Python数据分析--Pandas知识点(二)
本文主要是总结学习pandas过程中用到的函数和方法, 在此记录, 防止遗忘.
下面将是在知识点一的基础上继续总结.
13. 简单计算
新建一个数据表df
import pandas as pd
df = pd.DataFrame({"地区": ["A区","B区", "C区"],
"前半年销量": [3500, 4500,3800],
"后半年销量": [3000, 6000,5000],
"单价": [10, 18, 15]})
df

13.1 加法计算
有两种方式, 一种是利用add()函数: a.add(b) 表示a与b之和, 另一种是直接利用加法运算符号"+"
#第一种方式: 利用add()函数
# df["总销量"] = df["前半年销量"].add(df["后半年销量"])
#第二种方式: "+"
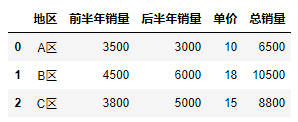
df["总销量"] = df["前半年销量"] + df["后半年销量"]
df
两者运算的结果都是相同的:
对于累加求和上述两种方法同样适用, 还有一种方式就是采用apply()函数, 参考文档: https://blog.csdn.net/luckarecs/article/details/72869051
这里介绍apply(func, axis = 0)函数的两个参数, apply()函数官方文档: http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.apply.html?highlight=apply#pandas.DataFrame.apply
第一个参数func就是指用于每行或者每列的函数, 这里将采用lambda函数: 接收任意多个参数并返回单个计算结果.
第二个参数axis=0则表示计算行与行的数据, axis=1则表示计算列与列的数据
#由于地区不能参与运算, 因此在df1数据表中删除地区
df1 = df.drop(["地区","单价"], axis = 1, inplace = False)
#对df1数据表进行累加运算, 随后添加到df表中.
df["总销量"] = df1.apply(lambda x: x.sum(), axis = 1)
df
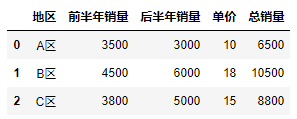
#删除地区和单价,分别计算前半年与后半年的三个地区总和.
df2 = df.drop(["地区","单价"], axis = 1, inplace = False)
#利用apply函数计算之后,添加至数据表中
df.loc["Sum"] = df2.apply(lambda x: x.sum(), axis = 0 )
df

13.2 减法运算
同样有两种方式: 一种是采用sub()函数, A.sub(B)表示A-B, 另一种是采用减法运算符 "-"
#函数法: 注意A.sub(B)表示A-B
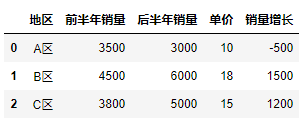
df["销量增长"] = df["后半年销量"].sub(df["前半年销量"])
#运算符: "-"
df["销量增长"] = df["后半年销量"] - df["前半年销量"]
df
两种方式, 同样的结果:
13.3 乘法运算
同样是两种方式: 一种是采用mul()函数: A.mul(B)表示: A与B之积, 另一种则是乘法运算符 "*"
#函数法: A.mul(B)
df["前半年销售额"] = df["前半年销量"].mul(df["单价"])
#运算符: "*"
df["后半年销售额"] = df["后半年销量"] * df["单价"]
df
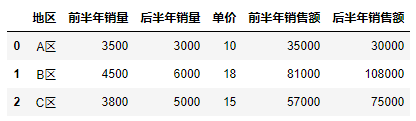
13.4 除法运算
同样是两种: 一种是采用div()函数: A.div(B)表示: A除以B, 第二种则是采用除法运算符"/"
#函数法
df["前半年销量1"] = df["前半年销量"].div(100)
#运算符法
df["前半年销量2"] = df["前半年销量"] / 1000
df
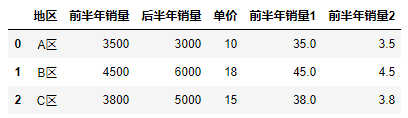
13.5 其他运算
13.5.1 取整和取余
#取整符号: "//"
df["后半年销量1"] = df["后半年销量"] // 1000
#取余符号: "%"
df["前半年销量1"] = df["前半年销量"] // 100 % 10
df
13.5.2 聚合运算
采用聚合函数对一组数据进行运算, 并返回单个值, 比如最大值max()函数, 最小值min()函数, 平均值mean()函数
#求前半年销量最大值
df1 = df["前半年销量"].max()
#求后半年销量最小值
df2 = df["后半年销量"].min()
#求单价的平均值
df3 = df["单价"].mean()
df1, df2 ,df3
(4500, 3000, 14.333333333333334)
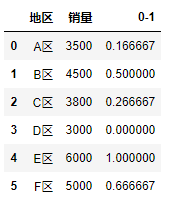
14. 0-1标准化
0-1标准化是对原始数据进行线性变换, 使其结果映射成[0,1]区间的值, 计算公式为: 新数据 = (原数据 - 最小值) / (最大值 - 最小值)
import pandas as pd
df = pd.DataFrame({"地区": ["A区","B区", "C区", "D区", "E区", "F区"],
"销量": [3500, 4500,3800,3000, 6000,5000]})
#利用公式对原始数据进行0-1标准化处理
df["0-1"] = (df["销量"] - df["销量"].min()) / (df["销量"].max() - df["销量"].min())
df
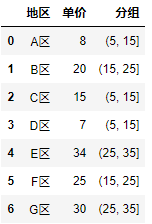
15. 数据分组
数据分组是根据统计研究的需求, 对原始数据按照某种标准划分为不同的组别. 主要目的是观察数据的分布特征. 在数据分组后再计算出各组中数据出现的的频数, 最终形成频数分布表.
