为你的 Hadoop 集群选择合适的硬件
|
随着Apache Hadoop的起步,云客户的增多面临的首要问题就是如何为他们新的的Hadoop集群选择合适的硬件。 尽管Hadoop被设计为运行在行业标准的硬件上,提出一个理想的集群配置不想提供硬件规格列表那么简单。 选择硬件,为给定的负载在性能和经济性提供最佳平衡是需要测试和验证其有效性。(比如,IO密集型工作负载的用户将会为每个核心主轴投资更多)。 在这个博客帖子中,你将会学到一些工作负载评估的原则和它在硬件选择中起着至关重要的作用。在这个过程中,你也将学到Hadoop管理员应该考虑到各种因素。 |

wangshuangshuang
|
结合存储和计算过去的十年,IT组织已经标准化了刀片服务器和存储区域网(SAN)来满足联网和处理密集型的工作负载。尽管这个模型对于一些方面的标准程序是有相当意义 的,比如网站服务器,程序服务器,小型结构化数据库,数据移动等,但随着数据数量和用户数的增长,对于基础设施的要求也已经改变。网站服务器现在有了缓存 层;数据库需要本地硬盘支持大规模地并行;数据迁移量也超过了本地可处理的数量。 大部分的团队还没有弄清楚实际工作负载需求就开始搭建他们的Hadoop集群。硬 件提供商已经生产了创新性的产品系统来应对这些需求,包括存储刀片服务器,串行SCSI交换机,外部SATA磁盘阵列和大容量的机架单元。然 而,Hadoop是基于新的实现方法,来存储和处理复杂数据,并伴随着数据迁移的减少。 相对于依赖SAN来满足大容量存储和可靠性,Hadoop在软件层次处理大数据和可靠性。 Hadoop在一簇平衡的节点间分派数据并使用同步复制来保证数据可用性和容错性。因为数据被分发到有计算能力的节点,数据的处理可以被直接发送到存储有数据的节点。由于Hadoop集群中的每一台节点都存储并处理数据,这些节点都需要配置来满足数据存储和运算的要求。 |

afei418
|
工作负载很重要吗?在几乎所有情形下,MapReduce要么会在从硬盘或者网络读取数据时遇到瓶颈(称为IO受限的应用),要么在处理数据时遇到瓶颈(CPU受限)。排序是一个IO受限的例子,它需要很少的CPU处理(仅仅是简单的比较操作),但是需要大量的从硬盘读写数据。模式分类是一个CPU受限的例子,它对数据进行复杂的处理,用来判定本体。 下面是更多IO受限的工作负载的例子:
下面是更多CPU受限的工作负载的例子:
|

deuso
|
|
Cloudera的客户需要完全理解他们的工作负载,这样才能选择最优的Hadoop硬件,而这好像是一个鸡生蛋蛋生鸡的问题。大多数工作组在没有彻底剖析他们的工作负载时,就已经搭建好了Hadoop集群,通常Hadoop运行的工作负载随着他们的精通程度的提高而完全不同。而且,某些工作负载可能会被一些未预料的原因受限。例如,某些理论上是IO受限的工作负载却最终成为了CPU受限,这是可能是因为用户选择了不同的压缩算法,或者算法的不同实现改变了MapReduce任务的约束方式。基于这些原因,当工作组还不熟悉要运行任务的类型时,深入剖析它才是构建平衡的Hadoop集群之前需要做的最合理的工作。 |
deuso
|
|
接下来需要在集群上运行MapReduce基准测试任务,分析它们是如何受限的。完成这个目标最直接的方法是在运行中的工作负载中的适当位置添加监视器来检测瓶颈。我们推荐在Hadoop集群上安装Cloudera Manager,它可以提供CPU,硬盘和网络负载的实时统计信息。(Cloudera Manager是Cloudera 标准版和企业版的一个组件,其中企业版还支持滚动升级)Cloudera Manager安装之后,Hadoop管理员就可以运行MapReduce任务并且查看Cloudera Manager的仪表盘,用来监测每台机器的工作情况。 |
deuso
|
|
第一步是弄清楚你的作业组已经拥有了哪些硬件 在为你的工作负载构建合适的集群之外,我们建议客户和它们的硬件提供商合作确定电力和冷却方面的预算。由于Hadoop会运行在数十台,数百台到数千台节点上。通过使用高性能功耗比的硬件,作业组可以节省一大笔资金。硬件提供商通常都会提供监测功耗和冷却方面的工具和建议。 |
deuso
|
为你的CDH(Cloudera distribution for Hadoop) Cluster选择硬件选择机器配置类型的第一步就是理解你的运维团队已经在管理的硬件类型。在购买新的硬件设备时,运维团队经常根据一定的观点或者强制需求来选择,并且他们倾向于工作在自己业已熟悉的平台类型上。Hadoop不是唯一的从规模效率上获益的系统。再一次强调,作为更通用的建议,如果集群是新建立的或者你并不能准确的预估你的极限工作负载,我们建议你选择均衡的硬件类型。 Hadoop集群有四种基本任务角色:名称节点(包括备用名称节点),工作追踪节点,任务执行节点,和数据节点。节点是执行某一特定功能的工作站。大部分你的集群内的节点需要执行两个角色的任务,作为数据节点(数据存储)和任务执行节点(数据处理)。 |
afei418
|
|
这是在一个平衡Hadoop集群中,为数据节点/任务追踪器提供的推荐规格:
名字节点角色负责协调集群上的数据存储,作业追踪器协调数据处理(备用的名字节点不应与集群中的名字节点共存,并且运行在与之相同的硬件环境上。)。Cloudera推荐客户购买在RAID1或10配置上有足够功率和企业级磁盘数的商用机器来运行名字节点和作业追踪器。 |

