《Java从入门到失业》第三章:基础语法及基本程序结构(四):基本数据类型(字符编码和char型)
3.6.4字符编码
咦?怎么好像有东西乱入了?不是讲基本数据类型么?哈哈,因为还剩下最后一个char型了,因为char型会牵涉到Unicode编码相关,因此我决定先科普一下字符集编码。
我儿子现在上小学,他们从1年级就开始学英语,为啥啊?因为英语是全球通用语言啊,我就是英语没学好,现在查资料看到英文版的就头疼。好像有点扯远了,言归正传,我们人和人之间沟通,需要通过语言,即我们把要表达的意思通过语言文字保存起来,通过阅读语言文字就能知道其含义。计算机只认识0和1组成的二进制串,那么我们和计算机沟通,就需要解决3个问题:
- 划分出人类的文字、符号的集合,简称字符集
- 把字符集中每一个字符,都定义一个唯一的二进制编码与之对应
- 给定一个二进制串,通过一定规则,解释出人类的文字
我个人把这3个问题称之为字符编码3要素:“字符集”、“编码”和“解码”。用一张示意图表示:
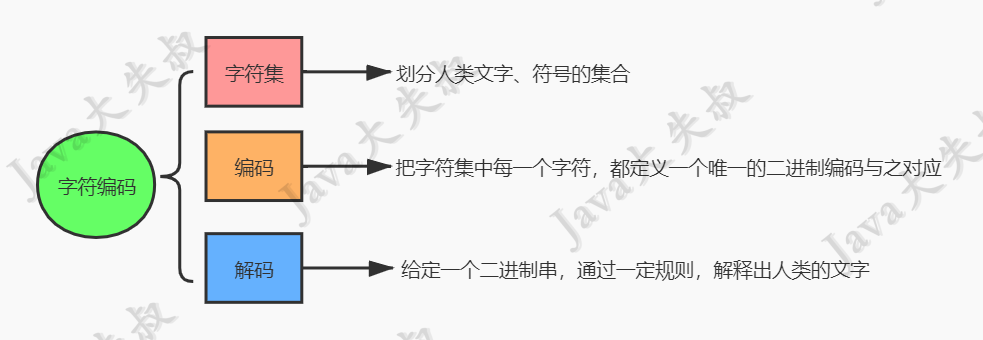
能够解决这3个问题的规则,就是字符编码。字符编码随着计算机的发展,经历了一个漫长的过程,下面尽量用简洁的语言讲明字符编码的简要发展过程及主要的一些字符编码方案。
3.6.4.1ASCII、ISO8859-1
在计算机早期,使用者只使用英文,英文字母只有26个,再加上数字、标点符号和一些其他字符也不超过128个,因此用7位的二进制就可以表示(7位二进制可以表示27=128个字符)。但是因为计算机都是以字节为单位,因此规定占用0-127一共128个8位二进制码来表示英文字母、数字、标点符号和一些其他字符。这种编码方式叫做ASCII编码(American Standard Code for Information Interchange)。例如大写字母A的ASCII编码是0b01000001,十进制是65。下表列出小部分ACSII编码:
|
二进制 |
十六进制 |
十进制 |
符号 |
说明 |
|
0000 0000 |
00 |
0 |
空字符(Null),不可见字符 |
|
|
0001 1111 |
1F |
31 |
单元分隔符,不可见字符 |
|
|
0010 0000 |
20 |
32 |
空格 |
空格 |
|
0010 0001 |
21 |
33 |
! |
|
|
0011 0000 |
30 |
48 |
0 |
数字0 |
|
0011 0001 |
31 |
49 |
1 |
数字1 |
|
0100 0001 |
41 |
65 |
A |
大写字母A |
|
0110 0001 |
61 |
97 |
a |
小写字母a |
|
0111 1111 |
7F |
127 |
删除,不可见字符 |
ASCII码的字符和二进制码是一一对应的,因此解码规则无需多言。
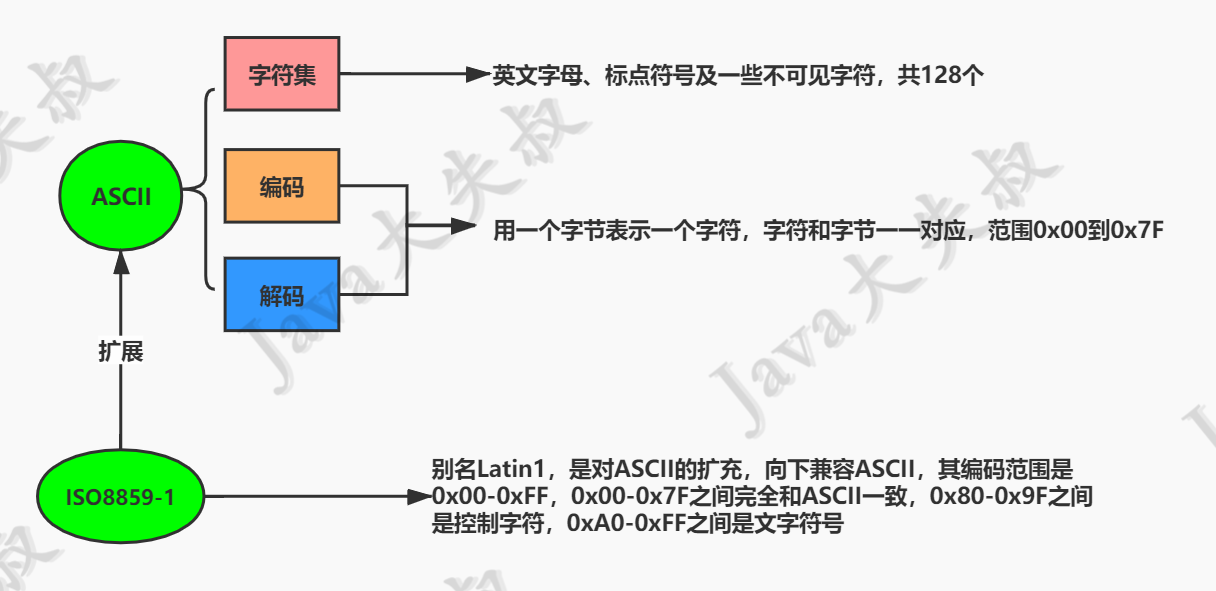
ISO-8859-1(Latin1)编码是对ASCII的扩充,向下兼容ASCII,其编码范围是0x00-0xFF,0x00-0x7F之间完全和ASCII一致,0x80-0x9F之间是控制字符,0xA0-0xFF之间是文字符号。因为ISO-8859-1编码范围使用了单字节内的所有空间,在支持ISO-8859-1的系统中传输和存储其他任何编码的字节流都不会被抛弃。换言之,把其他任何编码的字节流当作ISO-8859-1编码看待都没有问题。
