__细看InnoDB数据落盘 图解 MYSQL
http://hatemysql.com/?p=503
1. 概述
前面很多大侠都分享过MySQL的InnoDB存储引擎将数据刷新的各种情况。我们这篇文章从InnoDB往下,看看数据从InnoDB的内存到真正写到存储设备的介质上到底有哪些缓冲在起作用。
我们通过下图看一下相关的缓冲:

图 1 innodb all buffers
从上图中,我们可以看到,数据InnoDB到磁盘需要经过
- InnoDB buffer pool, Redo log buffer。这个是InnoDB应用系统本身的缓冲。
- page cache /Buffer cache(可通过o_direct绕过)。这个是vfs层的缓冲。
- Inode cache/directory buffer。这个也是vfs层的缓冲。需要通过O_SYNC或者fsync()来刷新。
- Write-Back buffer。(可设置存储控制器参数绕过)
- Disk on-borad buffer。(可通过设置磁盘控制器参数绕过)
这里我们使用术语“缓冲”(一般为buffer)来表示对数据写的暂存,使用术语“缓存”(一般为cache)来表示对数据读的暂存。顾名思义,由于底层存储设备和内存之间速率的差异,缓冲是用来暂“缓”对底层存储设备IO的“冲”击。缓存主要是在内存中暂“存”从磁盘读到的数据,以便接下来对这些数据的访问不用再次访问慢速的底层存储设备。
buffer和cache的讨论可以参考彭立勋的:
http://www.penglixun.com/tech/system/buffer_and_cache_diff.html
下面我们对这些缓冲自顶向下逐一进行详细的介绍。
2. InnoDB层
该层的缓冲都放在主机内存中,它的目的主要是在应用层管理自己的数据,避免慢速的读写操作影响了InnoDB的响应时间。
InnoDB层主要包括两个buffer:redo log buffer和innodb buffer pool。redo log buffer用来暂存对重做日志redo log的日志写,InnoDB buffer pool存储了从磁盘设备读到的InnoDB数据,也缓冲了对InnoDB数据写,即脏页数据。如果主机掉电或者MySQL异常宕机,innodb buffer pool将无法及时刷新到磁盘,那么InnoDB就只能从上一个checkpoint使用redo log来前滚;而redo log buffer如果不能及时刷新到磁盘,那么由于redo log中数据的丢失,就算使用redo 前滚,用户提交的事务由于没有真正的记录到非易失型的磁盘介质中,就丢失掉了。
控制redo log buffer刷新时机的参数是innodb_flush_log_at_trx_commit,而控制redo log buffer和innodb buffer pool刷新方式的参数为innodb_flush_method。针对这两个参数详细介绍的文章有非常多,我们这里主要从缓冲的角度来解析。
2.1. innodb_flush_log_at_trx_commit
控制redo log buffer的innodb_flush_log_at_trx_commit目前支持3种不同的参数值0,1,2
图 2 innodb_flush_log_at_trx_commit示意图
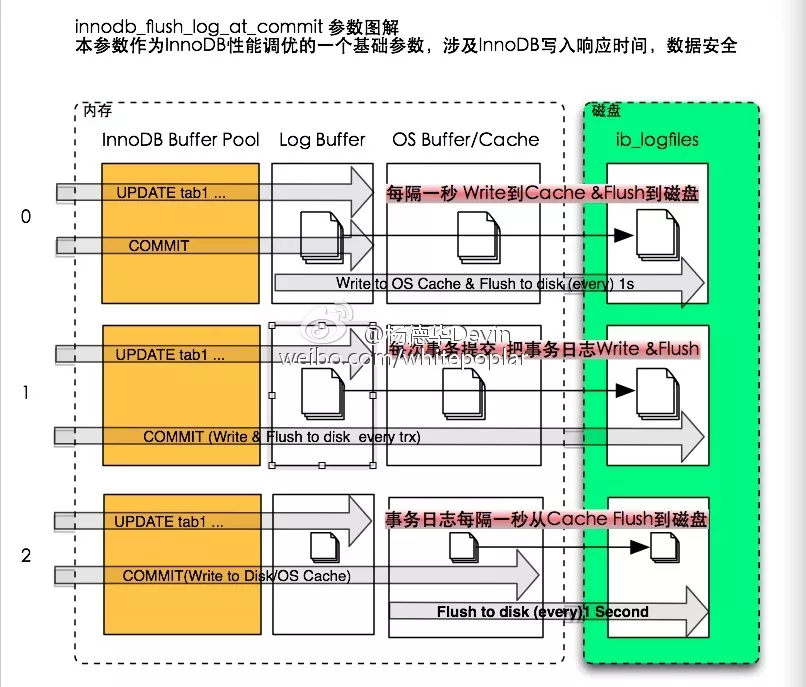
这里偷个懒,直接引用应元的图。另外,更新一下innodb_flush_log_at_trx_commit=2时在5.6的变化:
< 5.6.6: 每隔一秒将redo log buffer中的数据刷新到磁盘
= 5.6.6:每隔innodb_flush_log_at_timeout秒将数据刷新到磁盘中去。
我们这里不再详细讨论这个问题,具体细节可以参考MySQL数据丢失讨论
