『实践』VirtualBox 5.1.18+Centos 6.8+hadoop 2.7.3搭建hadoop完全分布式集群及基于HDFS的网盘实现
『实践』VirtualBox 5.1.18+Centos 6.8+hadoop 2.7.3搭建hadoop完全分布式集群及基于HDFS的网盘实现
1.基本设定和软件版本
|
主机名 |
ip |
对应角色 |
|
master |
192.168.56.4 |
NameNode |
|
slave1 |
192.168.56.3 |
DataNode1 |
|
slave2 |
192.168.56.5 |
DataNode2 |
- Windows主机设置的ip为192.168.56.88
- hadoop压缩包解压地址:/usr/local/hadoop
- 虚拟机用户都为ljy
- VirtualBox-5.1.18、CentOS-6.8、hadoop-2.7.3.tar.gz、jdk1.7.0_79,且都是64位版本。
- Centos6.8:链接:http://pan.baidu.com/s/1qYdjAY4 密码:7gxm
- 此处连接方式使用Host-only模式,虚拟机不能联网;如使用网络地址转换(NAT),虚拟机可以联网。

图1 Host-Only

图2 windows ip
2.VirtualBox安装Centos6.8
这个网上教程太多,这里不详细介绍了。
3.FileZilla
FileZilla是一款免费开源的ftp软件,此处用于Windows电脑和Centos虚拟机之间互传文件。

图3 FileZilla
4.安装jdk1.7.0-79
- l 查看系统自带的jdk并将其全部卸载:rpm -qa | grep jdk
- l 下载jdk包,并将其解压到/usr/java路径下。
- l 配置全局java环境变量(以root用户执行):vim /etc/profile
- l 在profile中的添加以下内容:
- export JAVA_HOME=/usr/java/jdk1.7.0_79
- export JRE_HOME=/usr/java/jdk1.7.0_79/jre
- l 使profile配置生效:source /etc/profile
- l 检测已经安装的jdk:java -version
- l 注意:其他DataNode执行上述同样操作。

图4 /etc/profile文件中添加的内容

图5 安装的jdk
5.设置NameNode的ip
方法一:
- l 切换到root,输入密码:su
- l 进入设置界面:setup
- l 选择网络设置
- l 选择设备设置
- l 选择eth0
- l 进行网络配置
- l 注意:其他DataNode执行上述同样操作。

图6 选择网络设置

图7 选择设备设置

图8 选择eth0

图9 NameNode的网络设置
方法二:
- l 打开网络连接,直接设置

图10 网络连接设置
方法三:
- l 编辑eth0文件:sudo vim /etc/sysconfig/network-scripts/ifcfg-eth0
- l 在文件中修改BOOTPROTO=static,添加IPADDR、NETMASK和GATEWAY。

图11 配置eth0

图12 windows电脑ping通NameNode
6.给用户增加sudo权限(此处用户名为ljy)
- l 切换到root,输入密码:su
- l 给sudoers增加写权限:chmod u+w /etc/sudoers
- l 编译sudoers文件:vim /etc/sudoers
- l 在#%wheel ALL=(ALL) NOPASSWD: ALL下方增加 xxx ALL=(ALL) NOPASSWD: ALL,注意xxx为用户,此处为ljy
- l 去掉sudoers文件的写权限:chmod u-w /etc/sudoers
- l 注意:其他DataNode执行上述同样操作。

图13 /etc/sudoers文件中增加的语句
7.配置每台机器的机器名和对应IP
- l 编辑hosts文件:sudo vim /etc/hosts
- l 编辑network文件,修改HOSTNAME为master:sudo vim /etc/sysconfig/network,注意:此处例子master为NameNode机器的机器名。
- l 使文件立即生效:source /etc/sysconfig/network
- l 注意:其他DataNode执行上述同样操作。只有/etc/sysconfig/network中的hostname需要改为对应机器的机器名,例如:slave1。

图14 在/etc/hosts文件中添加的内容

图15 /etc/sysconfig/network文件中修改HOSTNAME为master

图16 修改机器名和对应IP
8.永久关闭防火墙
- l 永久关闭防火墙,重启后生效:chkconfig iptables off
- l 即时性关闭防火墙,重启后失效:service iptables stop
- l 此处执行这两条语句就不用重启了。
- l 注意:其他DataNode执行上述同样操作。

