hadoop和hbase高可用模式部署
记录apache版本的hadoop和hbase的安装,并启用高可用模式。
1. 主机环境
我这里使用的操作系统是centos 6.5,安装在vmware上,共三台。
| 主机名 | IP | 操作系统 | 用户名 | 安装目录 |
|---|---|---|---|---|
| node1 | 192.168.1.101 | centos 6.5 | wxyuan | /opt/hadoop,/opt/hbase |
| node2 | 192.168.1.102 | centos 6.5 | wxyuan | /opt/hadoop,/opt/hbase |
| node3 | 192.168.1.103 | centos 6.5 | wxyuan | /opt/hadoop,/opt/hbase |
2. 集群规划
| node1 | node2 | node3 |
|---|---|---|
| NameNode | NameNode | |
| DataNode | DataNode | DataNode |
| DFSZKFailoverController | DFSZKFailoverController | |
| ResourceManager | ResourceManager | |
| NodeManager | NodeManager | NodeManager |
| JournalNode | JournalNode | JournalNode |
| HMaster | HMaster | |
| HRegionServer | HRegionServer | HRegionServer |
| Zookeeper | Zookeeper | Zookeeper |
hadoop、hbase、zookeeper和jdk的版本信息如下:
| 组件 | 版本号 |
|---|---|
| JDK | 1.7.079 |
| Hadoop | 2.6.0 |
| HBase | 1.1.3 |
| Zookeeper | 3.4.6 |
下载地址:
JDK: http://www.oracle.com/technetwork/java/javase/downloads/java-archive-downloads-javase7-521261.html
zookeeper: http://archive.apache.org/dist/zookeeper/
hadoop: https://archive.apache.org/dist/hadoop/core/
hbase: http://archive.apache.org/dist/hbase/
hadoop和bhase的高可用依赖于zookeeper,所以需要安装zookeeper集群.关于JDK和zookeeper的安装,这里不再叙述。
3. 配置SSH免密码登陆
高可用模式下,hadoop的故障切换需要通过ssh登陆到其它机器,进行主备切换,因此需要配置主机间的免密码登陆。配置方式可参考Linux配置ssh免密码登陆。
4. 安装hadoop
我这里安装使用的是普通用户(非root安装),下载的版本是hadoop-2.6.0.tar.gz。
4.1 修改配置文件
(1). 上传hadoop-2.6.0.tar.gz到/opt/hadoop目录下;
(2). 解压tar -zxvf hadoop-2.6.0.tar.gz;
(3). 修改配置文件:core-site.xml,hdfs-site.xml,yarn-site.xml,mapred-site.xml,配置文件在/opt/hadoop/hadoop-2.6.0/etc/hadoop目录下;
修改core-site.xml,内容如下:
<configuration>
<!-- hdfs连接地址,集群模式(高可用) -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster</value>
</property>
<!-- namenode,datanode数据存放目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/hadoop-2.6.0/tmp</value>
</property>
<!-- zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>node1:2181,node2:2181,node3:2181</value>
</property>
</configuration>
修改hdfs-site.xml,内容如下:
<configuration>
<property>
<name>dfs.nameservices</name>
<value>cluster</value>
</property>
<property>
<name>dfs.ha.namenodes.cluster</name>
<value>nn01,nn02</value>
</property>
<!-- nn01的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.cluster.nn01</name>
<value>node1:9000</value>
</property>
<!-- nn01的http通信地址 -->
<property>
<name>dfs.namenode.http-address.cluster.nn01</name>
<value>node1:50070</value>
</property>
<!-- nn02的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.cluster.nn02</name>
<value>node2:9000</value>
</property>
<!-- nn02的http通信地址 -->
<property>
<name>dfs.namenode.http-address.cluster.nn02</name>
<value>node2:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1:8485;node2:8485;node3:8485/cluster</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/hadoop/hadoop-2.6.0/journaldata</value>
</property>
<!-- 开启NameNode故障时自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.cluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制,需要ssh免登陆,默认端口22 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!--<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence(hadoop:22022)</value>
</property>-->
<!-- 如果使用ssh进行故障切换,ssh通信所需要的密钥存储位置。注意:密钥默认保存在当前用户家目录的.ssh目录下,请根据实际情况修改 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/wxyuan/.ssh/id_rsa</value>
</property>
<!-- connect-timeout超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
修改yarn-site.xml,内容如下:
<configuration>
<!-- 启用HA高可用性 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定resourcemanager的名字 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 配置2个resourcemanager -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node2</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node1:2181,node2:2181,node3:2181</value>
</property>
<!-- 指定nodemanager启动时加载server的方式为shuffle server -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
修改mapred-site.xml(该文件不存在,需要手动创建),cp mapred-site.xml.template mapred-site.xml,内容如下:
<configuration>
<!-- 采用yarn作为mapreduce的资源调度框架 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(4) 修改slaves文件vim slaves,内容如下:
node1
node2
node3
(5) 修改hadoop-env.sh文件,指定jdk的地址
# The java implementation to use.
export JAVA_HOME=/opt/java/jdk1.7.0_79
(6) 配置用户的环境变量,vim ~/.bash_profile,增加如下内容
# hadoop environment variables
export HADOOP_HOME=/opt/hadoop/hadoop-2.6.0
export PATH=$HADOOP_HOME/bin:$PATH
4.2 拷贝复制到其它机器
scp -r /opt/hadoop/hadoop-2.6.0 wxyuan@node2:/opt/hadoop
scp -r /opt/hadoop/hadoop-2.6.0 wxyuan@node3:/opt/hadoop
4.3 启动hadoop
启动hadoop前,需要执行几步格式化操作:
(1) 启动journalnode,三台机器都要这一步操作(仅第一次启动hadoop时,需要这一步操作,之后不再需要手动启动journalnode)
cd /opt/hadoop/hadoop-2.6.0/sbin
sh hadoop-daemon.sh start journalnode
(2) 在node1上执行格式化操作,格式化namenode和zkfc
hdfs namenode -format
hdfs zkfc -formatZK
(3) namenode主从信息同步:复制node1上的/opt/hadoop/hadoop-2.6.0/tmp目录到node2的/opt/hadoop/hadoop-2.6.0目录下,
scp -r /opt/hadoop/hadoop-2.6.0/tmp wxyuan@node2:/opt/hadoop/hadoop-2.6.0