示意图:
3.6.4.2GB2312、GBK、GB18030
随着计算机普及,问题马上就来了,要表示一些非英文字母怎么办呢?例如中文。为了满足这种需要,中国国家标准总局发布了一系列的汉字字符集国家标准编码,统称为GB码,或国标码。其中最有影响的是于1980年发布的《信息交换用汉字编码字符集 基本集》,标准号为GB 2312-1980,这就是GB2312编码。 GB 2312是一个简体中文字符集,由6763个常用汉字和682个全角的非汉字字符组成。GB2312采用了二维矩阵编码法对所有字符进行编码。首先构造一个94行94列的方阵,对每一行称为一个“区”,每一列称为一个“位”,然后将所有字符依照下表的规律填写到方阵中。
|
分区 |
说明 |
|
第01区 |
中文标点、数学符号以及一些特殊字符 |
|
第02区 |
各种各样的数学序号 |
|
第03区 |
全角西文字符 |
|
第04区 |
日文平假名 |
|
第05区 |
日文片假名 |
|
第06区 |
希腊字母表 |
|
第07区 |
俄文字母表 |
|
第08区 |
中文拼音字母表 |
|
第09区 |
制表符号 |
|
第10-15区 |
无字符 |
|
第16-55区 |
一级汉字(以拼音字母排序) |
|
第56-87区 |
二级汉字(以部首笔画排序) |
|
第88-94区 |
无字符 |
这样所有的字符在方阵中都有一个唯一的位置,这个位置可以用区号、位号合成表示,称为字符的区位码。如第一个汉字“啊”出现在第16区的第1位上,其区位码为16 01。这样所有的字符都可通过其区位码转换为数字编码信息。实际发布的国标码是通过把区位码都加上32,例如汉字“啊”的国标码是48 33(16+32,01+32)。一般用十六进制表示0x3021。至于为什么不直接发布区位码,我也没查到相关资料,个人猜测是为了避开ASCII码的控制字符。ASCII码中0-31和127都是不可见的控制字符,区码和位码+32后,范围就变成32-126,正好避开所有的控制字符。
但是这里还有个问题,因为国标码的高、低字节取值范围都是在32-126之间,例如汉字‘徕’在GB2312中的国标码为97 98,而两个英文字母‘ab’的存储码也是97,98。这种冲突将导致在解释编码时到底表示的是一个汉字还是两个英文字符将无法判断。为避免ASCII码发生冲突,GB2312字符在进行存储时不能按照国标码存储。我们可以发现国标码的二进制最高位都是0,如果我们把每个字节最高位都变为1来存储。这样在解释编码时,如果一个字节最高位为0,则表示西文字符,否则表示GB2312中字符的一个字节。字节最高位变为1,只需要将国标码每个字节都加上128即可,这个码叫机内码。例如汉字‘徕’的区位码为6566(0x4142),其机内码为0xE1E2,转换过程为:
|
区位码 |
国标码 |
高位转换 |
低位转换 |
机内码 |
|
0x4142 |
0x6162 |
0x61+0x80=E1 |
0x42+0x80=E2 |
0xE1E2 |
其实可以相当于区位码分别加上160,得到机内码。