2.2. innodb_flush_method
控制innodb buffer pool的innodb_flush_method目前支持4种不同的参数值:
- fdatasync
- O_DSYNC
- O_DIRECT
- O_DIRECT_NO_FSYNC
这里我们注意到有几个问题:
- innodb_flush_method指定的不仅是“数据文件”的刷新方式,也指定了“日志文件”刷新方式。
- 这些参数里面没有在windows环境下的参数配置,现在大家都开始不鸟盖茨兄了?其实在注释里面写了,windows就使用async_unbuffered,并且不允许修改,所以没有写到列表里面。
- 前三个参数值只允许在6.6和5.6.6之前的版本中用,从5.6.7开始新增了O_DIRECT_NO_FSYNC。也就是说用O_DIRECT打开文件,但是不用fsync()同步数据。这个由于在较新的Linux内核和部分文件系统中,使用O_DIRECT就可以保证数据安全,不用专门再用fsync()来同步,保证元数据也刷新到非易失型的磁盘介质。例如:XFS就不能用这个参数。O_DIRECT绕过了page cache,为什么还要用fsync()再刷新以下,我们在下节专门讨论。
- 有人会说referense文档有个小bug,6.6之前的版本default是fdatasync,但是Valid Values可指定的值内竟然没有fdatasync。
| System Variable Name | innodb_flush_method | |
| Variable Scope | Global | |
| Dynamic Variable | No | |
| Permitted Values (<= 5.6.6) | ||
| Type (Linux) | string | |
| Default | fdatasync | |
| Valid Values | O_DSYNC | |
| O_DIRECT | ||
表格 1 innodb_flush_method可选值
其实这里是他故意的,因为fdatasync()和fsync()是不一样的,就像O_DSYNC和O_SYNC的区别一样。Fdatasync和O_DSYNC仅用于数据同步,fsync()和O_SYNC用于数据和元数据meta-data同步。但是MySQL用fdatasync参数值来指明“数据文件”和“日志文件”是用fsync()打开的(注意:不是fdatasync()),这个是历史原因,所以5.6特意把它从可选值中去掉,避免误解。当然你如果仍然要使用fsync()来同步,那就对innodb_flush_method什么都不要指定就可以了。
- 除了O_DIRECT_NO_FSYNC以外,InnoDB都使用fsync()刷新“数据文件”。这里的异常就是O_DIRECT_NO_FSYNC。
- 如果指定O_DIRECT,O_DIRECT_NO_FSYNC,数据文件是以O_DIRECT打开(solaris上用directio()方式打开,如果Innodb的数据文件都放在单独的设备时,可以在mount 时使用forcedirectio使得整个文件系统都是以directio打开。这里指明为innodb而不是MySQL的原因是,MyISAM不要用directio())
对O_DIRECT_NO_FSYNC模式下日志文件是否可以用O_DIRECT方式打开的,我们特地找到mysql 5.6.14的storage/innobase/os/os0file.cc文件的os_file_create_func函数,摘录代码如下:
#ifdef UNIV_NON_BUFFERED_IO
// TODO: Create a bug, this looks wrong. The flush log
// parameter is dynamic.
