K8S线上集群排查,实测排查Node节点NotReady异常状态
一,文章简述
大家好,本篇是个人的第 2 篇文章。是关于在之前项目中,k8s 线上集群中 Node 节点状态变成 NotReady 状态,导致整个 Node 节点中容器停止服务后的问题排查。
文章中所描述的是本人在项目中线上环境实际解决的,那除了如何解决该问题,更重要的是如何去排查这个问题的起因。
关于 Node 节点不可用的 NotReady 状态,当时也是花了挺久的时间去排查的。
二,Pod 状态
在分析 NotReady 状态之前,我们首先需要了解在 k8s 中 Pod 的状态都有哪些。并且每个状态都表示什么含义,不同状态是很直观的显示出当前 Pod 所处的创建信息。
为了避免大家对 Node 和 Pod 的概念混淆,先简单描述下两者之间的关系(引用一张 K8S 官方图)。
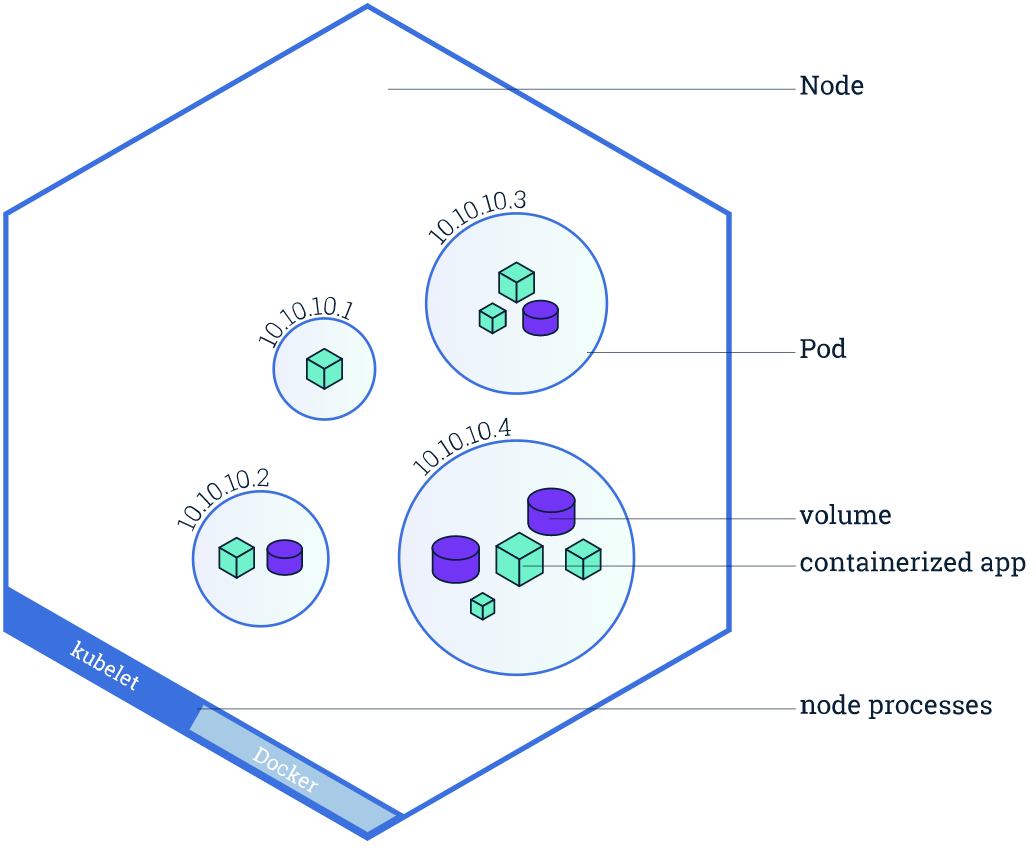
从图中很直观的显示出最外面就是 Node 节点,而一个 Node 节点中是可以运行多个 Pod 容器,再深入一层就是每个 Pod 容器可以运行多个实例 App 容器。
因此关于本篇文章所阐述的 Node 节点不可用,就会直接导致 Node 节点中所有的容器不可用。
毫无疑问,Node 节点是否健康,直接影响该节点下所有的实例容器的健康状态,直至影响整个 K8S 集群。
那么如何解决并排查 Node 节点的健康状态?不急,我们先来聊聊关于关于 Pod 的生命周期状态。
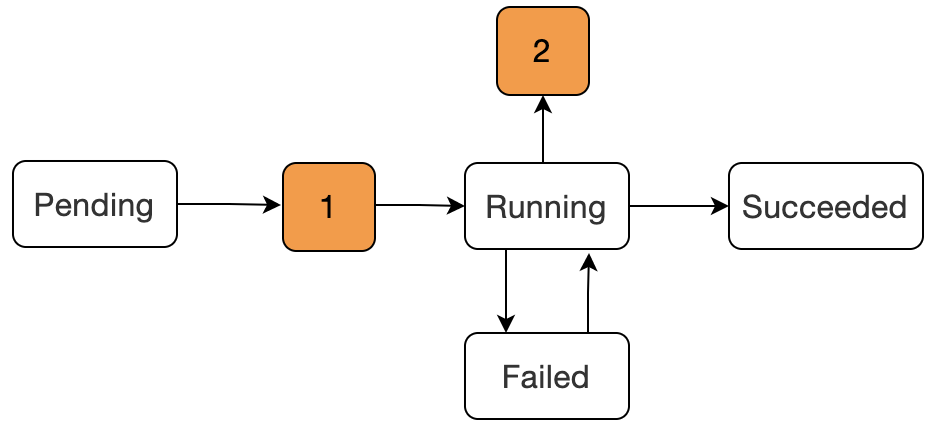
Pending:该阶段表示已经被 Kubernetes 所接受,但是容器还没有被创建,正在被 kube 进行资源调度。1:图中数字 1 是表示在被 kube 资源调度成功后,开始进行容器的创建,但是在这个阶段是会出现容器创建失败的现象Waiting或ContainerCreating:这两个原因就在于容器创建过程中镜像拉取失败,或者网络错误容器的状态就会发生转变。Running:该阶段表示容器已经正常运行。Failed:Pod 中的容器是以非 0 状态(非正常)状态退出的。2:阶段 2 可能出现的状态为CrashLoopBackOff,表示容器正常启动但是存在异常退出。Succeeded:Pod 容器成功终止,并且不会再在重启。
上面的状态只是 Pod 生命周期中比较常见的状态,还有一些状态没有列举出来。
这。。。状态有点多。休息 3 秒钟