图17 永久关闭防火墙
9.配置SSH免密码登录
- 检查是否安装了ssh,若没有安装,则安装(以下指令并非都要执行):
- l 检查是否安装ssh:rpm -qa| grep ssh
- l 查看ssh运行状态:service sshd status
- l 安装ssh:yum install ssh
- l 查看是否开机启动:chkconfig --list sshd
- l 设置开机启动:chkconfig sshd on
- l 注意:其他DataNode执行上述同样操作。

图18 设置ssh开机启动
配置ssh免密码登录:
- l 进入~/.ssh目录:cd ~/.ssh
- l 每台机器执行:ssh-keygen -t rsa,一路回车。
- l 生成两个文件,一个私钥,一个公钥,把id_rsa,pub文件追加到授权key(authorized_keys):cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
- l 通过ssh localhost命令登录本机,首次时会让输入yes/no,但是不需要密码:ssh localhost
- l 如果目录没有通过NFS共享,需要利用此方法共享公钥(此处是master把公钥发给slave1,别的就类似互相共享):ssh-copy-id slave1。
- l 注意:其他DataNode执行上述同样操作。

图19 ssh-keygen -t rsa命令执行后~/.ssh文件中

图20 设置ssh无密码登录

图21 master把公钥发送给slave1

图22 ssh免密码登录
10.安装hadoop 2.7.3
- l 转换到用户ljy下:su - ljy
- l 获取管理员权限:su
- l 输入管理员密码:
- l 新建hadoop文件夹:mkdir /usr/local/hadoop
- l 将hadoop包移动到hadoop文件夹中:mv /home/ljy/下载/hadoop-2.7.3.tar.gz /usr/local/hadoop
- l 移动到hadoop文件中:cd /usr/local/hadoop
- l 解压hadoop包:tar zxvf hadoop-2.7.3.tar.gz
- l 将hadoop-2.7.3重命名为hadoop: mv hadoop-2.7.3 hadoop
- l 注意:其他DataNode执行上述同样操作。
将hadoop文件的拥有者改为ljy用户和组
- l 引动到hadoop解压的路径:cd /usr/local/hadoop
- l 将hadoop文件的拥有者改为ljy用户:sudo chown -R ljy:ljy hadoop
- l 查看/hadoop目录下所有用户属于ljy的文件或者文件夹:find /hadoop -user ljy
配置环境变量
- l 编辑/etc/profile文件:vim /etc/profile
- l 在profile文件中添加的内容:export HADOOP_HOME=/usr/local/hadoop/hadoop、export PATH=$HADOOP_HOME/bin:$PATH
- l 使环境变量生效:source /etc/profile
- l 注意:其他DataNode执行上述同样操作。

图23 hadoop文件夹中的文件目录

图24 /etc/profile文件中添加的内容
配置Hadoop:
- l 移动到hadoop配置文件路径:cd /usr/local/hadoop/hadoop/etc/hadoop
- l 查看当前文件夹中的文件目录:ls

图25 hadoop配置文件夹中的文件目录
- l 配置hadoop-env.sh:export JAVA_HOME=/usr/java/jdk1.7.0_79
- l 添加masters,内容为slave1:vim masters
- l 配置通用属性:vim core-site.xml
<configuration>
<property>
<!-- NameNode 地址 -->
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<!-- 临时目录设定 -->
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/hadoop/tmp</value>
</property>
<property>
<name>fs.checkpoint.period</name>
<value>3600</value>
</property>
<property>
<name>fs.checkpoint.size</name> //以日志大小间隔 做备份间隔
<value>67108864</value>
</property>
</configuration>

图26 core-site.xml配置内容
- l 配置HDFS属性:vim hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave1:50090</value>
//注意:此处机器名要为另一个。
</property>
<property>
<name>dfs.http.address</name>
<value>master:50070</value>
</property>
<property>
<!-- 缺省的块复制数量,默认为3 -->
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<!-- -->
<name>dfs.webhdfs.enable</name>
<value>true</value>
</property>
<property>
<!-- 关闭hdfs权限验证 -->
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<!-- 存贮在本地的名字节点数据镜象的目录,作为名字节点的冗余备份 -->
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hadoop/hdfs/name</value>
</property>
<property>
<!-- 数据节点的块本地存放目录 -->
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hadoop/hdfs/data</value>
</property>
</configuration>