if (type == OS_LOG_FILE && srv_flush_log_at_trx_commit == 2) {
/* Do not use unbuffered i/o for the log files because
value 2 denotes that we do not flush the log at every
commit, but only once per second */
} else if (srv_win_file_flush_method == SRV_WIN_IO_UNBUFFERED) {
attributes |= FILE_FLAG_NO_BUFFERING;
}
#endif /* UNIV_NON_BUFFERED_IO */
也就是说,对于日志文件来说,如果设置innodb_flush_log_at_trx_commit为2,O_DIRECT是无效的。
闲话少说,下面的一个表和一张图能够更加直观的说明问题:
重新加工了orczhou的刷新关系表:
| Open log | Flush log | flush log | Open datafile | flush datafile |
| fdatasync | fsync() | fsync() | ||
| O_DSYNC | O_SYNC | fsync() | ||
| O_DIRECT | fsync() | O_DIRECT | fsync() | |
| O_DIRECT_NO_FSYNC | fsync() | O_DIRECT | ||
| All_O_DIRECT(percona) | O_DIRECT | fsync() | O_DIRECT | fsync |
表格 2 innodb_flush_method数据文件和日志刷新对应表
图 3 innodb_flush_method数据文件和日志刷新示意图
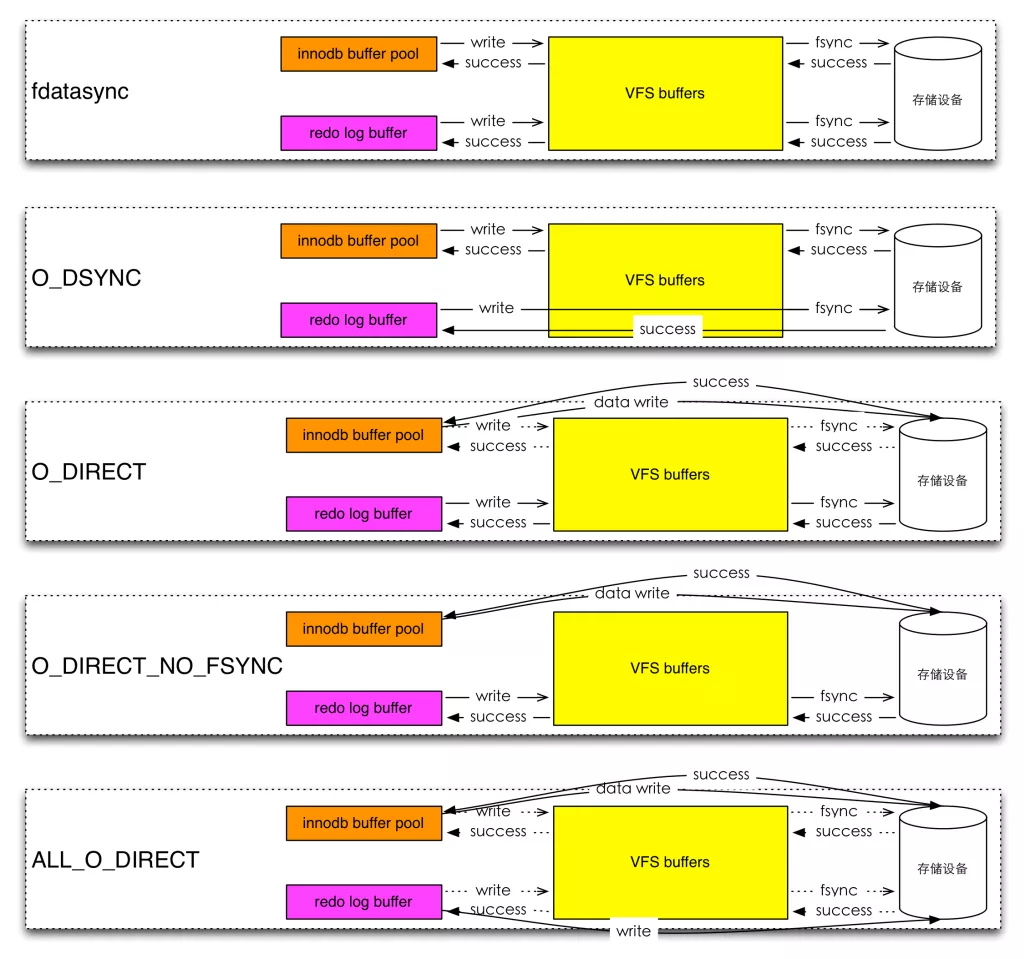
3. VFS层
该层的缓冲都放在主机内存中,它的目的主要是在操作系统层缓冲数据,避免慢速块设备读写操作影响了IO的响应时间。
3.1. 细究O_DIRECT/O_SYNC标签
在前面redo log buffer和innodb buffer pool的讨论中涉及到很多数据刷新和数据安全的问题,我们在本节中,专门讨论O_DIRECT/O_SYNC标签的含义。
我们打开一个文件并写入数据,VFS和文件系统是怎么把数据写到硬件层列,下图展示了关键的数据结构:
图 4 VFS cache图
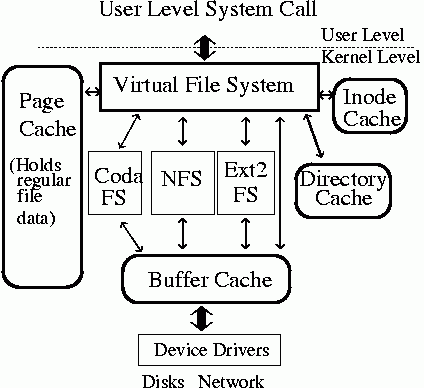
该图引用自The linux kernel’s VFS Layer。
图中,我们看到该层中主要有page_cache/buffer cache/Inode-cache/Directory cache。其中page_cache/buffer cache主要用于缓冲内存结构数据和块设备数据。而inode-cache用于缓冲inode,directory-cache用于缓冲目录结构数据。
根据文件系统和操作系统的不同,一般来说对一个文件的写入操作包括两部分,对数据本身的写入操作,以及对文件属性(metadata元数据)的写入操作(这里的文件属性包括目录,inode等)。
了解了这些以后,我们就能够比较简单的说清楚各个标志的意义了:
| page cache | buffer cache | inode cache | dictory cache | |
| O_DIRECT | write bypass | write bypass | write & no flush | write & no flush |
| O_DSYNC/fdatasync() | write & flush | write & flush | write & no flush | write & no flush |
| O_SYNC/fsync() | write & flush | write & flush | write & flush | write & flush |
表格 3 VFS cache刷新表
- O_DSYNC和fdatasync()的区别在于:是在每一个IO提交的时刻都针对对应的page cache和buffer cache进行刷新;还是在一定数据的写操作以后调用fdatasync()的时刻对整个page cache和buffer cache进行刷新。O_SYNC和fsync()的区别同理。
