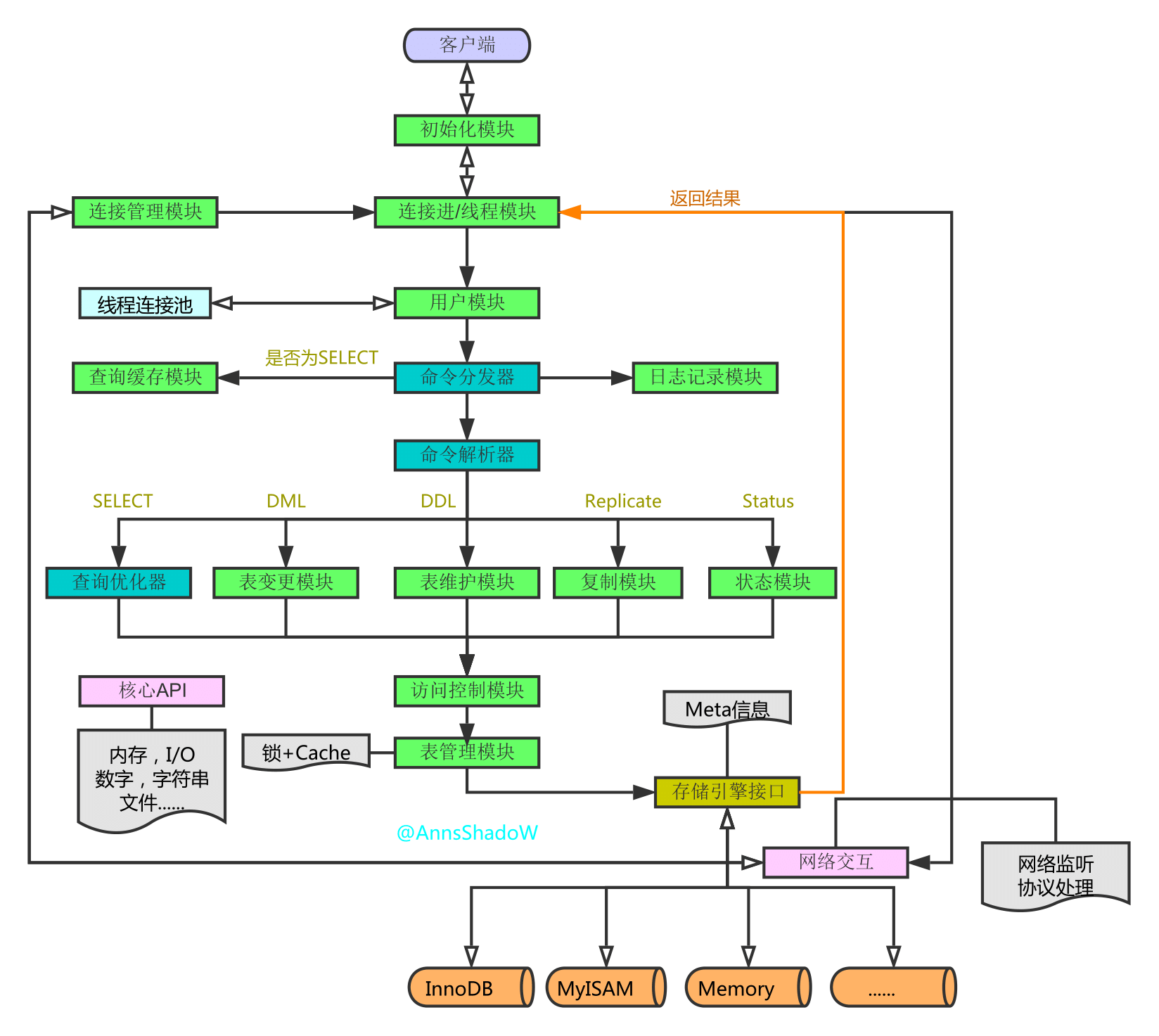
步步深入:MySQL架构总览->查询执行流程->SQL解析顺序
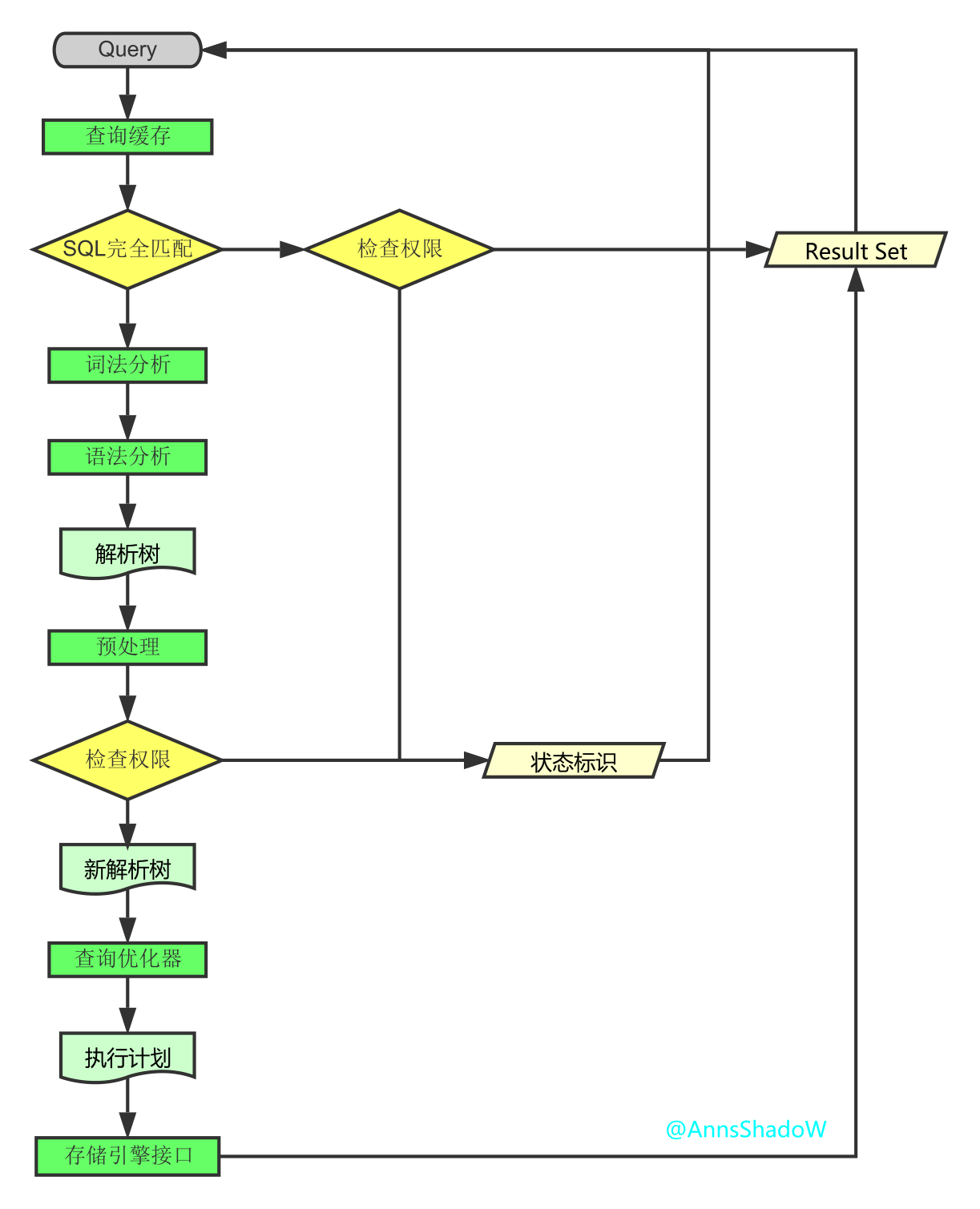
SELECT DISTINCT
< select_list >
FROM
< left_table > < join_type >
JOIN < right_table > ON < join_condition >
WHERE
< where_condition >
GROUP BY
< group_by_list >
HAVING
< having_condition >
ORDER BY
< order_by_condition >
LIMIT < limit_number >
FROM <left_table>
ON <join_condition>
<join_type> JOIN <right_table>
WHERE <where_condition>
GROUP BY <group_by_list>
HAVING <having_condition>
SELECT
DISTINCT <select_list>
ORDER BY <order_by_condition>
LIMIT <limit_number>
create database testQuery
CREATE TABLE table1
(
uid VARCHAR(10) NOT NULL,
name VARCHAR(10) NOT NULL,
PRIMARY KEY(uid)
)ENGINE=INNODB DEFAULT CHARSET=UTF8; CREATE TABLE table2
(
oid INT NOT NULL auto_increment,
uid VARCHAR(10),
PRIMARY KEY(oid)
)ENGINE=INNODB DEFAULT CHARSET=UTF8;
INSERT INTO table1(uid,name) VALUES('aaa','mike'),('bbb','jack'),('ccc','mike'),('ddd','mike');
INSERT INTO table2(uid) VALUES('aaa'),('aaa'),('bbb'),('bbb'),('bbb'),('ccc'),(NULL);
SELECT
a.uid,
count(b.oid) AS total
FROM
table1 AS a
LEFT JOIN table2 AS b ON a.uid = b.uid
WHERE
a. NAME = 'mike'
GROUP BY
a.uid
HAVING
count(b.oid) < 2
ORDER BY
total DESC
LIMIT 1;
mysql> select * from table1,table2;
+-----+------+-----+------+
| uid | name | oid | uid |
+-----+------+-----+------+
| aaa | mike | 1 | aaa |
| bbb | jack | 1 | aaa |
| ccc | mike | 1 | aaa |
| ddd | mike | 1 | aaa |
| aaa | mike | 2 | aaa |
| bbb | jack | 2 | aaa |
| ccc | mike | 2 | aaa |
| ddd | mike | 2 | aaa |
| aaa | mike | 3 | bbb |
| bbb | jack | 3 | bbb |
