Hadoop MapReduce 操作 统计词频
1、 准备文件并设置编码格式为UTF-8并上传Linux
1)设置编码:首先打开文件点击左上角 文件(F) 点击另存为并将编码(E)设置为UTF-8 然后保存(S)替换的原来的文件
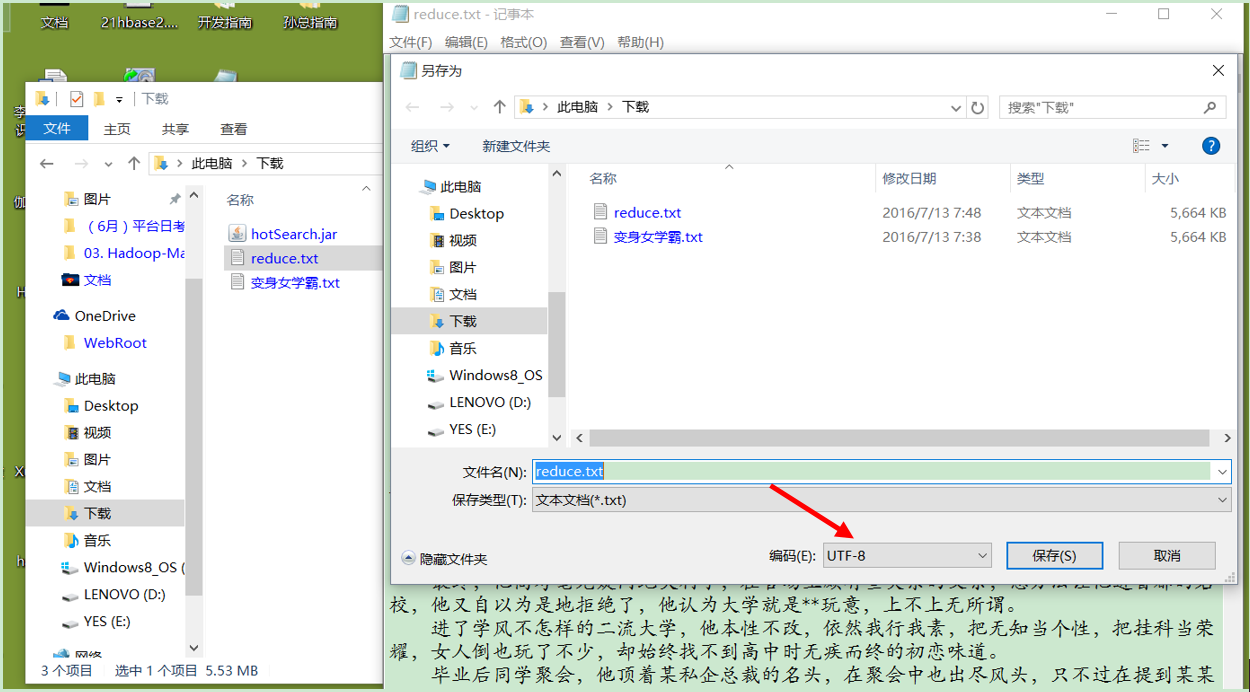
2)用工具将文件上传就Linux
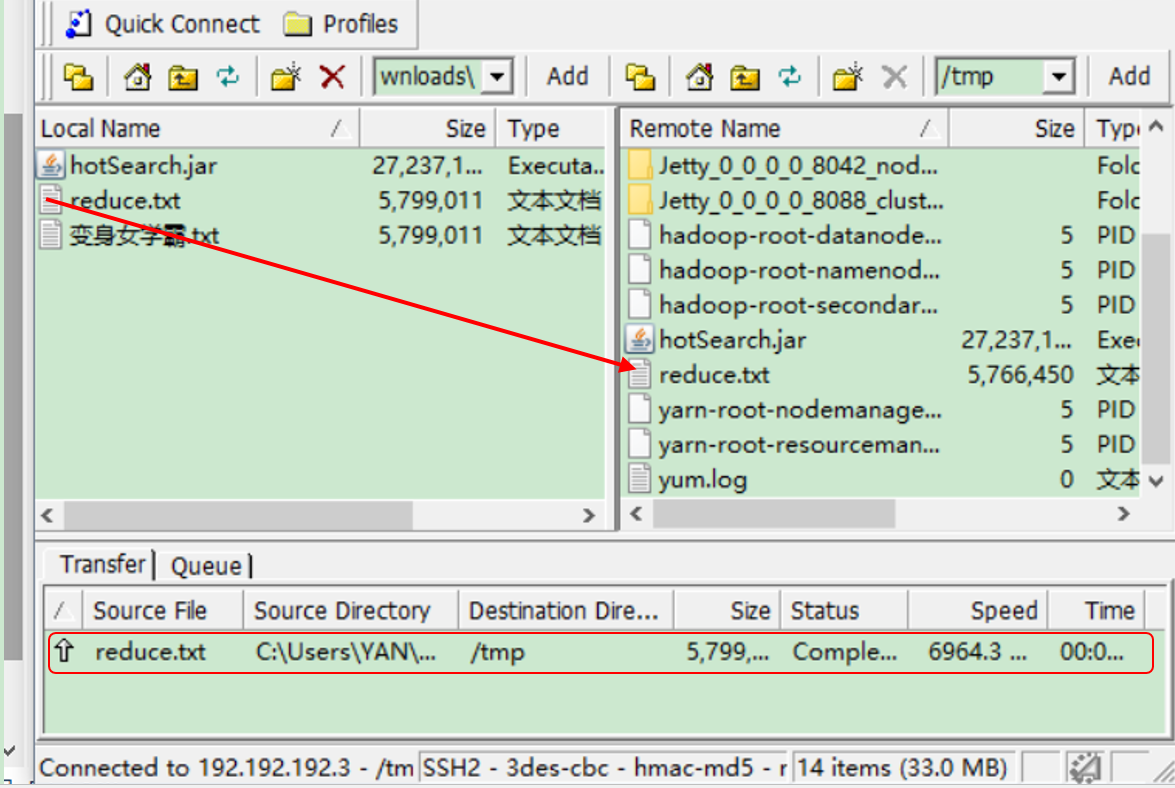