- page cache和buffer cache的主要区别在于一个是面向实际文件数据,一个是面向块设备。在VFS上层使用open()方式打开那些使用mkfs做成文件系统的文件,你就会用到page cache和buffer cache,而如果你在Linux操作系统上使用dd这种方式来操作Linux的块设备,你就只会用到buffer cache。
- O_DSYNC和O_SYNC的区别在于:O_DSYNC告诉内核,当向文件写入数据的时候,只有当数据写到了磁盘时,写入操作才算完成(write才返回成功)。O_SYNC比O_DSYNC更严格,不仅要求数据已经写到了磁盘,而且对应的数据文件的属性(例如文件inode,相关的目录变化等)也需要更新完成才算write操作成功。可见O_SYNC较之O_DSYNC要多做一些操作。
- Open()的referense中还有一个O_ASYNC,它主要用于terminals, pseudoterminals, sockets, 和pipes/FIFOs,是信号驱动的IO,当设备可读写时发送一个信号(SIGIO),应用进程捕获这个信号来进行IO操作。
- O_SYNC和O_DIRECT都是同步写,也就是说只有写成功了才会返回。
回过头来,我们再来看innodb_flush_log_at_trx_commit的配置就比较好理解了。O_DIRECT直接IO绕过了page cache/buffer cache以后为什么还需要fsync()了,就是为了把directory cache和inode cache元数据也刷新到存储设备上。
而由于内核和文件系统的更新,有些文件系统能够保证保证在O_DIRECT方式下不用fsync()同步元数据也不会导致数据安全性问题,所以InnoDB又提供了O_DIRECT_NO_FSYNC的方式。
当然,O_DIRECT对读和对写都是有效的,特别是对读,它可以保证读到的数据是从存储设备中读到的,而不是缓存中的。避免缓存中的数据和存储设备上的数据是不一致的情况(比如你通过DRBD将底层块设备的数据更新了,对于非分布式文件系统,缓存中的内容和存储设备上的数据就不一致了)。但是我们这里主要讨论缓冲(写buffer),就不深入讨论了。这个问题了。
3.2. O_DIRECT优劣势
在大部分的innodb_flush_method参数值的推荐中都会建议使用O_DIRECT,甚至在percona server分支中还提供了ALL_O_DIRECT,对日志文件也使用了O_DIRECT方式打开。
3.2.1. 优势:
- 节省操作系统内存:O_DIRECT直接绕过page cache/buffer cache,这样避免InnoDB在读写数据少占用操作系统的内存,把更多的内存留个innodb buffer pool来使用。
- 节省CPU。另外,内存到存储设备的传输方式主要有poll,中断和DMA方式。使用O_DIRECT方式提示操作系统尽量使用DMA方式来进行存储设备操作,节省CPU。
3.2.2. 劣势
- 字节对齐。O_DIRECT方式要求写数据时,内存是字节对齐的(对齐的方式根据内核和文件系统的不同而不同)。这就要求数据在写的时候需要有额外的对齐操作。可以通过/sys/block/sda/queue/logical_block_size知道对齐的大小,一般都是512个字节。
- 无法进行IO合并。O_DIRECT绕过page cache/buffer cache直接写存储设备,这样如果对同一块数据进行重复写就无法在内存中命中,page cache/buffer cache合并写的功能就无法生效了。
- 降低顺序读写效率。如果使用O_DIRECT打开文件,则读/写操作都会跳过cache,直接在存储设备上读/写。因为没有了cache,所以文件的顺序读写使用O_DIRECT这种小IO请求的方式效率是比较低的。
总的来说,使用O_DIRECT来设置innodb_flush_method并不是100%对所有应用和场景都是适用的。
4. 存储控制器层
该层的缓冲都放在存储控制器的对应板载cache中,它的目的主要是在存储控制器层缓冲数据,避免慢速块设备读写操作影响了IO的响应时间。