上述步骤完成后,接下来我们就可以启动hadoop了,在node1机器上执行下面的命令,
# 启动hdfs
cd /opt/hadoop/hadoop-2.6.0/sbin
sh start-dfs.sh
# 启动yarn
sh start-yarn.sh
在node2机器上启动ResourceManager(备用主节点的ResourceManager需要手动启动)
cd /opt/hadoop/hadoop-2.6.0/sbin
sh yarn-daemon.sh start resourcemanager
在每台机器上,使用jps命令可查看启动的进程,这里以我的机器为例,查看相关进程
node1机器
[wxyuan@node1 sbin]$ jps
13245 NameNode
11922 DataNode
12228 DFSZKFailoverController
11654 QuorumPeerMain
12328 ResourceManager
12423 NodeManager
11439 JournalNode
node2机器
[wxyuan@node2 ~]$ jps
9025 NodeManager
8546 JournalNode
9183 ResourceManager
8472 QuorumPeerMain
8945 DFSZKFailoverController
8717 NameNode
8782 DataNode
node3机器
[wxyuan@node3 ~]$ jps
8464 QuorumPeerMain
8655 DataNode
8534 JournalNode
8789 NodeManager
4.4 web界面查看hadoop信息
(1) 浏览器访问 http://node1:50070
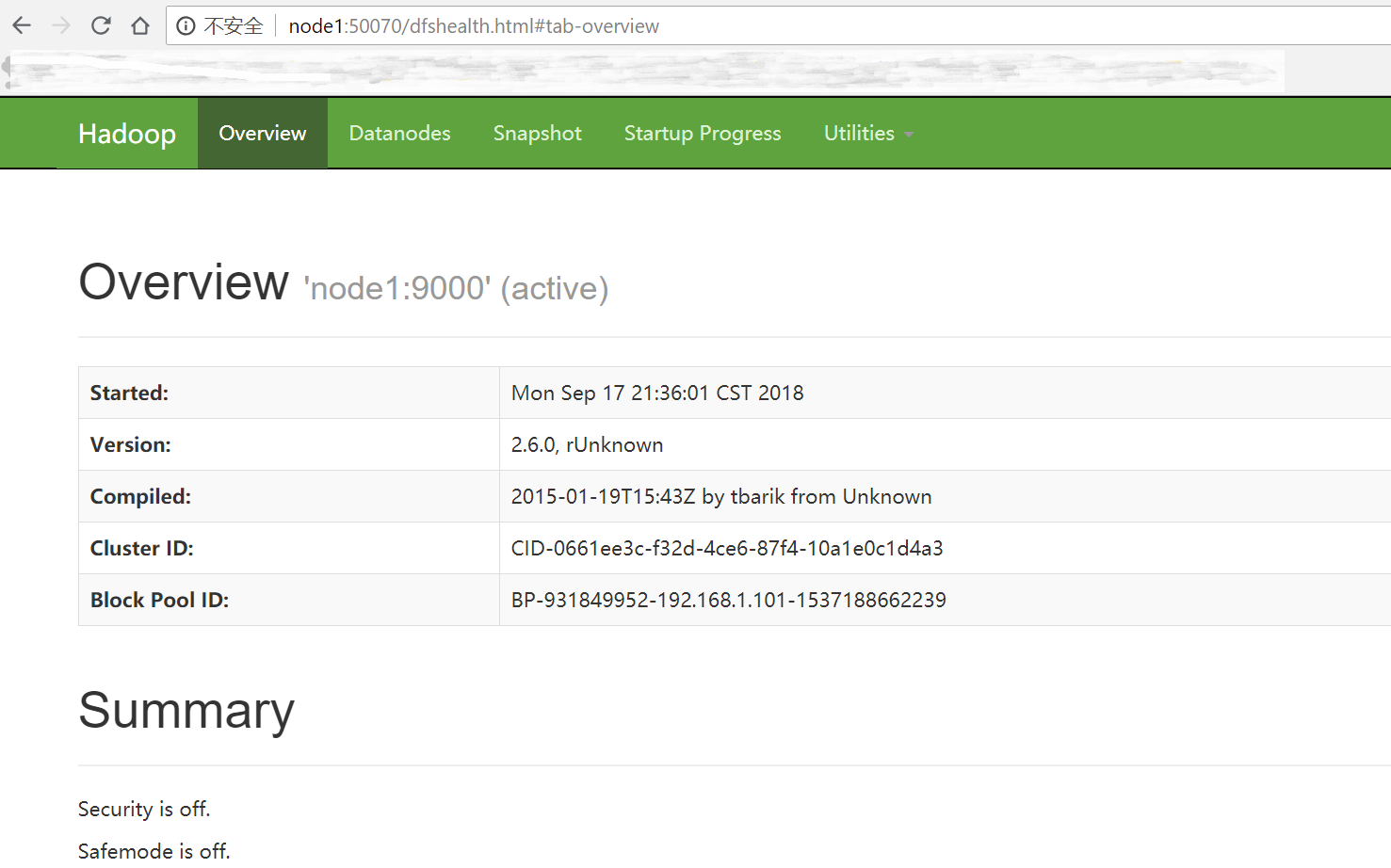
可以看到,当前节点node1处于active状态。
浏览器访问 http://node2:50070
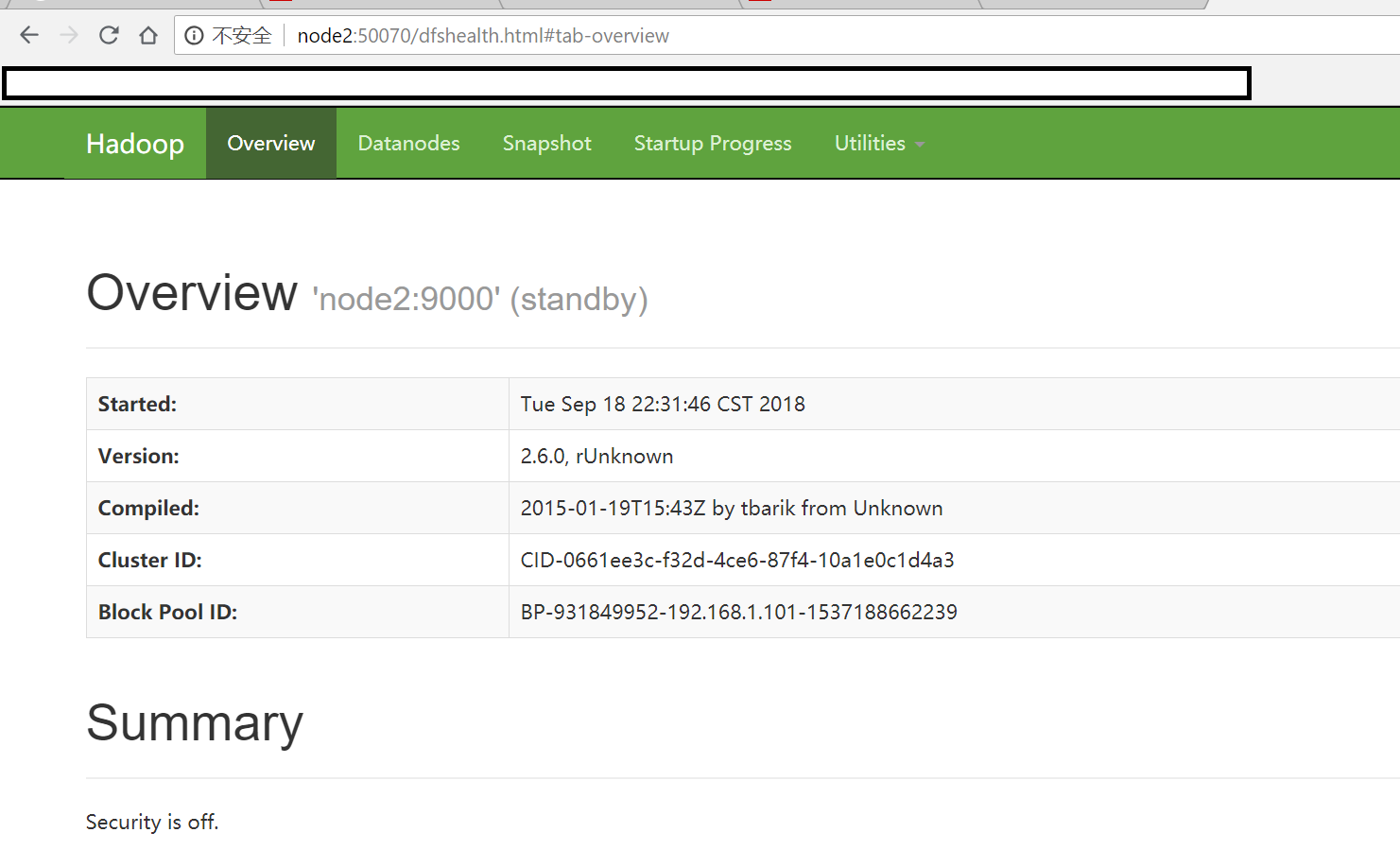
可以看到,当前节点node2处于standby状态。
(2) 查看每个datanode的信息,http://node1:50075、http://node2:50075、http://node3:50075
(3) 查看yarn的web控制台,浏览器访问 http://node1:8088/cluster
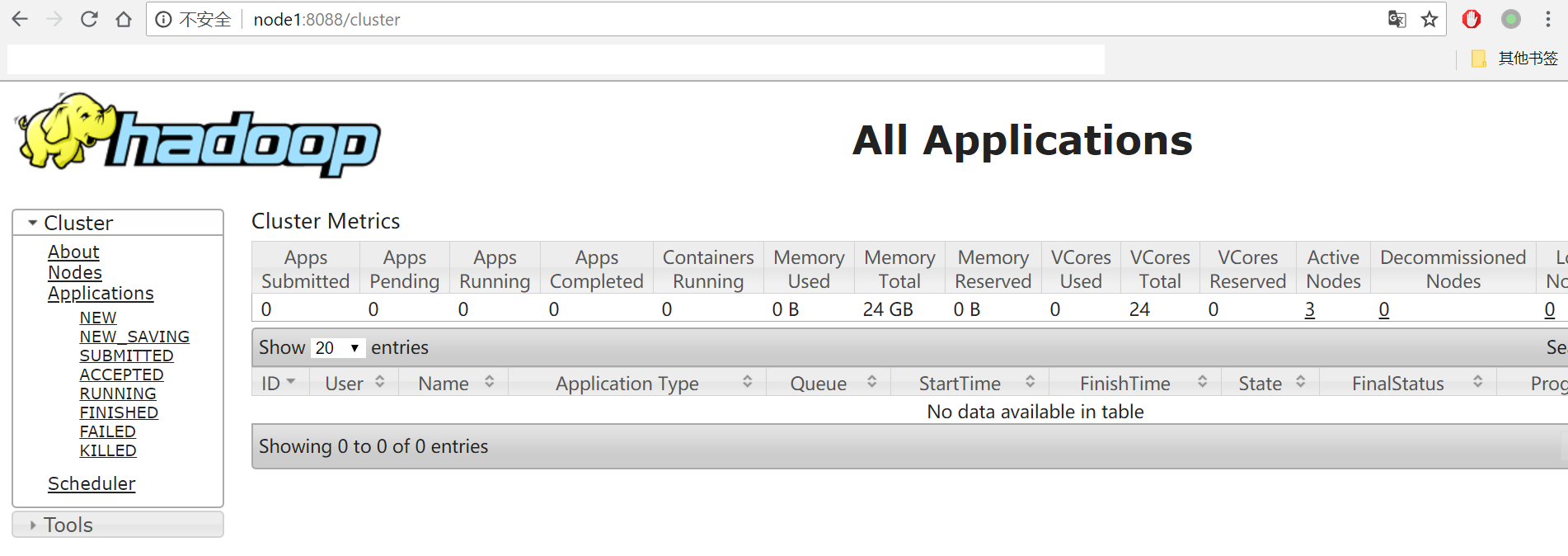
4.5 测试高可用
(1) 在node1节点上执行jps命令,查看namenode进程的pid,使用kill命令杀死该进程,此时浏览器访问 http://node2:50070,可以看到状态已经变成active。
(2) 重新启动node1的namenode,sh start-dfs.sh,浏览器访问 http://node1:50070,可以看到此时状态已经变成standby。
注意:hadoop进程日志位于/opt/hadoop/hadoop-2.6.0/logs目录下。
5. 安装hbase
这里我下载的版本是hbase-1.1.3-bin.tar.gz
5.1 修改配置文件
(1). 上传hadoop-2.6.0.tar.gz到/opt/hbase目录下;
(2). 解压tar -zxvf hbase-1.1.3-bin.tar.gz;
(3). 修改配置文件:hbase-env.sh,hbase-site.xml,配置文件在/opt/hbase/hbase-1.1.3/conf目录下;
对于hbase-env.sh,需要修改的内容有三处:
//指定jdk目录
# The java implementation to use. Java 1.7+ required.
export JAVA_HOME=/opt/java/jdk1.7.0_79
//指定pid文件目录
# The directory where pid files are stored. /tmp by default.
export HBASE_PID_DIR=/opt/hbase/hbase-1.1.3/pids
//禁用HBase自带的Zookeeper,因为我们是使用独立的Zookeeper
# Tell HBase whether it should manage it's own instance of Zookeeper or not.
export HBASE_MANAGES_ZK=false
修改hbase-site.xml,内容如下:
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://cluster/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>node1:2181,node2:2181,node3:2181</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/opt/hbase/hbase-1.1.3/tmp/hbase</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/hbase/hbase-1.1.3/tmp/data</value>
</property>
<property>
<name>hbase.regionserver.restart.on.zk.expire</name>
<value>true</value>
</property>
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
</property>
</configuration>
(4) 拷贝/opt/hadoop/hadoop-2.6.0/etc/hadoop目录下的core-site.xml和hdfs-site.xml文件到/opt/hbase/hbase-1.1.3/conf下,如果缺少这两个文件,启动hbase时会出现未知主机的异常,导致进程启动失败
(5) 修改regionservers文件
node1
node2
node3
(6) 新增backup-masters文件vim /opt/hbase/hbase-1.1.3/conf/backup-master,内容如下:
node2
(7) 配置用户的环境变量,vim ~/.bash_profile,增加如下内容:
# hbase environment variables
export HBASE_HOME=/opt/hbase/hbase-1.1.3
export PATH=$HBASE_HOME/bin:$PATH
5.2 拷贝复制到其它机器
scp -r /opt/hbase/hbase-1.1.3 wxyuan@node2:/opt/hbase
scp -r /opt/hbase/hbase-1.1.3 wxyuan@node3:/opt/hbase
5.3 启动hbase进程
cd /opt/hbase/hbase-1.1.3/bin
sh start-hbase.sh
使用jsp命令可查看hbase相关进程:HMaster、HRegionServer
5.4 登陆web界面查看hbase信息
(1) 浏览器访问http://node1:60010,可以看到node1是master