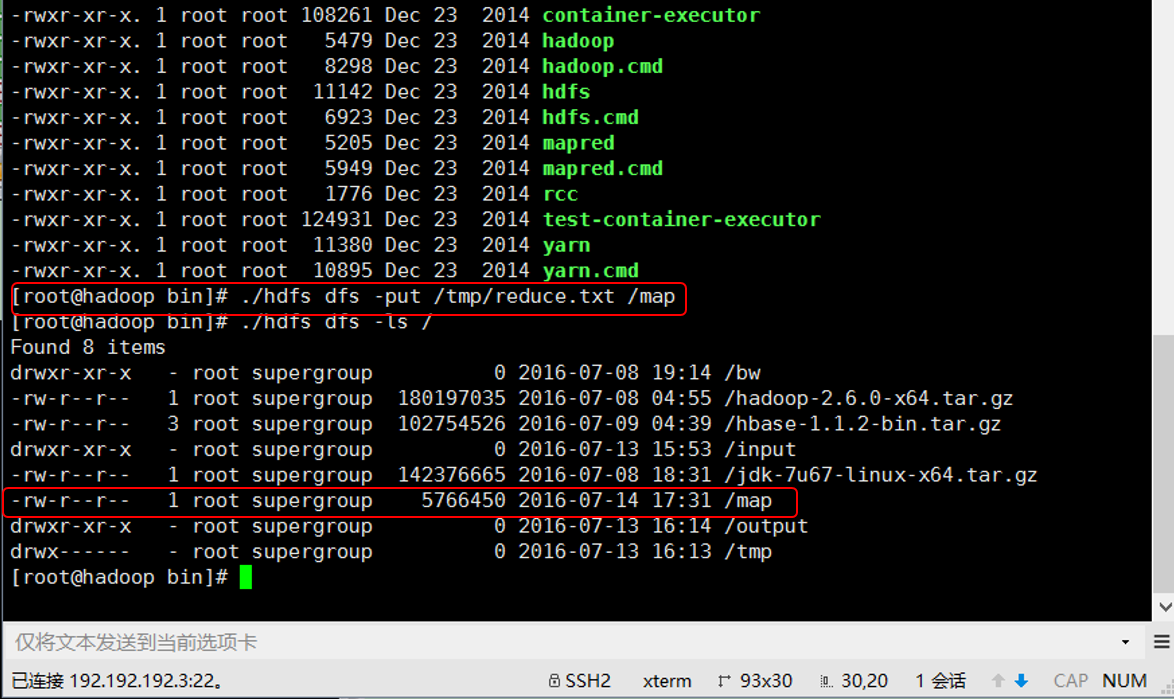
3)将文件上传至HDFS
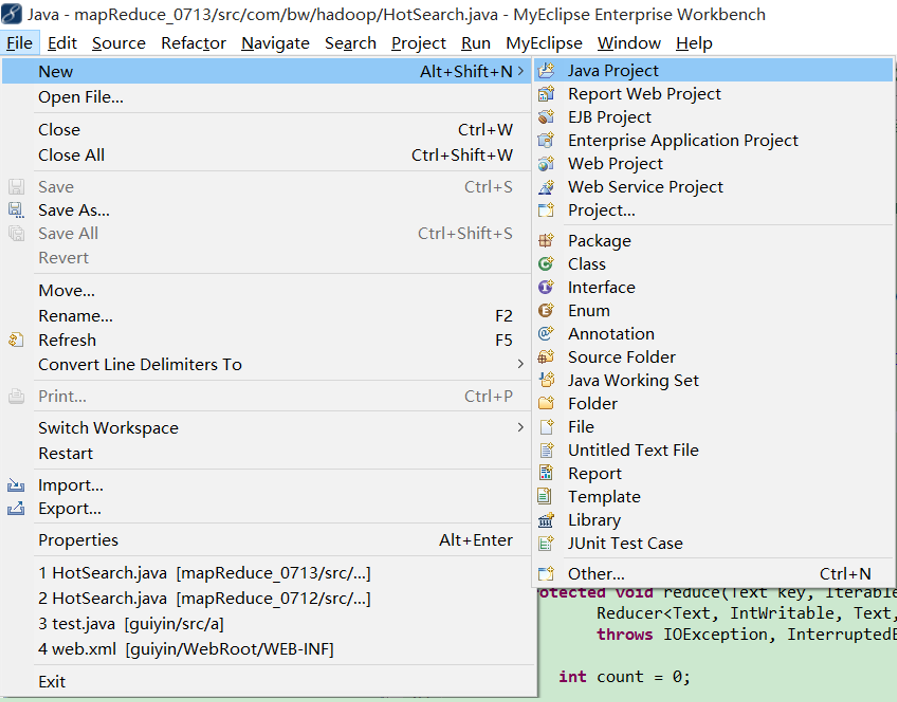
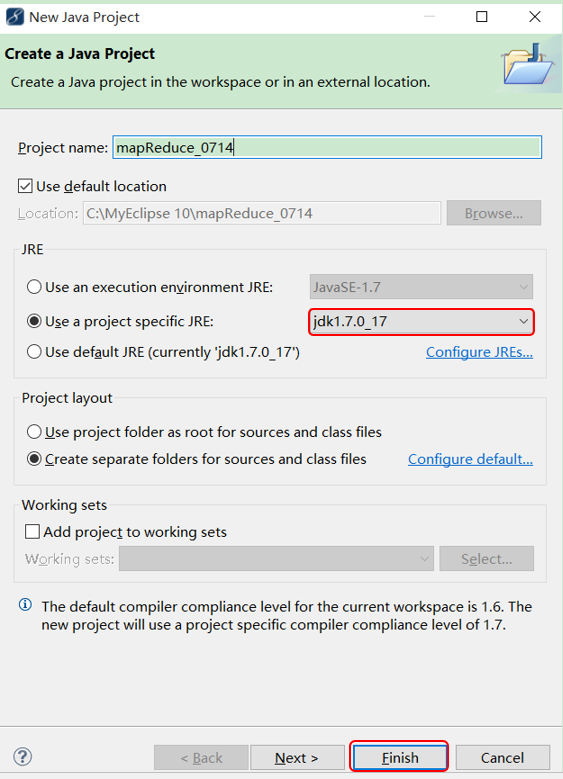
2、 新建一个Java Project
JDK必须是1.7版本以后的否则不支持

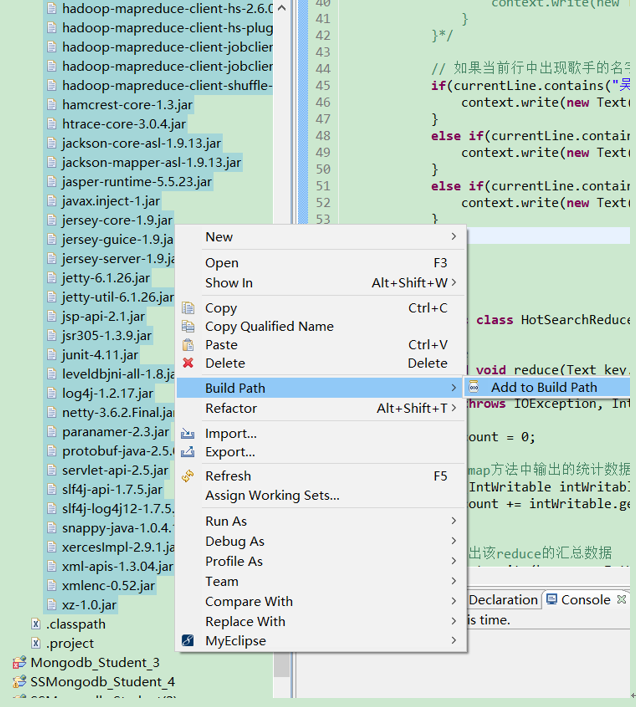