当数据被fsync()等刷到存储层时,首先会发送到存储控制器层。常见的存储控制器就是Raid卡,而目前大部分的Raid卡都有1G或者更大的存储容量。这个缓冲一般为易失性的存储,通过板载电池/电容来保证该“易失性的存储”的数据在机器断电以后仍然会同步到底层的磁盘存储介质上。
关于存储控制器我们有一些几个方面需要注意的:
- write back/write through:
针对是否使用缓冲,一般的存储控制器都提供write back和write through两种方式。write back方式下,操作系统提交的写数据请求直接写入到缓冲中就返回成功;write through方式下,操作系统提交的写数据请求必须要真正写到底层磁盘介质上才返回成功。
- 电池/电容区别:
为了保证机器掉电以后在“易失性”缓冲中的数据能够及时刷新到底层磁盘介质上,存储控制器上都有电池/电容来保证。普通的电池有容量衰减的问题,也就是说每隔一段时间,板载的电池都要被控制充放电一次,以保证电池的容量。在电池充放过程中,被设置为write-back的存储控制器会自动变为write through。这个充放电的周期(Learn Cycle周期)一般为90天,LSI卡可以通过MegaCli来查看:
#MegaCli -AdpBbuCmd -GetBbuProperties-aAll
BBU Properties for Adapter: 0
Auto Learn Period: 90 Days
Next Learn time: Tue Oct 14 05:38:43 2014
Learn Delay Interval:0 Hours
Auto-Learn Mode: Enabled
如果你每隔一段时间发现IO请求响应时间突然慢下来了,就有可能是这个问题哦。通过MegaCli -AdpEventLog -GetEvents -f mr_AdpEventLog.txt -aALL的日志中的Event Description: Battery started charging就可以确定是否发生了发生了充放电的情况。
由于电池有这个问题,新的Raid卡会配置电容来保证“易失性”缓冲中的数据能够及时刷新到底层磁盘介质上,这样就没有充放电的问题了。
- read/write ratio:
HP的smart array提供对cache的读和写的区别(Accelerator Ratio),
hpacucli ctrl all show config detail|grep ‘Accelerator Ratio’
Accelerator Ratio: 25% Read / 75% Write
这样你就可以根据应用的实际情况来设置用于缓存读和缓冲写的cache的比例了。
- 开启Direct IO
为了能够让上层的设备使用Direct IO方式来绕过raid卡,对Raid需要设置开启DirectIO方式:
/opt/MegaRAID/MegaCli/MegaCli64 -LDSetProp -Direct -Immediate -Lall -aAll
- LSI flash raid:
上面我们提到了“易失性”缓冲,如果我们现在有一个非易失性的缓冲,并且容量达到几百G,这样的存储控制器缓冲是不是更能给底层设备提速?作为老牌的Raid卡厂商,LSI目前就有这样的存储控制器,使用write back方式和比较依赖存储控制器缓冲的应用可以考虑使用这种类型的存储控制器。
- write barriers
目前raid卡的cache是否有电池或者电容保护对Linux来说是不可见的,所以Linux为了保证日志文件系统的一致性,默认会打开write barriers,也就是说,它会不断的刷新“易失性”缓冲,这样会大大降低IO性能。所以如果你确信底层的电池能够保证“易失性”缓冲会刷到底层磁盘设备的话,你可以在磁盘mount的时候加上-o nobarrier。
5. 磁盘控制器层
该层的缓冲都放在磁盘控制器的对应板载cache中。存储设备固件(firmware)会按规则排序将写操作真正同步到介质中去。这里主要是保证写的顺序性,对机械磁盘来说,这样可以尽量让一次磁头的移动能够完成更多的磁碟写入操作。
一般来说,DMA控制器也是放在磁盘这一层的,通过DMA控制器直接进行内存访问,能够节省CPU的资源。
对于机械硬盘,因为一般的磁盘设备上并没有电池电容等,无法保证在机器掉电时磁盘cache里面的所有数据能够及时同步到介质上,所以我们强烈建议把disk cache关闭掉。