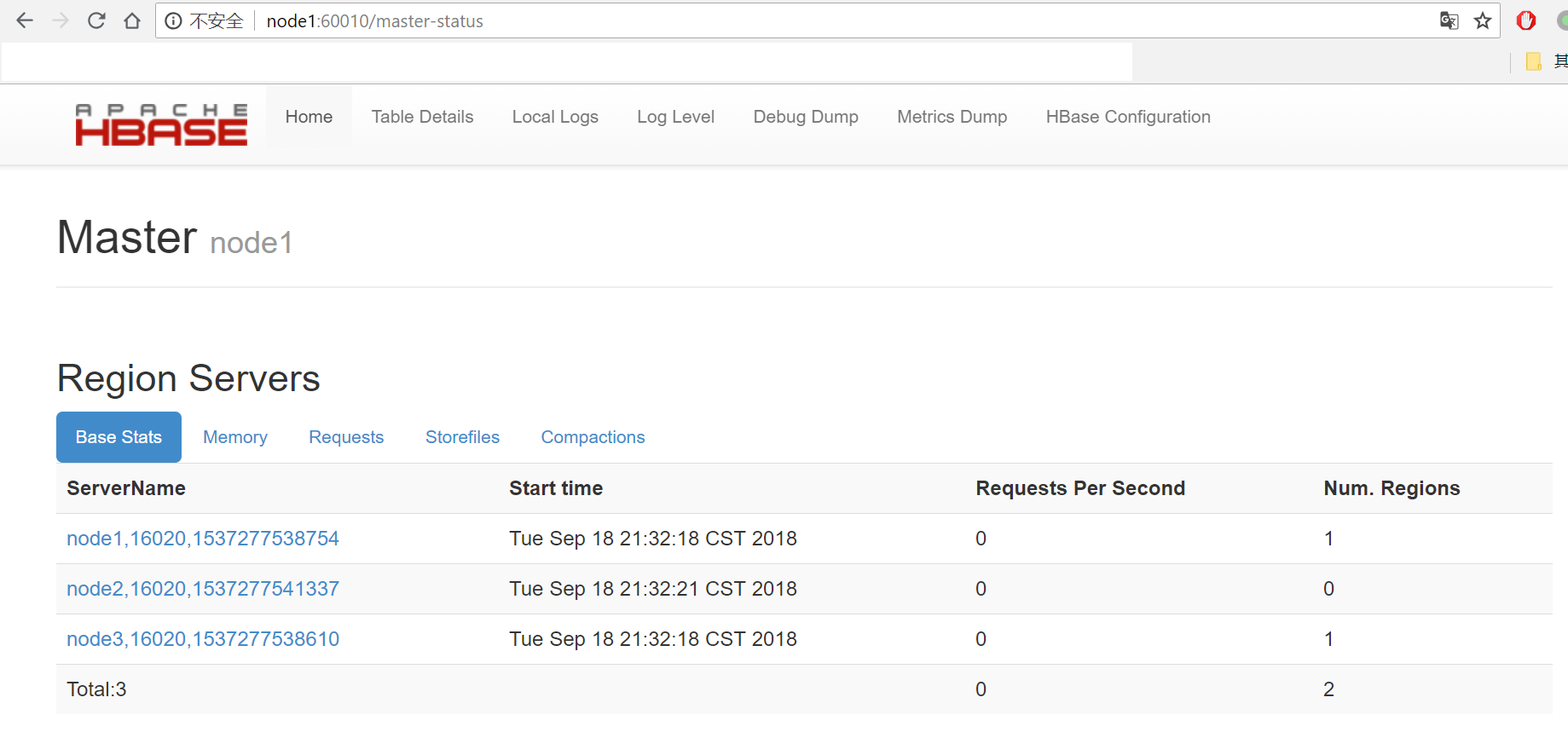
(2) 浏览器访问http://node2:60010
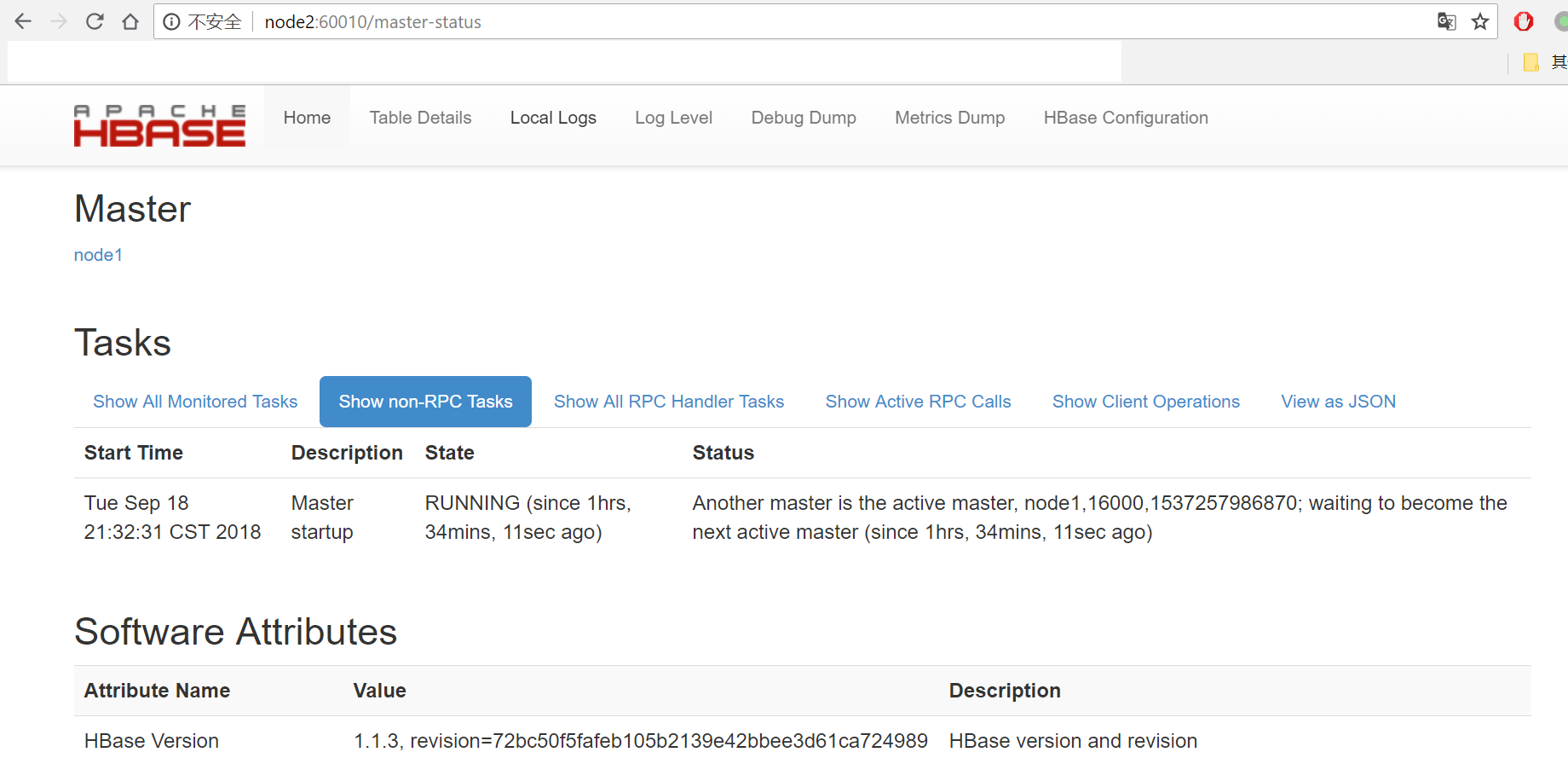
5.5 高可用测试
(1) 在node1节点上执行jps命令,查看HMaster进程的pid,使用kill命令杀死该进程,此时浏览器访问 http://node2:60010,可以看到node2变成了master。
(2) 重新启动node1的HMaster,sh start-hbase.sh,http://node1:60010
注意:hbase进程日志位于/opt/hbase/hbase-1.1.3/logs目录下。
关于hbase基本的shell命令,可参考HBase shell基本命令介绍
hadoop和hbase高可用模式部署的更多相关文章
- CentOS6下OpenLDAP+PhpLdapAdmin基本安装及主从/主主高可用模式部署记录
下面测试的部署机ip地址为:192.168.10.2051)yum安装OpenLDAP [root@openldap-server ~]# yum install openldap openldap- ...
- MongoDB高可用模式部署
首先准备机器,我这里是在公司云平台创建了三台DB server,ip分别是10.199.144.84,10.199.144.89,10.199.144.90. 分别安装mongodb最新稳定版本: w ...
- hbase高可用集群部署(cdh)
一.概要 本文记录hbase高可用集群部署过程,在部署hbase之前需要事先部署好hadoop集群,因为hbase的数据需要存放在hdfs上,hadoop集群的部署后续会有一篇文章记录,本文假设had ...