3、 导入jar
导入好多jar包并Add to Build Path

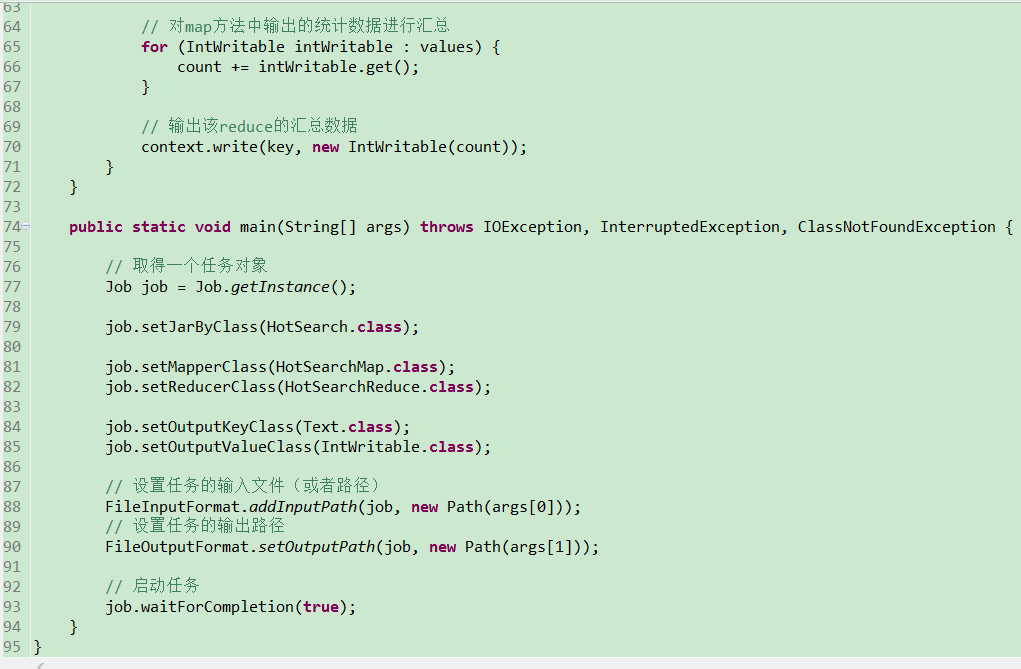
4、 编写Map()和Reduce()

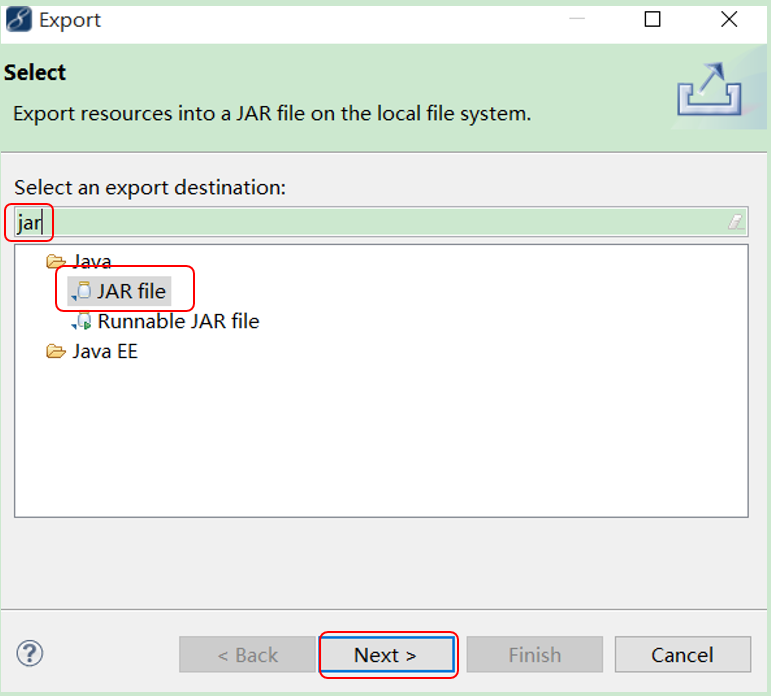
5、将代码输出成jar
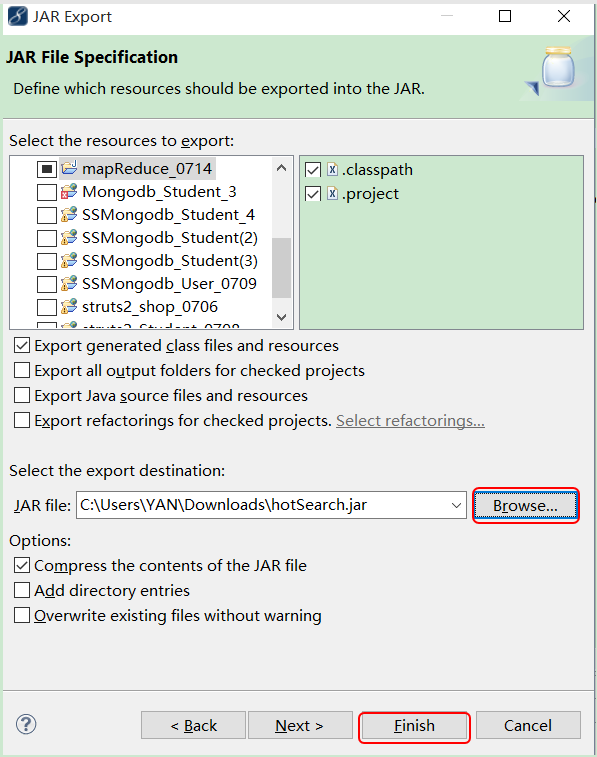
1) 将代码输出成jar

