步:接下来进入crm命令行接口定义资源:
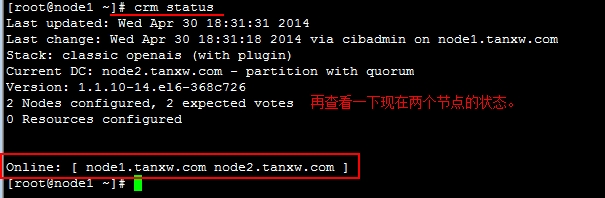
# crm status 查看节点的运行状态
# crm
# configure
# property stonith-enabled=false
# property no-quorum-policy=ignore
# rsc_defaults resource-stickiness=
# verify
# commit
# show
# meta ocf:linbit:drbd 查看drbd的详细信息
# 定义资源,切换到configure中,mysqlstore定义资源名,drbd_resource=mystore这个是drbd名,后面定义的都是一些监控
# primitive mysqlstore ocf:linbit:drbd params drbd_resource=mystore op monitor role=Master interval=30s timeout=20s op monitor role=Slave interval=60s timeout=20s op start timeout=240s op stop timeout=100s
# verify 检查语法
# 定义主资源
# master ms_mysqlstore mysqlstore meta master-max= master-node-max= clone-max= clone-node-max= notify=”True”
# verify
#commit
定义共享文件的资源,并且让服务器切换时可以自动挂载,device=/dev/drbd0挂载的设备,directory=/drbd挂载点,两个挂载点的文件名要一致:
# primitive mysqlfs ocf:heartbeat:Filesystem params device=/dev/drbd0 directory=/drbd fstype=ext4 op monitor interval=30s timeout=40s on-fail-restart op start timeout=60s op stop timeout=60s
# verify
定义排列约束:
# collocation mysqlfs_with_ms_mysqlstore_master inf: mysqlfs ms_mysqlstore:Master
# verify
定义顺序约束:
# order mysqlfs_after_ms_mysqlstore_master mandatory: ms_mysqlstore:promote mysqlfs:start
# show
# commit
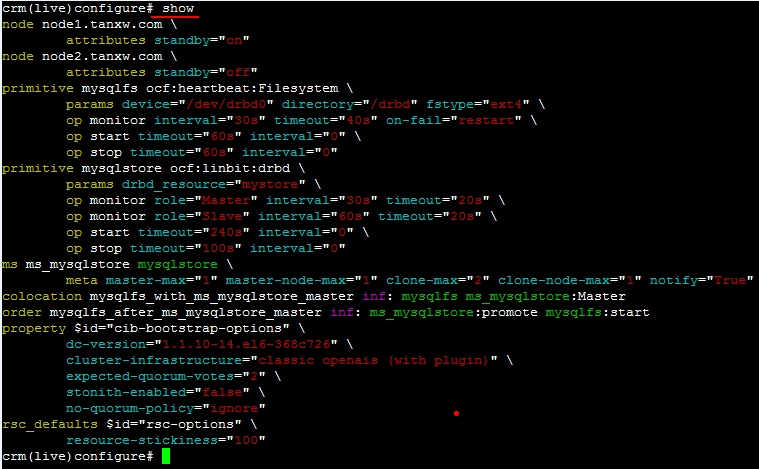
OK,再查看一下它们现在的状态,node2是主的,而node1是从的,可以到node2上查看文件是否已经挂载上去的,验证一下,再创建或修改几个文件进去都可以做一下测试的,而后再让node2停掉,看看node1是否会自动切换为主的:
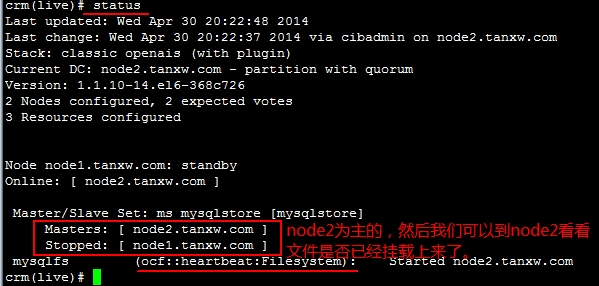
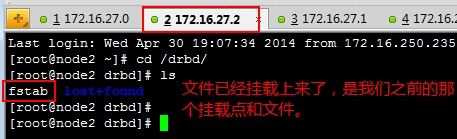
改变节点的主从位置:
crm(live)# node standby node2.tanxw.com 把node2提升为备用的
crm(live)# node noline node2.tanxw.com 让node2上线
crm(live)# node standby node1.tanxw.com 把node1提升为备用的
crm(live)# node noline node1.tanxw.com 让node1上线,都可以随意切换一下再检测一下挂载的效果的;
LINUX 高可用群集之 ~Corosync~的更多相关文章
- 全是干货---Linux 高可用(HA)集群基本概念详解
http://www.linuxidc.com/Linux/2013-08/88522.htm 高可用集群的衡量标准 HA(High Available), 高可用性群集是通过系统的可靠性(re ...