| ccc | mike | 3 | bbb |
| ddd | mike | 3 | bbb |
| aaa | mike | 4 | bbb |
| bbb | jack | 4 | bbb |
| ccc | mike | 4 | bbb |
| ddd | mike | 4 | bbb |
| aaa | mike | 5 | bbb |
| bbb | jack | 5 | bbb |
| ccc | mike | 5 | bbb |
| ddd | mike | 5 | bbb |
| aaa | mike | 6 | ccc |
| bbb | jack | 6 | ccc |
| ccc | mike | 6 | ccc |
| ddd | mike | 6 | ccc |
| aaa | mike | 7 | NULL |
| bbb | jack | 7 | NULL |
| ccc | mike | 7 | NULL |
| ddd | mike | 7 | NULL |
+-----+------+-----+------+
28 rows in set (0.00 sec)
mysql> SELECT
-> *
-> FROM
-> table1,
-> table2
-> WHERE
-> table1.uid = table2.uid
-> ;
+-----+------+-----+------+
| uid | name | oid | uid |
+-----+------+-----+------+
| aaa | mike | 1 | aaa |
| aaa | mike | 2 | aaa |
| bbb | jack | 3 | bbb |
| bbb | jack | 4 | bbb |
| bbb | jack | 5 | bbb |
| ccc | mike | 6 | ccc |
+-----+------+-----+------+
6 rows in set (0.00 sec)
mysql> SELECT
-> *
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid;
+-----+------+------+------+
| uid | name | oid | uid |
+-----+------+------+------+
| aaa | mike | 1 | aaa |
| aaa | mike | 2 | aaa |
| bbb | jack | 3 | bbb |
| bbb | jack | 4 | bbb |
| bbb | jack | 5 | bbb |
| ccc | mike | 6 | ccc |
| ddd | mike | NULL | NULL |
+-----+------+------+------+
7 rows in set (0.00 sec)

mysql> SELECT
-> *
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike';
+-----+------+------+------+
| uid | name | oid | uid |
+-----+------+------+------+
| aaa | mike | 1 | aaa |
| aaa | mike | 2 | aaa |
| ccc | mike | 6 | ccc |
| ddd | mike | NULL | NULL |
+-----+------+------+------+
4 rows in set (0.00 sec)