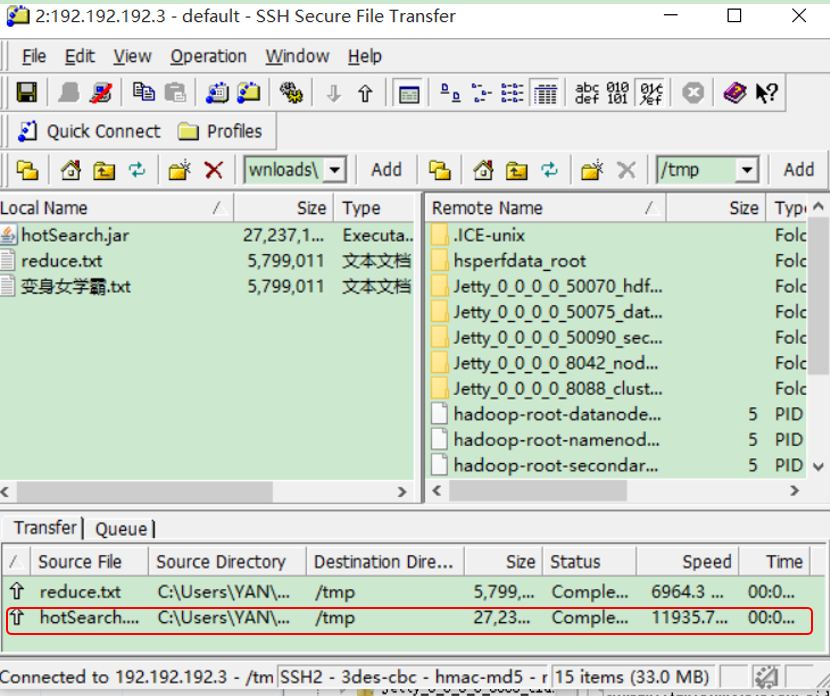
2) 将生成的jar上传至Linux
6、在linux中启动hdfs
1) 启动hdfs

1) 将text文件上传到HDFS

7、修改两个配置文件

在<configuration>配置项中增加以下内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
