HotSpot Generations
本文主要介绍HotSpot JVM的 Generations 机制,
原文来自 Oracle 文档 Java SE 6 HotSpot[tm] Virtual Machine Garbage Collection Tuning 第三,四章 -- Generations & Performance Considerations
Link: http://www.oracle.com/technetwork/java/javase/gc-tuning-6-140523.html#generations
---------------------------------------------------------------------------------------------------------------------
3. Generations
One strength of the J2SE platform is that it shields the developer from the complexity of memory allocation and garbage collection. However, once garbage collection is the principal bottleneck, it is worth understanding some aspects of this hidden implementation. Garbage collectors make assumptions about the way applications use objects, and these are reflected in tunable parameters that can be adjusted for improved performance without sacrificing the power of the abstraction.
J2SE平台的一个优势是将开发者从复杂的内存分配和垃圾回收中拯救出来.然而,一旦垃圾回收变成了主要的性能瓶颈, 了解一些潜在的实现就变得很有必要了. 垃圾回收器假定程序使用objects, 并且这些都可以反映在可调节参数的调整来提升性能, 并且不需要牺牲抽象的力量.
An object is considered garbage when it can no longer be reached from any pointer in the running program. The most straightforward garbage collection algorithms simply iterate over every reachable object. Any objects left over are then considered garbage. The time this approach takes is proportional to the number of live objects, which is prohibitive for large applications maintaining lots of live data.
一个object当它不在被其他运行程序可及的时候会被认为是垃圾. 最直接的垃圾回收算法简单地遍历每个可及的object. 任何没有被遍历到的object都会被认为是垃圾.这种方法的回收执行的时间和存活的object数量是成比例的, 对于有很多存活对象的大型应用这种方法是被禁止使用的.
Beginning with the J2SE 1.2, the virtual machine incorporated a number of different garbage collection algorithms that are combined using generational collection. While naive garbage collection examines every live object in the heap, generational collection exploits several empirically observed properties of most applications to minimize the work required to reclaim unused ("garbage") objects. The most important of these observed properties is the weak generational hypothesis, which states that most objects survive for only a short period of time.
J2SE 1.2开始, JVM使用分代集合(generational collection)合并了一些列的垃圾回收算法.傻逼的垃圾回收算法会检查每一个heap中存活的object, 分代垃圾回收利用大多数程序的经验型观察属性来最小化回收垃圾object的工作量.这些参数中最重要的是弱代假设(weak generational hypothesis),他声明了大多数object只存活一小会.
The blue area in the diagram below is a typical distribution for the lifetimes of objects. The X axis is object lifetimes measured in bytes allocated. The byte count on the Y axis is the total bytes in objects with the corresponding lifetime. The sharp peak at the left represents objects that can be reclaimed (i.e., have "died") shortly after being allocated. Iterator objects, for example, are often alive for the duration of a single loop.
蓝色区域是一个典型的objects(多个对象)的生命周期分布图表.X轴表示的是对象内存分配和生命周期的关系(按照我的理解应该是横轴的对象生命周期和纵轴的所有对象占用内存的关系,意思是生命周期短的对象很多).Y轴的字节计数是所有对应的生命周期的对象占用的总内存. 最左边的尖端代表刚被分配完就可以被回收(死了)的对象.遍历器对象, 例如, 通常就是在单次循环中存在的对象
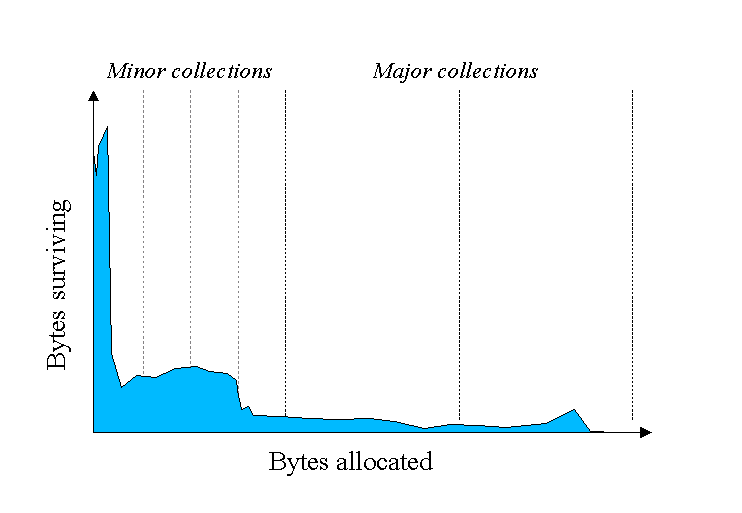
Some objects do live longer, and so the distribution stretches out to the the right. For instance, there are typically some objects allocated at initialization that live until the process exits. Between these two extremes are objects that live for the duration of some intermediate computation, seen here as the lump to the right of the initial peak. Some applications have very different looking distributions, but a surprisingly large number possess this general shape. Efficient collection is made possible by focusing on the fact that a majority of objects "die young."