mysql> SELECT
-> *
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid;
+-----+------+------+------+
| uid | name | oid | uid |
+-----+------+------+------+
| aaa | mike | 1 | aaa |
| ccc | mike | 6 | ccc |
| ddd | mike | NULL | NULL |
+-----+------+------+------+
3 rows in set (0.00 sec)
mysql> SELECT
-> *
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid
-> HAVING
-> count(b.oid) < 2;
+-----+------+------+------+
| uid | name | oid | uid |
+-----+------+------+------+
| ccc | mike | 6 | ccc |
| ddd | mike | NULL | NULL |
+-----+------+------+------+
2 rows in set (0.00 sec)
mysql> SELECT
-> a.uid,
-> count(b.oid) AS total
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid
-> HAVING
-> count(b.oid) < 2;
+-----+-------+
| uid | total |
+-----+-------+
| ccc | 1 |
| ddd | 0 |
+-----+-------+
2 rows in set (0.00 sec)
mysql> SELECT
-> a.uid,
-> count(b.oid) AS total
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid
-> HAVING
-> count(b.oid) < 2
-> ORDER BY
-> total DESC;
+-----+-------+
| uid | total |
+-----+-------+
| ccc | 1 |
| ddd | 0 |
+-----+-------+
2 rows in set (0.00 sec)
mysql> SELECT
-> a.uid,
-> count(b.oid) AS total
-> FROM
-> table1 AS a
-> LEFT JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid
-> HAVING
-> count(b.oid) < 2
-> ORDER BY
-> total DESC
-> LIMIT 1;
+-----+-------+
| uid | total |
+-----+-------+
| ccc | 1 |
+-----+-------+
1 row in set (0.00 sec)

步步深入:MySQL架构总览->查询执行流程->SQL解析顺序的更多相关文章
- MySQL架构总览->查询执行流程->SQL解析顺序
Reference: https://www.cnblogs.com/annsshadow/p/5037667.html 前言: 一直是想知道一条SQL语句是怎么被执行的,它执行的顺序是怎样的,然后 ...