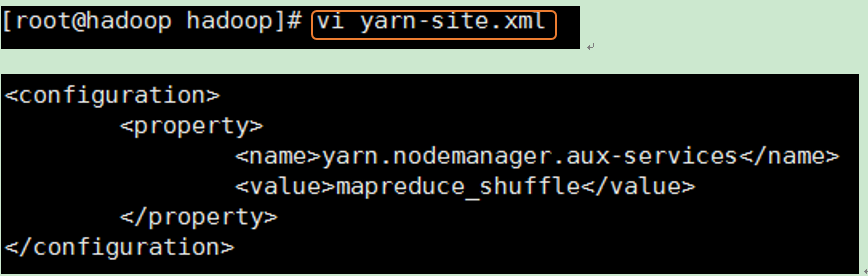
在<configuration>配置项中增加以下内容:
(参数解释:NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运MapReduce程序)
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
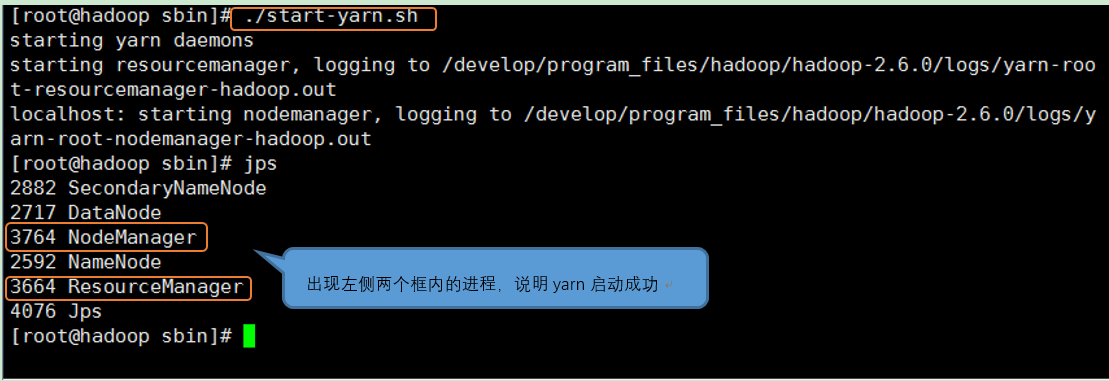
