Spark笔记之数据本地性(data locality)
一、什么是数据本地性(data locality)
大数据中有一个很有名的概念就是“移动数据不如移动计算”,之所以有数据本地性就是因为数据在网络中传输会有不小的I/O消耗,如果能够想办法尽量减少这个I/O消耗就能够提升效率。那么如何减少I/O消耗呢,当然是尽量不让数据在网络上传输,即使无法避免数据在网络上传输,也要尽量缩短传输距离,这个数据需要传输多远的距离(实际意味着数据传输的代价)就是数据本地性,数据本地性根据传输距离分为几个级别,不在网络上传输肯定是最好的级别,其它级别划分依据传输距离越远级别越低,Spark在分配任务的时候会考虑到数据本地性,优先将任务分配给数据本地性最好的Executor执行。
在执行任务时查看Task的执行情况,经常能够看到Task的状态中有这么一列: 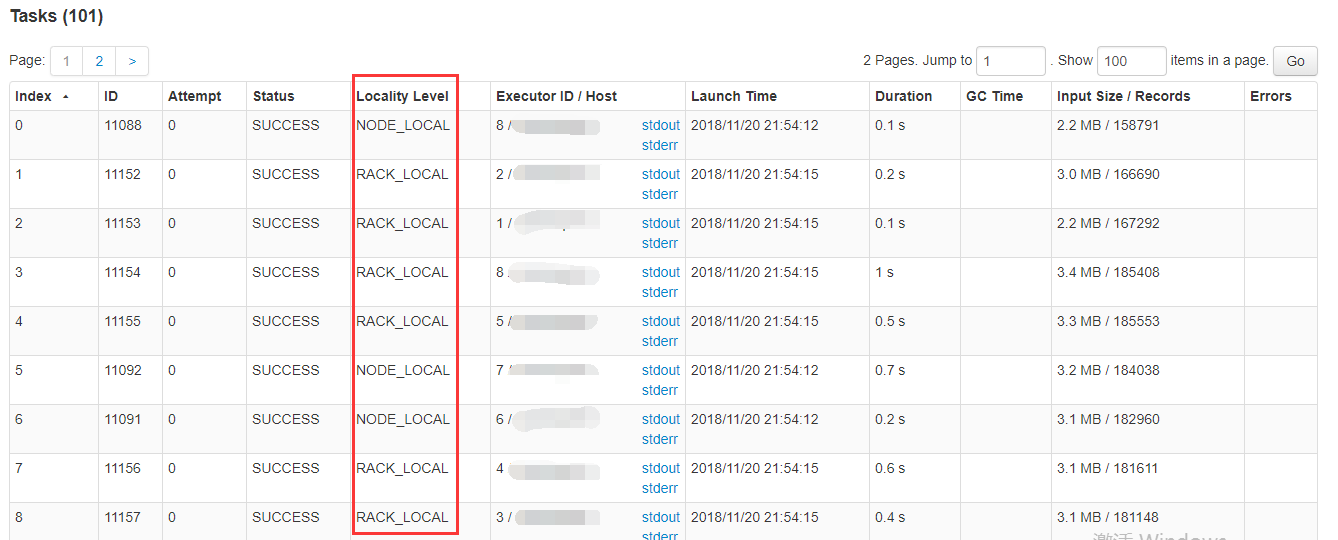
这一列就是在说这个Task任务读取数据的本地性是哪个级别,数据本地性共分为五个级别:
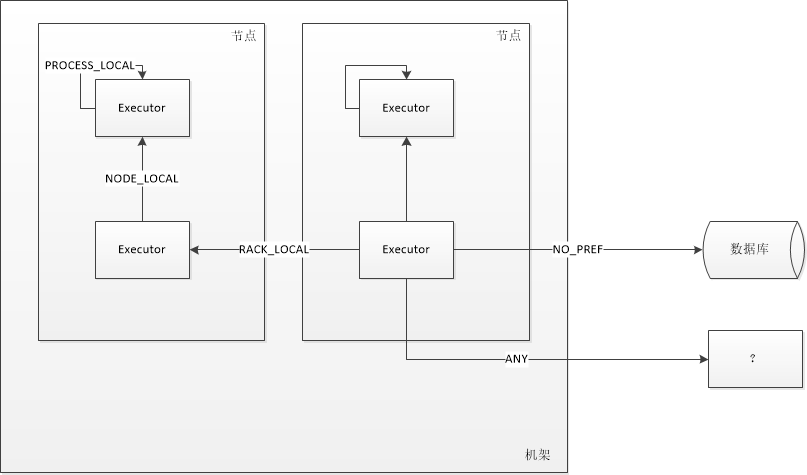
PROCESS_LOCAL:顾名思义,要处理的数据就在同一个本地进程中,即数据和Task在同一个Executor JVM中,这种情况就是RDD的数据在之前就已经被缓存过了,因为BlockManager是以Executor为单位的,所以只要Task所需要的Block在所属的Executor的BlockManager上已经被缓存,这个数据本地性就是PROCESS_LOCAL,这种是最好的locality,这种情况下数据不需要在网络中传输。
NODE_LOCAL:数据在同一台节点上,但是并不不在同一个jvm中,比如数据在同一台节点上的另外一个Executor上,速度要比PROCESS_LOCAL略慢。还有一种情况是读取HDFS的块就在当前节点上,数据本地性也是NODE_LOCAL。
NO_PREF:数据从哪里访问都一样,表示数据本地性无意义,看起来很奇怪,其实指的是从MySQL、MongoDB之类的数据源读取数据。
RACK_LOCAL:数据在同一机架上的其它节点,需要经过网络传输,速度要比NODE_LOCAL慢。
ANY:数据在其它更远的网络上,甚至都不在同一个机架上,比RACK_LOCAL更慢,一般情况下不会出现这种级别,万一出现了可能是有什么异常需要排查下原因。
使用一张图来表示五个传输级别:
二、延迟调度策略(Delay Scheduler)
Spark在调度程序的时候并不一定总是能按照计算出的数据本地性执行,因为即使计算出在某个Executor上执行时数据本地性最好,但是Executor的core也是有限的,有可能计算出TaskFoo在ExecutorBar上执行数据本地性最好,但是发现ExecutorBar的所有core都一直被用着腾不出资源来执行新来的TaskFoo,所以当TaskFoo等待一段时间之后发现仍然等不到资源的话就尝试降低数据本地性级别让其它的Executor去执行。
