CS229 1 .线性回归与特征归一化(feature scaling)
线性回归是一种回归分析技术,回归分析本质上就是一个函数估计的问题(函数估计包括参数估计和非参数估计),就是找出因变量和自变量之间的因果关系。回归分析的因变量是应该是连续变量,若因变量为离散变量,则问题转化为分类问题,回归分析是一个有监督学习问题。
线性其实就是一系列一次特征的线性组合,在二维空间中是一条直线,在三维空间中是一个平面,然后推广到n维空间,可以理解维广义线性吧。
例如对房屋的价格预测,首先提取特征,特征的选取会影响模型的精度,比如房屋的高度与房屋的面积,毫无疑问面积是影响房价的重要因素,二高度基本与房价不相关
下图中挑选了 面积、我是数量、层数、建成时间四个特征,然后选取了一些train Set{x(i) , y(i)}。
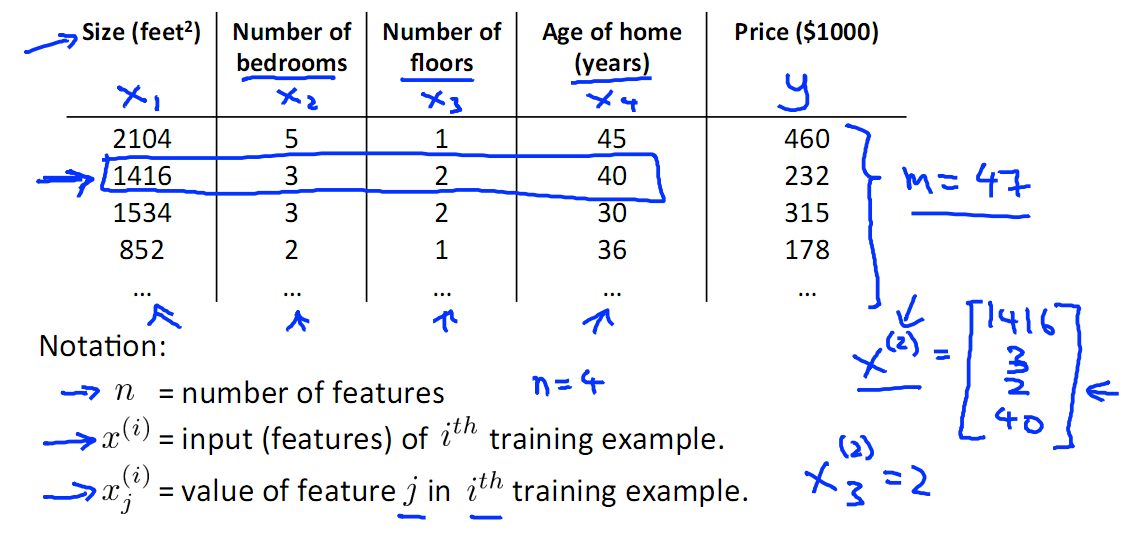
有了这些数据之后就是进行训练,下面附一张有监督学习的示意图

Train Set 根据 学习算法得到模型h,对New Data x,直接用模型即可得到预测值y,本例中即可得到房屋大小,其实本质上就是根据历史数据来发现规律,事情总是偏向于向历史发生过次数多的方向发展。
下面就是计算模型了,才去的措施是经验风险最小化,即我们训练模型的宗旨是,模型训练数据上产生结果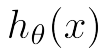 , 要与实际的y(i)越接近越好(假定x0 =1),定义损失函数J(θ)如下,即我们需要损失函数越小越好,本方法定义的J(θ)在最优化理论中称为凸(Convex)函数,即全局只有一个最优解,然后通过梯度下降算法找到最优解即可,梯度下降的形式已经给出。
, 要与实际的y(i)越接近越好(假定x0 =1),定义损失函数J(θ)如下,即我们需要损失函数越小越好,本方法定义的J(θ)在最优化理论中称为凸(Convex)函数,即全局只有一个最优解,然后通过梯度下降算法找到最优解即可,梯度下降的形式已经给出。