有一些对象存活的时间很长,所以这个分布被拉伸到了右边.例如,那些在初始化时就被分配内存但是一直存活到进程结束的对象.在两个(左右)极端之间是那些中间操作里存在的对象,在这里就是在初始峰值右边的那块.有些程序会有不一样的分布, 但是绝大多数具有这个形状. 有效的回收机制会将关注放在多数死得早的object上.
To optimize for this scenario, memory is managed in generations, or memory pools holding objects of different ages. Garbage collection occurs in each generation when the generation fills up. The vast majority of objects are allocated in a pool dedicated to young objects (the young generation), and most objects die there. When the young generation fills up it causes a minor collection in which only the young generation is collected; garbage in other generations is not reclaimed. Minor collections can be optimized assuming the weak generational hypothesis holds and most objects in the young generation are garbage and can be reclaimed. The costs of such collections are, to the first order, proportional to the number of live objects being collected; a young generation full of dead objects is collected very quickly. Typically some fraction of the surviving objects from the young generation are moved to the tenured generation during each minor collection. Eventually, the tenured generation will fill up and must be collected, resulting in a major collection, in which the entire heap is collected. Major collections usually last much longer than minor collections because a significantly larger number of objects are involved.
为了优化这个方案, 没存被分代进行管理, 或者说内存池把objects按不同年龄进行存储.垃圾回收机制会在每一代的内存区填满的时候发生.绝大多数的object都是在年轻代分配的, 他们大多数也是在那里死亡. 当年轻代被填满就会触发一次小回收, 小回收只会收集年轻代的垃圾; 其他代的垃圾是不会被回收的. 这种回收的代价和正在收集的对象的存活数目是成比例的;一个充满了死亡对象的年轻代的收集速度是非常快的(因为不需要去分析这些死亡对象的引用关系).一些年轻代里survival区的对象在每次小回收后会被移动到年老代.最后, 年老代会被充满, 并触发一次大收集,大收集会对整个heap进行一次收集.大收集通常会花费比小收集长得多的时间,因为大收集需要收集的对象数目比小收集要多得多.
As noted above, ergonomics selects the garbage collector dynamically in order to provide good performance on a variety of applications. The serial garbage collector is designed for applications with small data sets and its default parameters were chosen to be effective for most small applications. The throughput garbage collector is meant to be used with applications that have medium to large data sets. The heap size parameters selected by ergonomics plus the features of the adaptive size policy are meant to provide good performance for server applications. These choices work well in most, but not all, cases. Which leads to the central tenet of this document:
正如上面提到的, ergonomics会根据不同的程序动态选择垃圾回收器来提供最好的性能.串行垃圾回收器(serial garbage collector)设计用来给大多数只有小数据集的小程序使用. 吞吐率垃圾回收器(throughput garbage collector)用来给中型数据集的程序使用. ergonomics会给服务端程序选择最合适的heap size策略.这些选择大多数情况下都工作的很好, 但是有些情况下不行.这就引出了这篇文档的中心思想
|
If garbage collection becomes a bottleneck, you will most likely have to customize the total heap size as well as the sizes of the individual generations. Check the verbose garbage collector output and then explore the sensitivity of your individual performance metric to the garbage collector parameters. 如果垃圾收集成为了性能瓶颈, 你需要手动去设置heap size和各个分代的size. 检查垃圾回收日志并探索这些垃圾回收器参数对你的程序性能造成的敏感性. |
The default arrangement of generations (for all collectors with the exception of the parallel collector) looks something like this.
