spark中groupByKey与reducByKey
【译】避免使用GroupByKey
by:leotse
译文
让我们来看两个wordcount的例子,一个使用了reduceByKey,而另一个使用groupByKey:
1 |
val words = Array("one", "two", "two", "three", "three", "three")
|
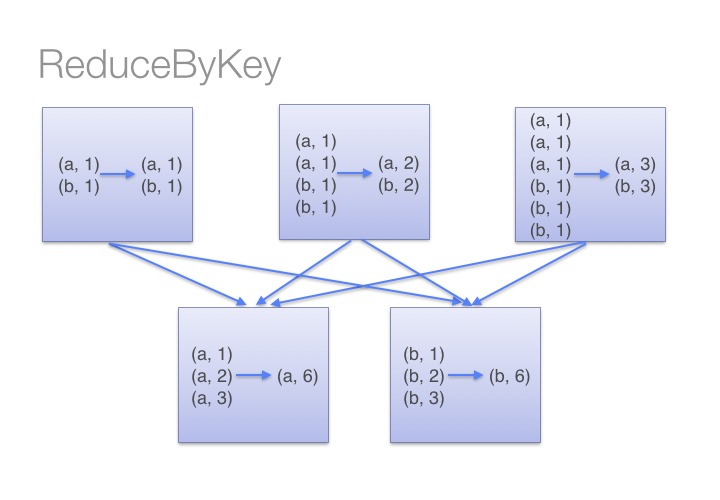
上面两个函数所得到的结果都是正确的,但是当数据集很大时,使用了reduceByKey的例子表现更佳。这是因为在shuffle输出的数据前,Spark会Combine每一个partition上具有相同key的输出结果。
看下图我们就能理解reduceByKey的工作流程。我们注意到同一台机器上数据shuffle之前,相同key的数据(通过调用传入reduceByKey的lambda函数)Combine在一起的,然后再一次调用这个lambda函数去reduce来自各个partition的全部值,从而得到最终的结果。
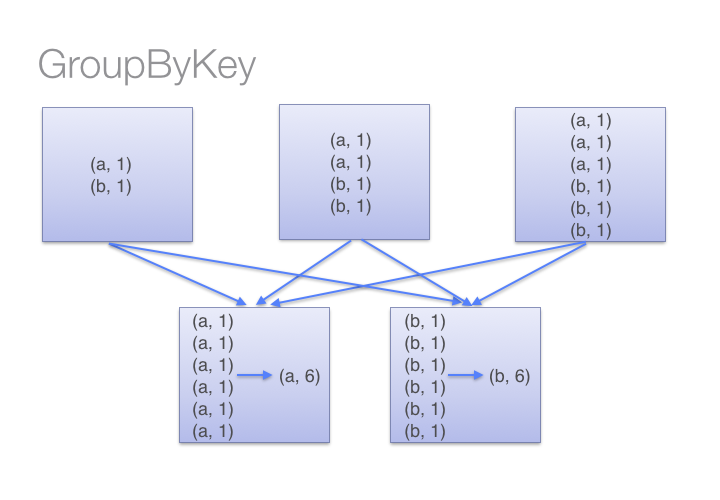
另一方面,当调用groupByKey的时候,所有的键值对都会进行shuffle,这将增加很多无谓的数据进行网络传输。
为了确定哪台机器将接受Shuffle后的键值对,Spark会针对该键值对数据的key调用一个分区函数。当某一台executor机器上的内存不足以保存过多的Shuffle后数据时,Spark就会溢写数据到磁盘上。然而,这种溢写磁盘会一次性将一个key的全部键值对数据写入磁盘,因此如果一个key拥有过多键值对数据——多到内存放不下时,将会抛出Out Of Memory异常。在之后发布的Spark中将会更加优雅地处理这种情况,使得这个job仍会继续运行,但是我们仍然需要避免(使用groupByKey)。当Spark需要溢写磁盘的时候,它的性能将受到严重影响。
如果你有一个非常大的数据集,那么reduceByKey和groupByKey进行shuffle的数据量之间的差异将会更加夸张。
下面是一些你可以用来替代groupByKey的函数:
1)当你在combine数据但是返回的数据类型因输入值的类型而异时,你可以使用combineByKey;
2)如果key使用到结合函数和“零值”,你可以用foldByKey函数合并value;
spark中groupByKey与reducByKey的更多相关文章
- Spark 中 GroupByKey 相对于 combineByKey, reduceByKey, foldByKey 的优缺点
避免使用GroupByKey 我们看一下两种计算word counts 的方法,一个使用reduceByKey,另一个使用 groupByKey: val words = Array("on ...
