高可用Kubernetes集群-14. 部署Kubernetes集群性能监控平台
参考文档:
- Github介绍:https://github.com/kubernetes/heapster
-
或者(source code):https://github.com/kubernetes/heapster/releases
- cAdvisor:https://github.com/google/cadvisor
- Influxdb:http://influxdb.com
- Grafana:http://grafana.org
开源软件cAdvisor(Container Advisor)用于监控所在节点的容器运行状态,当前已经被默认集成到kubelet组件内,默认使用tcp 4194端口。
在大规模容器集群,一般使用Heapster+Influxdb+Grafana平台实现集群性能数据的采集,存储与展示。
一.环境
1. 基础环境
|
组件 |
版本 |
Remark |
|
kubernetes |
v1.9.2 |
|
|
heapster |
v1.5.1 |
|
|
Influxdb |
v1.3.3 |
|
|
grafana |
v4.4.3 |
2. 原理
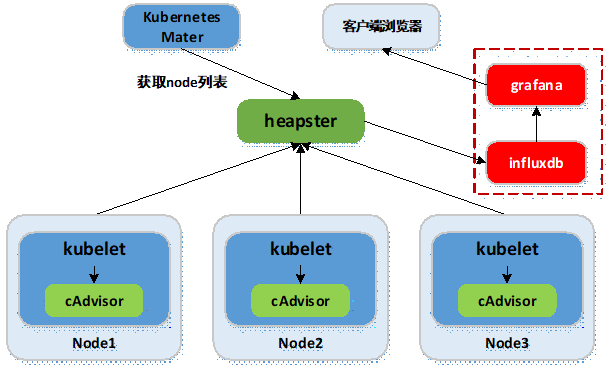
- Heapster:集群中各node节点的cAdvisor的数据采集汇聚系统,通过调用node上kubelet的api,再通过kubelet调用cAdvisor的api来采集所在节点上所有容器的性能数据。Heapster对性能数据进行聚合,并将结果保存到后端存储系统,heapster支持多种后端存储系统,如memory,Influxdb等。
- Influxdb:分布式时序数据库(每条记录有带有时间戳属性),主要用于实时数据采集,时间跟踪记录,存储时间图表,原始数据等。Influxdb提供rest api用于数据的存储与查询。
- Grafana:通过dashboard将Influxdb中的时序数据展现成图表或曲线等形式,便于查看集群运行状态。
- Heapster,Influxdb,Grafana均以Pod的形式启动与运行。
二.部署Kubernetes集群性能监控
1. 准备images
kubernetes部署服务时,为避免部署时发生pull镜像超时的问题,建议提前将相关镜像pull到相关所有节点(以下以kubenode1为例),或搭建本地镜像系统。
- 基础环境已做了镜像加速,可参考:http://www.cnblogs.com/netonline/p/7420188.html
- 需要从gcr.io pull的镜像,已利用Docker Hub的"Create Auto-Build GitHub"功能(Docker Hub利用GitHub上的Dockerfile文件build镜像),在个人的Docker Hub build成功,可直接pull到本地使用。
# heapster
[root@kubenode1 ~]# docker pull netonline/heapster-amd64:v1.5.1 # influxdb
[root@kubenode1 ~]# docker pull netonline/heapster-influxdb-amd64:v1.3.3 # grafana
[root@kubenode1 ~]# docker pull netonline/heapster-grafana-amd64:v4.4.3
2. 下载yaml范本
# release下载页:https://github.com/kubernetes/heapster/releases
# release中的yaml范本有时较https://github.com/kubernetes/heapster/tree/master/deploy/kube-config/influxdb的yaml新,但区别不大
[root@kubenode1 ~]# cd /usr/local/src/
[root@kubenode1 src]# wget -O heapster-v1.5.1.tar.gz https://github.com/kubernetes/heapster/archive/v1.5.1.tar.gz # yaml范本在heapster/deploy/kube-config/influxdb目录,另有1个heapster-rbac.yaml在heapster/deploy/kube-config/rbac目录,两者目录结构同github
[root@kubenode1 src]# tar -zxvf heapster-v1.5.1.tar.gz -C /usr/local/
[root@kubenode1 src]# mv /usr/local/heapster-1.5.1 /usr/local/heapster 本实验使用yaml文件(修改版):https://github.com/Netonline2016/kubernetes/tree/master/addons/heapster
3. heapster-rbac.yaml
# heapster需要向kubernetes-master请求node列表,需要设置相应权限;
# 默认不需要对heapster-rbac.yaml修改,将kubernetes集群自带的ClusterRole :system:heapster做ClusterRoleBinding,完成授权
[root@kubenode1 ~]# cd /usr/local/heapster/deploy/kube-config/rbac/
[root@kubenode1 rbac]# cat heapster-rbac.yaml
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: heapster