pandas中数据分组采用的函数是cut(x, bins, right = True, labels = None)函数:
第一个参数x指的是要分组的数据
第二个参数bins指的是划分标准, 也就是定义组的上限与下限
第三个参数right = True表示右边闭合, 左边不闭合; 当right = False时表示右边不闭合, 左边闭合, 默认为True.
第四个参数则是自定义分组的内容
更多cut()函数相关参考官方文档: http://pandas.pydata.org/pandas-docs/stable/generated/pandas.cut.html?highlight=cut#pandas.cut
import pandas as pd
df = pd.DataFrame({"地区": ["A区","B区", "C区", "D区", "E区", "F区", "G区"],
"单价": [ 8 , 20, 15, 7, 34, 25, 30]})
#对单价进行编组: (5,15),(15,25),(25,35)
bins = [5, 15, 25, 35]
#利用cut()函数对单价进行分组, 并添加至原数据表中
df["分组"] = pd.cut(df.单价, bins)
df
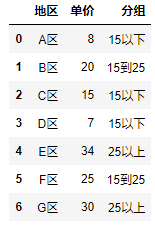
自定义labels:
import pandas as pd
df = pd.DataFrame({"地区": ["A区","B区", "C区", "D区", "E区", "F区", "G区"],
"单价": [ 8 , 20, 15, 7, 34, 25, 30]})
bins = [5, 15, 25, 35]
#自定义labels
labels = ["15以下", "15到25", "25以上"]
df["分组"] = pd.cut(df.单价, bins, labels = labels)
df
16. 日期转换
日期转换是指将字符类型转换成日期格式.
16.1 to_datetime方法
可使用to_datetime(arg, format = None)函数转换
第一个参数arg则是需要转化的字符串, 比如"2018/09/01"
第二个参数format则是原字符串中日期的格式, 比如"2018/09/01"的格式为 "%Y/%m/%d"
常用的格式有: %y表示两位数的年份, %Y表示四位数的年份, %m表示月份, %d表示月中的某一天, %H表示24小时制时数, %I表示12小时制时数, %M表示分钟, %S表示秒
to_datetime()函数官方文档: http://pandas.pydata.org/pandas-docs/stable/generated/pandas.to_datetime.html?highlight=to_datetime#pandas.to_datetime
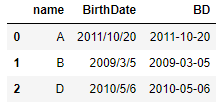
import pandas as pd
df = pd.DataFrame({"name":["A","B","D"],
"BirthDate": ["2011/10/20","2009/3/5","2010/5/6"]})
#转成日期格式
df["BD"] = pd.to_datetime(df.BirthDate,format = "%Y/%m/%d")
df
#查看数据类型
df.dtypes

16.2 datetime.strptime()方法
借助datetime模块中datetime类的strptime()方法, 将字符类型转化为日期格式.
strptime(date_string, format)方法中有两个参数, 第一个参数则是要转化的字符串, 第二个参数则为字符串中日期的格式
import pandas as pd
from datetime import datetime
df = pd.DataFrame({"name":["A","B","D"],
"BirthDate": ["2011/10/20","2009/3/5","2010/5/6"]})
#转化为日期格式
df["BD"] = df["BirthDate"].apply(lambda x: datetime.strptime(x, "%Y/%m/%d"))
df

17. 日期格式化
日期格式化就是将日期按照指定的格式输出成字符类型, 这里借助datetime模块中datetime类的strftime()方法实现:
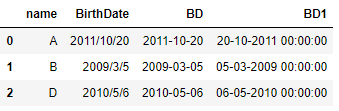
import pandas as pd
from datetime import datetime
df = pd.DataFrame({"name":["A","B","D"],
"BirthDate": ["2011/10/20","2009/3/5","2010/5/6"]})
#转化为日期格式
df["BD"] = df["BirthDate"].apply(lambda x: datetime.strptime(x, "%Y/%m/%d"))
#日期格式化
df["BD1"] = df["BD"].apply(lambda x: datetime.strftime(x, "%d-%m-%Y %H:%M:%S"))
df
18.日期抽取
从日期格式中抽取日期的部分内容, 比如抽取年份, 月份等. 语法: 转换为日期格式的列.dt.要抽取的属性.
import pandas as pd
from datetime import datetime
df = pd.DataFrame({"name":["A","B","D"],
"BirthDate": ["2011/10/20","2009/3/5","2010/5/6"]})
df["BD"] = df["BirthDate"].apply(lambda x: datetime.strptime(x, "%Y/%m/%d"))
df["year"] = df["BD"].dt.year
df["month"] = df["BD"].dt.month
df["day"] = df["BD"].dt.day
df["hour"] = df["BD"].dt.hour
df["minute"] = df["BD"].dt.minute
df["second"] = df["BD"].dt.second
df["weekday"] = df["BD"].dt.weekday
df
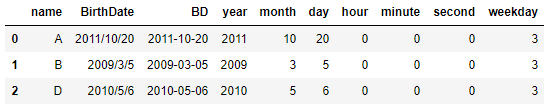
以上是本次的学习总结, 后续会持续更新...