梯度下降的具体形式:关于梯度下降的细节,请参阅 梯度下降详解

局部加权回归
有时候样本的波动很明显,可以采用局部加权回归,如下图,红色的线为局部加权回归的结果,蓝色的线为普通的多项式回归的结果。蓝色的线有一些欠拟合了。

局部加权回归的方法如下,首先看线性或多项式回归的损失函数“

很明显,局部加权回归在每一次预测新样本时都会重新确定参数,以达到更好的预测效果。当数据规模比较大的时候计算量很大,学习效率很低。并且局部加权回归也不是一定就是避免underfitting,因为那些波动的样本可能是异常值或者数据噪声。
在求解线性回归的模型时,有两个需要注意的问题
一就是特征组合问题,比如房子的长和宽作为两个特征参与模型的构造,不如把其相乘得到面积然后作为一个特征来进行求解,这样在特征选择上就做了减少维度的工作。
二就是特征归一化(Feature Scaling),这也是许多机器学习模型都需要注意的问题。
有些模型在各个维度进行不均匀伸缩后,最优解与原来等价,例如logistic regression。对于这样的模型,是否标准化理论上不会改变最优解。但是,由于实际求解往往使用迭代算法,如果目标函数的形状太“扁”,迭代算法可能收敛得很慢甚至不收敛。所以对于具有伸缩不变性的模型,最好也进行数据标准化。
归一化后有两个好处:
1. 提升模型的收敛速度
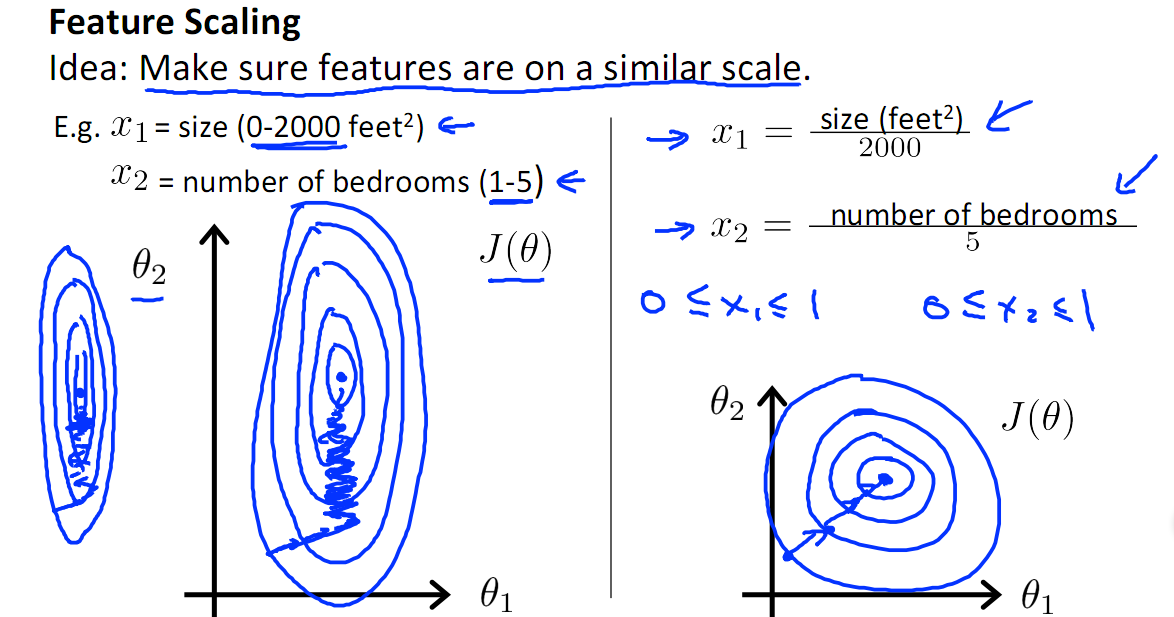
如下图,x1的取值为0-2000,而x2的取值为1-5,假如只有这两个特征,对其进行优化时,会得到一个窄长的椭圆形,导致在梯度下降时,梯度的方向为垂直等高线的方向而走之字形路线,这样会使迭代很慢,相比之下,右图的迭代就会很快
2.提升模型的精度
归一化的另一好处是提高精度,这在涉及到一些距离计算的算法时效果显著,比如算法要计算欧氏距离,上图中x2的取值范围比较小,涉及到距离计算时其对结果的影响远比x1带来的小,所以这就会造成精度的损失。所以归一化很有必要,他可以让各个特征对结果做出的贡献相同。
下边是常用归一化方法
1). 线性归一化,线性归一化会把输入数据都转换到[0 1]的范围,公式如下
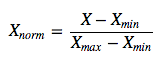
该方法实现对原始数据的等比例缩放,其中Xnorm为归一化后的数据,X为原始数据,Xmax、Xmin分别为原始数据集的最大值和最小值。
2). 0均值标准化,0均值归一化方法将原始数据集归一化为均值为0、方差1的数据集,归一化公式如下:
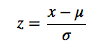
其中,μ、σ分别为原始数据集的均值和方法。该种归一化方式要求原始数据的分布可以近似为高斯分布,否则归一化的效果会变得很糟糕。
关于归一化方法的选择
1) 在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,第二种方法(Z-score standardization)表现更好。
2) 在不涉及距离度量、协方差计算、数据不符合正太分布的时候,可以使用第一种方法或其他归一化方法。比如图像处理中,将RGB图像转换为灰度图像后将其值限定在[0 255]的范围。
选择方法是参考自http://blog.csdn.net/zbc1090549839/article/details/44103801,至于为什么,我现在也还不清楚
线性回归,我用java实现的,源码地址 https://github.com/ooon/toylib
参考文献:
http://www.cnblogs.com/LBSer/p/4440590.html
CS229 1 .线性回归与特征归一化(feature scaling)的更多相关文章
- (一)线性回归与特征归一化(feature scaling)
线性回归是一种回归分析技术,回归分析本质上就是一个函数估计的问题(函数估计包括参数估计和非参数估计),就是找出因变量和自变量之间的因果关系.回归分析的因变量是应该是连续变量,若因变量为离散变量,则问题 ...
- 数据归一化Feature Scaling
数据归一化Feature Scaling 当我们有如上样本时,若采用常规算欧拉距离的方法sqrt((5-1)2+(200-100)2), 样本间的距离被‘发现时间’所主导.尽管5是1的5倍,200只是 ...
- 斯坦福大学公开课机器学习:梯度下降运算的特征缩放(gradient descent in practice 1:feature scaling)
以房屋价格为例,假设有两个特征向量:X1:房子大小(1-2000 feets), X2:卧室数量(1-5) 关于这两个特征向量的代价函数如下图所示: 从上图可以看出,代价函数是一个又瘦又高的椭圆形轮廓 ...
- 机器学习中的特征缩放(feature scaling)