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:heapster
subjects:
- kind: ServiceAccount
name: heapster
namespace: kube-system
4. heapster.yaml
hepster.yaml由3个模块组成:ServiceAccout,Deployment,Service。
1)ServiceAccount
默认不需要修改ServiceAccount部分,设置ServiceAccount资源,获取rbac中定义的权限。
2)Deployment
# 修改处:第23行,变更镜像名;
# --source:配置采集源,使用安全端口调用kubernetes集群api;
# --sink:配置后端存储为influxdb;地址采用influxdb的service名,需要集群dns正常工作,如果没有配置dns服务,可使用service的ClusterIP地址
[root@kubenode1 ~]# cd /usr/local/heapster/deploy/kube-config/influxdb/
[root@kubenode1 influxdb]# sed -i 's|gcr.io/google_containers/heapster-amd64:v1.5.1|netonline/heapster-amd64:v1.5.1|g' heapster.yaml
[root@kubenode1 influxdb]# cat heapster.yaml
……
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: heapster
namespace: kube-system
spec:
replicas: 1
template:
metadata:
labels:
task: monitoring
k8s-app: heapster
spec:
serviceAccountName: heapster
containers:
- name: heapster
image: netonline/heapster-amd64:v1.5.1
imagePullPolicy: IfNotPresent
command:
- /heapster
- --source=kubernetes:https://kubernetes.default
- --sink=influxdb:http://monitoring-influxdb.kube-system.svc:8086
……
3)Service
默认不需要修改Service部分。
5. influxdb.yaml
influxdb.yaml由2个模块组成:Deployment,Service。
1)Deployment
# 修改处:第16行,变更镜像名;
[root@kubenode1 influxdb]# sed -i 's|gcr.io/google_containers/heapster-influxdb-amd64:v1.3.3|netonline/heapster-influxdb-amd64:v1.3.3|g' influxdb.yaml
2)Service
默认不需要修改Service部分,注意Service名字的对应即可。
6. grafana.yaml
grafana.yaml由2个模块组成:Deployment,Service。
1)Deployment
# 修改处:第16行,变更镜像名;
# 修改处:第43行,取消注释;“GF_SERVER_ROOT_URL”的value值设定后,只能通过API Server proxy访问grafana;
# 修改处:第44行,注释本行;
# INFLUXDB_HOST的value值设定为influxdb的service名,依赖于集群dns,或者直接使用ClusterIP
[root@kubenode1 influxdb]# sed -i 's|gcr.io/google_containers/heapster-grafana-amd64:v4.4.3|netonline/heapster-grafana-amd64:v4.4.3|g' grafana.yaml
[root@kubenode1 influxdb]# sed -i '43s|# value:|value:|g' grafana.yaml
[root@kubenode1 influxdb]# sed -i '44s|value:|# value:|g' grafana.yaml
[root@kubenode1 influxdb]# cat grafana.yaml
……
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: monitoring-grafana
namespace: kube-system
spec:
replicas: 1
template:
metadata:
labels:
task: monitoring
k8s-app: grafana
spec:
containers:
- name: grafana
image: netonline/heapster-grafana-amd64:v4.4.3
ports:
- containerPort: 3000
protocol: TCP
volumeMounts:
- mountPath: /etc/ssl/certs
name: ca-certificates
readOnly: true
- mountPath: /var
name: grafana-storage
env:
- name: INFLUXDB_HOST
value: monitoring-influxdb
- name: GF_SERVER_HTTP_PORT
value: ""
