[Network Architecture]ResNext论文笔记(转)
文章地址: https://blog.csdn.net/u014380165/article/details/71667916
ResNeXt 结构可以在不增加参数复杂度的前提下提高准确率,同时还减少了超参数的数量(得益于子模块的拓扑结构一样,后面会讲)。
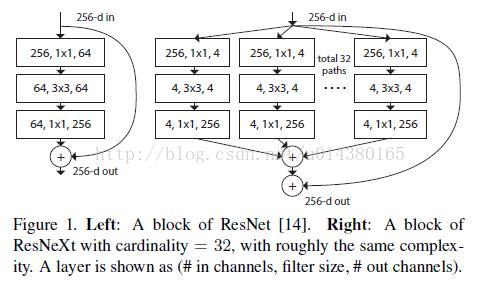
size of the set of transformations,如下图 Fig1 右边是 cardinality=32 的样子,这里注意每个被聚合的拓扑结构都是一样的(这也是和 Inception 的差别,减轻设计负担)

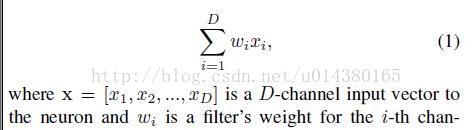
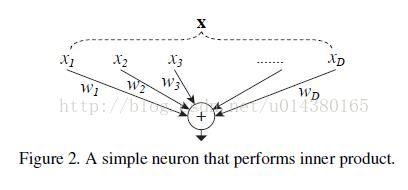
in Neuron,式子如下:
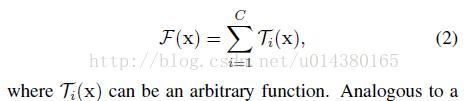
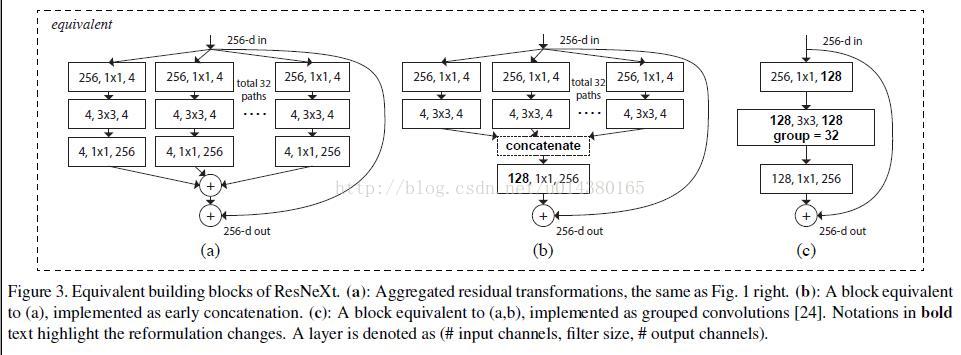
convolutions,这个 group 参数就是 caffe 的 convolusion 层的 group 参数,用来限制本层卷积核和输入 channels 的卷积,最早应该是 AlexNet 上使用,可以减少计算量。这里 fig 3.c 采用32个 group,每个 group 的输入输出 channels 都是4,最后把channels合并。这张图的 fig3.c 和 fig1 的左边图很像,差别在于fig3.c的中间 filter 数量(此处为128,而fig 1中为64)更多。作者在文中明确说明这三种结构是严格等价的,并且用这三个结构做出来的结果一模一样,在本文中展示的是
fig3.c 的结果,因为 fig3.c 的结构比较简洁而且速度更快。

文章来源: https://www.cnblogs.com/lillylin/p/6799173.html
Saining——【arXiv2017】Aggregated Residual Transformations for Deep Neural Networks
目录
- 作者和相关链接
- 主要思想
- ResNet和ResNext对比
作者和相关链接
- 作者

主要思想
- 要解决的问题是什么?
对于ResNet,VGG,Inception等网络,需要由一些重复的building block堆叠而成,而这些building block的滤波器个数,大小等不能任意设置,需要人工调整。由于其中有很多超参数需要调整,而且在不同的vision task甚至是不同的dataset上参数不能直接共享需要进行个性化定制,因此,这种需要为一定task或者dataset定制的module虽然效果好,但通用性太差。这篇文章介绍了一种新的building block,可以用来替换ResNet的building block,新的模型称为ResNeXt。ResNeXt的最大优势在于整个网络的building block都是一样的,不用在每个stage里再对每个building block的超参数进行调整,只用一个building block,重复堆叠即可形成整个网络。实验结果表明ResNeXt比ResNet在同样模型大小的情况下效果更好。
- 解决思路?