8、在linux中启动yarn
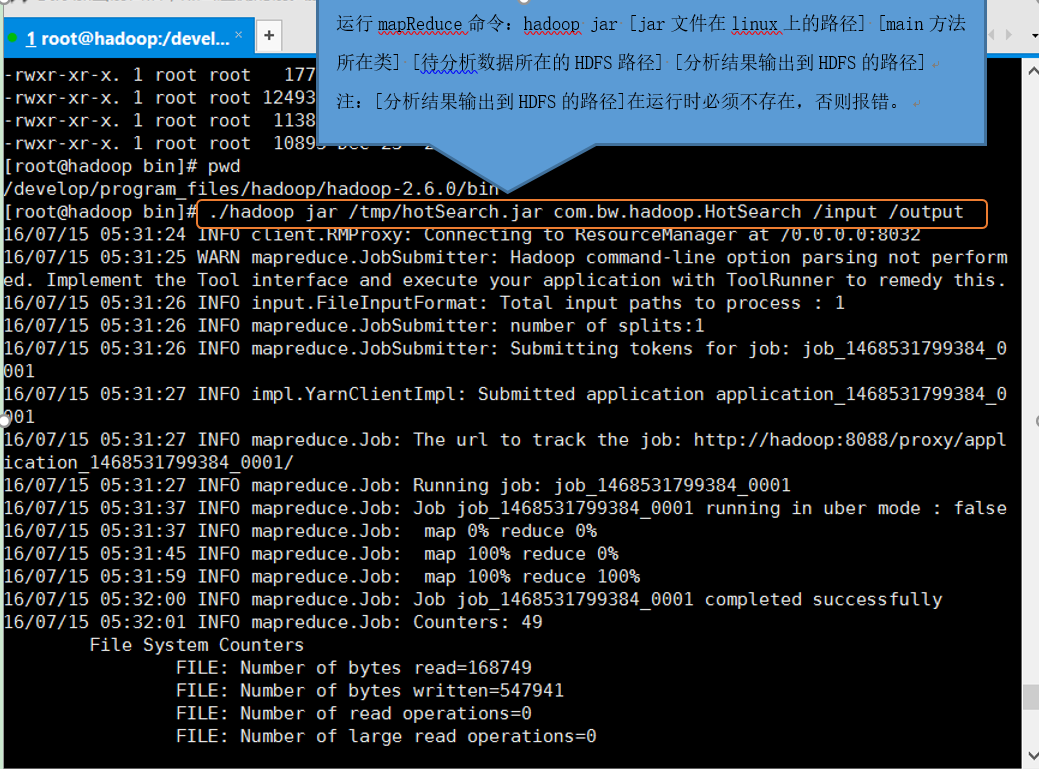
9、运行mapReduce
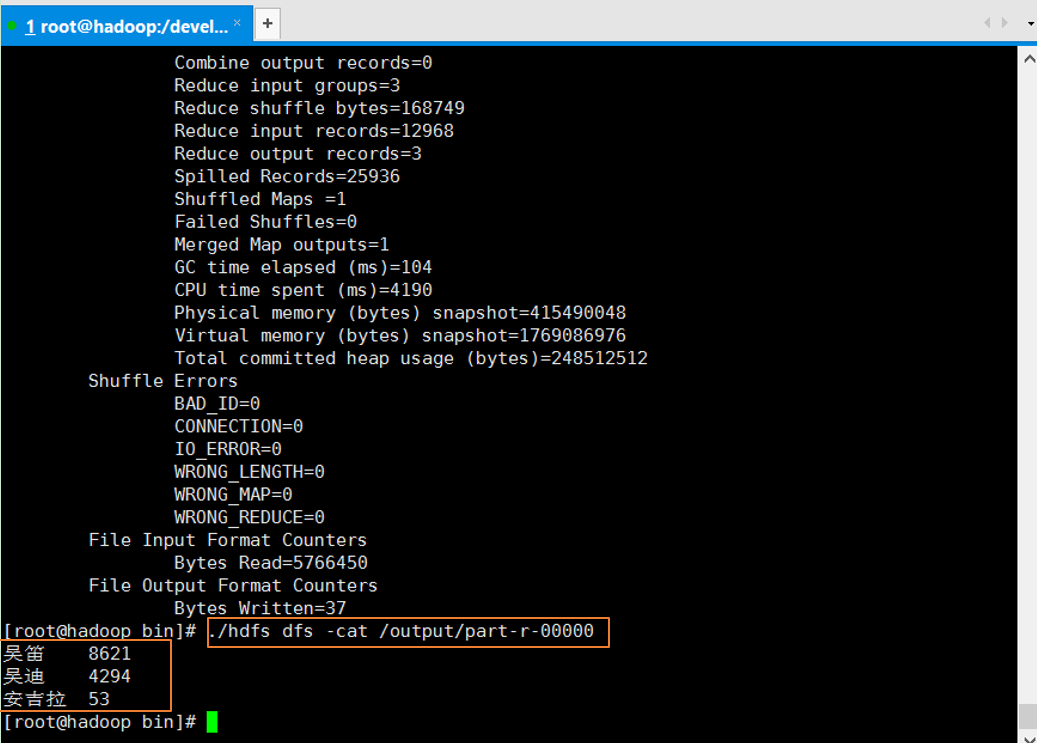
10、查看运行结果
Hadoop MapReduce 操作 统计词频的更多相关文章
- Hadoop,MapReduce操作Mysql
前以前帖子介绍,怎样读取文本数据源和多个数据源的合并:http://www.cnblogs.com/liqizhou/archive/2012/05/15/2501835.html 这一个博客介绍一下 ...
- Hadoop MapReduce编程学习
一直在搞spark,也没时间弄hadoop,不过Hadoop基本的编程我觉得我还是要会吧,看到一篇不错的文章,不过应该应用于hadoop2.0以前,因为代码中有 conf.set("map ...