GB2312基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75% 的使用频率,但是对于人名、古汉语等方面出现的罕用字,GB 2312 不能处理,这导致了后来 GBK 及 GB 18030 汉字字符集的相继出现。
GBK全称《汉字内码扩展规范》(GBK即“国标”、“扩展”汉语拼音的第一个字母,英文名称:Chinese Internal Code Specification) ,中华人民共和国全国信息技术标准化技术委员会1995年12月1日制订,国家技术监督局标准化司、电子工业部科技与质量监督司1995年12月15日联合以技监标函1995 229号文件的形式,将它确定为技术规范指导性文件。这一版的GBK规范为1.0版。GBK 向下与 GB 2312 编码兼容,是在GB2312-80标准基础上的内码扩展规范,使用了双字节编码方案,其编码范围从8140至FEFE(剔除xx7F),共23940个码位,共收录了21003个汉字,完全兼容GB2312-80标准,支持国际标准ISO/IEC10646-1和国家标准GB13000-1中的全部中日韩汉字,并包含了BIG5编码中的所有汉字。GBK编码方案于1995年10月制定, 1995年12月正式发布。GBK其实是一个过渡性的规范,现在已经完成其使命了。但是仍然被广泛使用。
GB 18030,全称《信息技术 中文编码字符集》,是中华人民共和国国家标准所规定的变长多字节字符集。其对GB 2312-1980完全向后兼容,与GBK基本向后兼容,并支持Unicode(GB 13000)的所有码位。GB 18030共收录汉字70,244个。
GB18030一共有2个版本:GB18030-2000和GB18030-2005。2000年发布的GB18030-2000,全名是《信息技术 汉字编码字符集 基本集的扩充》。GB18030-2000仅规定了常用非汉字符号和27533个汉字(包括部首、部件等)的编码。GB18030-2000是全文强制性标准,市场上销售的产品必须符合。2005年发布的GB18030-2005在GB18030-2000的基础上增加了42711个汉字和多种我国少数民族文字的编码,增加的这些内容是推荐性的。
示意图如下:

3.6.4.3ANSI编码
上面我们搞明白了GB2312编码,它是为了解决中文简体字符编码而制定的一种编码标准。其他国家也相应的制定了他们的标准,例如繁体中文的BIG5,日文的JIS等。这些都是使用 2 个字节来代表一个字符,人们把他们统称为 ANSI 编码,又称为"MBCS(Muilti-Bytes Character Set,多字节字符集)"。在ANSi编码下,同一个编码值,在不同的编码体系里代表着不同的字。在简体中文系统下,ANSI 编码代表 GB2312 编码,在日文操作系统下,ANSI 编码代表 JIS 编码,在ANSI编码体系下,要想打开一个文本文件,不但要知道它的编码方式,还要安装有对应编码表,否则就可能无法读取或出现乱码。为什么电子邮件和网页都经常会出现乱码,就是因为信息的提供者可能是日文的ANSI编码体系,信息的读取者可能是中文的编码体系,他们对同一个二进制编码值进行显示,采用了不同的编码,导致乱码。这个问题促使了unicode码的诞生。如果有一种编码,将世界上所有的符号都纳入其中,无论是英文、日文、还是中文等,大家都使用这个编码表,就不会出现编码不匹配现象。每个符号对应一个唯一的编码,乱码问题就不存在了。这就是Unicode编码。