Disk cache可以在存储控制器层关闭。例如,使用MegaCli关闭的命令如下:
MegaCli -LDSetProp -DisDskCache -Lall -aALL
6. 总结
从InnoDB到最终的介质,我们经过了各种缓冲,他们的目的其实很明确,就是为了解决:内存和磁盘的速度不匹配的问题,或者说是磁盘的速度过慢的问题。
另外,其实最懂数据是否应该缓冲/缓存的还是应用本身,VFS,存储控制器和磁盘只能通过延迟写入(以便合并重复IO,使随机写变成顺序写)来缓解底层存储设备慢速造成的响应速度慢的问题。所以数据库类型的应用都会来自己管理缓冲,然后尽量避免操作系统和底层设备的缓冲。
但是其实由于目前SSD固态硬盘和PCIe Flash卡的出现,内存和磁盘之间的速度差异被大大缩减了,这些缓冲是否必要,软硬件哪些可改进的,对软硬件工程师的一大挑战。
参考:
http://www.codeproject.com/Articles/460057/HDD-FS-O_SYNC-Throughput-vs-Integrity
http://rdc.taobao.com/blog/dba/html/296_innodb_flush_method_performance.html
http://www.orczhou.com/index.php/2009/08/innodb_flush_method-file-io/
http://blog.csdn.net/yuyin86/article/details/8113305
https://www.usenix.org/legacy/event/usenix01/full_papers/kroeger/kroeger_html/node8.html
http://www.lsi.com/downloads/Public/Direct%20Assets/LSI/Benchmark_Tips.pdf
http://www.lsi.com/products/flash-accelerators/pages/default.aspx。
http://en.wikipedia.org/wiki/Direct_memory_access
http://en.wikipedia.org/wiki/Disk_buffer
标签:
innodb_flush_method,O_DIRECT,O_SYNC,fsync,fdatasync,open,mysql5.6,page_cache,cache buffer,disk buffer,inode buffer,write through,write back,write barriers,dma
7. 附录
7.1. O_Direct的方式的python code
错误的方式:
import os
f = os.open(‘file’, os.O_CREAT | os.O_TRUNC | os.O_DIRECT | os.O_RDWR)
s = ‘ ‘ * 1024
os.write(f, s)
Traceback (most recent call last):
File “”, line 1, in
OSError: [Errno 22] Invalid argument
正确的方式:
import os
import mmap
f = os.open(‘file’, os.O_CREAT | os.O_DIRECT | os.O_TRUNC | os.O_RDWR)
m = mmap.mmap(-1, 1024 * 1024)
s = ‘ ‘ * 1024 * 1024
m.write(s)
os.write(f, m)
os.close(f)
__细看InnoDB数据落盘 图解 MYSQL的更多相关文章
- 细看InnoDB数据落盘 图解 MYSQL 专家hatemysql
http://hatemysql.com/?p=503 1. 概述 前面很多大侠都分享过MySQL的InnoDB存储引擎将数据刷新的各种情况.我们这篇文章从InnoDB往下,看看数据从InnoDB的 ...
- 细看INNODB数据落盘
本文来自:沃趣科技 http://www.woqutech.com/?p=1459 1. 概述 前面很多大侠都分享过MySQL的InnoDB存储引擎将数据刷新的各种情况.我们这篇文章从InnoDB往 ...