不过话又说回来,Pod 的状态和 Node 状态是一回事吗?嗯。。。其实并不完全是一回事。
但是当容器服务不可用时,首先通过 Pod 的状态去排查是非常重要的。那么问题来了,如果 Node 节点服务不可用,Pod 还能访问吗?
答案是:不能。
因此排查Pod的健康状态的意义就在于,是什么原因会导致Node节点服务不可用,因此这是一项非常重要的排查指标。
三,业务回顾
由于本人的工作是和物联网相关的,暂且我们假设 4 台服务器(假设不考虑服务器本身性能问题,如果是这个原因那最好是升级服务器),其中一台做 K8S-Master 搭建,另外 3 台机器做 Worker 工作节点。

每个 worker 就是一个 Node 节点,现在需要在 Node 节点上去启动镜像,一切正常 Node 就是ready状态。

但是过了一段时间后,就成这样了

这就是我们要说的 Node 节点变成 NotReady 状态。
四,问题刨析
这跑着跑着就变成 NotReady 了,啥是 NotReady?

这都运行一段时间了,你告诉我还没准备好?

好吧,那就看看为什么还没准备好。
4.1 问题分析
再回到我们前面说到问题,就是 Node 节点变成 NotReady 状态后,Pod 容器是否还成正常运行。

图中用红框标示的就是在节点edgenode上,此时 Pod 状态已经显示为Terminating,表示 Pod 已经终止服务。
接下来我们就分析下 Node 节点为什么不可用。
(1)首先从服务器物理环境排查,使用命令df -m查看磁盘的使用情况

或者直接使用命令free查看

磁盘并没有溢出,也就是说物理空间足够。
(2)接着我们再查看下 CPU 的使用率,命令为:top -c (大写P可倒序)

CPU 的使用率也是在范围内,不管是在物理磁盘空间还是 CPU 性能,都没有什么异常。那 Node 节点怎么就不可用了呢?而且服务器也是正常运行中。
这似乎就有点为难了,这可咋整?