3.6.4.4Unicode字符
Unicode的发展也经历了一些过程,目前已经有13个版本了。这里就不再复述。我们只需要知道,Unicode确实做到了将全世界文字符号都统一编码,在表示一个Unicode的字符时,通常会用“U+”然后紧接着一组十六进制的数字来表示这一个字符。例如U+0041表示大写字母A。
目前Unicode的编码从U+0000到U+10FFFF,一共有1114112个码位(code point)。然后按照顺序分成17个平面(Plane),每个平面包含216=65536个码位。具体如下:
|
平面 |
范围 |
说明 |
|
Plane0 |
U+0000~U+FFFF |
基本多文种平面(Basic Multilingual Plane, BMP) |
|
Plane1 |
U+10000~U+1FFFF |
多文种补充平面(Supplementary Multilingual Plane, SMP) 包含古文字,专用文字,符号和特定领域用的标记。古文字诸如埃及象形文字,楔形文字等,现代音乐标记,Emoji表情等都属于这个平面的范畴 |
|
Plane2 |
U+20000~U+2FFFF |
表意文字补充平面(Supplementary Ideographic Plane, SIP) 主要对CJK的字符进行补充 |
|
Plane3 |
U+30000~U+3FFFF |
表意文字第三平面(Tertiary Ideographic Plane, TIP),暂未使用 |
|
Plane4~Plane13 |
U+40000~U+DFFFF |
未使用(unassigned) |
|
Plane14 |
U+E0000~U+EFFFF |
特别用途补充平面(Supplementary Special-purpose Plane, SSP)240个(VS17~VS256)补充变量选择器(Variation Selectors Supplement)就在这个平面定义 |
|
Plane15~Plane16 |
U+F0000~U+10FFFF |
保留作为私人使用区(Private Use Area, PUA) |
平面0包含了几乎现代语言的常用字符和大量符号。其中U+D800~U+DFFF这2048个码位保留作为代理,具体在UTF-16中会阐述。
需要注意的是,Unicode 只是一个字符集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。比如,U+0041表示大写字母A,至少需要1个字节存储。U+4E2D表示汉字‘中’,至少需要2个字节存储。具体一个字符是用几个字节存储,如何存储,Unicode并没有规定。 这就导致了一个问题,计算机在解释1个字节的时候,怎么知道它是表示一个ASCII符号,还是一个其他符号的第一个字节呢?也就是说,我们得有一个存储实现来存储Unicode编码。目前有UTF-8、UTF-16、UTF-32这几种方式。示意图如下: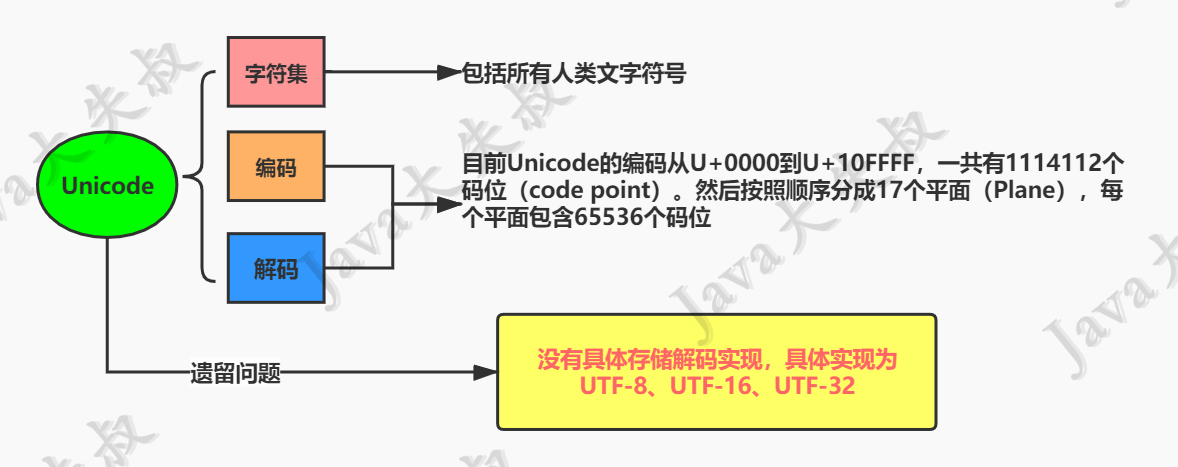
3.6.4.5UTF-8
UTF-8就是Unicode的一种实现,它把Unicode编码划分为不同的范围,采用一种变长的编码方式,对于不同范围采用不同的字节数来编码。我们可以用如下表来表示:
|
Unicode编码 |
UTF-8存储码模板 |
|
U+0000- U+007F |
0xxxxxxx |
|
U+0080- U+07FF |
110xxxxx 10xxxxxx |
|
U+0800- U+FFFF |
1110xxxx 10xxxxxx 10xxxxxx |
|
U+10000- U+10FFFF |
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
我们可以看到,Unicode编码一共被划分成4个范围,分别用1-4个字节来存储不同范围的编码。我们对着这个表,搞清楚2个事情,一是给定Unicode编码,如何确定UTF-8编码。二是给定一个UTF-8字节流,如何确定Unicode编码:
- 对于一个给定的Unicode编码,我们可以确定它的范围,然后确定UTF-8编码的模板。按照表中把固定的1和0填上,剩下的xxx部分用Unicode编码补满即可。
例1:中文“汉”字的Unicode编码是0x6C49。0x6C49在0x0800-0xFFFF之间,使用3字节模板:1110xxxx 10xxxxxx 10xxxxxx。x的数量是16。将0x6C49写成16位二进制是:0110 1100 0100 1001, 用这个比特流依次代替模板中的x,得到:11100110 10110001 10001001,即E6 B1 89。
例2:Unicode编码0x20C30在0x010000-0x10FFFF之间,使用4字节模板:11110xxx 10xxxxxx 10xxxxxx 10xxxxxx。x的数量是21,。将0x20C30写成21位二进制数字:0 0010 0000 1100 0011 0000,用这个比特流依次代替模板中的x,得到:11110000 10100000 10110000 10110000,即F0 A0 B0 B0。
- 对于一个给定UTF-8存储码,如何知道表示什么字符?其实很简单,对于给定的一个字节,如果第1位是0,则表示是单字节字符,如果第1位是1,则看连续有几个1,比如有4个1,就是4字节字符,再去掉模板中的固定1和0,剩下的拼接到一起,就是Unicode编码,就知道对应的字符了。
示意图如下:

3.6.4.6UTF-16
UTF-16是Unicode的另一种实现。我们也搞清楚2个事情,一是给定Unicode编码,如何确定UTF-16编码。二是给定一个UTF-16字节流,如何确定Unicode编码:
- 对于一个给定的Unicode编码U,如果是属于平面0,即U+0000到U+FFFF,把对应的Unicode编码补足为16位,就是UTF-16编码。如果U≥U+10000,我们先计算U'=U-0x10000,U'的最大值就是0x10FFFF-0x10000=0xFFFFF。所以U'可以用20个二进制位表示。我们把U'的二进制补足位20位,假设是yyyy yyyy yyxx xxxx xxxx,U的UTF-16编码就是:110110yyyyyyyyyy 110111xxxxxxxxxx。也就是说非0平面的字符,需要用4个字节表示。