- Linux 高可用(HA)集群基本概念详解
大纲一.高可用集群的定义二.高可用集群的衡量标准三.高可用集群的层次结构四.高可用集群的分类 五.高可用集群常用软件六.共享存储七.集群文件系统与集群LVM八.高可用集群的工作原理 推荐阅读: Cen ...
- http高可用+负载均衡 corosync + pacemaker + pcs
http高可用+负载均衡 corosync + pacemaker + pcsopenstack pike 部署 目录汇总 http://www.cnblogs.com/elvi/p/7613861. ...
- 高可用群集HA介绍与LVS+keepalived高可用群集
一.Keepalived介绍 通常使用keepalived技术配合LVS对director和存储进行双机热备,防止单点故障,keepalived专为LVS和HA设计的一款健康检查工具,但演变为后来不仅 ...
- 高可用集群corosync+pacemaker之crmsh使用(一)
上一篇博客我们聊了下高可用集群corosync+pacemaker的相关概念以及corosync的配置,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/13585 ...
- LVS+Keepalived 高可用群集部署
LVS+Keepalived 高可用群集部署 1.LVS+Keepalived 高可用群集概述 2.LVS+Keepalived高可用群集部署 1.LVS+Keepalived 高可用群集概述: LV ...
- 22.LVS+Keepalived 高可用群集
LVS+Keepalived 高可用群集 目录 LVS+Keepalived 高可用群集 keepalived工具介绍 Keepalived实现原理剖析 VRRP(虚拟路由冗余协议) VRRP 相关术 ...
- HaProxy+Keepalived+Mycat高可用群集配置
概述 本章节主要介绍配置HaProxy+Keepalived高可用群集,Mycat的配置就不在这里做介绍,可以参考我前面写的几篇关于Mycat的文章. 部署图: 配置 HaProxy安装 181和1 ...
- [ Openstack ] Openstack-Mitaka 高可用之 Pacemaker+corosync+pcs 高可用集群
目录 Openstack-Mitaka 高可用之 概述 Openstack-Mitaka 高可用之 环境初始化 Openstack-Mitaka 高可用之 Mariadb-Galera集群 ...
随机推荐
- Oracle-AWR报告简介及如何生成【转】
AWR报告 awr报告是oracle 10g及以上版本提供的一种性能收集和分析工具,它能提供一个时间段内整个系统资源使用情况的报告,通过这个报告,我们就可以了解Oracle数据库的整个运行情况,比如硬 ...
- 大数据系列之Hadoop框架
Hadoop框架中,有很多优秀的工具,帮助我们解决工作中的问题. Hadoop的位置 从上图可以看出,越往右,实时性越高,越往上,涉及到算法等越多. 越往上,越往右就越火…… Hadoop框架中一些简 ...
- The algorithm of entropy realization
近似熵的一种快速实用算法 Pincus提出的近似熵算法中有很多冗余的计算,效率低,速度慢,不利于实际应用,洪波等人在定义的基础上引入二值距离矩阵的概率,提出了一种实用快速的算法. function A ...
- webstrom 使用git
1.首先进入码云创建项目 2.创建成功,复制https地址,打开webstrom,选择git,填入https的地址 3.下载完成,打开项目,新建一个测试测HTML文件,点击右键,选择git,再选择ad ...
- [How to] 使用HBase协处理器---Endpoint服务端的实现
1.简介 前篇文章[How to] 使用HBase协处理器---基本概念和regionObserver的简单实现中提到了两种不同的协处理器,并且实现了regionObserver. 本文将介绍如何使用 ...
- word2vec参数
架构:skip-gram(慢.对罕见字有利)vs CBOW(快) · 训练算法:分层softmax(对罕见字有利)vs 负采样(对常见词和低纬向量有利) 负例采样准确率提高,速度会慢, ...
- 20165301 2017-2018-2 《Java程序设计》第六周学习总结
20165301 2017-2018-2 <Java程序设计>第六周学习总结 教材学习内容总结 第七章:常用实类 String类 构造String对象 常量对象 String对象 Stri ...
- hdu 5001(概率DP)
Walk Time Limit: 30000/15000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others)Total Subm ...
- python进行des加密解密,而且可以与JAVA进行互相加密解密
import binasciifrom pyDes import des, CBC, PAD_PKCS5import uuidimport time # pip install -i https:// ...
- 【LOJ】 #2009. 「SCOI2015」小凸玩密室
题解 神仙dp啊QAQ 我们发现我们需要枚举一个起点,遍历完它所有的儿子然后向上爬 设\(f[i][j]\)表示第i个点的子树全部处理完之后到达i深度为j的祖先的兄弟处 我们只需要对叶子节点和只有一个 ...