将ResNet的blcok(如图Figure 1的左图所示)换成ResNeXt的block(如图Figure 1的右图所示),实际上是将左边的64个卷积核分成了右边32条不同path,每个path有4个卷积核,最后的32个path将输出向量直接pixel-wise相加(所有通道对应位置点相加),再与Short Cut相加
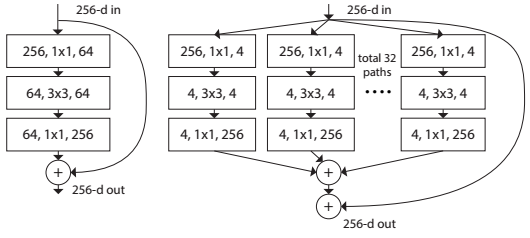 Figure 1. Left: A block of ResNet [13]. Right: A block of ResNeXt with cardinality = 32, with roughly the same complexity. A layer is shown as (# in channels, filter size, # out channels)
Figure 1. Left: A block of ResNet [13]. Right: A block of ResNeXt with cardinality = 32, with roughly the same complexity. A layer is shown as (# in channels, filter size, # out channels)
- Cardinality和Bottleneck
这篇文章提出了一种新的衡量模型容量(capacity,指的是模型拟合各种函数的能力)。在此之前,模型容量有宽度(width)和高度(height)这两种属性,本文提出的“Cardinality”指的是网络结构中的building block的变换的集合大小(the size of the set of transformation)。如图Figure 2所示,(a)、(b)、(c)三种结构是等价的,本文用的是图(c)。实际上Cardinality指的就是Figure 2(b)中path数或Figure 2(c)中group数,即每一条path或者每一个group表示一种transformation,因此path数目或者group个数即为Cardinality数。Bottleneck指的是在每一个path或者group中,中间过渡形态的feature map的channel数目(或者卷积核个数),如Figure 2(a)中,在每一条path中,对于输入256维的向量,使用了4个1*1*256的卷积核进行卷积后得到了256*4的feature map,即4个channel,每个channel的feature map大小为256维,因此,Bottleneck即为4。
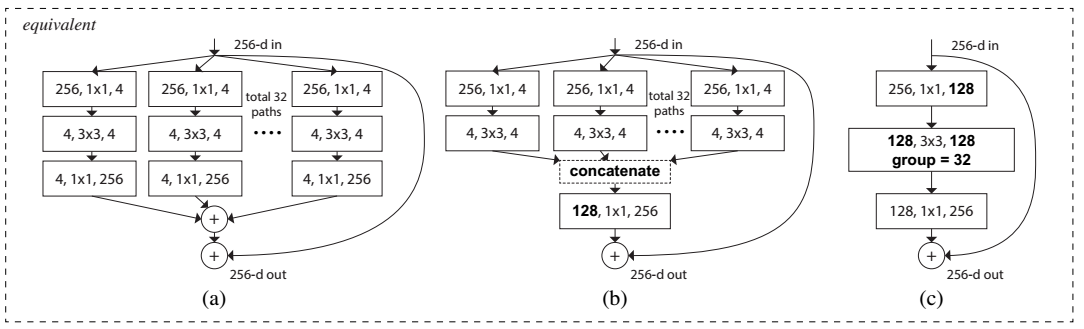
Figure 2. Equivalent building blocks of ResNeXt. (a): Aggregated residual transformations, the same as Fig. 1 right. (b): A block equivalent to (a), implemented as early concatenation. (c): A block equivalent to (a,b), implemented as grouped convolutions [23]. Notations in bold text highlight the reformulation changes. A layer is denoted as (# input channels, filter size, # output channels).