jimmyjmh
|
|
NameNode也会直接需要与群集中的数据块的数量成比列的RAM。一个好的但不精确的规则是对于存储在分布式文件系统里面的每一个1百万的数据块,分配1GB的NameNode内存。于在一个群集里面的100个DataNodes而言,NameNode上的64GB的RAM提供了足够的空间来保证群集的增长。我们也推荐把HA同时配置在NameNode和JobTracker上, 这里就是为NameNode/JobTracker/Standby NameNode节点群推荐的技术细节。驱动器的数量或多或少,将取决于冗余数量的需要。
记住, 在思想上,Hadoop 体系设计为用于一种并行环境。 |

自由之信
|
|
如果你希望Hadoop集群扩展到20台机器以上,那么我们推荐最初配置的集群应分布在两个机架,而且每个机架都有一个位于机架顶部的10G的以太网交换。当这个集群跨越多个机架的时候,你将需要添加核心交换机使用40G的以太网来连接位于机架顶部的交换机。两个逻辑上分离的机架可以让维护团队更好地理解机架内部和机架间通信对网络需求。 Hadoop集群安装好后,维护团队就可以开始确定工作负载,并准备对这些工作负载进行基准测试以确定硬件瓶颈。经过一段时间的基准测试和监视,维护团队将会明白如何配置添加的机器。异构的Hadoop集群是很常见的,尤其是在集群中用户机器的容量和数量不断增长的时候更常见-因此为你的工作负载所配置的“不理想”开始时的那组机器不是在浪费时间。Cloudera管理器提供了允许分组管理不同硬件配置的模板,通过这些模板你就可以简单地管理异构集群了。 |