比如当前有一个RDD,有四个分区,称为A、B、C、D,当前Stage中这个RDD的每个分区对应的Task分别称为TaskA、TaskB、TaskC、TaskD,在之前的Stage中将这个RDD cache在了一台机器上的两个Executor上,称为ExecutorA、ExecutorB,每个Executor的core是2,ExecutorA上缓存了RDD的A、B、C分区,ExecutorB上缓存了RDD的D分区,然后分配Task的时候会把TaskA、TaskB、TaskC分配给ExecutorA,TaskD分配给ExecutorB,但是因为每个Executor只有两个core,只能同时执行两个Task,所以ExecutorA能够执行TaskA和TaskB,但是TaskC就只能等着,尽管它在ExecutorA上执行的数据本地性是PROCESS_LOCAL,但是人家没有资源啊,于是TaskC就等啊等,但是等了一会儿它发现不太对劲,搞这个数据本地性不就是为了加快Task的执行速度以提高Stage的整体执行速度吗,我搁这里干等着可不能加快Stage的整体速度,我要看下边上有没有其它的Executor是闲着的,假设我在ExecutorA需要再排队10秒才能拿到core资源执行,拿到资源之后我需要执行30秒,那么我只需要找到一个其它的Executor,即使因为数据本地性不好但是如果我能够在40秒内执行完的话还是要比在这边继续傻等要快的,所以TaskC就给自己设定了一个时间,当超过n毫秒之后还等不到就放弃PROCESS_LOCAL级别,转而尝试NODE_LOCAL级别的Executor,然后它看到了ExecutorB,ExecutorB和ExecutorA在同一台机器上,只是两个不同的jvm,所以在ExecutorB上执行需要从ExecutorA上拉取数据,通过BlockManager的getRemote,底层通过BlockTransferService去把数据拉取过来,因为是在同一台机器上的两个进程之间使用socket数据传输,走的应该是回环地址,速度会非常快,所以对于这种数据存储在同一台机器上的不同Executor上因为降级导致的NODE_LOCAL的情况,理论上并不会比PROCESS_LOCAL慢多少,TaskC在ExecutorB上执行并不会比ExecutorA上执行慢多少。但是对于比如HDFS块存储在此节点所以将Task分配到此节点的情况导致的NODE_LOCAL,因为要跟HDFS交互,还要读取磁盘文件,涉及到了一些I/O操作,这种情况就会耗费较长时间,相比较于PROCESS_LOCAL级别就慢上不少了。