ResNet和ResNeXt对比
- 网络结构对比
图Figure 2所示表示的depth=3的情况下ResNet和ResNeXt的building block的对比。
- 具体配置对比
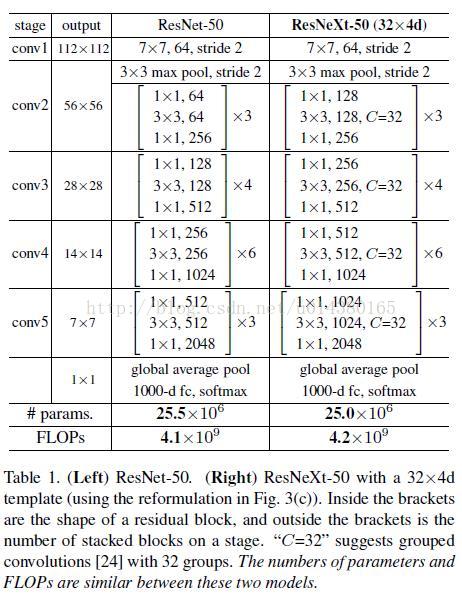
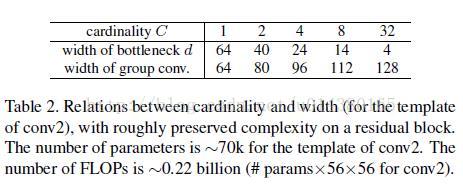
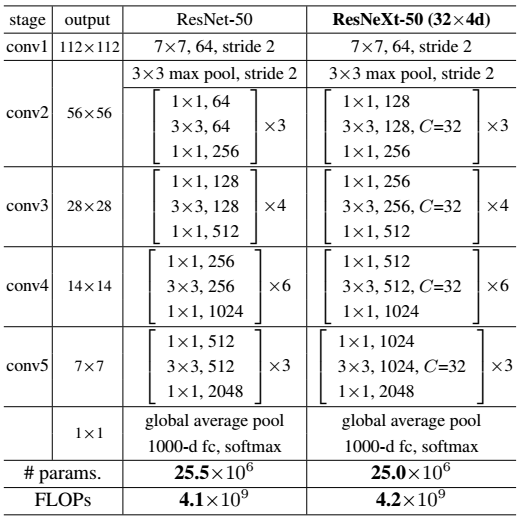
ResNet-50和ResNeXt-50的building block的配置对比如Table 1所示,图中C=32即表示Cardinality=32,Bottleneck= 4,即如图Figure 2中所示。
Table 1. (Left) ResNet-50. (Right) ResNeXt-50 with a 32×4d template (using the reformulation in Fig. 3(c)). Inside the brackets are the shape of a residual block, and outside the brackets is the number of stacked blocks on a stage. “C=32” suggests grouped convolutions [23] with 32 groups. The numbers of parameters and FLOPs are similar between these two models.
- 模型大小计算
以图Figure 3为例,ResNet的参数个数为256 · 64 + 3 · 3 · 64 · 64 + 64 · 256 ≈ 70k 。
ResNeXt的参数个数为C · (256 · d + 3 · 3 · d · d + d · 256),其中,C表示Cardinality=32,d表示bottleneck=4,因此参数总数 ≈ 70k 。

Figure 3. Left: A block of ResNet [13]. Right: A block of ResNeXt with cardinality = 32, with roughly the same complexity. A layer is shown as (# in channels, filter size, # out channels)
- 实验结果对比
- 证明ResNeXt比ResNet更好,而且Cardinality越大效果越好
Table 2. Ablation experiments on ImageNet-1K. (Top): ResNet-50 with preserved complexity (∼4.1 billion FLOPs); (Bottom): ResNet-101 with preserved complexity ∼7.8 billion FLOPs). The error rate is evaluated on the single crop of 224×224 pixels.

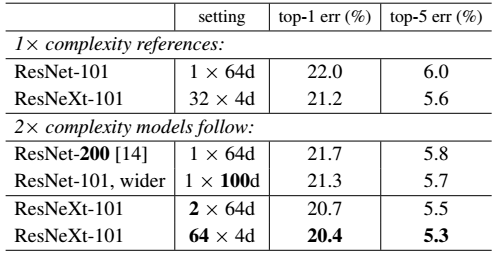
- 证明增大Cardinality比增大模型的width或者depth效果更好
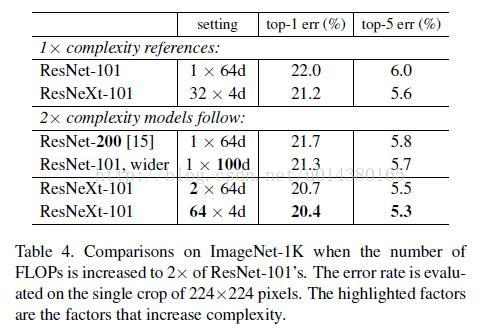
Table 3. Comparisons on ImageNet-1K when the number of FLOPs is increased to 2× of ResNet-101’s. The error rate is evaluated on the single crop of 224×224 pixels. The highlighted factors are the factors that increase complexity.