- 大数据学习笔记——Hbase高可用+完全分布式完整部署教程
Hbase高可用+完全分布式完整部署教程 本篇博客承接上一篇sqoop的部署教程,将会详细介绍完全分布式并且是高可用模式下的Hbase的部署流程,废话不多说,我们直接开始! 1. 安装准备 部署Hba ...
- Haproxy+Keepalived高可用环境部署梳理(主主和主从模式)
Nginx.LVS.HAProxy 是目前使用最广泛的三种负载均衡软件,本人都在多个项目中实施过,通常会结合Keepalive做健康检查,实现故障转移的高可用功能. 1)在四层(tcp)实现负载均衡的 ...
- LVS+Keepalived 高可用环境部署记录(主主和主从模式)
之前的文章介绍了LVS负载均衡-基础知识梳理, 下面记录下LVS+Keepalived高可用环境部署梳理(主主和主从模式)的操作流程: 一.LVS+Keepalived主从热备的高可用环境部署 1)环 ...
- HBase高可用原理与实践
前言 前段时间有套线上HBase出了点小问题,导致该套HBase集群服务停止了2个小时,从而造成使用该套HBase作为数据存储的应用也出现了服务异常.在排查问题之余,我们不禁也在思考,以后再出现类似的 ...
- 一脸懵逼学习Hadoop分布式集群HA模式部署(七台机器跑集群)
1)集群规划:主机名 IP 安装的软件 运行的进程master 192.168.199.130 jdk.hadoop ...
- openstack pike 集群高可用 安装 部署 目录汇总
# openstack pike 集群高可用 安装部署#安装环境 centos 7 史上最详细的openstack pike版 部署文档欢迎经验分享,欢迎笔记分享欢迎留言,或加QQ群663105353 ...
随机推荐
- SQLserver 查询某个表的字段及字段属性
SELECT C.name as [字段名],T.name as [字段类型] ,convert(bit,C.IsNullable) as [可否为空] ,convert(bit,case when ...
- java反序列化——XMLDecoder反序列化漏洞
本文首发于“合天智汇”公众号 作者:Fortheone 前言 最近学习java反序列化学到了weblogic部分,weblogic之前的两个反序列化漏洞不涉及T3协议之类的,只是涉及到了XMLDeco ...
- 虚拟化技术之kvm镜像模板制作工具virt-sysprep
virt-sysprep这个工具来自libguest-tools这个工具包,它能够把kvm虚拟机对应的磁盘文件做成一个模板,后续我们启动虚拟机就可以基于这个镜像模板启动:什么是镜像模板呢?所谓模板就是 ...
- SpringBoot项目 使用Jenkins进行自动化部署 gitlab打tag 生产测试环境使用 含配置中心
脚本 node('master') { def mvnHome = tool 'maven11-free' def gitUrl = "http://gitlab.wdcloud.cc:10 ...
- go语言之接口
一:接口的基本概念 1 接口声明 接口字面量,接口命名类型,接口声明使用interface关键字. 1)接口字面量类型声明语法如下: interface{ methodSignature1 metho ...
- AQI分析
A Q I 分 析 1.背景信息 AOI( Air Quality Index),指空气质量指数,用来衡量空气清洁或污染的程度.值越小,表示空气质量越好.近年来,因为环境问题,空气质量也越来越受到人 ...
- Centos7安装Oracle12c教程
12c数据库 创建oracle的系统用户和用户组 [root@localhost /]# groupadd oinstall [root@localhost /]# groupadd dba [roo ...
- Pytest-allure 生成美观好看的测试报告
在我们使用pytest-allure生成测试报告时,需要分为以下几步来执行 1.pytest TestCal.py --alluredir=/tmp/my_allure_results[这一步,是设置 ...
- spring集成shiro,事务失效问题 not eligible for auto-proxying
BeanPostProcessor bean实例化顺序有关,@Configuration会最先实例化,也就是在spring启动完成之前. 导致Configuration中使用的注入,没能在spring ...
- 使用代码给Unity中的动画片段绑定回调函数
在制作动作游戏的时候,需要播放许多动画,同时还有个需求,那就是动画播放到一定时间时,给一个回调函数,好做对应的状态变更, 我查了一下,发现如果使用的是unity自带的动画系统,要做到这样的话,需要这样 ...