- 步步深入:MySQL架构总览->查询执行流程->SQL解析顺序(转)
文章转自 http://www.cnblogs.com/annsshadow/p/5037667.html https://www.cnblogs.com/cuisi/p/7685893.html
- 步步深入MySQL:架构->查询执行流程->SQL解析顺序!
一.前言 一直是想知道一条SQL语句是怎么被执行的,它执行的顺序是怎样的,然后查看总结各方资料,就有了下面这一篇博文了. 本文将从MySQL总体架构--->查询执行流程--->语句执行顺序 ...
- 让MySQL为我们记录执行流程
让MySQL为我们记录执行流程 我们可以开启profiling,让MySQL为我们记录SQL语句的执行流程 查看profiling参数 shell > select @@profilin ...
- mysql join语句的执行流程是怎么样的
mysql join语句的执行流程是怎么样的 join语句是使用十分频繁的sql语句,同样结果的join语句,写法不同会有非常大的性能差距. select * from t1 straight_joi ...
- MySQL深层理解,执行流程
MySQL是一个关系型数据库,关联的数据保存在不同的表中,增加了数据操作的灵活性. 执行流程 MySQL是一个单进程服务,每一个请求用线程来响应, 流程: 1,客户请求,服务器开辟一个线程响应用户. ...
- Spark架构与作业执行流程简介(scala版)
在讲spark之前,不得不详细介绍一下RDD(Resilient Distributed Dataset),打开RDD的源码,一开始的介绍如此: 字面意思就是弹性分布式数据集,是spark中最基本的数 ...
- mysql update语句的执行流程是怎样的
update更新语句流程是怎么样的 update更新语句基本流程也会查询select流程一样,都会走一遍. update涉及更新数据,会对行加dml写锁,这个DML读锁是互斥的.其他dml写锁需要等待 ...
- SQL学习笔记四(补充-1-1)之MySQL单表查询补充部分:SQL逻辑查询语句执行顺序
阅读目录 一 SELECT语句关键字的定义顺序 二 SELECT语句关键字的执行顺序 三 准备表和数据 四 准备SQL逻辑查询测试语句 五 执行顺序分析 一 SELECT语句关键字的定义顺序 SELE ...
随机推荐
- React Native 环境搭建
1,安装 HomeBrew /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install ...
- iOS-推送,证书申请,本地推送
介绍一点点背景资料 众所周知,使用推送通知是一个很棒的.给应用添加实时消息通知的方式.这样做的结局是,开发者和用户之间,彼此永远保持着一种令人愉悦的亲密关系. 然而不幸的是,iOS的推送通知并非那么容 ...
- jQuery之常用且重要方法梳理(target,arguments,slice,substring,data,trigger,Attr)-(一)
1.jquery data(name) data() 方法向被选元素附加数据,或者从被选元素获取数据. $("#btn1").click(function(){ $(" ...
- 【译】Unity3D Shader 新手教程(3/6) —— 更加真实的积雪
本文为翻译,附上原文链接. 转载请注明出处--polobymulberry-博客园. 如果你满足以下条件,我建议你阅读这篇教程: 你想知道如何在表面着色器中进行混色(blend colour) 你想实 ...
- 【完全开源】微信客户端.NET版
目录 说明 功能 原理步骤 一些参考 说明 前两天比较闲,研究了一下web版微信.因为之前看过一篇博客讲微信web协议的,后来尝试分析了一下,半途中发现其实没什么意义,但又不想半途而废,所以最后做出了 ...
- MVC5 网站开发之六 管理员 1、登录、验证和注销
上次业务逻辑和展示层的架构都写了,可以开始进行具体功能的实现,这次先实现管理员的登录.验证和注销功能. 目录 奔跑吧,代码小哥! MVC5网站开发之一 总体概述 MVC5 网站开发之二 创建项目 MV ...
- 谁是2016年的.NET开发者?
Nora Georgieva (http://www.telerik.com/blogs/infographic-the-dotnet-developer-of-2016) Whether you h ...
- Hawk 4. 数据清洗
数据清洗模块,包括几十个子模块, 这些子模块包含四类:生成, 转换, 过滤和执行. 数据清洗可以通过组合多个不同的子模块,生成多样的功能,通过拖拽构造出一个工作流,它能够产生一个有限或无限的文档序列. ...
- JS处理事件小技巧
今天,就分享一下我自己总结的一些JS的小技巧: ①防止鼠标选中事件 <div class="mask" onselectstart="return false&qu ...
- HTML5-video标签-实现点击预览图播放或暂停视频
HTML5-video标签-实现点击预览图播放或暂停视频 刚刚参加工作,开始更多的接触到一些新的知识,促使我开始了解html5和css3的新特性.这时我才真的发现到html5和css3的强大. 之前关 ...