# The following env variables are required to make Grafana accessible via
# the kubernetes api-server proxy. On production clusters, we recommend
# removing these env variables, setup auth for grafana, and expose the grafana
# service using a LoadBalancer or a public IP.
- name: GF_AUTH_BASIC_ENABLED
value: "false"
- name: GF_AUTH_ANONYMOUS_ENABLED
value: "true"
- name: GF_AUTH_ANONYMOUS_ORG_ROLE
value: Admin
- name: GF_SERVER_ROOT_URL
# If you're only using the API Server proxy, set this value instead:
value: /api/v1/namespaces/kube-system/services/monitoring-grafana/proxy
# value: /
volumes:
- name: ca-certificates
hostPath:
path: /etc/ssl/certs
- name: grafana-storage
emptyDir: {}
……
2)Service
默认不需要修改Service部分,注意Service名字的对应即可。
三.验证
1. 启动监控相关服务
# 将heapster-rbac.yaml复制到influxdb/目录;
[root@kubenode1 ~]# cd /usr/local/heapster/deploy/kube-config/influxdb/
[root@kubenode1 influxdb]# cp /usr/local/heapster/deploy/kube-config/rbac/heapster-rbac.yaml .
[root@kubenode1 influxdb]# kubectl create -f .
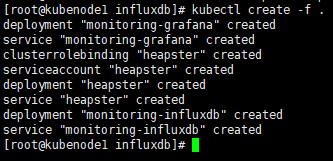
2. 查看相关服务
# 查看deployment与Pod运行状态
[root@kubenode1 ~]# kubectl get deploy -n kube-system | grep -E 'heapster|monitoring'
[root@kubenode1 ~]# kubectl get pods -n kube-system | grep -E 'heapster|monitoring'

# 查看service运行状态
[root@kubenode1 ~]# kubectl get svc -n kube-system | grep -E 'heapster|monitoring'

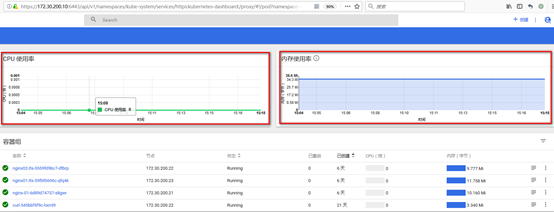
3. 访问dashboard
浏览器访问访问dashboard:https://172.30.200.10:6443/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard:/proxy
注意:Dasheboard没有配置hepster监控平台时,不能展示node,Pod资源的CPU与内存等metric图形
Node资源CPU/内存metric图形:

Pod资源CPU/内存metric图形:
4. 访问grafana
# 通过kube-apiserver访问
[root@kubenode1 ~]# kubectl cluster-info

浏览器访问访问dashboard:https://172.30.200.10:6443/api/v1/namespaces/kube-system/services/monitoring-grafana/proxy
集群节点信息:
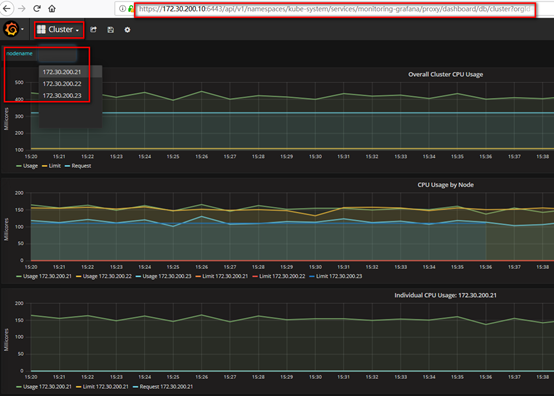
Pod信息:
高可用Kubernetes集群-14. 部署Kubernetes集群性能监控平台的更多相关文章
- cAdvisor0.24.1+InfluxDB0.13+Grafana4.0.2搭建Docker1.12.3 Swarm集群性能监控平台
目录 [TOC] 1.基本概念 既然是对Docker的容器进行监控,我们就不自己单独搭建cAdvisor.InfluxDB.Grarana了,本文中这三个实例,主要以Docker容器方式运行. 本 ...
- 高可用Kubernetes集群-15. 部署Kubernetes集群统一日志管理
参考文档: Github:https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/fluentd-elasticsear ...
- centos7.4安装高可用(haproxy+keepalived实现)kubernetes1.6.0集群(开启TLS认证)
目录 目录 前言 集群详情 环境说明 安装前准备 提醒 一.创建TLS证书和秘钥 安装CFSSL 创建 CA (Certificate Authority) 创建 CA 配置文件 创建 CA 证书签名 ...