图27 hdfs-site.xml配置内容
- l 复制mapred-site.xml.template并重命名为mapred-site.xml:cp mapred-site.xml.template mapred-site.xml
- l 配置MapReduce属性:vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>

图28 mapred-site.xml配置内容

图29 配置core-site.xml、hdfs-site.xml、mapred-site.xml
- l 配置yarn-site.xml:vim yarm-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>

图30yarn-site.xml配置内容
- l 配置slaves:vim slaves
slave1
slave2
11.复制NameNode作为DataNode

图31 NameNode和DataNode
- l 复制master,并重命名为slave1和slave2。
- l 运行slave2,将hostname改为slave2。
- l 将网络连接的ip改为192.168.56.5。
- l 对slave1的操作同对slave2的操作一样。

图32 master ping slave2
- l master ping windows时,需要关闭windows的防火墙。

图33 master ping windows

图34 windows ping master

图35 slave1 ping slave2
12.在master节点格式化hdfs
- l 到bin路径下:cd /usr/local/hadoop/hadoop/bin
- l Hadoop初始化:hdfs namenode -format
13.启动HDFS和YARN
- l 到sbin路径下:lcd /usr/local/hadoop/hadoop/sbin
- l 启动全部服务:start-all.sh
- l 查看:jps

图36 master

图37 slave1

图38 slave2
- 通过浏览器的方式验证:
- http://192.168.56.4:50070 (HDFS管理界面)

图39 HDFS管理界面
- http://192.168.56.4:8088 (YARN管理界面)