(3)不慌,还有一项可以作为排查的依据,那就是使用 kube 命令 describe 命令查看 Node 节点的详细日志。完整命令为:
kubectl describe node <节点名称>,那么图中 Node 节点如图:

哎呀,好像在这个日志里面看到了一些信息描述,首先我们先看第一句:Kubelet stoped posting node status,大致的意思是 Kubelet 停止发送 node 状态了,再接着Kubelet never posted node status意思为再也收不到 node 状态了。
查看下 Kubelet 是否在正常运行,是使用命令:
systemctl status kubelet,如果状态为 Failed,那么是需要重启下的。但如果是正常运行,请继续向下看。
分析一下好像有点眉目了,Kubelet 为什么要发送 node 节点的状态呢?这就抛出了关于 Pod 的另一个知识点,请耐心向下看。
五,Pod 健康检测 PLEG
根据我们最后面分析的情形,似乎是 node 状态再也没有收到上报,导致 node 节点不可用,这就引申出关于 Pod 的生命健康周期。
PLEG全称为:Pod Lifecycle Event Generator:Pod 生命周期事件生成器。
简单理解就是根据 Pod 事件级别来调整容器运行时的状态,并将其写入 Pod 缓存中,来保持 Pod 的最新状态。
在上述图中,看出是 Kubelet 在检测 Pod 的健康状态。Kubelet 是每个节点上的一个守护进程,Kubelet 会定期去检测 Pod 的健康信息,先看一张官方图。
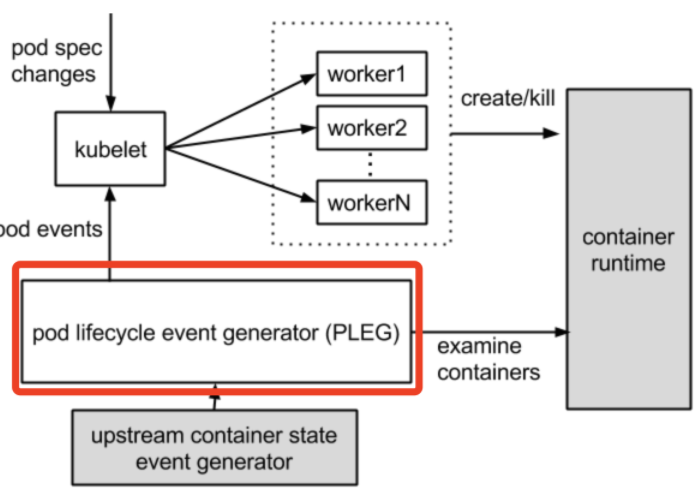
PLEG去检测运行容器的状态,而 kubelet 是通过轮询机制去检测的。
分析到这里,似乎有点方向了,导致 Node 节点变成 NotReady 状态是和 Pod 的健康状态检测有关系,正是因为超过默认时间了,K8S 集群将 Node 节点停止服务了。
那为什么会没有收到健康状态上报呢?我们先查看下在 K8S 中默认检测的时间是多少。
在集群服务器是上,进入目录:/etc/kubernetes/manifests/kube-controller-manager.yaml,查看参数:
–node-monitor-grace-period=40s(node驱逐时间)
–node-monitor-period=5s(轮询间隔时间)
上面两项参数表示每隔 5 秒 kubelet 去检测 Pod 的健康状态,如果在 40 秒后依然没有检测到 Pod 的健康状态便将其置为 NotReady 状态,5 分钟后就将节点下所有的 Pod 进行驱逐。
官方文档中对 Pod 驱逐策略进行了简单的描述,https://kubernetes.io/zh/docs/concepts/scheduling-eviction/eviction-policy/