例如:Unicode编码0x20C30,减去0x10000后,得到0x10C30,写成二进制是:0001 0000 1100 0011 0000。用前10位依次替代模板中的y,用后10位依次替代模板中的x,就得到:1101100001000011 1101110000110000,即0xD843 0xDC30。
- 按照上述规则,对于非0平面的字符的UTF-16编码有4个字节,第一个16位的高6位是110110,第二个16位的高6位是110111。可见,第一个16位的取值范围(二进制)是11011000 00000000到11011011 11111111,即0xD800-0xDBFF。第二个16位的取值范围(二进制)是11011100 00000000到11011111 11111111,即0xDC00-0xDFFF。还记得平面0的2048个保留码位吗?正好就是0xD800-0xDFFF。这就好办了。
- 对于一个给定UTF-16字节流,2个字节2个字节读取,如果这2个字节不在0xD800-0xDFFF范围,则是平面0的字符。否则连续读取4个字节,把高位2个字节去掉前6位,把低位2个字节去掉前6位,然后拼接在一起,再加上0x10000,结果就是Unicode编码。
示意图如下:

3.6.4.7字符编码总结
首先看一个问题,在win10系统下,新建一个记事本,点击“文件”->“另存为”,弹出保存框,截图如下:
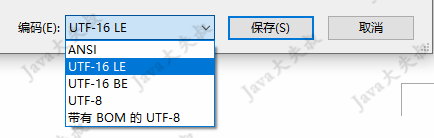
一共有5种编码,我们记事本输入文字“Java大失叔”,分别保存为这5种类型,然后用“winHex”软件打开,查看十六进制编码。下面分别列出十六进制编码及对应的说明:
|
编码 |
十六进制 |
说明 |
|
ANSI |
4A 61 76 61 B4 F3 CA A7 CA E5 |
在中文简体Win10下,代表GBK “Java”用4个单字节表示。汉字“大失叔”分别用2个字节表示 |
|
UTF-16 LE |
FF FE 4A 00 61 00 76 00 61 00 27 59 31 59 D4 53 |
UTF-16编码,其后缀LE 即 little-endian,小端的意思。就是将高位字节放在前面,文本开头有2个字节用来表明字节序列:FF FE。 无论字母汉字都是2个字节 |
|
UTF-16 BE |
FE FF 00 4A 00 61 00 76 00 61 59 27 59 31 53 D4 |
UTF-16编码,其后缀BE即 big-endian,大端的意思。就是将高位字节放在后面,文本开头有2个字节用来表明字节序列:FE FF 无论字母汉字都是2个字节 |
|
UTF-8 |
4A 61 76 61 E5 A4 A7 E5 A4 B1 E5 8F 94 |
UTF-8编码,“Java”用4个单字节表示。汉字“大失叔”分别用3个字节表示 |
|
带有BOM的UTF-8 |
EF BB BF 4A 61 76 61 E5 A4 A7 E5 A4 B1 E5 8F 94 |
BOM(Byte Order Mark),字节序列的意思。UTF-8编码本来无需BOM,但是可以用来表明编码方式。收到字节流带有EFBBBF,就知道是UTF-8。 “Java”用4个单字节表示。汉字“大失叔”分别用3个字节表示 文本开头多了EF BB BF 3个字节 |
最后用一张总结一下:
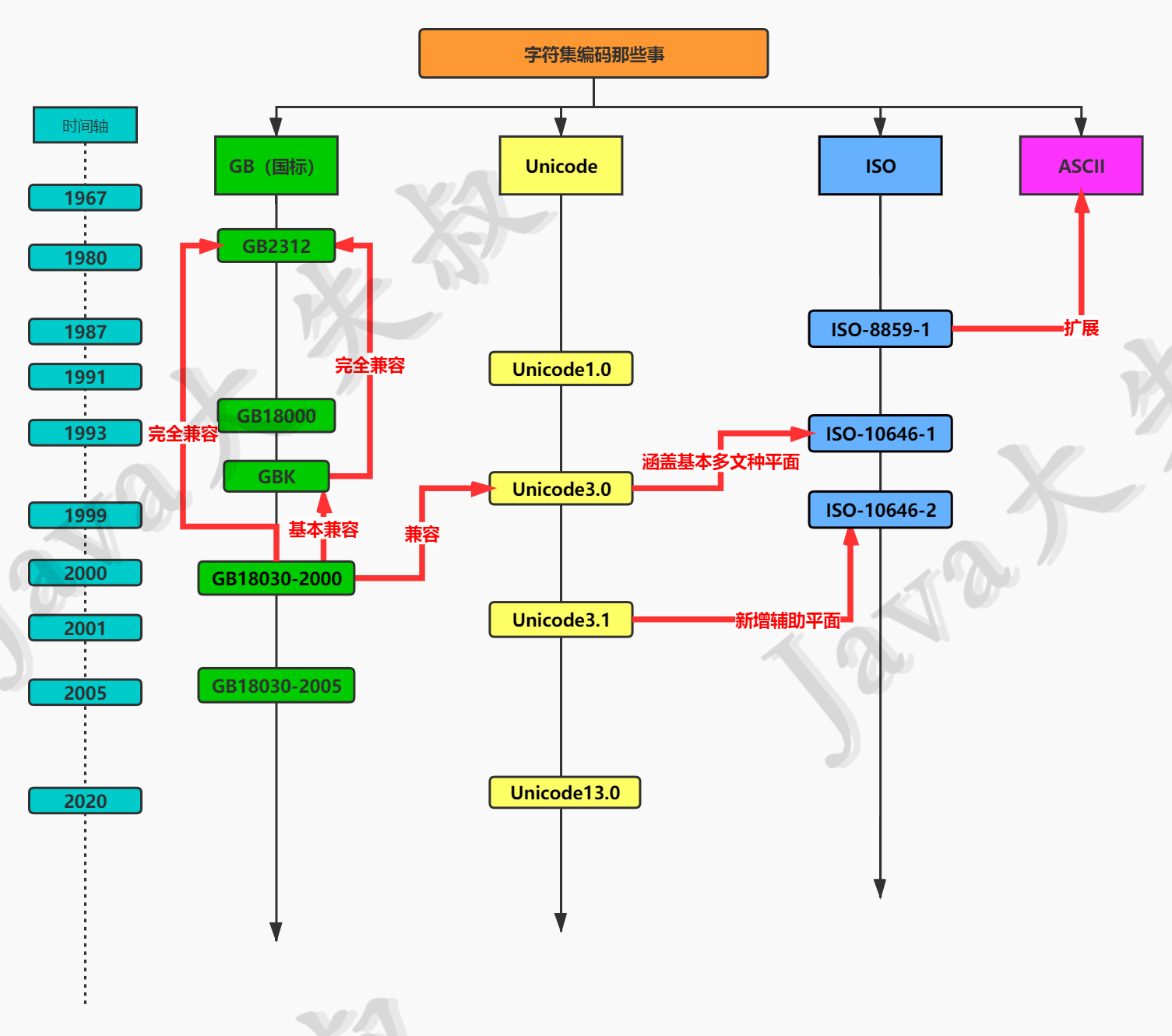