上面举的例子中提到了TaskC会等待一段时间,根据数据本地性不同,等待的时间间隔也不一致,不同数据本地性的等待时间设置参数:
spark.locality.wait:设置所有级别的数据本地性,默认是3000毫秒
spark.locality.wait.process:多长时间等不到PROCESS_LOCAL就降级,默认为${spark.locality.wait}
spark.locality.wait.node:多长时间等不到NODE_LOCAL就降级,默认为${spark.locality.wait}
spark.locality.wait.rack:多长时间等不到RACK_LOCAL就降级,默认为${spark.locality.wait}
总结一下数据延迟调度策略:当使用当前的数据本地性级别等待一段时间之后仍然没有资源执行时,尝试降低数据本地性级别使用更低的数据本地性对应的Executor执行,这个就是Task的延迟调度策略。
最后探讨一下什么样的Task可以针对数据本地性延迟调度的等待时间做优化?
如果Task的输入数据比较大,那么耗费在数据读取上的时间会比较长,一个好的数据本地性能够节省很长时间,所以这种情况下最好还是将延迟调度的降级等待时间调长一些。而对于输入数据比较小的,即使数据本地性不好也只是多花一点点时间,那么便不必在延迟调度上耗费太长时间。总结一下就是如果数据本地性对任务的执行时间影响较大的话就稍稍调高延迟调度的降级等待时间。
相关资料:
1. spark on yarn 中的延迟调度(delay scheduler)
.
Spark笔记之数据本地性(data locality)的更多相关文章
- spark读取hdfs数据本地性异常
在分布式计算中,为了提高计算速度,数据本地性是其中重要的一环. 不过有时候它同样也会带来一些问题. 一.问题描述 在分布式计算中,大多数情况下要做到移动计算而非移动数据,所以数据本地性尤其重要,因此我 ...
- spark读取hdfs数据本地性异常【转】
在分布式计算中,为了提高计算速度,数据本地性是其中重要的一环. 不过有时候它同样也会带来一些问题. 一.问题描述 在分布式计算中,大多数情况下要做到移动计算而非移动数据,所以数据本地性尤其重要,因此我 ...
- 【原】Spark数据本地性
Spark数据本地性 分布式计算系统的精粹在于移动计算而非移动数据,但是在实际的计算过程中,总存在着移动数据的情况,除非是在集群的所有节点上都保存数据的副本.移动数据,将数据从一个节点移动到另一个节点 ...
- Spark数据本地性
1.文件系统本地性 第一次运行时数据不在内存中,需要从HDFS上取,任务最好运行在数据所在的节点上: 2.内存本地性 第二次运行,数据已经在内存中,所有任务最好运行在该数据所在内存的节点上: 3.LR ...