参考:https://blog.csdn.net/iterate7/article/details/78881562 在运用一些机器学习算法的时候不可避免地要对数据进行特征缩放(feature sca ...
- 131.006 Unsupervised Learning - Feature Scaling | 非监督学习 - 特征缩放
@(131 - Machine Learning | 机器学习) 1 Feature Scaling transforms features to have range [0,1] according ...
- Feature Scaling
定义:Feature scaling is a method used to standardize the range of independent variables or features of ...
- 浅谈Feature Scaling
浅谈Feature Scaling 定义:Feature scaling is a method used to standardize the range of independent variab ...
- Feature Scaling深入理解
Feature Scaling 可以翻译为特征归一化,或者数据归一化,比如统计学习中,我们一般都会对不同量纲的特征做归一化,深度学习中经常会谈到增加的BN层,LRN层会带来训练收敛速度的提升,等等.问 ...
- 特征工程(Feature Engineering)
一.什么是特征工程? "Feature engineering is the process of transforming raw data into features that bett ...
随机推荐
- 20165308 学习基础和C语言基础调查
学习基础和C语言基础调查 技能学习 我认为给学生具体的, 能实践的, 能马上看到因果关系的教材和练习, 是激发学生兴趣, 好奇心, 求知欲的好方法. -- 引用自<做中学> 老师博客中注重 ...
- oracle之 ORA-12557: TNS: 协议适配器不可加载
操作系统:windows 7数据库版本: 11.2.0.1问题描述:直接通过 sqlplus sys/oracle@10.10.100.109:1521/ysxt as sysdba 可以登录,但是通 ...
- 弱网测试—Network-Emulator-Toolkit工具
参考别人网址:http://blog.csdn.net/no1mwb/article/details/53638681 弱网测试,属于健壮性测试:怎么样去做弱网测试呢? 一.安装弱网测试工具-Netw ...
- spring-IOC容器(一)
ApplicationContext 代表IOC容器(控制反转) ApplicationContext的主要实现类: ——ClassPathXmlApplicationContext:从类路径下加载配 ...
- DeviceIoControl函数对应的四种数据交换方式
交换方式 输入缓冲区 输出缓冲区 METHOD_BUFFE ...
- C#语法中一个问号(?)和两个问号(??)的运算符
(1).C#语法中一个个问号(?)的运算符是指:可以为 null 的类型. MSDN上面的解释: 在处理数据库和其他包含不可赋值的元素的数据类型时,将 null 赋值给数值类型或布尔型以及日期类型的功 ...
- Simple Logging Facade for Java 简单日志门面(Facade)
SLF4J是为各种 loging APIs提供一个简单统一的接口,从而使得最终用户能够在部署的时候配置自己希望的loging APIs实现.Logging API实现既可以选择直接实现SLF4J接口的 ...
- 用monit监控mongodb,崩溃后自动重启mongdb
什么是monit Monit是一个跨平台的用来监控Unix/linux系统(比如Linux.BSD.OSX.Solaris)的工具.Monit特别易于安装,而且非常轻量级(只有500KB大小),并且不 ...
- Azure ARM (22) 使用Azure PowerShell创建Azure RM VM
<Windows Azure Platform 系列文章目录> 在Azure China获得VM Image,可以执行下面的脚本. Get-AzureRmVMImagePublisher ...
- [蓝桥杯]ALGO-48.算法训练_关联矩阵
题目描述: 问题描述 有一个n个结点m条边的有向图,请输出他的关联矩阵. 输入格式 第一行两个整数n.m,表示图中结点和边的数目.n<=,m<=. 接下来m行,每行两个整数a.b,表示图中 ...