3.6.5char型
终于把字符编码搞定了,是不是有点头昏脑涨了?好吧,接下来来点轻松的。我们继续Java的最后一个基本数据类型char。还记得UTF-16吗?对于平面0的字符,采用的是2个字节来表示,我们把2个字节称为一个代码单元(code unit),char就是用来表示一个代码单元,也就是说,char不能表示所有的Unicode字符。
这里有个小插曲,Unicode是在1991年发布的1.0,当时都认为16位足以涵盖所有的字符了,因此Java定义一个2个字节的char类型来表示所有字符。但是好景不长,Unicode字符集随后爆炸增长,Java就面临一个问题了,是把char扩充为4个字节呢?还是重新定义一个新的类型?考虑到兼容性的问题,Java换成了UTF-16编码,char用来表示一个代码单元。
因此,在实际工作和实践中,尽量避免使用char类型,除非你对所要操作的内容非常熟悉。后面我们讲到String类的时候,会继续详细分析这一块内容。
虽然不建议使用char,但是我们还是得了解char的使用,因为你不用,不代表别人不用,我们不学会使用,将来就看不懂别人写的代码。
首先是赋值,我们把一个‘中’赋值给一个char,可以有3种方式:
char a = '中';// 直接用字符的符号赋值
char b = 20013;// 用0~65535的任意十进制数值赋值,当然二进制、十六进制也行
char c = '\u4e2d';// 用Unicode编码赋值
因为可以把一个数值赋值给char,因此char还可以直接参与运算:
// 中的编码十进制是20013,a的编码十进制是97
char a = '中' + 'a';// char类型相加,提升为int类型,输出对应的字符"于"
int b = '中' + 'a';// 结果是20110
char c = '中' + 97;// 输出结果是"于"
《Java从入门到失业》第三章:基础语法及基本程序结构(四):基本数据类型(字符编码和char型)的更多相关文章
- 《Java程序设计》第三章-基础语法
20145221<Java程序设计>第三章-基础语法 总结 教材学习内容总结 类型.变量与运算符 类型 Java可区分为基本类型(Primitive Type)和类类型(Class Typ ...
- 《Java从入门到失业》第二章:Java环境(一):Java SE安装
从这一章开始,终于我们可以开始正式进入Java世界了.前面我们提到过,Java分三个版本,我们这里只讨论Java SE. 2.1Java SE安装 所谓工欲善其事,必先利其器.第一步,我们当然是要下载 ...
- 《Java从入门到失业》第一章:计算机基础知识(三):程序语言简介
1.3程序语言简介 我们经常会听到一些名词:低级语言.高级语言.编译型.解释型.面向过程.面向对象等.这些到底是啥意思呢?在正式进入Java世界前,笔者也尝试简单的聊一聊这块东西. 1.3.1低级语言 ...
- 《Java从入门到失业》第二章:Java环境(三):Java命令行工具
2.3Java命令行工具 2.3.1编译运行 到了这里,是不是开始膨胀了,想写一段代码来秀一下?好吧,满足你!国际惯例,我们写一段HelloWorld.我们在某个目录下记事本,编写一段代码如下: 保存 ...