几点人
|
|
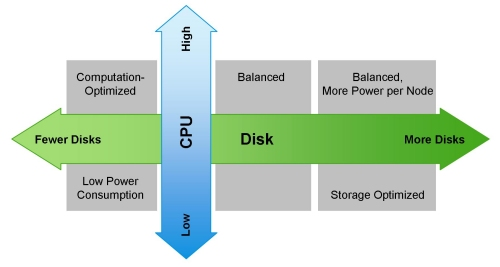
下面是针对不同的工作负载所采用对应的各种硬件配置的列表,包括我们最初推荐的“负载均衡”的配置:
(注意Cloudera期望你配置它可以使用的2x8,2x10和2x12核心CPU的配置。) 下图向你展示了如何根据工作负载来配置一台机器:
|
几点人
|
|
其他要考虑的 记住Hadoop生态系统的设计是考虑了并行环境这点非常重要。当购买处理器时,我们不建议购买最高频率(GHZ)的芯片,这些芯片都有很高的功耗(130瓦以上)。这么做会产生两个问题:电量消耗会更高和热量散发会更大。处在中间型号的CPU在频率、价格和核心数方面性价比是最好的。 当我们碰到生成大量中间数据的应用时-也就是说输出数据的量和读入数据的量相等的情况-我们推荐在单个以太网接口卡上启用两个端口,或者捆绑两个以太网卡,让每台机器提供2Gbps的传输速率。绑定2Gbps的节点最多可容纳的数据量是12TB。一旦你传输的数据超过12TB,你将需要使用传输速率为捆绑方式实现的4Gbps(4x1Gbps)。另外,对哪些已经使用10Gb带宽的以太网或者无线网络用户来说,这样的方案可以用来按照网络带宽实现工作负载的分配。如果你正在考虑切换到10GB的以太网络上,那么请确认操作系统和BIOS是否兼容这样的功能。 |
几点人
|
|
当计算需要多少内存的时候,记住Java本身要使用高达10%的内存来管理虚拟机。我们建议把Hadoop配置为只使用堆,这样就可以避免内存与磁盘之间的切换。切换大大地降低MapReduce任务的性能,并且可以通过给机器配置更多的内存以及给大多数Linux发布版以适当的内核设置就可以避免这种切换。 优化内存的通道宽度也是非常重要的。例如,当我们使用双通道内存时,每台机器就应当配置成对内存模块(DIMM)。当我们使用三通道的内存时,每台机器都应当使用三的倍数个内存模块(DIMM)。类似地,四通道的内存模块(DIMM)就应当按四来分组使用内存。 |
几点人
|
超越MapReduceHadoop不仅仅是HDFS和MapReduce;它是一个无所不包的数据平台。因此CDH包含许多不同的生态系统产品(实际上很少仅仅做为MapReduce使用)。当你在为集群选型的时候,需要考虑的附加软件组件包括Apache HBase、Cloudera Impala和Cloudera Search。它们应该都运行在DataNode中来维护数据局部性。
HBase是一个可靠的列数据存储系统,它提供一致性、低延迟和随机读写。Cloudera Search解决了CDH中存储内容的全文本搜索的需求,为新类型用户简化了访问,但是也为Hadoop中新类型数据存储提供了机会。Cloudera Search基于Apache Lucene/Solr Cloud和Apache Tika,并且为与CDH广泛集成的搜索扩展了有价值的功能和灵活性。基于Apache协议的Impala项目为Hadoop带来了可扩展的并行数据库技术,使得用户可以向HDFS和HBase中存储的数据发起低延迟的SQL查询,而且不需要数据移动或转换。 |