- Hadoop Mapreduce 案例 wordcount+统计手机流量使用情况
mapreduce设计思想 概念:它是一个分布式并行计算的应用框架它提供相应简单的api模型,我们只需按照这些模型规则编写程序,即可实现"分布式并行计算"的功能. 案例一:word ...
- 【Cloud Computing】Hadoop环境安装、基本命令及MapReduce字数统计程序
[Cloud Computing]Hadoop环境安装.基本命令及MapReduce字数统计程序 1.虚拟机准备 1.1 模板机器配置 1.1.1 主机配置 IP地址:在学校校园网Wifi下连接下 V ...
- Hadoop MapReduce编程 API入门系列之薪水统计(三十一)
不多说,直接上代码. 代码 package zhouls.bigdata.myMapReduce.SalaryCount; import java.io.IOException; import jav ...
- 023_数量类型练习——Hadoop MapReduce手机流量统计
1) 分析业务需求:用户使用手机上网,存在流量的消耗.流量包括两部分:其一是上行流量(发送消息流量),其二是下行流量(接收消息的流量).每种流量在网络传输过程中,有两种形式说明:包的大小,流量的大小. ...
- Hadoop MapReduce编程 API入门系列之统计学生成绩版本2(十八)
不多说,直接上代码. 统计出每个年龄段的 男.女 学生的最高分 这里,为了空格符的差错,直接,我们有时候,像如下这样的来排数据. 代码 package zhouls.bigdata.myMapRedu ...
- hadoop MapReduce运营商案例关于用户基站停留数据统计
注 如果需要文件和代码的话可评论区留言邮箱,我给你发源代码 本文来自博客园,作者:Arway,转载请注明原文链接:https://www.cnblogs.com/cenjw/p/hadoop-mapR ...
- Hadoop最基本的wordcount(统计词频)
package com.uniclick.dapa.dstest; import java.io.IOException; import java.net.URI; import org.apache ...
随机推荐
- tensorflow入门(三)
三种代价函数 1,二次代价函数 式子代表预测值与样本值的差得平方和 由于使用的是梯度下降法,我们对变量w,b分别求偏导: 这种函数对于处理线性的关系比较好,但是如果遇到s型函数(如下图所示),效率 ...
- Java导出Excel(有数据库导出代码)
/** * 导出 * @param request * @param response * @throws Exception */ @SuppressWarnings("unchecked ...
- Spring Boot配置ContextPath【从零开始学Spring Boot】
Spring boot默认是/ ,这样直接通过http://ip:port/就可以访问到index页面,如果要修改为http://ip:port/path/ 访问的话,那么需要在Application ...
- HDU 4734 F(x) ★(数位DP)
题意 一个整数 (AnAn-1An-2 ... A2A1), 定义 F(x) = An * 2n-1 + An-1 * 2n-2 + ... + A2 * 2 + A1 * 1,求[0..B]内有多少 ...
- poj 1258 Agri-Net 最小生成树 prim算法+heap不完全优化 难度:0
Agri-Net Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 41230 Accepted: 16810 Descri ...
- hdu3488
题解: 首先把每一个点拆到两边 然后做KM求最大 吧没一条边相反即可 代码: #include<cstdio> #include<cmath> #include<algo ...
- 【jQuery】IE9 jQuery 1.9.1 报 Syntax error,unrecognized expression 错误
<script type="ctrip-template-x" id="ctrip-page-index"> <article class=& ...
- Redis数据结构:SDS
1. 简单动态字符串(simple dynamic string,SDS)是Redis的默认字符串表示结构,底层的string都是基于SDS实现.Redis基于C语言,并引用了部分C函数. 使用场景: ...
- String类的编码和解码问题
我们前面知道同一个字符在利用不同的编码表得到的结果一般是不一样的. 这里讨论个字符串的编码和解码问题 字符串的一些方法: String(byte[] b,Charset charset); Strin ...
- SpringInAction--自动化装配Bean(隐式装配)
关于Bean的介绍就具体不多介绍了,,, Spring在配置时候有三种方案可选 1.在xml中进行显示配置 2.在java中进行显示配置 3.隐式的Bean发现机制和自动装配 今天学习的就是自动化装配 ...