- 《Java从入门到失业》第一章:计算机基础知识(一):二进制和十六进制
0 前言 最近7年来的高强度工作和不规律的饮食作息,压得我有些喘不过气,身体也陆续报警.2018年下半年的一场病,让我意识到了这个问题的严重性,于是开始强制自己有规律饮食和作息,并辅以健身锻炼,不到2 ...
- 《Java从入门到失业》第二章:Java环境(四):IDE集成环境
2.4IDE集成环境 在掌握了编写.编译和运行Java程序的基本步骤以后,你肯定就在想,这太麻烦了,有没有更好的工具?当然有了,那就是IDE.IDE就是专业的集成开发环境(Integrated Dev ...
- 《Java从入门到失业》第二章:Java环境(二):JDK、JRE、JVM
2.2JDK.JRE.JVM 在JDK的安装目录中,我们发现有一个目录jre(其实如果是下一步下一步安装的,在和JDK安装目录同级目录下,还会有一个jre目录).初学Java的同学,有时候搞不清楚这3 ...
- 《Java从入门到失业》第一章:计算机基础知识(二):计算机组成及基本原理
1.2计算机组成及基本原理 1.2.1硬件组成 这里说的计算机主要指微型计算机,俗称电脑.一般我们见到的有台式机.笔记本等,另外智能手机.平板也算.有了一台计算机,我们就能做很多事情了,比如我在写这篇 ...
- Java 学习笔记 ------第三章 基础语法
本章学习目标: 认识类型与变量 学习运算符的基本使用 了解类型转换细节 运用基本流程语法 一.类型(基本类型) 所谓基本类型,就是在使用时,得考虑一下数据用多少内存长度存比较经济,利用程序语法告诉JV ...
随机推荐
- Day01_mongoDB入门
学于黑马和传智播客联合做的教学项目 感谢 黑马官网:http://www.itheima.com 传智播客官网:http://www.itcast.cn 微信搜索"艺术行者",关注 ...
- 两数相加(B站看视频总结)
''' 两数相加: 给出两个 非空 的链表用来表示两个非负的整数 各自的位数是按照逆序的方式存储的 每一个节点只能保存 一位数 示例: 输入:(2->4->3) + (5->6-&g ...
- CF R 635 div1 C Kaavi and Magic Spell 区间dp
LINK:Kaavi and Magic Spell 一打CF才知道自己原来这么菜 这题完全没想到. 可以发现 如果dp f[i][j]表示前i个字符匹配T的前j个字符的方案数 此时转移变得异常麻烦 ...
- Spring Cloud Data Flow用Shell来操作,方便建立CICD
1 前言 欢迎访问南瓜慢说 www.pkslow.com获取更多精彩文章! 之前我们用两篇文章讲解了Spring Cloud Data Flow,例子都是用UI操作的,但我们在Linux系统上经常是无 ...
- Java项目中经常遇到的一些异常情况
一. 1. java.lang.nullpointerexception 这个异常大家肯定都经常遇到,异常的解释是"程序遇上了空指针",简单地说就是调用了未经初始化的对象或者是不存 ...
- 密码学系列——常见的加密方式(c#代码实操)
前言 说起加密方式,其实密码学的角度ASCII编码其实本身就是一种加密解密. 由于其公开,现在用于数字与字符的转换. 查看ASCII表可以去官网查查. 转换代码如下: static void Main ...
- 利用这10个工具,你可以写出更好的Python代码
我每天都使用这些实用程序来使我的Python代码可显示. 它们是免费且易于使用的. 编写漂亮的Python比看起来难. 作为发布工作流程的一部分,我使用以下工具使代码可显示并消除可避免的错误. 很多人 ...
- 将vscode打造成强大的C/C++ IDE
一.安装 你可以直接从微软官网下载,如果你想要一个纯净的vscode(微软官方的有一项商标.一个插件库.一个 C# 调试器以及遥测),可以手动编译https://github.com/microsof ...
- Catalina 默认使用zsh了,你可习惯
zsh 成为默认 shell 淘汰掉我的旧MBP换新后,欢天喜地打开Terminal,感觉有点不对,提示符什么时候变成了 %. 查询了一些资料发现,原来在2019年WWDC期间,苹果推出了macOS ...
- java流程控制语句switch
switch 条件语句也是一种很常用的选择语句,它和if条件语句不同,它只能针对某个表达 式的值作出判断,从而决定程序执行哪一段代码. 格式: switch (表达式){ case 目标值1: 执行语 ...