- linux系统数据落盘之细节
本文节选自这里,原文以mysql innodb系统为例,介绍了数据经过的各层级的buffer和cache,其它系统也有相似的原理,摘录于此. 3. VFS层 该层的缓冲都放在主机内存中,它的目的 ...
- Java如何保证文件落盘?
本文转载自Java如何保证文件落盘? 导语 在之前的文章Linux/UNIX编程如何保证文件落盘中,我们聊了从应用到操作系统,我们要如何保证文件落盘,来确保掉电等故障不会导致数据丢失.JDK也封装了对 ...
- Linux/UNIX编程如何保证文件落盘
本文转载自Linux/UNIX编程如何保证文件落盘 导语 我们编写程序write数据到文件中时,其实数据不会立马写入磁盘,而是会经过层层缓存.每层缓存都有自己的刷新时机,每层缓存都刷新后才会写入磁盘. ...
- 面试题:了解MySQL的Flush-List吗?顺便说一下脏页的落盘机制!(文末送书)
Hi,大家好!我是白日梦! 今天我要跟你分享的MySQL话题是:"了解Flush-List吗?顺便说一下脏页的落盘机制!(文末送书)" 本文是MySQL专题的第 8 篇,共110篇 ...
- MySQL · 引擎特性 · InnoDB 数据页解析
前言 之前介绍的月报中,详细介绍了InnoDB Buffer Pool的实现细节,Buffer Pool主要就是用来存储数据页的,是数据页在内存中的动态存储方式,而本文介绍一下数据页在磁盘上的静态存储 ...
- SQL Server中数据的修改是如何落盘的?
SQL Server 维护着一个叫做buffer cache的东西, 在buffer cache中SQL Server 读取必须被取回的data pages. 数据在修改时并不是直接写到磁盘上的, 而 ...
- Mysql+innodb数据存储逻辑
Mysql+innodb数据存储逻辑. 表空间由段,区,页组成 ibdata1:共享表空间.即所有的数据都存放在这个表空间内.如果用户启用了innodb_file_per_table,则每张表内的数据 ...
随机推荐
- CentOS7 下安装 NFS,Linux/Windows 作为客户端
目录 一.简介 1. 定义 2. 版本和变化 3. 部署说明 二.服务端 1. 关闭防火墙 2. 安装 nfs 3. 配置说明 4. 配置共享目录 5. 启动服务 6. 确认启动成功 三.Linux ...
- Java-Maven(八):配置远程中央仓库的各种方法
一.远程仓库的配置 在平时的开发中,我们往往不会使用默认的中央仓库,默认的中央仓库访问的速度比较慢,访问的人或许很多,有时候也无法满足我们项目的需求,可能项目需要的某些构件中央仓库中是没有的,而在其他 ...
- zoj 2104 Let the Balloon Rise(map映照容器的应用)
题目链接: http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemCode=2104 题目描述: Contest time again! Ho ...
- ASP.NET开发,且编且改,分清职责
本篇Insus.NET使用一个实例,分享在ASP.NET开发时,一个功能一个方法(函数),且编且改,一步一个脚印把实例完成.在方法多变多形式的情况之下,怎样把写出来程序简单明了. 下面是一个Excel ...
- Spring基础(5): 构造函数注入无法处理循环依赖
public class Person{ public Leader leader; public Person(Leader l){ this.leader= l; } } public class ...
- date时间格式化
Date方法的扩展 /** * 时间格式化 * @param fmt * @returns {*} * @constructor */ // (new Date()).Format("yyy ...
- Oracle空表导出
执行: Select 'alter table '||table_name||' allocate extent;' from user_tables where num_rows=0 执行该命令后产 ...
- ADO.NET 【增】【删】【改】【查】
数据访问 Using System.Data.SqlClient; 对应命名空间 -- SqlConnection ...
- 月赛 && SX_ACM 惨痛教训
1.cnt变量若有多次询问,一定要记得初始化!!! 2.多组数据输出入,区泛~. 3.高性能问题,考虑位运算,
- 解决代码报红:Cannot resolve symbol 'xxx'
直接复制别人的代码,maven依赖到自己的IDEA中,个别代码报红,说是不能加载这个东西,检查代码没错,依赖没错,引入jar包也没错 最后网上找到了解决方法,参考文章 如上图所示,一般建议点击Inva ...