默认的分代布局(除了并行回收期(parallel collector))都是像下面这样的

At initialization, a maximum address space is virtually reserved but not allocated to physical memory unless it is needed. The complete address space reserved for object memory can be divided into the young and tenured generations.
初始化时, 最大值的地址空间会被保留但是不会真正的分配到物理空间知道它确实需要被分配.全部地址空间会被分为年轻代和年老代
The young generation consists of eden and two survivor spaces. Most objects are initially allocated in eden. One survivor space is empty at any time, and serves as the destination of any live objects in eden and the other survivor space during the next copying collection. Objects are copied between survivor spaces in this way until they are old enough to be tenured (copied to the tenured generation).
年轻代包括eden和两个survivor spaces. 大多数对象都在eden被初始化. 一个幸存者空间在任意时候都是空的, 他会作为在下一次拷贝手机的时候,任何存活在eden和另一个survivor space的对象目的地. 当对象够老时会从survivor space拷贝到年老代.
A third generation closely related to the tenured generation is the permanent generation which holds data needed by the virtual machine to describe objects that do not have an equivalence at the Java language level. For example objects describing classes and methods are stored in the permanent generation.
第三个和年老代密切相关的是持久代(permanent generation), 他保存了那些不在java语言层面但是JVM用来描述object的数据(class信息?).例如描述class和方法的数据就是存在持久代
Performance Considerations
性能注意事项
There are two primary measures of garbage collection performance:
考量垃圾回收性能最重要的两个方面是:
- Throughput is the percentage of total time not spent in garbage collection, considered over long periods of time. Throughput includes time spent in allocation (but tuning for speed of allocation is generally not needed).
- Pauses are the times when an application appears unresponsive because garbage collection is occurring.
- 吞吐量(Throughput)是非垃圾回收占总时间的百分比, 这是很长的一段时间. 吞吐量包括申请内存的时间(但是调整申请内存的速度通常都是不需要的).
- 暂停(Pauses)是当垃圾回收发生时程序未响应的时间
Users have different requirements of garbage collection. For example, some consider the right metric for a web server to be throughput, since pauses during garbage collection may be tolerable, or simply obscured by network latencies. However, in an interactive graphics program even short pauses may negatively affect the user experience.
不同的用户对垃圾回收有不一样的需求.例如,有些人会考虑web server的throughput的量, 因为pauses在垃圾回收的时候可能是可以忍受的,或者说pauses的影响被网络传输时间给掩盖了.然而,在一个交互式图形程序中, 即使很短的pauses也会对用户体验造成很坏的影响.
Some users are sensitive to other considerations. Footprint is the working set of a process, measured in pages and cache lines. On systems with limited physical memory or many processes, footprint may dictate scalability. Promptness is the time between when an object becomes dead and when the memory becomes available, an important consideration for distributed systems, including remote method invocation (RMI).
有些用户对其他注意事项很敏感. Footprint是一个进程工作计划,在内存页和高速缓存线中被测量. 一个只有优先的物理内存或者很多继承的系统, footprint可能命令得很有扩展性. Promptness 是当一个对象死亡到这块内存可以被使用的时间差, 对于分布式系统来说, 这是一个很重要的注意事项, 包括远程方法调用(RMI)
In general, a particular generation sizing chooses a trade-off between these considerations. For example, a very large young generation may maximize throughput, but does so at the expense of footprint, promptness and pause times. young generation pauses can be minimized by using a small young generation at the expense of throughput. To a first approximation, the sizing of one generation does not affect the collection frequency and pause times for another generation.