图40 YARN管理界面
14. MyEclipse开发环境配置
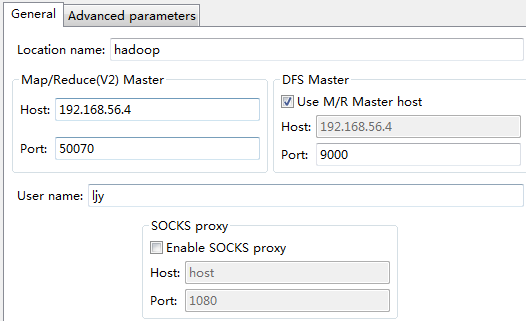
15.使用HDFS API实现云盘基本功能
- 配置configuration
//设置configuration
public static Configuration setConf(Configuration conf){
conf.addResource("/core-site.xml");
conf.addResource("/hdfs-site.xml");
return conf;
}
- 判断是否是目录
//判断是否是目录
public static boolean isDirectory(String path, Configuration conf) throws IOException{ FileSystem fs = FileSystem.get(conf);
boolean res = fs.isDirectory(new Path(path));
return res;
}
- 显示当前目录下所有文件
//显示当前目录下所有文件
public static List<FileStatusInfo> listAll(String dirPath,Configuration conf) throws IOException{
FileSystem fs = FileSystem.get(conf);
List<FileStatusInfo> fileList = new ArrayList<FileStatusInfo>();
FileStatus[] dirStatus = fs.listStatus(new Path(dirPath));
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss");//设置日期格式
//判断是否是目录
if(fs.isDirectory(new Path(dirPath))){
for(int i = ; i < dirStatus.length; i++){