- 【Spark笔记】Windows10 本地搭建单机版Spark开发环境
0x00 环境及软件 1.系统环境 OS:Windows10_x64 专业版 2.所需软件或工具 JDK1.8.0_131 spark-2.3.0-bin-hadoop2.7.tgz hadoop-2 ...
- [转载] Spark:大数据的“电光石火”
转载自http://www.csdn.net/article/2013-07-08/2816149 Spark已正式申请加入Apache孵化器,从灵机一闪的实验室“电火花”成长为大数据技术平台中异军突 ...
- [Spark内核] 第36课:TaskScheduler内幕天机解密:Spark shell案例运行日志详解、TaskScheduler和SchedulerBackend、FIFO与FAIR、Task运行时本地性算法详解等
本課主題 通过 Spark-shell 窥探程序运行时的状况 TaskScheduler 与 SchedulerBackend 之间的关系 FIFO 与 FAIR 两种调度模式彻底解密 Task 数据 ...
- TaskScheduler内幕天机解密:Spark shell案例运行日志详解、TaskScheduler和SchedulerBackend、FIFO与FAIR、Task运行时本地性算法详解等
本课主题 通过 Spark-shell 窥探程序运行时的状况 TaskScheduler 与 SchedulerBackend 之间的关系 FIFO 与 FAIR 两种调度模式彻底解密 Task 数据 ...
- Spark:大数据的电花火石!
什么是Spark?可能你很多年前就使用过Spark,反正当年我四六级单词都是用的星火系列,没错,星火系列的洋名就是Spark. 当然这里说的Spark指的是Apache Spark,Apache Sp ...
随机推荐
- 手机访问PC端
输入所要访问的端口,然后默认下一步即可.
- python引入pytesseract报错:ValueError: Attempted relative import in non-package
http://blog.csdn.net/yifengfuxue/article/details/79015651
- 代理 ip
利用 VPN 技术通过一台服务器将自己的电脑冒名借用这个服务器的ip ,这台服务器的 ip 即为代理 ip,被冒名ip的服务器即为 代理服务器.我猜的. 实验 这次使用的是 芝麻软件 代理ip软件,其 ...
- 编写JDBC框架:(策略设计模式)
package com.itheima.domain; //一般:实体类的字段名和数据库表的字段名保持一致 //约定优于编码 public class Account { private int id ...
- Window环境下RabbitMQ的安装和配置教程
一.安装 首先,RabbitMQ基于Erlang语言环境,所以需要先安装Erlang. Erlang下载地址:http://www.erlang.org/downloads 按照安装程序默认安装完成就 ...
- InputStream流无法重复读取的解决办法
前言:今天工作的需要需要读取aws云上S3桶里面的PDF数据,第一步能够正常的获取PDF文件的InputStream流,然后,我为了测试使用了IOUtils.toString(is)将流System. ...
- UOJ#424 【集训队作业2018】count
题意 我们定义长度为\(n\),每个数为\(1\sim m\)之间的整数且\(1\sim m\)都至少出现一次的序列为合法序列.再定义\(pos(l,r)\)表示这个序列的区间\([l,r]\)之间的 ...
- 【大数据】SparkSql学习笔记
第1章 Spark SQL概述 1.1 什么是Spark SQL Spark SQL是Spark用来处理结构化数据的一个模块,它提供了2个编程抽象:DataFrame和 DataSet,并且作为分布式 ...
- 菜菜小问题——python中print函数 以及单引号、双引号、三引号
直接面对——引号,就是为了保证打印出来的东东符合预期 如:print("小菜菜") 结果是: .================1========================= ...
- Java线程池 与Lambda
七.线程池.Lambda 1.1基本概念: 线程池:其实就是一个容纳多个线程的容器,其中的线程可以反复使用,省去了频繁创建线程对象的操作,无需反复创建线程而消耗过多的资源. 1.2线程池的好处: ...