- DolphinScheduler 集群高可用测试:有效分摊服务器压力,达到性能最大优化!
点击上方 蓝字关注我们 1 文档编写目的 Apache DolphinScheduler(简称DS)是一个分布式去中心化,易扩展的可视化DAG工作流任务调度平台.在生产环境中需要确保调度平台的稳定可靠 ...
- 【Linux运维-集群技术进阶】Nginx+Keepalived+Tomcat搭建高可用/负载均衡/动静分离的Webserver集群
额.博客名字有点长.. . 前言 最终到这篇文章了,心情是有点激动的. 由于这篇文章会集中曾经博客讲到的全部Nginx功能点.包含主要的负载均衡,还有动静分离技术再加上这篇文章的重点.通过Keepal ...
- docker compose搭建redis7.0.4高可用一主二从三哨兵集群并整合SpringBoot【图文完整版】
一.前言 redis在我们企业级开发中是很常见的,但是单个redis不能保证我们的稳定使用,所以我们要建立一个集群. redis有两种高可用的方案: High availability with Re ...
- centos7下kubernetes(3。部署kubernetes)
环境:三个centos7 K8s2是Master;K8s1是node1:K8s3是node2 官方文档:https://kubernetes.io/docs/setup/independent/ins ...
- centos7下kubernetes(5。部署kubernetes dashboard)
基于WEB的dashboard,用户可以用kubernetes dashboard部署容器话的应用,监控应用的状态,执行故障排查任务以及管理kubernetes各种资源. 在kubernetes da ...
- MySQL高可用方案-PXC环境部署记录
之前梳理了Mysql+Keepalived双主热备高可用操作记录,对于mysql高可用方案,经常用到的的主要有下面三种: 一.基于主从复制的高可用方案:双节点主从 + keepalived 一般来说, ...
随机推荐
- Win7下设置护眼的电脑豆沙绿界面
控制面板\所有控制面板项\个性化\窗口颜色和外观 "色调"(Hue)设为85,"饱和度"(Sat)设为90,"亮度" (Lum)设为205. ...
- trait代码复用
在面对对象编程中我们经常通过继承来解决部分代码多次出现的问题 php支持单继承,有时候由于不相关联的两个类的方法相同我们需要进行继承操作, trait可以实现不继承的情况下复用代码 trait的使用类 ...
- 如何使用EditPlus批量删除 带有某个字符的一行
比如以下五行,我要将带有英文字母a的一行全部批量删除1234551243243123aa244123123981232137aa 2013-04-11 19:32 提问者采纳 我这里是英文版, ...
- October 26th, 2017 Week 43rd Thursday
For success, attitude is equally as important as ability. 为取得成功,态度与能力一样重要. Today I read a news about ...
- python第二十八课——编码小常识
2.内存和硬盘: 内存:计算机硬件组成部分之一,它是一个容器,用来存储数据:处理数据速度快, 存储数据量小:断电死机数据会丢失,短暂性存储数据 硬盘:计算机硬件组成部分之一,它是一个容器,用来存储数据 ...
- An Introduction to Protocol Oriented Programming in Swift
swift面向协议编程的根本原因在于值类型的存在:面向对象必须要有引用类型的支持: Protocol Oriented approach was introduced to resolve some ...
- swift和oc的protocol的成员变量
都需要协议实现者提供具体变量: 否则认为不符合协议. @protocol edddd <NSObject> @property(nonatomic, strong) NSObject *e ...
- BZOJ2460:[BJWC2011]元素(贪心,线性基)
Description 相传,在远古时期,位于西方大陆的 Magic Land 上,人们已经掌握了用魔法矿石炼制法杖的技术.那时人们就认识到,一个法杖的法力取决于使用的矿石. 一般地,矿石越多则法力越 ...
- C++的技术探究
C++深究 函数指针 double pam(int, double); // prototype double (*pf)(int, double); // declare function poin ...
- pytorch faster_rcnn
代码地址:https://github.com/jwyang/faster-rcnn.pytorch 1.fasterRCNN.train():这个不是让网络进行训练,而是让module in tra ...