if(dirStatus[i].getOwner().equals("ljy")){
FileStatusInfo fsi = new FileStatusInfo();
fsi.setId(i); fsi.setName(dirStatus[i].getPath().getName());
fsi.setLen(dirStatus[i].getLen());
fsi.setModificationTime(df.format(dirStatus[i].getModificationTime()));
fileList.add(fsi);
}
}
}
return fileList;
}
- 上传文件
// 上传文件
public static void copyFromLocal(String localPath, String hdfsPath, Configuration conf) throws Exception {
FileSystem fs = FileSystem.get(conf);
fs.copyFromLocalFile(new Path(localPath), new Path(hdfsPath));
fs.close(); // 需要关闭文件流
}
- 下载文件
// 下载文件
public static void downFromHdfs(String localPath, String hdfspath, Configuration conf) throws Exception {
FileSystem fs = FileSystem.get(conf);
fs.copyToLocalFile(false,new Path(hdfspath), new Path(localPath),true);
fs.close();
}
- 创建文件夹
// 创建文件夹
public static boolean createDir(String dirName, Configuration conf) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path dir = new Path(dirName);
boolean res = fs.mkdirs(dir);
fs.close();
return res;
}
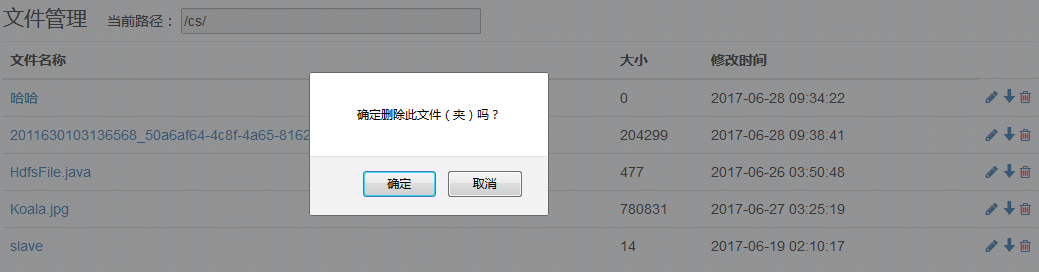
- 删除文件(夹)
// 删除文件(夹)
public static boolean deleteDir(String dirName, Configuration conf) throws Exception {
FileSystem fs = FileSystem.get(conf);
boolean res = fs.delete(new Path(dirName), true);
return res;
}
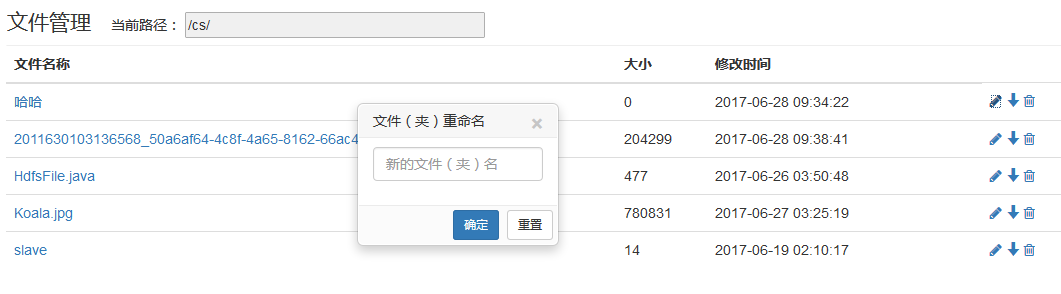
- 文件夹重命名
// 文件(夹)重命名
public static boolean reNameFile(String oldname, String rename, Configuration conf) throws Exception {
FileSystem fs = FileSystem.get(conf);
boolean res = fs.rename(new Path(oldname), new Path(rename));
return res;
}
16.实现效果
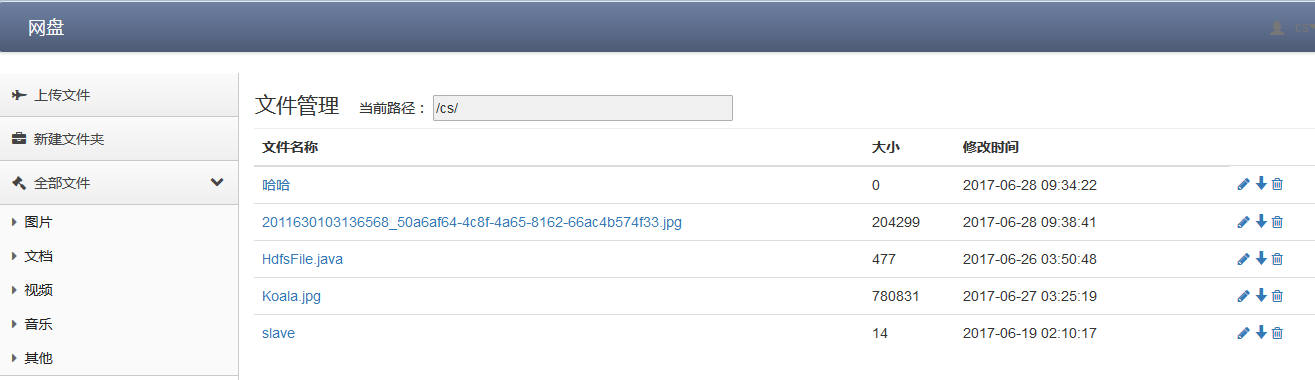
- 显示当前目录下所有文件
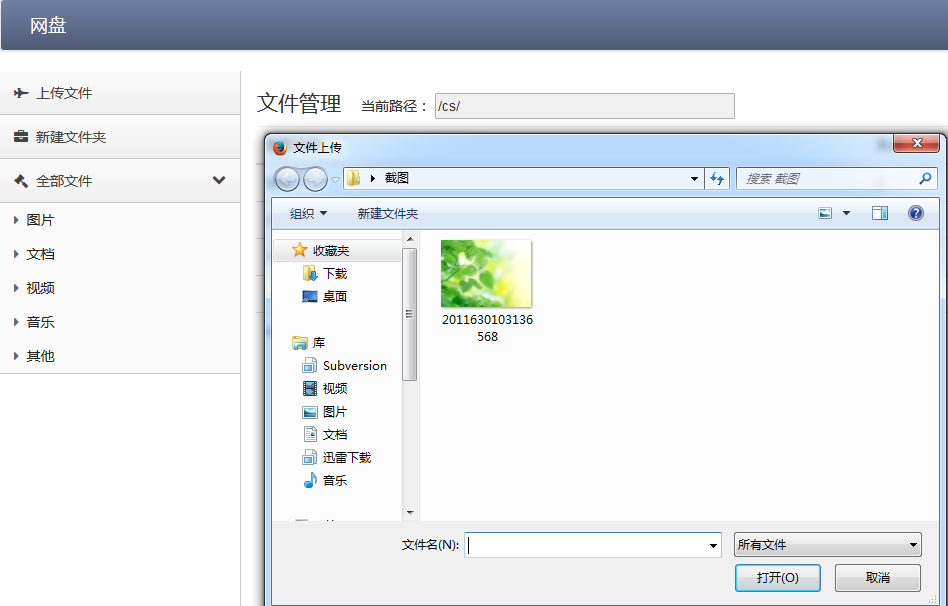
- 文件上传
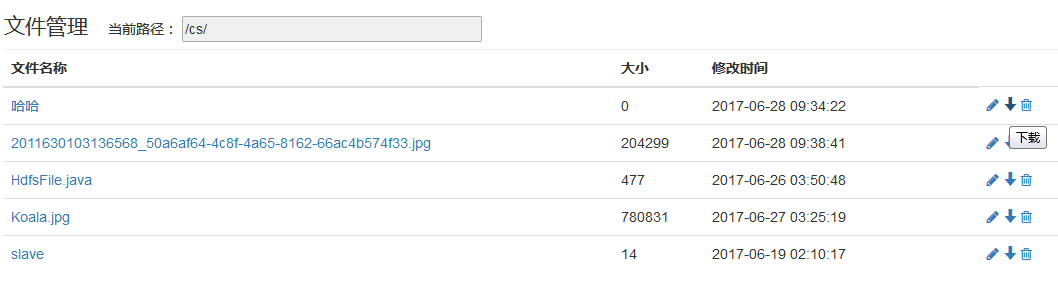
- 文件下载
- 新建文件夹
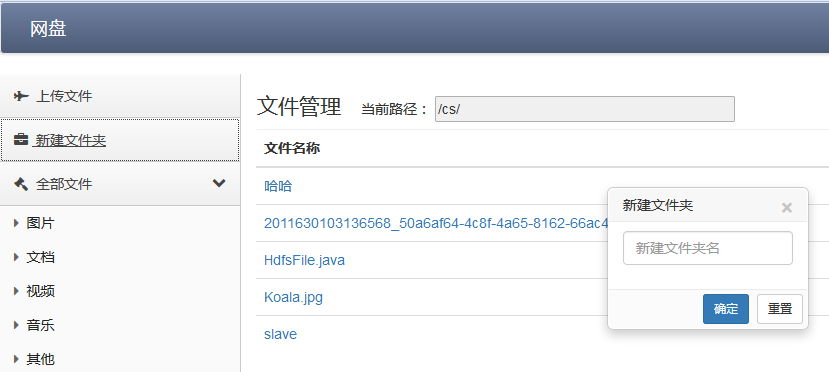
- 文件(夹)重命名
- 删除文件(夹)
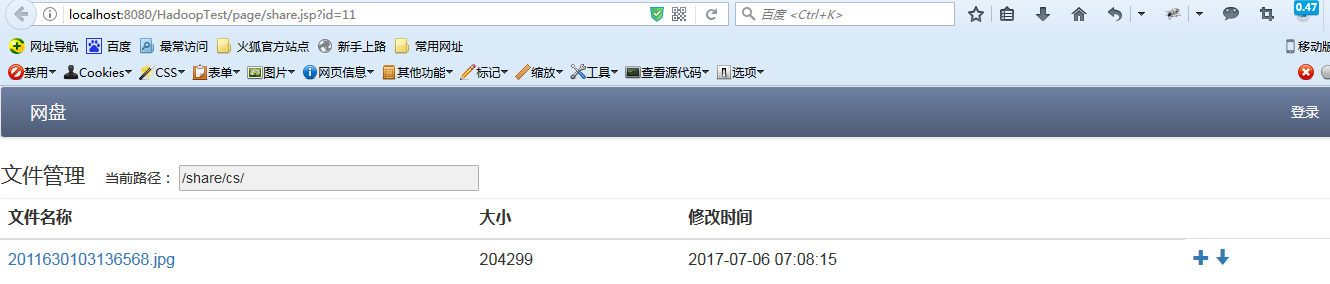
- 分享文件