kubelet 轮询检测 Pod 的状态其实是一种很消耗性能的操作,尤其随着 Pod 容器的数量增加,对性能是一种严重的消耗。
在 GitHub 上的一位小哥对此也表示有自己的看法,原文链接为:
https://github.com/fabric8io/kansible/blob/master/vendor/k8s.io/kubernetes/docs/proposals/pod-lifecycle-event-generator.md
到这里我们分析的也差不多了,得到的结论为:
Pod 数量的增加导致 Kubelet 轮询对服务器的压力增大,CPU 资源紧张
Kubelet 轮询去检测 Pod 的状态,就势必受网络的影响
Node 节点物理硬件资源限制,无法承载较多的容器
而由于本人当时硬件的限制,及网络环境较差的前提下,所以只改了上面了两项参数配置,延长 Kubelet 去轮询检测 Pod 的健康状态。实际效果也确实得到了改善。
// 需要重启docker
sudo systemctl restart docker
// 需要重启kubelet
sudo systemctl restart kubelet
但是如果条件允许的情况下,个人建议最好是从硬件方面优化。
- 提高 Node 节点的物理资源
- 优化 K8S 网络环境
六,K8S 常用命令
最后分享一些常用的 K8S 命令
1,查询全部 pod(命名空间)
kubectl get pods -n
2,查询全部 node 节点
kubectl get nodes
3,查看 pod 详细信息和日志
kubectl describe pod -n
kubectl logs -f -n
4,查看 pod-yaml 文件
kubectl get pod -n -o yaml
5,通过标签查询 pod
kubectl get pod -l app= -n
6,查询 pod 具体某一条信息
kubectl -n get pods|grep |awk '{print $3}'
7,删除 pod(或通过标签 -l app=)
kubectl delete pod -n
8,删除 deployment
kubectl delete deployment -n
9,强制删除 pod
kubectl delete pod -n --force --grace-period=0
10,进入 pod 容器
kubectl exec -it -n -- sh
11,给 node 打标签
kubectl label node app=label
12,查看某一个 node 标签
kubectl get node -l ""
13,查看全部 node 标签
kubectl get node --show-labels=true
六,总结
关于 Node 节点的 NotReady 状态当时也是排查了很久,对很多种情况也是猜测,并不能具体确定是什么原因。
网上关于这方面的内容也不是很多,只能是根据提示一步一步去排查问题的源头,并加以验证,最后也是在条件限制下解决了这个问题。
以后的工作也是做 AIOT 相关的,所谓 A 是指 Ai,IOT 指物联网。也是和 K8S 强相关的内容,后续也还会继续和大家分享关于 K8S 相关的知识。
如果您也是 K8S 的使用者,或者想接触学习 K8S,欢迎关注个人公众号!
最后,求关注
总结辛苦,原创不易!希望一些正能量的支持,求关注,点赞,转发(一键三连)