一般来说, 分代大小的设置会根据这些注意实现中间做出选择.例如, 一个很大的年轻代可能会最大化throughput(提升throughput效率?因为不需要频繁申请内存), 但是这对fottprint, promptness和pause时间会有损失.使用小的年轻代会最小化pauses时间但是却会对throughput造成损失.直观的估计, 一个分代的大小分配不会影响其他分代的垃圾回收的频繁度和暂停次数.
There is no one right way to size generations. The best choice is determined by the way the application uses memory as well as user requirements. Thus the virtual machine's choice of a garbage collectior is not always optimal and may be overridden with command line options described below.
并没有一个绝对正确的分配分代大小的方法. 最好的选择是通过用户需求和程序需要的内存来决定.因此JVM对垃圾回收器的选择不总是最佳的, 而且可能被下面的命令行选项覆盖
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
总结
heap与generation
Heap被分为young generation, tenured generation和 permanent generation
young generation: 绝大多数对象创建和死亡的地方, 内部又被分为 Eden和两个Survivor, 每次young被填满后,会触发一次小回收, 小回收只会对young的对象进行回收, 小回收效率较高. 每次小回收(minor collection)后存活的的对象就会被被后移(Eden->Survivor, Survivor -> Tenured)
tenured generation: 当GC认为对象足够老的时候, 对象会从young移动到tenured, 当tenured满了的时候,会触发大回收(major collection), 大回收会对整个heap进行扫描, 他相对而言会更消耗效率
permanent generation: 存储类信息和字符串常量的地方(方法区和运行时常量池)
垃圾回收的性能
垃圾回收包括内存分配阶段,垃圾清理阶段等,内存分配阶段花费的时间叫做吞吐量(?Throughput), 垃圾清理阶段可能会导致程序进入暂停(Pause), 我们需要根据需要来考虑分配年轻代的大小. 大的年轻代会提升throughput的性能, 但是会降低pause的性能(延长pause时间), 小的年轻代则相反.
有些程序可能会考虑使用小的年轻代来减少pause时间,例如拥有交互式UI的程序,是无法忍受长时间的pause的.
HotSpot Generations的更多相关文章
- Hotspot优化指南(上)
一次偶然,博主在浏览docs.oracle.com/javase的时候发现了<Hotspot虚拟机垃圾收集调优指南>这篇文档.内心百感交集,之前在看完了周志明的<深入理解Java虚拟 ...
- 【译】Java SE 14 Hotspot 虚拟机垃圾回收调优指南
原文链接:HotSpot Virtual Machine Garbage Collection Tuning Guide,基于Java SE 14. 本文主要包括以下内容: 优化目标与策略(Ergon ...
- HotSpot JVM常用参数设置
转自:https://www.zybuluo.com/jewes/note/57352 选项的分类 Hotspot JVM提供以下三大类选项: 1. 标准选项:这类选项的功能是很稳定的,在后续版本中也 ...
- 转:什么是即时编译(JIT)!?OpenJDK HotSpot VM剖析
重点 应用程序可以选择一个适当的即时编译器来进行接近机器级的性能优化. 分层编译由五层编译构成. 分层编译提供了极好的启动性能,并指导编译的下一层编译器提供高性能优化. 提供即时编译相关诊断信息的JV ...
- HSDB - HotSpot debugger
HSDB 是专门用于调试 HotSpot VM 的调试器,它是一个图形化界面.与之对应的还有个 CLHSDB-Command Line HotSpot Debugger,命令行调试界面.下面是启动命令 ...
- 关于Linux x64 Oracle JDK7u60 64-bit HotSpot VM 线程栈默认大小问题的整理
JVM线程的栈默认大小,oracle官网有简单描述: In Java SE 6, the default on Sparc is 512k in the 32-bit VM, and 1024k in ...