[Network Architecture]ResNext论文笔记(转)的更多相关文章
- [Network Architecture]Xception 论文笔记(转)
文章来源 论文:Xception: Deep Learning with Depthwise Separable Convolutions 论文链接:https://arxiv.org/abs/161 ...
- 论文笔记系列-Neural Network Search :A Survey
论文笔记系列-Neural Network Search :A Survey 论文 笔记 NAS automl survey review reinforcement learning Bayesia ...
- 论文笔记:CNN经典结构2(WideResNet,FractalNet,DenseNet,ResNeXt,DPN,SENet)
前言 在论文笔记:CNN经典结构1中主要讲了2012-2015年的一些经典CNN结构.本文主要讲解2016-2017年的一些经典CNN结构. CIFAR和SVHN上,DenseNet-BC优于ResN ...
- 【论文笔记】Malware Detection with Deep Neural Network Using Process Behavior
[论文笔记]Malware Detection with Deep Neural Network Using Process Behavior 论文基本信息 会议: IEEE(2016 IEEE 40 ...
- 论文笔记: Dual Deep Network for Visual Tracking
论文笔记: Dual Deep Network for Visual Tracking 2017-10-17 21:57:08 先来看文章的流程吧 ... 可以看到,作者所总结的三个点在于: 1. ...
- Face Aging with Conditional Generative Adversarial Network 论文笔记
Face Aging with Conditional Generative Adversarial Network 论文笔记 2017.02.28 Motivation: 本文是要根据最新的条件产 ...
- 论文笔记 《Maxout Networks》 && 《Network In Network》
论文笔记 <Maxout Networks> && <Network In Network> 发表于 2014-09-22 | 1条评论 出处 maxo ...
- 论文笔记系列-Auto-DeepLab:Hierarchical Neural Architecture Search for Semantic Image Segmentation
Pytorch实现代码:https://github.com/MenghaoGuo/AutoDeeplab 创新点 cell-level and network-level search 以往的NAS ...
- 论文笔记之:Dueling Network Architectures for Deep Reinforcement Learning
Dueling Network Architectures for Deep Reinforcement Learning ICML 2016 Best Paper 摘要:本文的贡献点主要是在 DQN ...
随机推荐
- ROS 笔记
ros的编程范式 - ros认为,linux平台下,机器人的软件由一个个小程序组成,这些小程序称为node,每个小程序负责一部分功能 - ros实现的框架就是,小程序的并发执行+相互通信,程序(进程) ...
- 如何使文本溢出边界不换行强制在一行内显示?#test{width:150px;white-space:nowrap;}
#test{width:150px;white-space:nowrap;}
- ubuntu安装mysql步骤
https://dev.mysql.com/downloads/file/?id=477124 ubuntu上安装mysql非常简单只需要几条命令就可以完成. 1. sudo apt-get inst ...
- Ant-Design如何使用
1.下载Node.js Node.js的版本需要不低于V4.x,本不在省略,如果需要出门左转Node.js安装教程. 查看Node.js版本: C:\Users\Administrator>no ...
- ubuntu安装markdown
# sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys BA300B7755AFCFAE linuxidc@linuxidc:~ ...
- wpa安装方法
1.openssl 2.lib 1.1.2 3.wpa lua 编译错误 http://www.blogjava.net/xiaomage234/archive/2013/09/13/404037.h ...
- ALV tree标准DEMO
BCALV_TREE_01 ALV 树控制:构建层次树 BCALV_TREE_02 ALV 树控制:事件处理 BCALV_TREE_03 ALV 树控制:使用自己的上下文菜单 BCALV_TREE_0 ...
- Mysql binlog 安全删除(转载)
简介: 如果你的 Mysql 搭建了主从同步 , 或者数据库开启了 log-bin 日志 , 那么随着时间的推移 , 你的数据库 data 目录下会产生大量的日志文件 shell > ll /u ...
- What does Quick Sort look like in Python?
Let's talk about something funny at first. Have you ever implemented the Quick Sort algorithm all by ...
- ruby on rails 数据库操作
(1)增加列的操作 rails generate migration add_password_digest_to_students password_digest:string bundle exe ...