K8S线上集群排查,实测排查Node节点NotReady异常状态的更多相关文章
- kubeadm 线上集群部署(二) K8S Master集群安装以及工作节点的部署
PS:所有机器主机名请提前设置好 在上一篇,ETCD集群我们已经搭建成功了,下面我们需要搭建master相关组件,apiverser需要与etcd通信并操作 1.配置证书 将etcd证书上传到mast ...
- kubeadm 线上集群部署(一) 外部 ETCD 集群搭建
IP Hostname 192.168.1.23 k8s-etcd-01 etcd集群节点,默认关于ETCD所有操作均在此节点上操作 192.168.1.24 k8s-etcd-02 etcd ...
- kubeadm搭建kubernetes集群之三:加入node节点
在上一章<kubeadm搭建kubernetes集群之二:创建master节点>的实战中,我们把kubernetes的master节点搭建好了,本章我们将加入node节点,使得整个环境可以 ...
- k8s集群添加新得node节点
服务端操作: 方法一: 获取master的join token kubeadm token create --print-join-command 重新加入节点 kubeadm join 192.16 ...
- k8s, etcd 多节点集群部署问题排查记录
目录 文章目录 目录 部署环境 1. etcd 集群启动失败 解决 2. etcd 健康状态检查失败 解决 3. kube-apiserver 启动失败 解决 4. kubelet 启动失败 解决 5 ...
- Linux(2)---记录一次线上服务 CPU 100%的排查过程
Linux(2)---记录一次线上服务 CPU 100%的排查过程 当时产生CPU飙升接近100%的原因是因为项目中的websocket时时断开又重连导致CPU飙升接近100% .如何排查的呢 是通过 ...
- 一次线上CPU高的问题排查实践
一次线上CPU高的问题排查实践 前言 近期某一天上班一开电脑,就收到了运维警报,有两台服务CPU负载很高,同时收到一线同事反馈 系统访问速度非常慢,几乎无响应. 一个美好的早晨,最怕什么就来什么.只好 ...
- 线上CPU飙升100%问题排查
本文转载自线上CPU飙升100%问题排查 引子 对于互联网公司,线上CPU飙升的问题很常见(例如某个活动开始,流量突然飙升时),按照本文的步骤排查,基本1分钟即可搞定!特此整理排查方法一篇,供大家参考 ...
- Kubeadm部署K8S(kubernetes)集群(测试、学习环境)-单主双从
1. kubernetes介绍 1.1 kubernetes简介 kubernetes的本质是一组服务器集群,它可以在集群的每个节点上运行特定的程序,来对节点中的容器进行管理.目的是实现资源管理的自动 ...
随机推荐
- mac或linux常见命令
1. 用某个软件打开某文件,如subline text: https://blog.csdn.net/Cinderella_hou/article/details/82392139 如果想使用subl ...
- 透明小电视上线——GitHub 热点速览 v.21.05
作者:HelloGitHub-小鱼干 这周的 GitHub Trending 真是棒极了.小鱼干喜欢的科技博主又开源了他的硬件玩具,一个透明的小电视机,HG 的小伙伴看完项目,再买个电路板和分光棱镜, ...
- 一文读懂云上DevOps能力体系
简介: 阿里云ECS自动化运维套件架构师,深度拆解云上运维能力体系建设:自动化运维等级金字塔.自动化运维的进阶模式.DevOps的基础核心.云上标准化部署三大能力-- 序言 云计算行业已经有十多年的发 ...
- linux(1)Mac上传文件到Linux服务器
前言 我们使用mac时,想让本地文件上传至服务器,该怎么办呢 windows系统,我们可以使用xftp或者rz命令,那么mac呢? mac系统,我们可以使用sftp.scp或者rz命令,本文介绍sft ...
- UDP实现多人聊天
发送端 package com.zy.exercise; import java.net.DatagramPacket; import java.net.DatagramSocket; import ...
- VScode 连接虚拟机
VScode 连接虚拟机 在VScode上面使用SSH连接虚拟机,编写代码以及运行都将会方便许多 打开VScode,安装Remote-SSH插件 配置SSH连接信息 点击左侧第四个图标,然后单击设置按 ...
- [SCOI2009] [BZOJ1026] windy数
windy定义了一种windy数.不含前导零且相邻两个数字之差至少为2的正整数被称为windy数. windy想知道, 在A和B之间,包括A和B,总共有多少个windy数?\(1 \le A \le ...
- hdu4710 Balls Rearrangement(数学公式+取模)
Balls Rearrangement Time Limit: 6000/3000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Othe ...
- 2020牛客暑期多校训练营 (第二场) All with Pairs
传送门:All with Pairs 题意:给你n个字符串,求出,f(si,sj)的意思是字符串 si 的前缀和字符串 sj 后缀最长相等部分. 题解:先对所有的字符串后缀hash,用map记录每个h ...
- Consonant Fencity Gym - 101612C 暴力二进制枚举 Intelligence in Perpendicularia Gym - 101612I 思维
题意1: 给你一个由小写字母构成的字符串s,你可以其中某些字符变成大写字母.如果s中有字母a,你如果想把a变成大写,那s字符串中的每一个a都要变成A 最后你需要要出来所有的字符对,s[i]和s[i-1 ...