Python数据分析--Pandas知识点(二)的更多相关文章
- Python数据分析--Pandas知识点(三)
本文主要是总结学习pandas过程中用到的函数和方法, 在此记录, 防止遗忘. Python数据分析--Pandas知识点(一) Python数据分析--Pandas知识点(二) 下面将是在知识点一, ...
- Python数据分析--Pandas知识点(一)
本文主要是总结学习pandas过程中用到的函数和方法, 在此记录, 防止遗忘 1. 重复值的处理 利用drop_duplicates()函数删除数据表中重复多余的记录, 比如删除重复多余的ID. im ...
- Python数据分析教程(二):Pandas
Pandas导入 Pandas是Python第三方库,提供高性能易用数据类型和分析工具 Pandas基于NumPy实现,常与NumPy和Matplotlib一同使用 两个数据类型:Series, Da ...
- Python数据分析-Pandas(Series与DataFrame)
Pandas介绍: pandas是一个强大的Python数据分析的工具包,是基于NumPy构建的. Pandas的主要功能: 1)具备对其功能的数据结构DataFrame.Series 2)集成时间序 ...
- Python:pandas(二)——pandas函数
Python:pandas(一) 这一章翻译总结自:pandas官方文档--General functions 空值:pd.NaT.np.nan //判断是否为空 if a is np.nan: .. ...
- python数据分析Numpy(二)
Numpy (Numerical Python) 高性能科学计算和数据分析的基础包: ndarray,多维数组(矩阵),具有矢量运算能力,快速.节省空间: 矩阵运算,无需循环,可以完成类似Matlab ...
- Python数据分析Pandas库之熊猫(10分钟二)
pandas 10分钟教程(二) 重点发法 分组 groupby('列名') groupby(['列名1','列名2',.........]) 分组的步骤 (Splitting) 按照一些规则将数据分 ...
- Python数据分析 Pandas模块 基础数据结构与简介(二)
重点方法 分组:groupby('列名') groupby(['列1'],['列2'........]) 分组步骤: (spiltting)拆分 按照一些规则将数据分为不同的组 (Applying)申 ...
- python 数据分析--pandas
接下来pandas介绍中将学习到如下8块内容:1.数据结构简介:DataFrame和Series2.数据索引index3.利用pandas查询数据4.利用pandas的DataFrames进行统计分析 ...
随机推荐
- Dev的TextEdit控件IP地址的Mask设置
1. 添加TextEdit控件. 2. 选中TextEdit控件,查看控件属性. 3. 展开Properties属性项,找到Mask属性项. 4. 设置Mask属性项的EditMask属性值为:(25 ...
- getVisibleSize,getWinSize,getFrameSize,getViewPortRect
cc.director.getVisibleSize();//获取运行场景的可见大小 cc.director.getWinSize();//获取视图的大小,以点为单位 cc.director.getW ...
- Haskell语言开发工具
Stack How to Script with Stack Originate Guides - Haskell Tool Stack 配置 Intellij Idea IntelliJ plugi ...
- 【365】拉格朗日乘子法与KKT条件说明
参考:知乎回答 - 通过山头形象描述 参考:马同学 - 如何理解拉格朗日乘子法? 参考: 马同学 - 如何理解拉格朗日乘子法和KKT条件? 参考:拉格朗日乘数 - Wikipedia 自己总结的规律 ...
- 如何设置java环境变量
以安装目录是E:\Program Files\Java\jDK1.7.0为例:
- datagridview表头全选
参与程序http://www.codeproject.com/KB/grid/CheckBoxHeaderCell.aspx 这里老外写的一个控件,他少了委托重载的一个方法.先写一个控件 public ...
- iphone上实现H264 硬编码
供ios下h264硬编码sdk,可以生成h264流. 我们的H264 SDK提供了一个理想的软件开发工具包,使您的app可以在iPhone或iPod上实时的访问H264帧数据.SDK提供了一套API功 ...
- hbase高可用集群部署(cdh)
一.概要 本文记录hbase高可用集群部署过程,在部署hbase之前需要事先部署好hadoop集群,因为hbase的数据需要存放在hdfs上,hadoop集群的部署后续会有一篇文章记录,本文假设had ...
- Mac中使用pycharm引包matplotlib失败
最开始是使用matplotlib这个包,然后在pycharm中失败,然后在终端中pip install matplotlib,发现,安装了以后,pycharm依然找不到包. 代码如下: import ...
- linux的一些目录结构
home:家.用户的家. 普通用户的家目录文件在home下 例如:一个用户名为tom的用户,在home下就会存在tom的目录. root:超级管理员root的家 etc:存放配置文件 usr:存放共享 ...