- Spark中groupByKey、reduceByKey与sortByKey
groupByKey把相同的key的数据分组到一个集合序列当中: [("hello",1), ("world",1), ("hello",1 ...
- 在Spark中尽量少使用GroupByKey函数(转)
原文链接:在Spark中尽量少使用GroupByKey函数 为什么建议尽量在Spark中少用GroupByKey,让我们看一下使用两种不同的方式去计算单词的个数,第一种方式使用reduceByKey ...
- Spark中的编程模型
1. Spark中的基本概念 Application:基于Spark的用户程序,包含了一个driver program和集群中多个executor. Driver Program:运行Applicat ...
- 关于Spark中RDD的设计的一些分析
RDD, Resilient Distributed Dataset,弹性分布式数据集, 是Spark的核心概念. 对于RDD的原理性的知识,可以参阅Resilient Distributed Dat ...
- Spark中的键值对操作-scala
1.PairRDD介绍 Spark为包含键值对类型的RDD提供了一些专有的操作.这些RDD被称为PairRDD.PairRDD提供了并行操作各个键或跨节点重新进行数据分组的操作接口.例如,Pa ...
- Spark中的键值对操作
1.PairRDD介绍 Spark为包含键值对类型的RDD提供了一些专有的操作.这些RDD被称为PairRDD.PairRDD提供了并行操作各个键或跨节点重新进行数据分组的操作接口.例如,Pa ...
- 【Spark篇】--Spark中的宽窄依赖和Stage的划分
一.前述 RDD之间有一系列的依赖关系,依赖关系又分为窄依赖和宽依赖. Spark中的Stage其实就是一组并行的任务,任务是一个个的task . 二.具体细节 窄依赖 父RDD和子RDD parti ...
- 020 Spark中分组后的TopN,以及Spark的优化(重点)
一:准备 1.源数据 2.上传数据 二:TopN程序编码 1.程序 package com.ibeifeng.bigdata.spark.core import java.util.concurren ...
随机推荐
- Python安装httplib2 0.9.2
1.首先下载httplib2 0.9.2,下载地址: https://pypi.python.org/pypi/httplib2/#downloads 2.然后解压到Python27的安装目录下,将下 ...
- 关于oracle数据库(4)数据类型
数据类型 字符数据类型char:固定长度字符串,最大可以存放2000字节 字符串varchar2:可变长度字符串,最大可以存放2GB数值类型数据 数字number:可以存放整数.浮点数.实数 numb ...
- jquery ui sortable 实现table,row的拖动。(Make Table Rows Sortable Using jQuery UI Sortable)
// Return a helper with preserved width of cells var fixHelper = function(e, ui) { //console.log(ui) ...
- 请教下关于CKEditor富文本编辑框设置字体颜色的问题
CKEDITOR.editorConfig = function( config ){ config.plugins = 'about,a11yhelp,basicstyles,bidi,blockq ...
- Jquery实现表格的分页
功能描述 该分页功能不是一次将所有记录都加载出来,然后在点击按钮翻页的时候,通过设置每一条记录的display属性展示或隐藏实现分页的效果.由于后台的获取数据的接口已实现分页的功能,所以在点击翻页按钮 ...
- postgresql删除属性
PostgreSQL update and delete property from JSONB column up vote 2 down vote favorite From this artic ...
- HDU 5777 domino
贪心一下.有k次机会,也就是那些数字中,最大的k-1可以不选择.答案为:sum{a[i]}-sum{最大的k-1个a[i]}+n.注意:k>=n的时候直接输出n. #pragma comment ...
- android抓日志
1. adb logcat -c 清楚以前的日志 adb logcat -s 过滤 adb logcat -s *:E adb logcat -v 指定输出的格式 adb logcat -v brie ...
- 给php代码添加规范的注释phpDocumentor
给php代码添加规范的注释更多参考 http://phpdoc.org/docs/latest/index.html在phpdocumentor中,注释分为文档性注释和非文档性注释.所谓文档性注释,是 ...
- table导出到excel的两种方法
1. 用table2excel 的js文件,这种方法没有IE兼容性 需要在文件中导入 <script type="text/javascript" src="< ...