袁不语
|
|
由于垃圾回收器(GC)的超时,HBase的用户应该留意堆的大小的限制。别的JVM列存储也面临这个问题。因此,我们推荐每一个区域服务器的堆最大不超过16GB。HBase不需要太多别的资源而运行于Hadoop之上,但是维护一个实时的SLAs,你应该使用多个调度器,比如使用fair and capacity 调度器,并协同Linux Cgroups使用。 Impala使用内存以完成其大多数的功能,在默认的配置下,将最多使用80%的可用RAM资源,所以我们推荐,最少每一个节点使用96GB的RAM。与MapReduce一起使用Impala的用户,可以参考我们的建议 - “Configuring Impala and MapReduce for Multi-tenant Performance.” 也可以为Impala指定特定进程所需的内存或者特定查询所需的内存。 |
自由之信
|
|
搜索是最有趣的订制大小的组件。推荐的订制大小的实践操作是购买一个节点,安装Solr和Lucene,然后载入你的文档群。一旦文档群被以期望的方式来索引和搜索,可伸缩性将开始作用。持续不断的载入文档群,直到索引和查询的延迟,对于项目而言超出了必要的数值 - 此时,这让你得到了在可用的资源上每一个节点所能处理的最大文档数目的基数,以及不包括欲期的集群复制此因素的节点的数量总计基数。 结论购买合适的硬件,对于一个Hapdoop群集而言,需要性能测试和细心的计划,从而全面理解工作负荷。然而,Hadoop群集通常是一个形态变化的系统,而Cloudera建议,在开始的时候,使用负载均衡的技术文档来部署启动的硬件。重要的是,记住,当使用多种体系组件的时候,资源的使用将会是多样的,而专注与资源管理将会是你成功的关键。 我们鼓励你在留言中,加入你关于配置Hadoop生产群集服务器的经验! Kevin O‘Dell 是一个工作于Cloudera的系统工程师。 |
为你的 Hadoop 集群选择合适的硬件的更多相关文章
- 为Hadoop集群选择合适的硬件配置
随着Apache Hadoop的起步,云客户的增多面临的首要问题就是如何为他们新的的Hadoop集群选择合适的硬件. 尽管Hadoop被设计为运行在行业标准的硬件上,提出一个理想的集群配置不想提供硬件 ...
- 如何为Kafka集群选择合适的Partitions数量
转载:http://blog.csdn.net/odailidong/article/details/52571901 这是许多kafka使用者经常会问到的一个问题.本文的目的是介绍与本问题相关的一些 ...
- [转]大数据hadoop集群硬件选择
问题导读 1.哪些情况会遇到io受限制? 2.哪些情况会遇到cpu受限制? 3.如何选择机器配置类型? 4.为数据节点/任务追踪器提供的推荐哪些规格? 随着Apache Hadoop的起步,云客户 ...
- Hadoop集群(第8期)_HDFS初探之旅
1.HDFS简介 HDFS(Hadoop Distributed File System)是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开 ...
- Hadoop集群(第10期)_MySQL关系数据库
1.MySQL安装 MySQL下载地址:http://www.mysql.com/downloads/ 1.1 Windows平台 1)准备软件 MySQL版本:mysql-5.5.21-win32. ...
- 非常不错 Hadoop 的HDFS (Hadoop集群(第8期)_HDFS初探之旅)
1.HDFS简介 HDFS(Hadoop Distributed File System)是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开 ...
- 沉淀,再出发——手把手教你使用VirtualBox搭建含有三个虚拟节点的Hadoop集群
手把手教你使用VirtualBox搭建含有三个虚拟节点的Hadoop集群 一.准备,再出发 在项目启动之前,让我们看一下前面所做的工作.首先我们掌握了一些Linux的基本命令和重要的文件,其次我们学会 ...
- [hadoop读书笔记] 第九章 构建Hadoop集群
P322 运行datanode和tasktracker的典型机器配置(2010年) 处理器:两个四核2-2.5GHz CPU 内存:16-46GN ECC RAM 磁盘存储器:4*1TB SATA 磁 ...
- 保护Hadoop集群三大方法
自今年以来,不少恶意软件开始频繁向Hadoop集群服务器下手,受影响最大的莫过于连接到互联网且没有启用安全防护的Hadoop集群. 大约在两年前,开源数据库解决方案MongoDB以及Hadoop曾遭受 ...
随机推荐
- 二分图最大权匹配模板(pascal)
用uoj80的题面了: 从前一个和谐的班级,有 nlnl 个是男生,有 nrnr 个是女生.编号分别为 1,…,nl1,…,nl 和 1,…,nr1,…,nr. 有若干个这样的条件:第 vv 个男生和 ...
- Java NIO 详解(一)
一.基本概念描述 1.1 I/O简介 I/O即输入输出,是计算机与外界世界的一个借口.IO操作的实际主题是操作系统.在java编程中,一般使用流的方式来处理IO,所有的IO都被视作是单个字节的移动,通 ...
- CodeForces - 707C
C. Pythagorean Triples time limit per test 1 second memory limit per test 256 megabytes input standa ...
- fgt2eth Script
fgt2eth Script explanation_on_how_to_packet_capture_for_only_certain_TCP_flags_v2.txt Packet capture ...
- python(27) 抓取淘宝买家秀
selenium 是Web应用测试工具,可以利用selenium和python,以及chromedriver等工具实现一些动态加密网站的抓取.本文利用这些工具抓取淘宝内衣评价买家秀图片. 准备工作 下 ...
- MySQL-->高级-->001-->MySQL备份与恢复测试
- App爬虫神器mitmproxy和mitmdump的使用
原文 mitmproxy是一个支持HTTP和HTTPS的抓包程序,有类似Fiddler.Charles的功能,只不过它是一个控制台的形式操作. mitmproxy还有两个关联组件.一个是mitmdum ...
- Python常用模块-时间模块(time&datetime)
Python常用模块-时间模块(time & datetime) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.初始time模块 #!/usr/bin/env pyth ...
- docker mysql authentication_string client does not support authentication 连接问题
docker安装mysql后,本地navicat连接报错client does not support authentication 解决办法: 1. docker ps -a 查找到容器id 2. ...
- postman断言的几种方式(二)
1.检查响应体是否包含字符串 pm.test("Body matches string", function () { pm.expect(pm.response.text()). ...