17.参考文献
安装java1.6 http://www.cnblogs.com/ssslinppp/p/5923298.html
CentOS常用的文件操作命令总结: http://www.haorooms.com/post/centeros_wj_zj
Linux给用户添加sudo权限 :http://blog.chinaunix.net/uid-25305993-id-126661.html
yarn-site.xml参数设置: http://blog.csdn.net/xiaoshunzi111/article/details/51221139
VirtualBox虚拟机网络环境解析和搭建-NAT、桥接、Host-Only、Internal、端口映射 :http://blog.csdn.net/yxc135/article/details/8458939
hadoop(2.x)以hadoop2.2为例完全分布式最新高可靠安装文档: http://www.aboutyun.com/thread-7684-1-1.html
Hadoop之Secondary NameNode : http://blog.csdn.net/zwto1/article/details/50839191
hadoop2.x常用端口、定义方法及默认端口、hadoop1.X端口对比和新旧 Hadoop 脚本 / 变量 / 位置变化表: http://www.aboutyun.com/thread-7513-1-1.html
『实践』VirtualBox 5.1.18+Centos 6.8+hadoop 2.7.3搭建hadoop完全分布式集群及基于HDFS的网盘实现的更多相关文章
- CentOS中搭建Redis伪分布式集群【转】
解压redis 先到官网https://redis.io/下载redis安装包,然后在CentOS操作系统中解压该安装包: tar -zxvf redis-3.2.9.tar.gz 编译redis c ...
- 『实践』Yalmip获取对偶函数乘子
『实践』Yalmip获取对偶函数乘子 一.sdpsetting设置 Yalmip网站给出的说明 savesolveroutput默认为0,需要设置为1才会保存输出结果. 下面是我模型的约束个数: 二. ...
- 『实践』Yalmip+Ipopt+Cplex使用手册
Yalmip+Ipopt+Cplex使用手册 1.软件版本 Cplex 12.6.2,Matlab R2014a,Ipopt 3.12.9,Yalmip 2.Cplex添加方法 官方下载地址: htt ...
- 基于CentOS与VmwareStation10搭建Oracle11G RAC 64集群环境:2.搭建环境-2.4. 安装JDK
2.4.安装JDK 2.4.1.准备JDK 在百度搜索:JDK下载 2.4.2.上传JDK put E:\软件安装文件\jdk-8u11-linux-x64.rpm /home/linuxrac1/D ...
- 基于CentOS与VmwareStation10搭建Oracle11G RAC 64集群环境:4.安装Oracle RAC FAQ-4.5.安装Grid,创建ASM磁盘组空间不足
因之前分区时,分区的Last cylinder的值选了“1”,导致创建磁盘组空间不足.解决办法是先删除分区,重新创建分区并删除ASM磁盘,然后重建ASM磁盘 1. 先删除分区,重新创建分区: 1)查询 ...
- 分布式实时日志系统(四) 环境搭建之centos 6.4下hbase 1.0.1 分布式集群搭建
一.hbase简介 HBase是一个开源的非关系型分布式数据库(NoSQL),它参考了谷歌的BigTable建模,实现的编程语言为 Java.它是Apache软件基金会的Hadoop项目的一部分,运行 ...
- 超详细!CentOS 7 + Hadoop3.0.0 搭建伪分布式集群
超详细!CentOS 7 + Hadoop3.0.0 搭建伪分布式集群 ps:本文的步骤已自实现过一遍,在正文部分避开了旧版教程在新版使用导致出错的内容,因此版本一致的情况下照搬执行基本不会有大错误. ...
- CentOS下Docker与.netcore(五)之 三剑客之一Docker-swarm集群
CentOS下Docker与.netcore(一) 之 安装 CentOS下Docker与.netcore(二) 之 Dockerfile CentOS下Docker与.netcore(三)之 三剑客 ...
- 基于CentOS与VmwareStation10搭建Oracle11G RAC 64集群环境:3.安装Oracle RAC-3.1.安装并配置ASM驱动
3.1.安装并配置ASM驱动 3.3.1.检查内核 [root@linuxrac2 etc]# uname -r 2.6.18-164.el5 下载以下rpm包(注意rpm包版本和Linux内核版本一 ...
随机推荐
- 对MP4一些概念的理解
首先,对视频一些基本概念的理解: I帧:i帧又称为内编码帧,是一种自带全部信息的独立帧,可独立解码,可理解为一张静态图片,视频序列中的第一个帧始终是i帧,因为它是关键帧. P帧:P帧又称为帧间预测编码 ...
- Window环境下RabbitMQ的安装和配置教程
一.安装 首先,RabbitMQ基于Erlang语言环境,所以需要先安装Erlang. Erlang下载地址:http://www.erlang.org/downloads 按照安装程序默认安装完成就 ...
- ElasticSearch 2 (31) - 信息聚合系列之时间处理
ElasticSearch 2 (31) - 信息聚合系列之时间处理 摘要 如果说搜索是 Elasticsearch 里最受欢迎的功能,那么按时间创建直方图一定排在第二位.为什么需要使用时间直方图? ...
- Linux基础二(挂载、关机重启与系统等级)
一.Linux 基础之挂载 1. 挂载和查询 1.1 挂载 什么叫挂载?装系统的时候要给硬盘分区,在 Windows 中要分 C 盘 D 盘 DEF 盘,这个操作我们叫做分配盘符,分配盘符之后我们就可 ...
- (改进)Python语言实现词频统计
需求: 1.设计一个词频统计的程序. 2.英语文章中包含的英语标点符号不计入统计. 3.将统计结果按照单词的出现频率由大到小进行排序. 设计: 1.基本功能和用法会在程序中进行提示. 2.原理是利用分 ...
- Xshell登录Docker
使用SSH协议登录即可,用户名为docker,密码为tcuser
- php环境搭建及入门
在php文件里,写入header('content-type:text/html;charset = uft-8'); <?php header('content-type:text/html; ...
- CORS跨域资源共享简述
什么是CORS? 默认情况下,为预防某些而已行为,浏览器的XHR对象只能访问来源于同一个域中的资源.但是我们在日常实际开发中,常常会遇到跨域请求的需求,因此就出现了一种跨域请求的方案:CORS(Cro ...
- Python【知识点】傻傻的函数内变量
问题的由来 有个学生问我一个问题关于函数内部变量的我们来一起看下代码: Code1 x = 50 def func(): print(x) global x print("x修改前的值:&q ...
- Emacs 安装配置使用教程
Emacs 安装配置使用教程 来源 https://www.jianshu.com/u/a27b97f900f7 序|Preface 先来一篇有趣的简介:Emacs和Vim:神的编辑器和编辑器之神 - ...