- HotSpot虚拟机对象介绍
1.对象的创建 Java是一门面向对象语言,在运行过程中无时不刻不在创建对象.从语言层面,创建对象仅仅是一个new关键字而已,而在虚拟机中,对象(文中讨论的对象仅限于普通java对象,不包含数组和Cl ...
- Hotspot内存溢出测试
一.堆溢出 在执行代码时通过设置堆的最小值-Mms以及堆的最大值-Mmx来控制堆的大小,-XX参数dump出堆内存快照以便对内存溢出进行分析.通过创建大量对象来使堆溢出,当堆内存溢出时会提示OutOf ...
- ROS Hotspot服务器的搭建与设定!(上网认证)
注:本文由Colin撰写,版权所有!转载请注明原文地址,谢谢合作! 说明:由于Hotspot设定的步骤比较多,此文档只讲解如何设定Hotspot的方法,关于ROS的安装与路由上网的配置请自行百度查阅. ...
随机推荐
- Qt编译好的oracle驱动下载
在上文,我累赘了一大堆,给大家写了一篇Qt如何编译OCI驱动,在这里自然就不再累赘了,直接附上编译好的文件供大家下载: <Qt5.3.1+OCI驱动下载地址> 有经济来源的请传送:http ...
- mini-css-extract-plugin简介
将css单独打包成一个文件的插件,它为每个包含css的js文件都创建一个css文件.它支持css和sourceMaps的按需加载. 目前只有在webpack V4版本才支持使用该插件 和extract ...
- Mac idea 快捷键
Mac键盘符号和修饰键说明 ⌘ Command⇧ Shift⌥ Option⌃ Control↩︎ Return/Enter⌫ Delete⌦ 向前删除键(Fn+Delete)↑ 上箭头↓ 下箭头← ...
- 使用ApiPost模拟发送get、post、delete、put等http请求
现在的模拟发送请求插件很多比如老外的postman等,但亲测咱们国内的 ApiPost 更好用一些,因为它不仅可以模拟发送get.post.delete.put请求,还可以导出文档,支持团队协作也是它 ...
- JDBC之 自增长与事务
JDBC之 自增长与事务 1.自增长 有这样一个现象:数据库中有两个表格 学生表(学生姓名,所在班级),班级表(班级号(自增长的主键),班级人数). 现在我往班级表插入一条信息, 只提供班级人数,班级 ...
- [ 转载 ] Tcp三次握手和四次挥手详解
#TCP的报头: 源端口号:表示发送端端口号,字段长为16位.目标端口号:表示接收端口号,字段长为16位.序列号:表示发送数据的位置,字段长为32位.每发送一次数据,就累加一次该数据字节数的大小.注意 ...
- [CC-XXOR]Chef and Easy Problem
[CC-XXOR]Chef and Easy Problem 题目大意: 给你一个长度为\(n(n\le10^5)\)的序列\(A(A_i<2^{31})\).\(m(m\le10^5)\)次询 ...
- [JSOI2015]最小表示
题目大意:尽可能多地去掉一个有向无环图上的边,使得图的连通性不变. 思路:拓扑排序,然后倒序求出每个结点到出度为$0$的点的距离$d$,再倒序遍历每一个点$x$,以$d$为关键字对其出边降序排序,尝试 ...
- BZOJ2915 : [Poi1997] gen
设f[i][j]表示串ij可以由哪些字母成长过来,用二进制压位表示. 设g[i][j]表示给定串中[i,j]这个区间一开始可以由哪些字母成长多来,用二进制压位表示. 设h[i]表示给定串前i位最少需要 ...
- ConcurrentHashMap内存溢出问题
写在前面 上周,同事写了一段ConcurrentHashMap的测试代码,说往map里放了32个元素就内存溢出了,我大致看了一下他的代码及运行的jvm参数,觉得很奇怪,于是就自己捣鼓了一下.首先上一段 ...